프로세스 스케줄링 (+리눅스에서의 스케줄링 예시)
들어가며
이 글은 "준비큐에 있는 프로세스 중 어떤 프로세스에게 CPU를 할당할 것인가?"에 대한 내용을 다루고 있습니다. 기초적인 내용으로 어렵지는 않지만, 프로세스가 가질 수 있는 상태와 상태 전이에 대해서 이해한 상태에서 글을 보는 걸 추천드립니다.
용어 정리
앞으로 나오게 될 용어들을 정리하고 넘어가겠습니다.
스케줄링(Scheduling)
컴퓨팅에서 "스케줄링"은 작업을 수행하기 위해 자원을 할당하는 작업입니다. 여기서 자원은 processors, network links 또는 expansion cards가 될 수 있습니다.
(참고: Wikipedia)
- 스케줄링 작업은 스케줄러에 의해 수행됩니다.
스케줄러(Scheduler)
"스케줄러"는 다양한 방법을 통해 프로세스 스케줄링을 처리하는 특별한 목적의 시스템 소프트웨어입니다.
(참고: tutorialspoint)
- 스케줄러의 주요 업무는 시스템에 제출할 작업을 선택하고 실행할 프로세스를 결정하는 것입니다.
- 스케줄러는 장기 스케줄러/중기 스케줄러/단기 스케줄러 이렇게 총 3가지 유형으로 나뉩니다.
디스패치(Dispatch)
준비 리스트 맨 앞에 있던 프로세스에 프로세서를 할당하여 실행하는 것을 "디스패치"라고 한다. (상태 전이: 준비 → 실행)
(참고: (책)운영체제 - 그림으로 배우는 원리와 구조)
디스패처(Dispatcher)
CPU 스케줄링 기능에 참여하는 또 다른 요소는 디스패처(Dispatcher)이다. 단기 스케줄러에 의해 선택된 프로세스에 CPU의 제어권을 주는 모듈이다. 인터럽트나 시스템콜의 결과로 커널 모드에서 제어권을 받는다.
(참고: Wikipedia)
-
디스패처의 기능은 다음을 포함합니다.
- 문맥 전환(Context Switch)에서 디스패처는 이전에 실행중이던 프로세스 또는 스레드의 상태 저장; 디스패처는 초기 또는 이전에 저장했던 새로운 프로세스의 상태를 로드
- 유저 모드로 전환
- new state로 표시된 프로그램을 다시 시작하기 위해 사용자 프로그램 안에서 적절한 위치로 점프
하나의 프로세스를 종료하고 다른 프로세스를 시작시키기 위해 걸리는 시간을 “dispatch latency” 라고 합니다.
타임 슬라이스(Time Slice)
선점형 멀티태스킹 시스템에서 프로세스가 실행되도록 허용된 시간을 일반적으로 타임 슬라이스(time slice) 또는 퀀텀(quantum)이라고 합니다.
(참고: Wikipedia)
여러분은 평소에 어떻게 계획을 세우시나요? 저는 마감기간, 예상 소요 시간, 중요도 등을 고려하여 계획을 세우는데요. 운영체제는 어떤 목적을 가지고 어떤 것들을 고려하여 스케줄링을 하는지 살펴봅시다!
스케줄링의 목적과 고려 사항
스케줄링의 목적
1. 공평성
모든 프로세스가 자원을 공평하게 배정받아야 하며, 자원 배정 과정에서 특정 프로세스가 배제되어서는 안 됩니다.
2. 효율성
시스템 자원이 유휴 시간 없이 사용되도록 스케줄링을 하고, 유휴 자원을 사용하려는 프로세스에는 우선권을 주어야 합니다.
3. 안정성
우선순위를 사용하여 중요 프로세스가 먼저 작동하도록 배정함으로써 시스템 자원을 점유하거나 파괴하려는 프로세스로부터 자원을 보호해야합니다.
4. 확장성
프로세스가 증가해도 시스템이 안정적으로 작동하도록 조치해야 한다. 또한 시스템 자원이 늘어나는 경우 이 혜택이 시스템에 반영되게 해야 합니다.
5. 반응 시간 보장
응답이 없는 경우 사용자는 시스템이 멈춘 것으로 가정하기 때문에 시스템은 적절한 시간 안에 프로세스의 요구에 반응해야 합니다.
6. 무한 연기 방지
특정 프로세스의 작업이 무한히 연기되어서는 안 됩니다.
