프로세스의 생성과정 및 상태 전이( + 스레드와 차이점 )
프로세스에 대해 왜 알아야할까?
프로세스는 운영체제에서 자주 등장하는 개념이면서 면접 단골질문이기도 하다. 운영체제 스터디를 하면서 해당 주제를 맡게 됐는데, 학습하기 전 프로세스에 대해 왜 알아야할까 고민을 해봤다. 고민한 결과 나는 다음과 같은 결론을 내렸다.
- 우리는 컴퓨터에서 프로그램을 통해 다양한 활동을 수행할 수 있다. 따라서 운영체제의 핵심은 그 프로그램들을 실행시키고 관리하는 것이라고 생각할 수 있다.
- 위와 같은 이유로 인해 운영체제에 대한 기초를 쌓기 위해서는 "실행중인 프로그램"이라는 정의를 가지는 프로세스에 대해 이해할 필요가 있다.
프로그램 vs 프로세스
위에서 프로그램과 프로세스가 모두 언급이 됐는데, 이 두개는 어떤 차이가 있을까? 프로세스에 대해 알아보기 전 짚고 넘어가도록 하자.
프로그램
- 워드, 엑셀, 카카오톡과 같은 프로그램은 코드 모음이라고 할 수 있다.
프로세스
- 프로그램을 메모리 공간에 할당하고 실행시켜 동적인 상태가 된 것을 프로세스라고 한다. → 따라서 "실행중인 프로그램"으로 정의하기도 한다.
- 운영체제로부터 시스템 자원(CPU)를 할당받으면 서비스를 이용할 수 있게 된다.
- 스레드보다 더 많은 자원을 사용하기 때문에, heavyweight process라고도 하고, 시분할 시스템에서는 스케줄링의 대상이 되는 작업이라는 의미로 Task 라고도 한다.
이제 프로그램은 디스크에 있는 "코드 모음" 즉 정적인 상태라면, 프로세스는 메모리에 적재되어 실행이 가능한 동적인 상태인 건 알겠다. 그럼 프로그램은 어떻게 프로세스가 될까? 이제부턴 프로세스 생성 과정에 대해 정리해보자.
프로세스 생성과정
프로세스는 실행 중에 프로세스 생성 시스템을 호출하여 새로운 프로세스를 생성할 수 있다. 이에 따라 부모/자식 관계를 유지하며 계층적으로 생성된다. 따라서 프로세스가 생성되기 위해서는 부모 프로세스와 생성 요청을 하기 위한 시스템콜이 필요하다. 이를 차근차근 살펴보자.
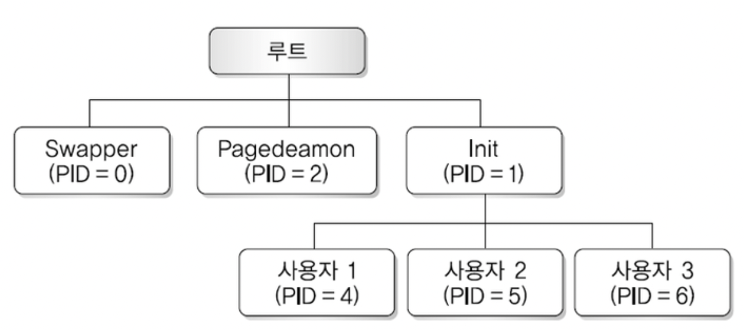
위 그림은 유닉스 시스템에서의 프로세스 계층 구조이다. 시스템을 부팅할 때 Swapper, Pagedaemon, Init 이렇게 3개의 프로세스가 생성되는데, 이를 운영체제(커널) 프로세스라고 한다. 그리고 모든 사용자 프로세스는 fork() 명령을 통해 계층적으로 Init의 자식 프로세스로 생성된다.
fork()와 exec()
프로세스 생성과 관련된 시스템콜을 살펴보자. 리눅스나 유닉스 시스템에서는 fork() 시스템콜을 통해 부모 프로세스를 복제하여 새로운 자식 프로세스를 생성할 수 있고, exec() 시스템콜을 통해서는 프로세스 내용을 새로운 프로세스로 대체할 수 있다.
