머신러닝 기반 시계열 접근은 공통된 특징을 가진다.
- 시계열 → 특징(feature) 추출
- 고정 길이 벡터 → 회귀 문제
- 시간 의존성은 간접적으로만 존재
RNN 계열 모델은 이 접근에 대한 명확한 문제의식에서 출발한다.
“왜 시간 정보를 사람이 요약해야 하는가?”
“순서 자체를 모델이 직접 다루게 할 수는 없는가?”
그 결과가 RNN, 그리고 그 한계를 보완한 LSTM과 GRU다.
1. RNN (Recurrent Neural Network)
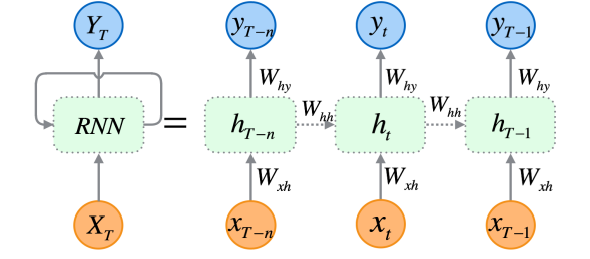
기본 아이디어
RNN은 이전 시점의 상태를 다음 시점으로 전달한다.
- (x_t): 시점 (t)의 입력
- (h_t): 은닉 상태(hidden state)
- (h_{t-1}): 과거 정보를 압축한 벡터
과거 정보가 하나의 상태 벡터로 누적된다
RNN이 시계열을 다루는 방식
- 시계열 전체를 한 스텝씩 순차 처리
- 과거 → 은닉 상태에 압축
- 피처 추출을 사람이 아닌 모델이 수행
이는 슬라이딩 윈도우 + 회귀와 근본적으로 다르다.
한계: Gradient Vanishing / Exploding
RNN은 학습 시 역전파(BPTT) 를 사용한다.
이때 다음 문제가 발생한다.
- 긴 시퀀스에서 기울기 소실
- 먼 과거 정보가 학습되지 않음
결과적으로,
RNN은 이론적으로는 시계열을 기억하지만
실제로는 짧은 기억만 가능하다
2. LSTM (Long Short-Term Memory)
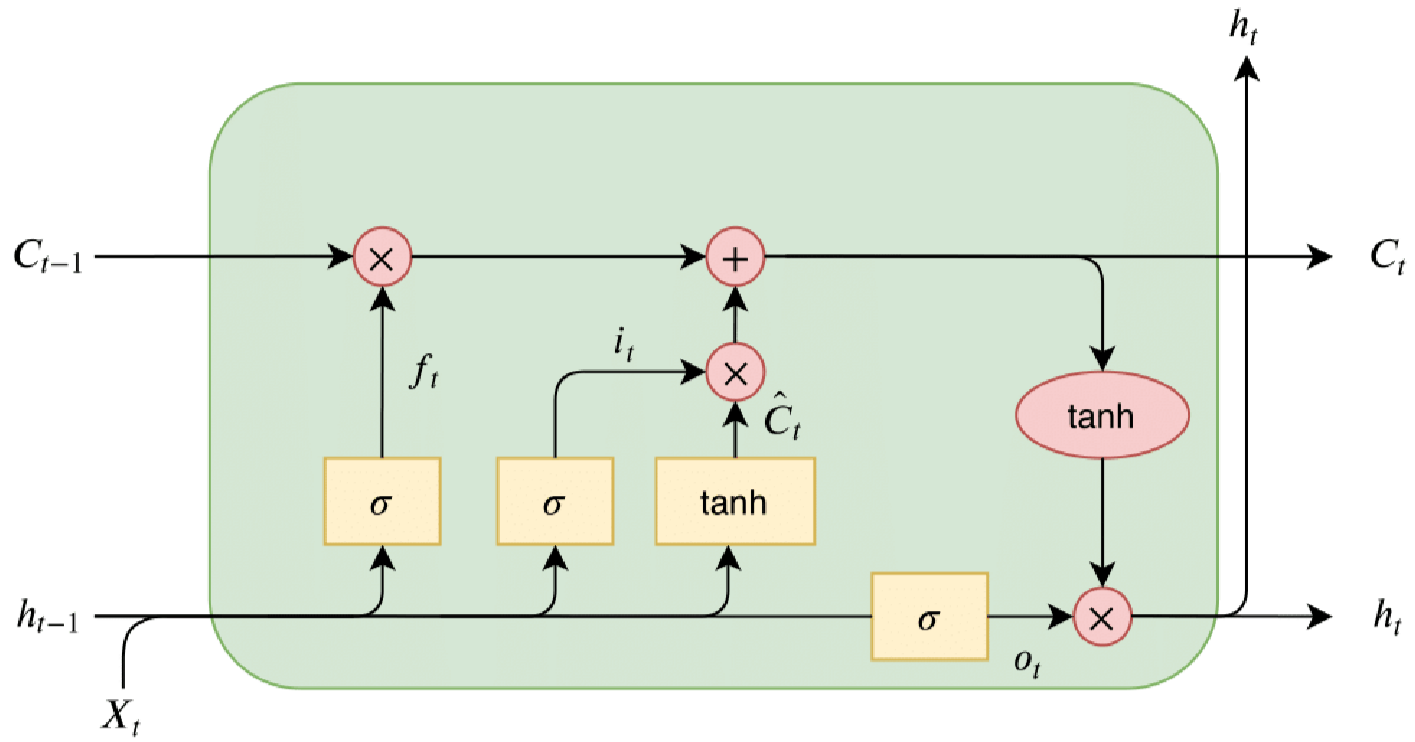
RNN의 한계를 해결하기 위해 등장한 구조다.