스케줄링 시 고려 사항
1. 프로세스 우선순위
- 커널과 관련된 작업은 우선적으로 처리되어야 하기 때문에, 우선순위를 고려하는 것이 필요합니다.
- 우선순위가 높을수록 더 빨리 자주 실행된다는 의미입니다.
2. 전면 프로세스 vs 후면 프로세스
- 전면 프로세스: GUI를 사용하는 운영체제에서 화면의 맨 앞에 놓인 프로세스. 현재 입력과 출력을 사용하는 프로세스로, 사용자와 상호작용이 가능하여 상호작용 프로세스라고 합니다.
- 후면 프로세스: 사용자와 상호작용이 없는 프로세스. 압축 프로그램처럼 사용자의 입력 없이 작동하기 때문에, 일괄 작업 프로세스라고도 합니다.
- 전면 프로세스는 사용자의 요구에 즉각 반응해야 하지만, 후면 프로세스는 상호작용이 없기 때문에, 전면 프로세스의 우선순위가 후면 프로세스보다 높습니다.
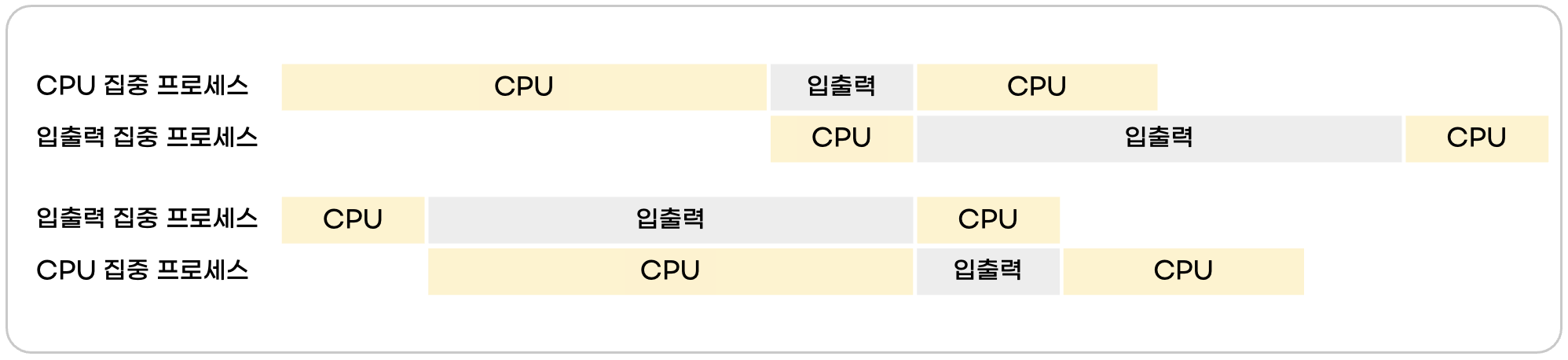
3. CPU 집중 프로세스 VS 입출력 집중 프로세스
- CPU를 할당받아 실행하는 작업을 "CPU 버스트(CPU burst)", 입출력 작업을 입출력 버스트(I/O burst)라고 합니다.
- 작업 형태에 따라 CPU 집중 프로세스와 입출력 집중 프로세스로 나눌 수 있습니다.
- CPU 집중 프로세스: 수한 연산과 같이 CPU를 많이 사용하는 프로세스 (CPU 버스트가 많은 프로세스)
- 입출력 집중 프로세스: 저장장치에서 데이터를 복사하는 일과 같이 입출력을 많이 사용하는 프로세스 (입출력 버스트가 많은 프로세스)
- 입출력 집중 프로세스는 CPU를 많이 안쓰기 때문에, 먼저 처리하면 시스템의 효율을 높일 수 있습니다.
위에서 설명한 목적과 고려사항 중에서 어떤 것을 얼마나 고려하는지에 따라 다양하게 스케줄러를 구현할 수가 있는데요. 그럼 다양한 스케줄링 알고리즘 중에서 어떤 것을 선택하는 게 좋을까요? 이제부턴 선택 기준과 알고리즘에 대해 살펴보겠습니다😀
스케줄링 알고리즘
선택 기준
운영체제마다 다르겠지만, 알고리즘을 선택할 때 고려할 수 있는 기준에 대해 설명드리고자 합니다.
- CPU 사용률: 전체 시스템의 동작 시간 중 CPU가 사용된 시간을 측정하는 방법
- 처리량: 시스템이 정상적으로 작동한다면 일정 시간 후 작업이 끝난다. 처리량은 단위 시간당 작업을 마친 프로세스의 수로, 이 수치가 클수록 좋은 알고리즘이다.