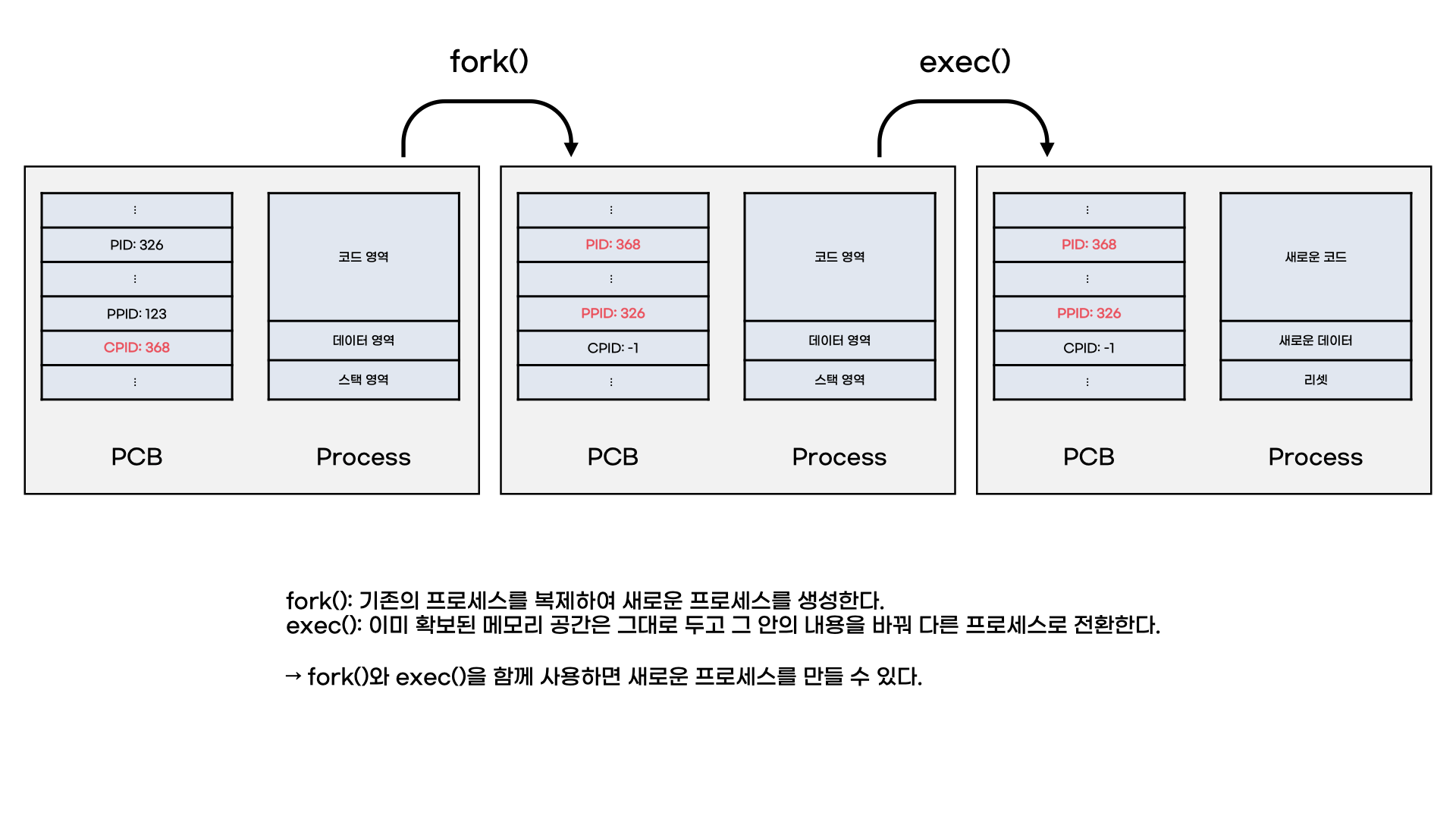
좀 더 자세하게 살펴보면 fork()는 기존의 프로세스를 복제하여 동일한 프로세스를 가지고 있지만, PCB(Process Control Block)의 PID(프로세스 아이디)와 PPID(부모 프로세스 아이디), CPID(자식 프로세스 아이디)가 다르다.
프로세스는 실행중인 프로세스로부터 fork()와 exec() 시스템콜을 호출하여 생성될 수 있다는 것을 알았다. 이제 프로세스가 어떤 과정을 거쳐 생성되는지 자세하게 살펴보자!