핵심은 기억을 선택적으로 저장하고 삭제하는 메커니즘이다.
LSTM의 핵심 구성 요소
LSTM은 두 개의 상태를 가진다.
- Cell State ((c_t)): 장기 기억
- Hidden State ((h_t)): 단기 출력
그리고 이를 제어하는 게이트(gate) 가 있다.
게이트 구조
Forget Gate
- 무엇을 잊을지 결정
Input Gate
- 무엇을 새로 기억할지 결정
Cell Update
Output Gate
LSTM 정리
- 기울기 소실 문제 완화
- 장기 의존성 학습 가능
- 불규칙한 시계열에서도 안정적
- 단, 구조가 복잡하고 연산량이 크다.
3 GRU (Gated Recurrent Unit)
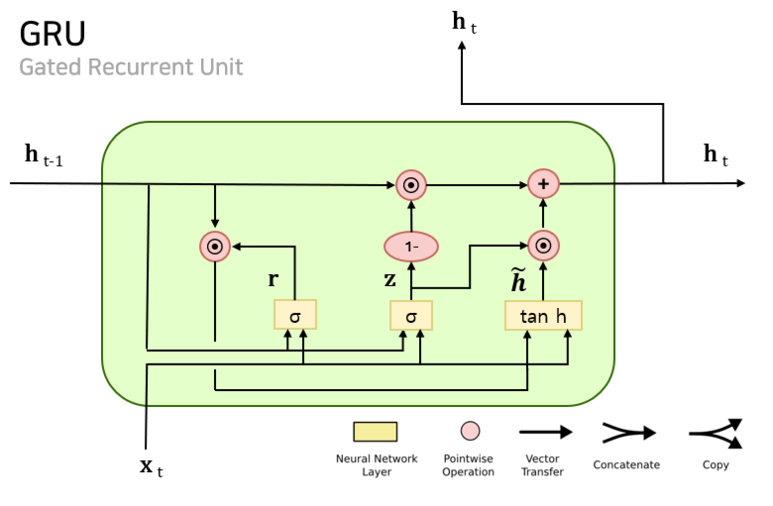
GRU는 LSTM의 단순화 버전이다.
GRU 구조
GRU는 하나의 상태만 유지한다.
GRU의 특징
- LSTM보다 파라미터 적음
- 학습 속도 빠름
- 성능은 많은 경우 LSTM과 유사
4. RNN / LSTM / GRU 비교 도표
| 구분 | RNN | LSTM | GRU |
|---|---|---|---|
| 장기 의존성 | ❌ 매우 약함 | ⭕ 강함 | ⭕ 비교적 강함 |
| 기울기 소실 | ❌ 심각 | ⭕ 완화 | ⭕ 완화 |
| 상태 구조 | Hidden State 1개 | Hidden + Cell | Hidden State 1개 |
| 게이트 수 | 없음 | 3개 | 2개 |
| 파라미터 수 | 적음 | 많음 | 중간 |
| 학습 속도 | 빠름 | 느림 | 중간 |
| 구현 복잡도 | 낮음 | 높음 | 중간 |
| 실무 사용 빈도 | 거의 없음 | 있음 | 매우 높음 |
5. 언제 어떤 모델을 사용하는가
RNN을 쓰는 경우
- 시퀀스 길이가 매우 짧을 때
LSTM을 쓰는 경우
- 장기 패턴이 명확한 시계열
- 불규칙한 간격, 누락 데이터 존재
- 시계열 길이가 길고 복잡한 경우
예:
- 설비 로그
- 사용자 행동 시퀀스
- 금융 시계열
GRU를 쓰는 경우
- LSTM이 과도하게 무거운 경우
- 데이터가 상대적으로 적을 때
- 빠른 실험이 필요한 경우

2026년 화이팅!!!