- 대기 시간: 작업을 요청한 프로세스가 작업을 시작하기까지 대기하는 시간. 짧을수록 좋다.
- 응답 시간: 프로세스 시작 후 첫 번째 출력 또는 반응이 나올 때까지 걸리는 시간. 짧을수록 좋다.
- 반환 시간: 대기 시간 + 실행 시간. 프로세스가 생성된 후 종료되어 사용하던 자원을 모두 반환하는데까지 걸리는 시간
아래에서 스케줄링 알고리즘을 설명할 때는 대기 시간을 기준으로 살펴보겠습니다.
선점형 vs 비선점형
스케줄링은 <한 프로세스가 CPU를 차지하고 있을 때 운영체제가 이를 빼앗을 수 있느냐 없느냐>에 따라 "비선점형"과 "선점형" 방식으로 나뉠 수 있기 때문에, 해당 개념부터 이해해야합니다.
- 선점형 스케줄링: 어떤 프로세스가 CPU를 받아 실행 중일 때 운영체제가 CPU를 강제로 빼앗을 수 있는 스케줄링 방식
- 비선점형 스케줄링: 어떤 프로세스가 CPU를 받아 실행 중일 때 운영체제가 CPU를 강제로 빼앗을 수 없는 스케줄링 방식
스케줄링 알고리즘을 위의 기준에 따라 분류한 표입니다.

이제부터 본격적으로 스케줄링 알고리즘을 살펴보겠습니다!
비선점형 알고리즘
1. FCFS(First Come First Served) 스케줄링
-