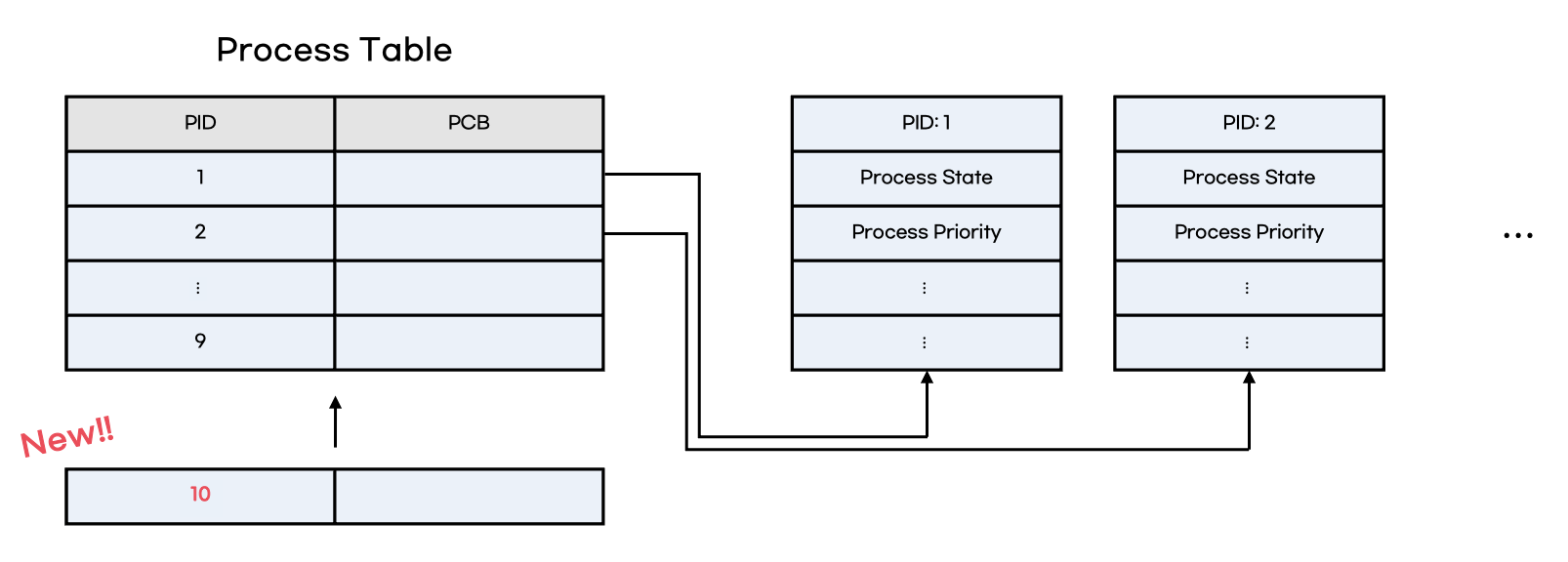
1. PID 생성 후 Process Table에 삽입
새로운 프로세스가 생성되면, 운영체제는 고유한 프로세스 아이디를 할당하고 process table에 삽입한다.
2. 메모리 할당
PCB를 포함하여 프로그램, 데이터, 스택과 같은 프로세스의 요소에 필요한 메모리 공간이 할당된다.
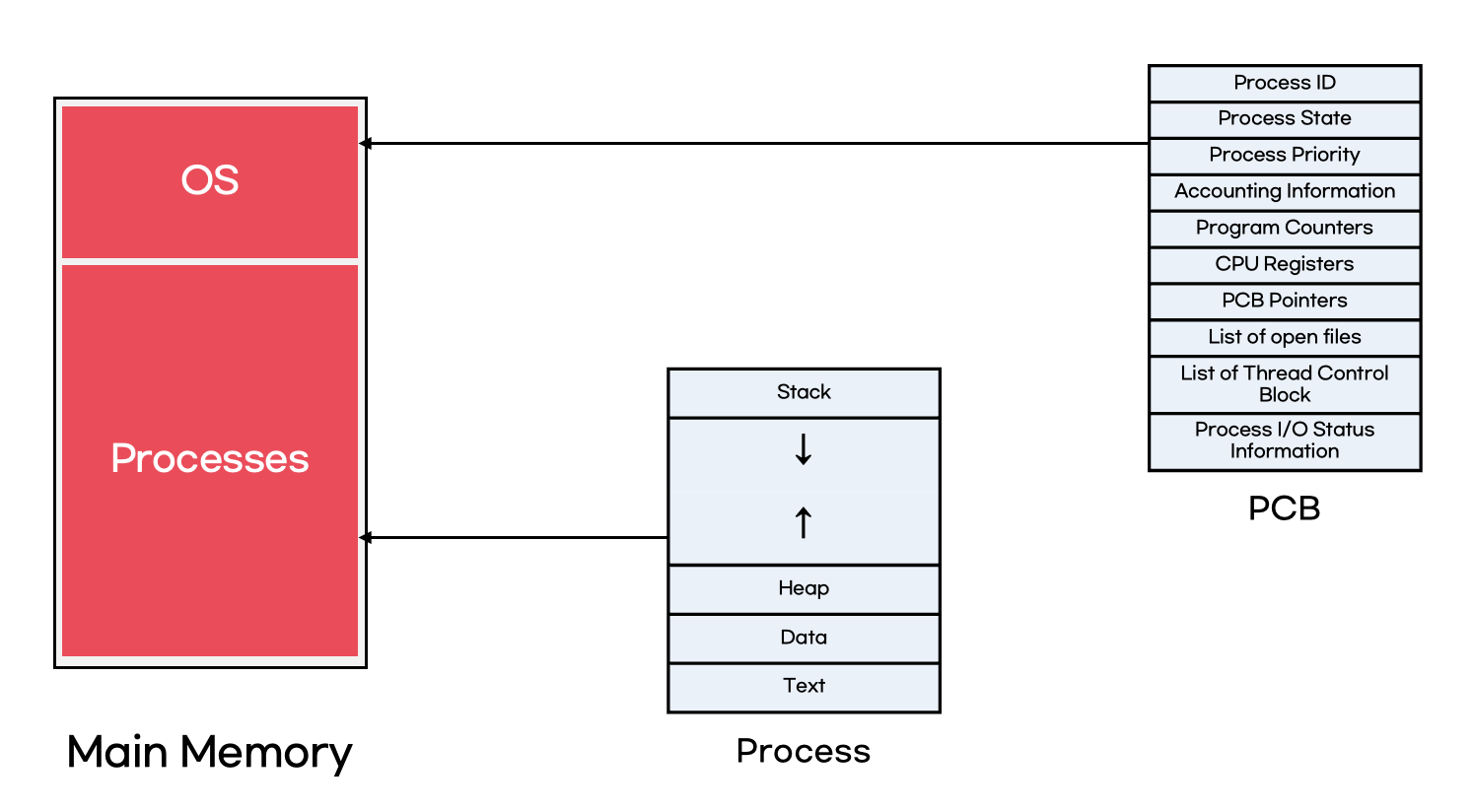
3. PCB값 초기화
PCB에는 프로세스 아이디, 상태, 우선순위, Thread Control Block 리스트 등의 정보가 저장된다.
1) 첫 번째 단계에서 생성한 PID를 PID 영역에 채우고, 부모 프로세스 아이디도 채워준다.
2) 스택 포인터와 프로그램 카운터를 제외한 대부분의 영역은 0으로 채워진다. 스택 포인터는 두번째 단계에서 할당받은 메모리 공간을 기반으로 채워지고, 프로그램 카운터는 프로그램의 시작점의 주소로 채워진다.
3) 프로세스 상태에는 'New'로 세팅된다.
4) 프로세스의 우선순위는 디폴트가 가장 낮은 단계이다. 하지만 유저가 변경 가능하다.
4. 준비 상태로 전환
프로세스를 스케줄링큐에 넣고 프로세스 상태를 'New'에서 'Ready'로 바꾼다. 이제 프로세스는 CPU가 할당되길 기다린다.
프로세스가 어떻게 생성되는지는 알았으니 이제부터 생성된 이후에는 어떻게 되는지 살펴보자!