FIFO(First In First Out) 라고도 하는데, 이는 큐를 가리키는 말이기 때문에, 이와 구분하기 위해 스케줄링 알고리즘에서는 FCFS라고 부릅니다.
-
스케줄링 준비 큐에 도착한 순서대로 CPU를 할당하는 비선점형 방식으로 큐가 하나라 모든 우선순위가 동일합니다.
[ 단점 ]
-
처리 시간이 긴 프로세스가 있다면 이를 처리하느라 다음 프로세스의 대기 시간이 길어질 수 있습니다. 이처럼 앞의 작업이 오래 걸려 뒤의 작업이 지연되는 현상을 콘보이 효과(convoy effect) 또는 호위 효과라고 합니다.
-
현재 작업 중인 프로세스가 입출력 작업을 요청하는 경우 CPU가 작업하지 않고 쉬는 시간이 늘어납니다.
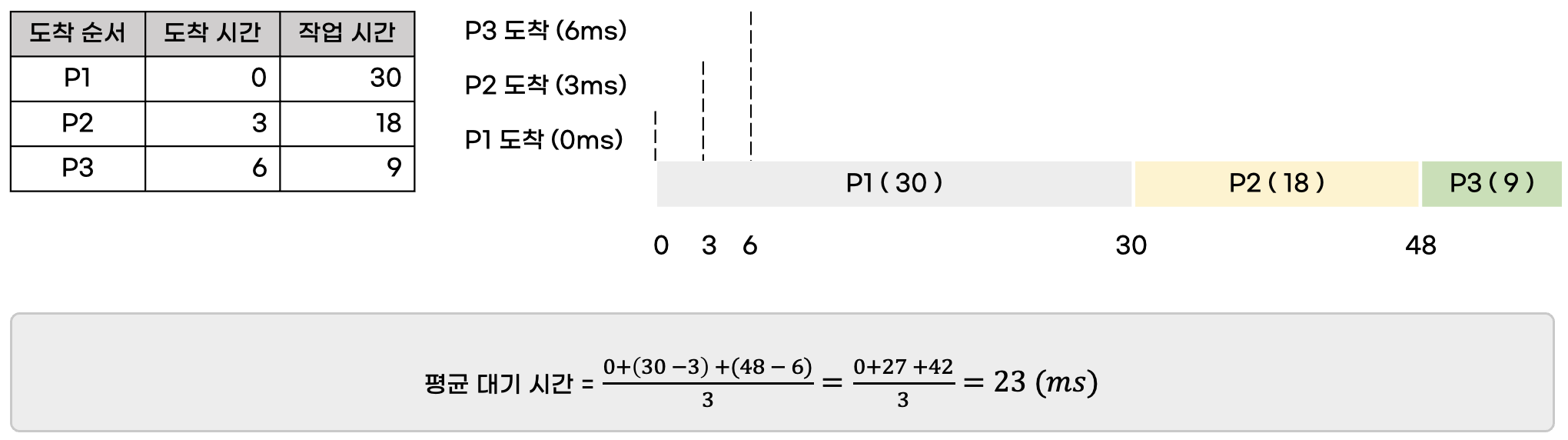
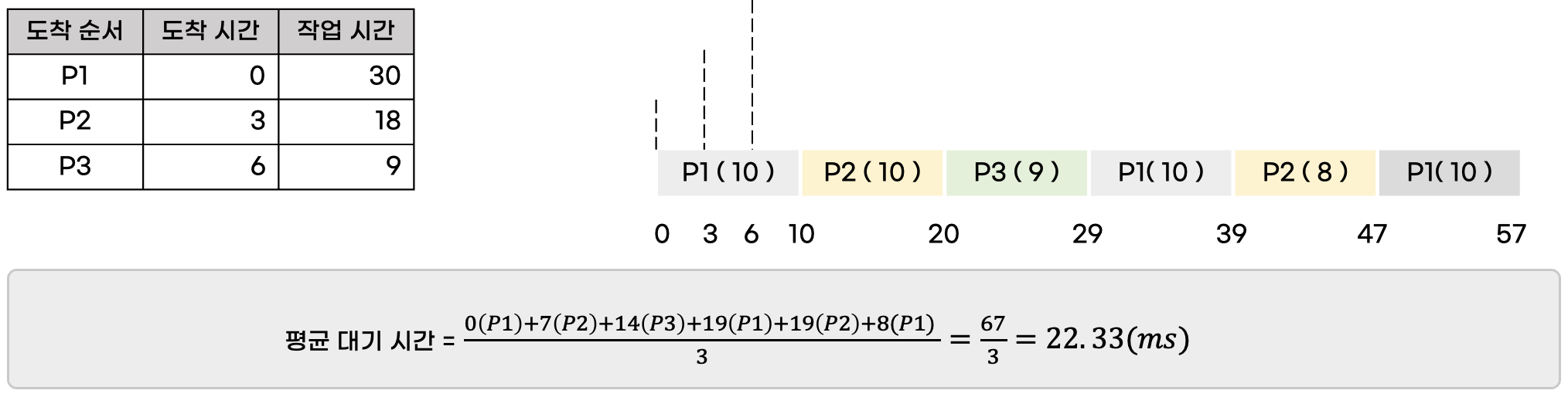
[ 예시 ]
아래 첨부한 그림과 같이 0초, 3초, 6초에 도착하는 프로세스 3개가 있을 때 대기 시간을 계산해보면 총 23초가 나옵니다.
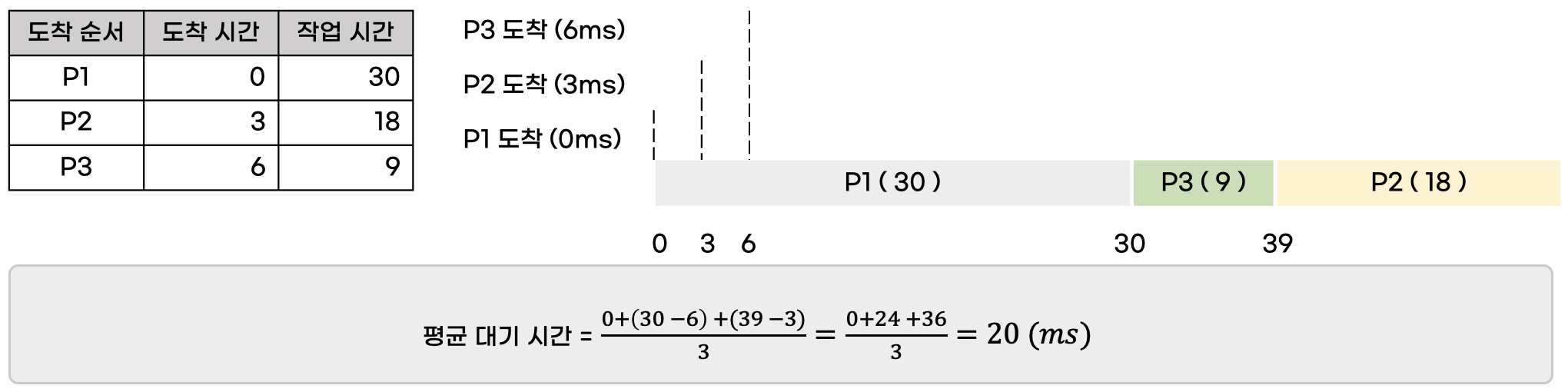
2. SJF(Short Job First) 스케줄링
- SPF(Shortest Process First) 또는 최단 프로세스 우선 스케줄링이라고 합니다.