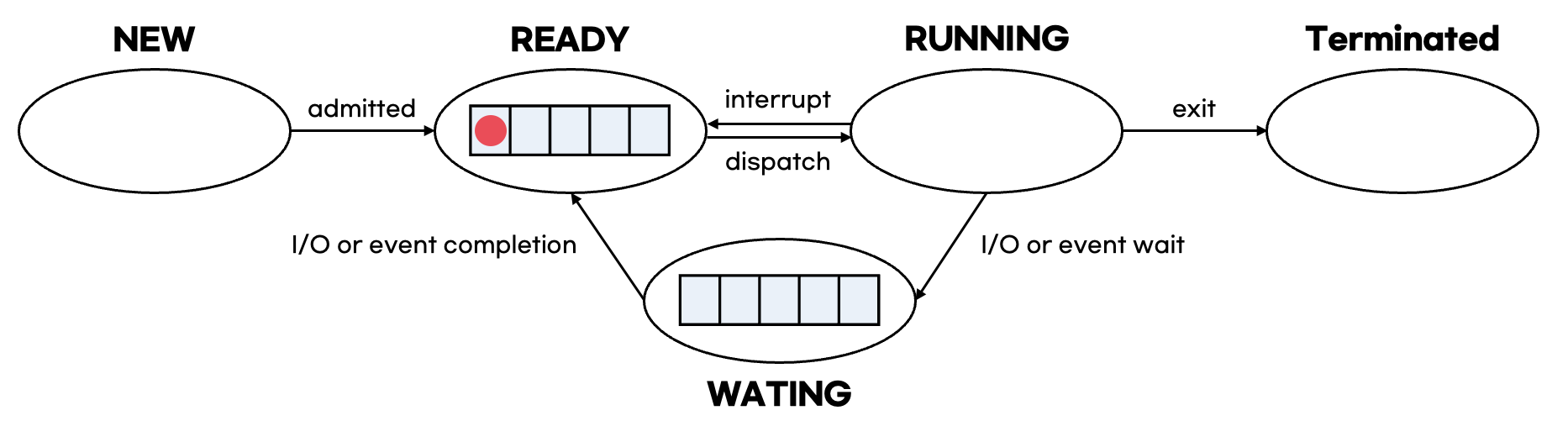
프로세스 상태
프로세스의 상태는 일반적으로 위와 같이 생성/준비/실행/대기/종료 5개로 구분한다.
프로세스 상태 전이
프로세스의 상태가 변하는 것을 상태 전이라고 한다. 전이되는 경우를 정리해보았다.
준비 → 실행
- 준비 큐의 맨 앞에 있는 프로세스가 프로세서를 할당받아 실행된다. 이렇게 프로세스를 할당받아 실행되는 것을 디스패치(Dispatch)라고 한다.
실행 → 준비
- 특정 프로세스가 프로세스를 독점하는 것을 막기 위해 인터럽트 클록(Interrupt Clock)을 두어 프로세서 점유 시간을 지정한다.
- 프로세스가 일정 시간이 지나도 프로세서를 반환하지 않으면 클록이 인터럽트를 발생시켜 운영체제가 제어권을 갖게 한다.
- 운영체제가 제어권을 가지면 실행 중인 프로세스는 준비 상태로 전환된다.
실행 → 대기(보류)
실행 프로세스가 지정 시간 전에 입출력 연산 등이 필요하거나 새로운 자원 요청과 같은 문제가 발생하면 스스로 프로세스를 양도하고 대기 상태가 된다.
대기(보류) → 준비
- 입출력이 끝나고 Wake Up이 발생하면 준비 상태로 전환된다.
실행 → 종료
- 프로세스가 마지막 명령의 실행을 마치면 종료되고 운영체제에 프로세스 삭제를 요청한다.
- 자식 프로세스가 할당된 자원을 초과해서 사용하거나 자식 프로세스에 할당된 작업(Task)가 없으면 부모 프로세스가 자식 프로세스를 종료시킬 수 있다.
프로세스와 스레드의 차이
프로세스하면 스레드라는 개념이 연관지어 많이 등장한다. 프로세스와 스레드의 차이는 면접에서 단골질문으로 많이 나온다고 하는데, 둘이 뭐가 다르냐! 이런 차이가 중요하다기보다 각각의 개념을 잘 알고 있는지 확인하기 위한 질문에 가깝다고 생각한다.
어차피 프로세스는 1개 이상의 스레드를 가지고 있기 때문에, 반드시 1개의 스레드는 가지고 있다. 따라서 두 개를 따로따로 보고 차이에 집중하기보다는 개념을 잘 정리하는 게 중요할 듯 하다.