- 실행 시간이 가장 짧은 작업부터 CPU를 할당하는 비선점형 방식입니다.
- 콘보이 효과를 완화하여 시스템의 효율을 높입니다.
[ 단점 ] - 운영체제가 프로세스의 종료 시간을 정확하게 예측하기 어렵습니다. 특히 현대의 프로세스는 사용자와 상호작용이 많기 때문에 예측이 어렵습니다. 이는 프로세스가 자신의 작업 시간을 운영체제에 알려주면 해결이 가능하지만, 프로세스 또한 자신의 작업 시간을 정확히 알기 어렵습니다.
- 먼저 들어왔음에도 실행 시간이 짧은 프로세스에 의해 계속 뒤로 밀릴 수 있습니다. 이를 "아사(starvation) 현상" 또는 "무한 봉쇄(infinite blocking)" 현상이라고 합니다. 이는 에이징(aging)으로 완화할 수 있다. 에이징은 프로세스가 양보할 수 있는 상한선을 정하는 방식입니다.
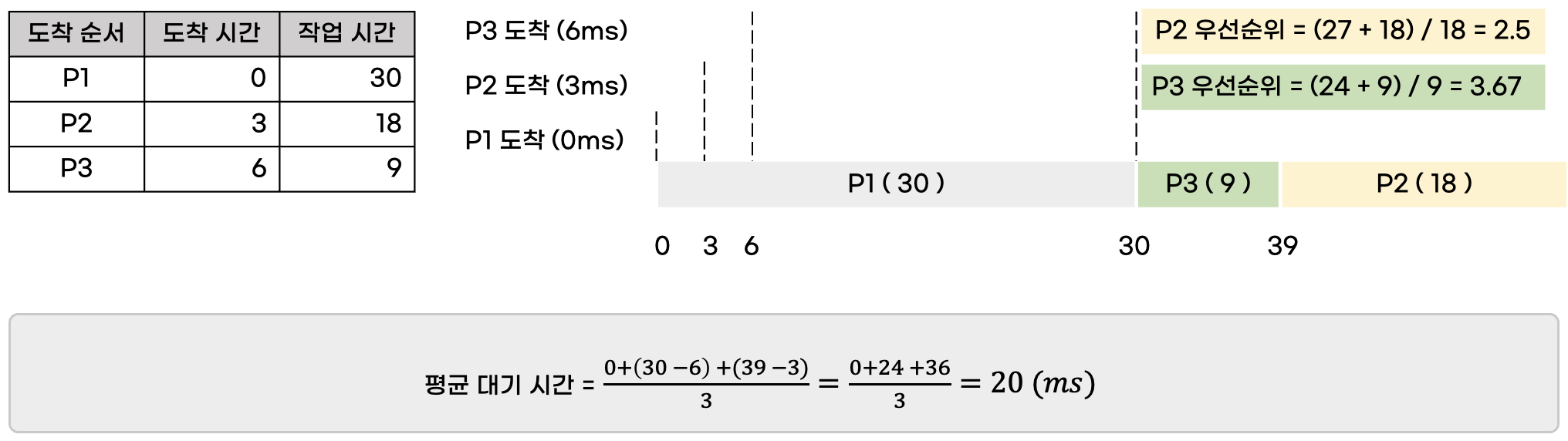
3. HRN(Highest Response Ration Next) 스케줄링
- 아사 현상을 해결하기 위해 만들어진 비선점형 알고리즘으로 최고 응답률 우선 스케줄링이라고도 합니다.
- HRN 스케줄링에서는
(대기 시간 + CPU 사용 시간) / CPU 사용 시간으로 우선순위를 결정합니다. - 대기 시간을 고려함으로써 아사 현상을 완화시킵니다. 해당 스케줄링에서는 숫자가 클수록 우선순위가 높습니다.
[ 단점 ] - 아사 현상은 완화되지만, 여전히 공평성이 위배되어 많이 사용되지 않는다고 합니다.
선점형 알고리즘
1. Round Robin 스케줄링
- 시분할 시스템을 위해 설계된 스케줄링의 하나로서, 프로세스들 사이에 우선순위를 두지 않고, 타임 슬라이스(=Time Quantum)로 CPU를 할당하는 방식입니다.
(참고: Wikipedia) - 선점형 알고리즘 중 우선순위가 적용되지 않은 가장 단순하고 대표적인 방식으로, 프로세스들이 작업을 완료할 때까지 계속 순환하면서 실행된다. 따라서 순환 순서 방식이라고도 불립니다.
- 앞의 긴 작업을 무작정 기다리는 콘베이 효과가 줄어듭니다.
[ 단점 ] - 타임 슬라이스에 따라 성능이 달라집니다.
- 타임 슬라이스를 너무 작게 설정할 경우 문맥 교환이 자주 일어나게 돼서 문맥 교환에 걸리는 시간이 실제 작업 시간보다 길어질 수 있습니다.
- 타임 슬라이스를 너무 크게 설정할 경우 FCFS 알고리즘과 다를 게 없으며 이 경우 FCFS의 단점과 동일하게 콘보이 효과가 발생하게 됩니다.
- 위의 2가지 이유로 인해 타임 슬라이스 시간을 적절하게 설정하는 것이 중요하지만, 정확하게 완벽한 시간을 찾는 것은 어렵습니다.
2. SRT(Shortest Remaining Time) 스케줄링
- SJF 스케줄링과 라운드 로빈 스케줄링을 혼합한 방식으로 "최소 잔류 시간 우선 스케줄링"이라고도 합니다. 쉽게 말해 SJF 스케줄링의 선점형 버전이라고 할 수 있습니다.
- CPU를 할당받을 프로세스를 선택할 때 남아 있는 작업 시간이 가장 적은 프로세스를 선택합니다.
- 라운드 로빈 스케줄링이 큐에 있는 순서대로 CPU를 할당한다면, SRT 스케줄링은 남은 시간이 적은 프로세스에 CPU를 먼저 할당합니다.
[ 단점 ] - 현재 실행 중인 프로세스와 큐에 남아 있는 프로세스의 남은 시간을 주기적으로 계산하고 남은 시간이 더 적은 프로세스와 문맥 교환을 해야한다는 단점이 있습니다.
- SJF 스케줄링과 마찬가지로 운영체제가 프로세스의 종료 시간을 예측하기 어렵고 아사 현상이 일어나기 때문에 잘 사용하지 않는다고 합니다.

3. 다단계 큐(Multiple Queue) 스케줄링
- 우선순위에 따라 큐를 나눠 스케줄링합니다.
- 우선순위는 고정형 우선순위를 사용하며, 상단의 큐에 있는 모든 프로세스가 실행되어야 다음 우선순위 큐의 작업이 시작됩니다.
[ 단점 ] - 우선순위가 높은 프로세스 때문에 우선순위가 낮은 프로세스의 작업이 연기되는데 이러한 문제를 해결하기 위해 제안된 것이 다단계 피드백 큐 스케줄링입니다.

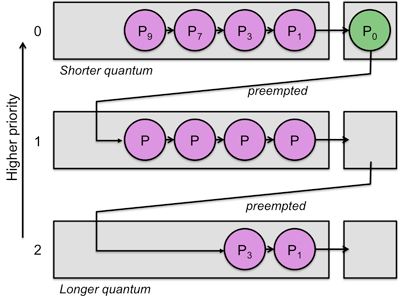
4. 다단계 피드백 큐(Multilevel Feedback Queue) 스케줄링
- CPU를 사용하고 나면 우선순위가 낮아집니다.
- 우선순위에 따라 타임 슬라이스가 달라집니다.
- 우선순위가 낮은 프로세스를 위한 기회를 확대하긴 했지만, 그럼에도 여전히 우선순위가 높은 프로세스에 비해 CPU를 얻을 확률이 낮습니다. 따라서 어렵게 얻은 CPU를 오래 사용할 수 있도록 우선순위가 낮을수록 타임슬라이스를 크게 설정합니다.
- 다단계 피드백 큐 스케줄링은 오늘날의 운영체제가 CPU 스케줄링을 위해 사용하는 일반적인 방식으로 변동 우선순위 알고리즘의 대표적인 예시 입니다.
그렇다면 실제로 운영체제는 어떤 알고리즘을 선택하여 사용하고 있을까요? 이제부턴 실제 사용 사례에 대해 소개해드리려 합니다.