프로세스와 스레드를 비교하기에 앞서 두 개념의 등장배경을 알아보자. 왜 나왔을까? 시작에 대해서 알아두면 좀 더 이해하기 쉬울 것 같다.
"프로세스"의 등장배경
- 초창기 컴퓨터 시스템
초창기 컴퓨터 시스템은 한 번에 하나의 프로그램만 실행할 수 있어 프로그램 하나가 컴퓨터 시스템 자원을 독차지했다. - 멀티 프로그래밍
만약 실행중인 프로그램이 입출력을 위해 대기하고 있다면 CPU는 할 일 없이 놀게 될 것이다. 그럼 대기하는 동안 다른 프로그램을 실행하는 것은 어떨까? 이런 생각으부터 "멀티 프로그래밍"이 등장하게 됐다.
하지만 여기서도 문제가 있다. 만약 입출력 이벤트가 필요없다면, 한 프로그램이 실행되는 중간에 다른 프로그램을 실행시킬 일이 없다. 다른 프로그램은 실행중인 프로그램에서 입출력 이벤트가 발생하거나 종료되기만을 기다려야한다. - 멀티 태스킹
응답 시간을 높이기 위해 컴퓨터 자원을 시간적으로 분배하고, 여러 작업들을 번갈아가며 수행하여 마치 동시에 수행되는 것처럼 느끼게 했다.
이렇게 컴퓨터의 자원을 시간적으로 분배하여 사용하는 시분할 시스템이 개발되는 과정에서 "프로세스" 개념이 생기게 됐다. "프로세스(Process)"라는 용어는 1960년대 멀틱스 시스템을 설계한 사람들이 처음 사용했다고 한다. 여기서 멀틱스 시스템은 초기 시분할 시스템이라고 생각하면 된다.
"스레드"의 등장배경
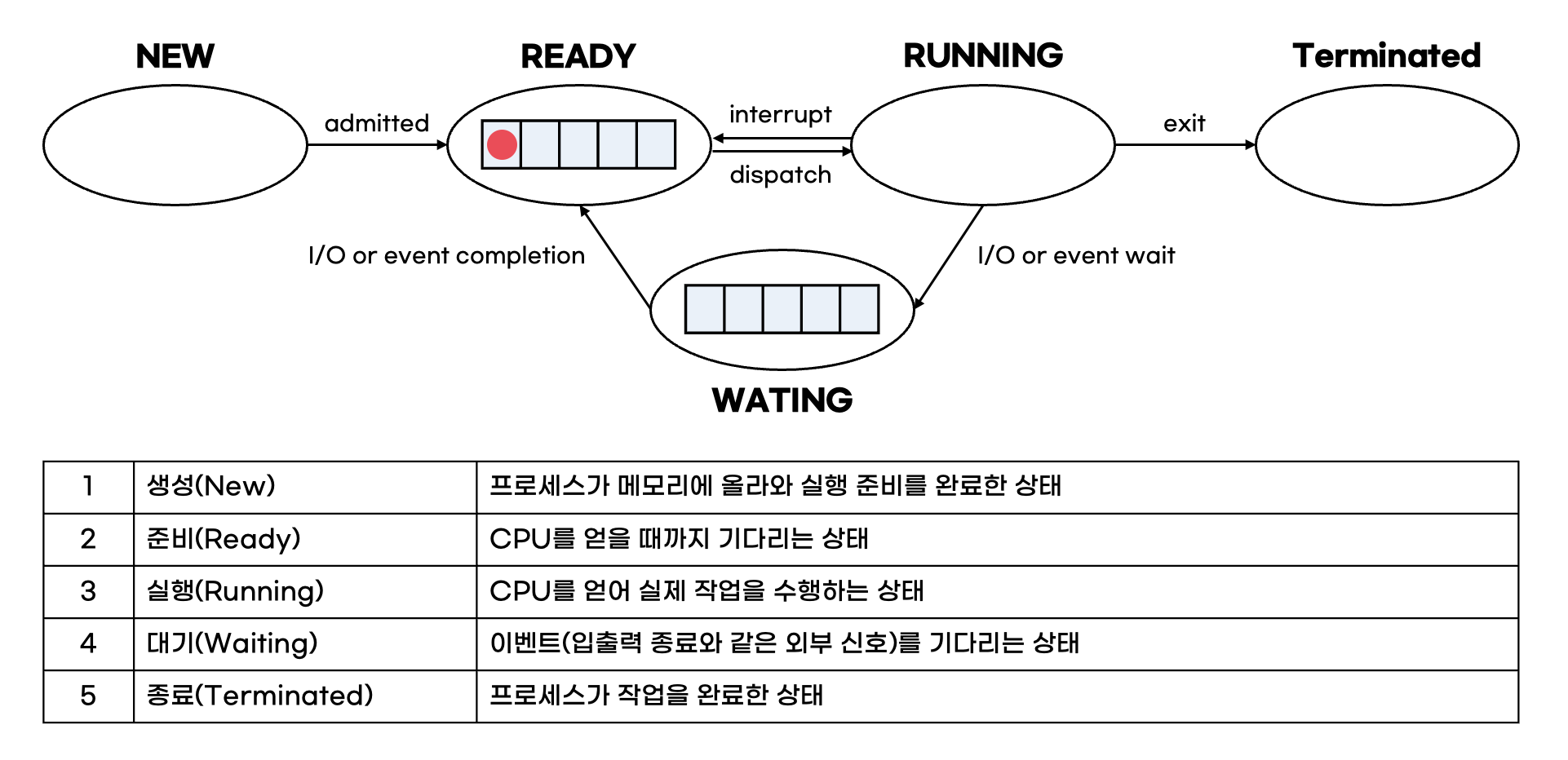
하지만 여전히 아쉬운 점이 존재했다. 멀티 태스킹을 통해 응답 시간을 높였지만, 하나의 프로세스가 동시에 여러 작업을 수행하지는 못한다는 한계가 있었다. 이를 보완하기 위해 "스레드"와 "멀티 스레딩" 개념이 등장했다.