스케줄링 알고리즘 사용 예시
운영체제별 사용하는 알고리즘
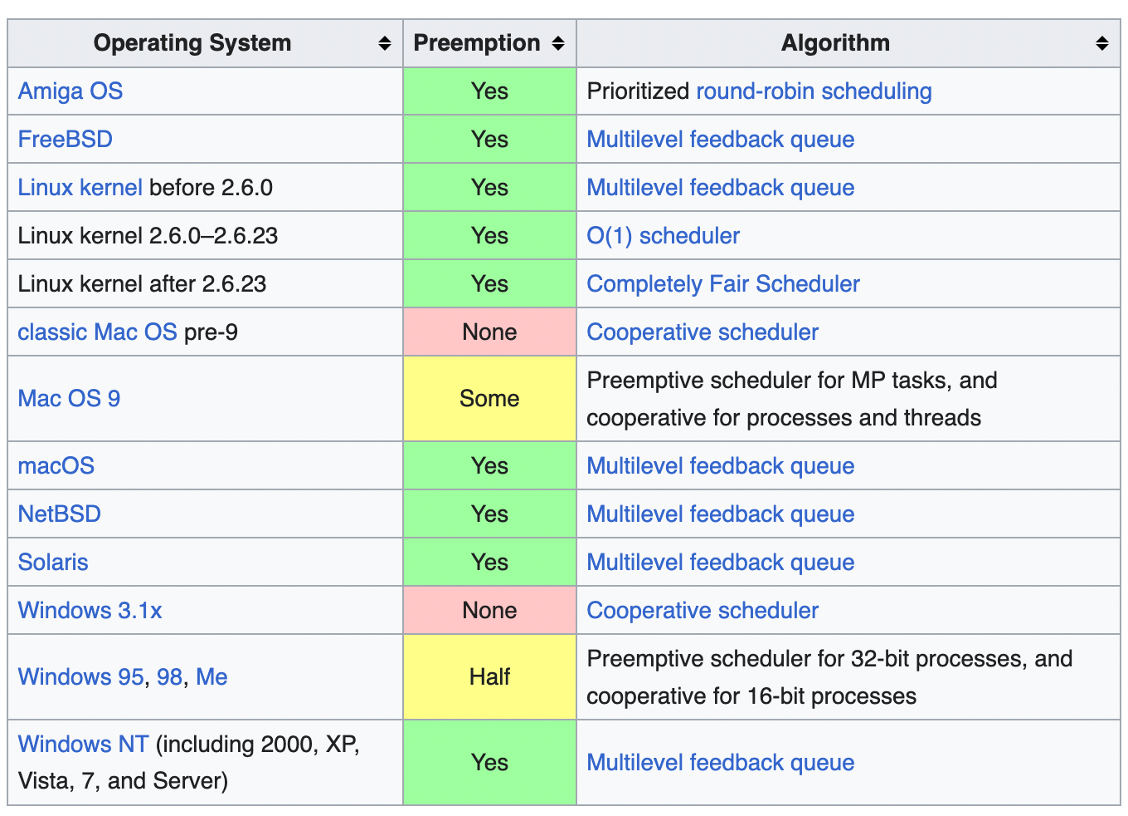
많은 운영체제에서 다단계 피드백 큐를 사용하고 있는데요. 그 외 몇 가지 낯선 알고리즘 중에서 리눅스에서 사용하고 있는 알고리즘에 대해 좀 더 살펴보도록 하겠습니다.
리눅스에서 사용하는 알고리즘

Linux 2.4
- Linux 2.4에서는 우선순위의 범위가 0부터 140인 다단계 피드백 큐가 있는 O(n) 스케줄러가 사용되었습니다. (0-99는 real-time task용으로 예약되어 있고 100에서 140은 nice task 레벨로 간주된다.)
- 스케줄러는 준비된 모든 프로세스들의 run queue를 통해 실행되며, 우선순위가 높은 프로세스부터 실행되고 그들의 time slice만큼 실행된 후에 expired queue로 옮겨집니다.
- run queue는 ready queue와 동일한 의미이며, 활성화된 프로세스들이 모여있는 큐입니다. 각각의 프로세스를 위한 우선순위 값을 포함하고 있습니다. 이는 active queue와 expired queue로 구성됩니다.
- active queue의 모든 작업이 끝나면 expired queue가 active queue가 됩니다.
- SUSE Linux Enterprise Server와 같은 몇몇 기업용 Linux distribution들은 이 스케줄러를 O(1) 스케줄러의(Linux 2.4-ac Kernel 시리즈에서 Alan Cox가 유지 보수하고 있는) backport로 대체했습니다.
- real-time task에서 프로세스를 전환하기 위한 시간 텀은 약 200ms이고, nice task를 위한 시간 텀은 10ms입니다.
Linux 2.6.0 ~ Linux 2.6.22
- 2.6.0부터 2.6.22까지의 버전에서 커널은 Linux 2.5 개발 중에 Ingo Molnar과 다른 많은 커널 개발자가 개발한 O(1) 스케줄러를 사용했습니다.
- O(1) 스케줄러는 운영체제에서 실행중인 프로세스의 수와 관계없이 일정한 시간 내에 프로세스를 스케줄링 할 수 있도록 고안된 커널 스케줄링 설계입니다.
- O(n) 스케줄러와 마찬가지로 run queue에서 active와 expired 배열을 사용하며, active 배열에서 선택된 프로세스는 실행 후 expired 배열로 이동합니다.
Linux 2.6.23
-
O(1) 스케줄러의 작성자인 Ingo Molnar은 Con Kolivas의 Staircase scheduler에 포함되어 있던 RDSL(Rotating Stairecase Deadline Scheduler)에서 영감을 받아 Completely Fair Scheduler(CFS)를 만들었다고 합니다.
-
Completely Fair Scheduler(CFS)의 기본 개념은 프로세스의 시간을 제공할 때 공평성을 유지하는 것입니다.
-
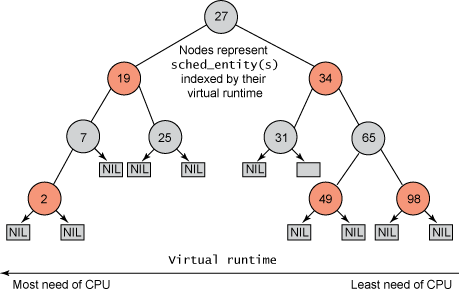
run queue는 red-black tree로 구현되어 있기 때문에 task를 고르는 것은 정해진 시간 안에 수행이 가능하지만, 실행 후 다시 삽입하는 것은 O(logN) 연산을 필요로 합니다.
-
red-black tree는 아래 첨부한 그림과 같은 구조로 되어 있으며, "가상 런타임"을 기준으로 정렬된 트리입니다. 스스로 정렬한다는 특징이 있기 때문에 밸런스를 유지하기 위해 적합한 구조입니다. 스케줄러는 가상 런타임이 가장 낮은 작업, 즉 가장 왼쪽에 있는 작업을 다음에 실행할 노드로 선택합니다.
참고
- 프로세스 스케줄링의 전반적인 개념 – [책] 쉽게 배우는 운영체제 | 한빛아카데미
- 용어 정리 > 스케줄링, 디스패처
https://en.wikipedia.org/wiki/Scheduling_(computing) - 용어 정리 > 스케줄러
https://www.tutorialspoint.com/operating_system/os_process_scheduling.htm - 리눅스 커널 스케줄링
- “[ Linux Kernel ] 14. Kernel-Scheduling(커널 스케쥴링)”: https://coder-in-war.tistory.com/entry/Embedded-21-Linux-Kernel-Kernel-Scheduling%EC%BB%A4%EB%84%90-%EC%8A%A4%EC%BC%80%EC%A5%B4%EB%A7%81
- ”리눅스 커널 스케줄러”: http://cloudrain21.com/linux-kernel-scheduler
- CFS
https://dataonair.or.kr/db-tech-reference/d-lounge/technical-data/?mod=document&uid=236896 - 라운드로빈 알고리즘 단점
https://data-flair.training/blogs/round-robin-scheduling-algorithm/
[ 참고하려 했던 자료(읽어보면 좋을 듯함) ]
- “Linux Schedling”: https://www.cse.iitd.ac.in/~rijurekha/col788/scheduling1.pdf
- 실시간 시스템과 실시간 스케줄링: https://eunajung01.tistory.com/67 (실시간 시스템에서는 작업 수행이 제한된 시간 안에 처리하여 결과를 반환해주어야한다. 실시간 스케줄링 알고리즘이란 동시에 여러 태스크가 존재할 때 해당 태스크들의 수행 순서를 정하는 것이다.)
이미지 출처
- 다단계 큐, 다단계 피드백 큐 설명에서 사용된 구조 사진
https://people.cs.rutgers.edu/~pxk/416/notes/07-scheduling.html - 운영체제별 사용하는 알고리즘
https://en.wikipedia.org/wiki/Scheduling_(computing)#Summary - red-black 트리