- 멀티 스레딩
프로세스를 둘 이상의 스레드로 구성하여 하나의 프로세스 내에서 여러 작업이 동시에 수행되게 하는 시스템이다. 스레드도 프로세스와 마찬가지로 CPU의 코어 수보다 더 많은 스레드가 실행되면 문맥 교환(context switching)이 발생한다.
하지만 이 때 스레드끼리는 코드, 데이터, 파일 영역을 공유하기 때문에 같은 프로세스 내의 다른 스레드로 전환하는 것은 프로세스 문맥 교환보다 시간이 덜 걸린다.
프로세스와 스레드의 차이

프로세스와 스레드의 차이를 표로 정리해보았다. 여기서 코드, 데이터, 파일 영역은 공유하면서 스택만 독립적으로 할당받은 이유에 대해 정리하고 글을 마쳐보려 한다.
스레드는 왜 스택만 독립적으로 할당받을까?
이는 스택 프레임의 역할과 스택 프레임의 동작방식에 대해 이해가 더 필요하다. 만약 좀 더 자세하게 알고 싶다면, 아래 링크를 참고하자.
http://www.tcpschool.com/c/c_memory_stackframe
int main(void)
{
int d = func1(); // func1() 호출
return d;
}
void func1()
{
int c = func2(1, 2); // func2() 호출
return c;
}
void func2(int a, int b)
{
return a + b;
}위와 같은 코드가 존재할 때 스택 프레임은 아래와 같이 변화한다.
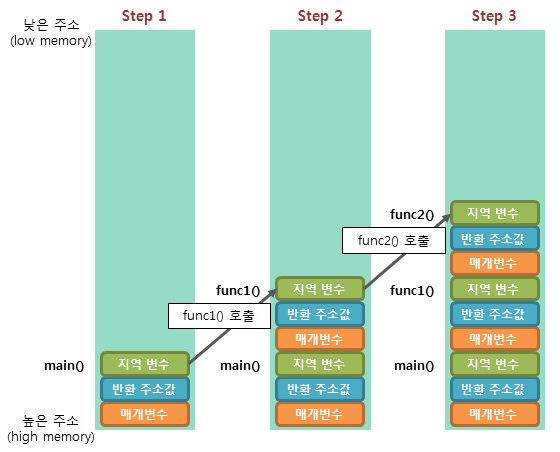
함수가 호출될 때마다 해당 함수와 관련된 변수 값과 돌아갈 주소값을 저장한다.
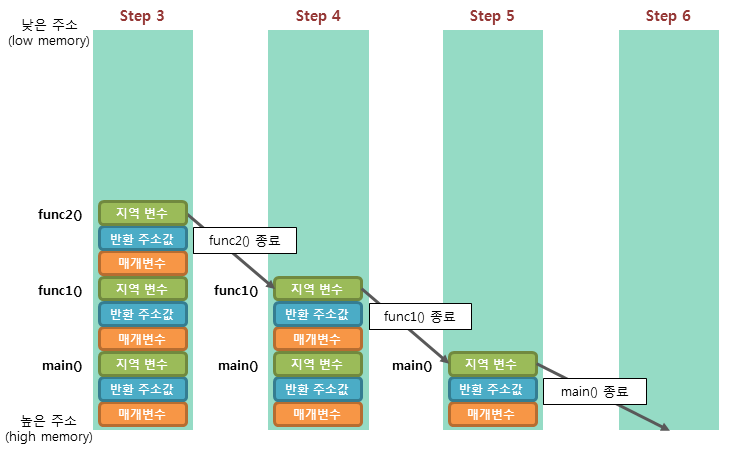
그리고 함수가 종료되면 하나씩 제거해가면서 돌아갈 주소값을 참고하여 함수를 호출한 위치로 돌아간다. 만약 한 스레드에서 물건을 주문하는 흐름이 진행되고 있다고 가정해보자. 그렇다면 스택에는 물건 주문과 관련된 값들과 함수를 호출한 곳의 주소(반환 주소값)이 저장되어 있을 것이다. 근데 물건을 등록하는 또 다른 흐름을 새로 진행하고 싶은데, 이 공간을 그래도 활용하면 관련 값들이 뒤죽박죽 되어버리고 함수 수행 완료시 해당 함수를 호출한 곳이 아닌 이상한 곳으로 이동할 수도 있을 것이다.
즉 아래와 같이 정리할 수 있다.

전반적인 프로세스의 개념과 생성과정 및 상태 전이 그리고 스레드에 대해서도 간단하게 살펴봤다. 다음에는 프로세스 스케줄링에 대해 공부해볼 예정이다.
여기까지 글을 읽어주신 분이 있다면 긴 글을 읽어주셔서 감사합니다. 만약 틀린 부분이 있다면 알려주세요. 빠르게 수정하도록 하겠습니다 :)
참고
- 스택 구조 – “시스템 해킹 강좌 6강 – 스택 프레임(Stack Frame) 이해하기”
https://www.youtube.com/watch?v=ZFOHvzXcao0&t=3s - 스택 구조 –"스택 프레임 ”
http://www.tcpschool.com/c/c_memory_stackframe - 프로세스와 스레드 개념 – "완전히 정복하는 프로세스 vs 스레드 개념"
https://inpa.tistory.com/entry/%F0%9F%91%A9%E2%80%8D%F0%9F%92%BB-%ED%94%84%EB%A1%9C%EC%84%B8%EC%8A%A4-%E2%9A%94%EF%B8%8F-%EC%93%B0%EB%A0%88%EB%93%9C-%EC%B0%A8%EC%9D%B4#thankYou - 프로세스 컨트롤 블럭 – “What is Process Control Block in OS?”
https://www.scaler.com/topics/operating-system/process-control-block-in-os/ - 프로세스의 생성과 종료 과정 – “process-creation-and-deletions-in-operating-systems”
https://www.geeksforgeeks.org/process-creation-and-deletions-in-operating-systems/ - 스레드 생성 – “Thread creation using POSIX”
https://www.linkedin.com/pulse/thread-creation-using-posix-amit-nadiger - Java에서 스레드 상태 변화 – “Life Cycle of Thread in Java | Thread State”, “[Java]쓰레드 상태(Thread State)와 메서드에 대하여
”
https://www.scientecheasy.com/2020/08/life-cycle-of-thread-in-java.html/
https://jongwoon.tistory.com/14
https://docs.oracle.com/javase/7/docs/api/java/lang/Thread.State.html - 프로세스의 생성과 전반적인 개념 – [책] 운영체제 개정판 – 그림으로 배우는 원리와 구조
- 스레드 관련
https://www.cs.fsu.edu/~baker/opsys/notes/threads.html
https://www.d.umn.edu/~gshute/os/processes-and-threads.html
