Target Table :
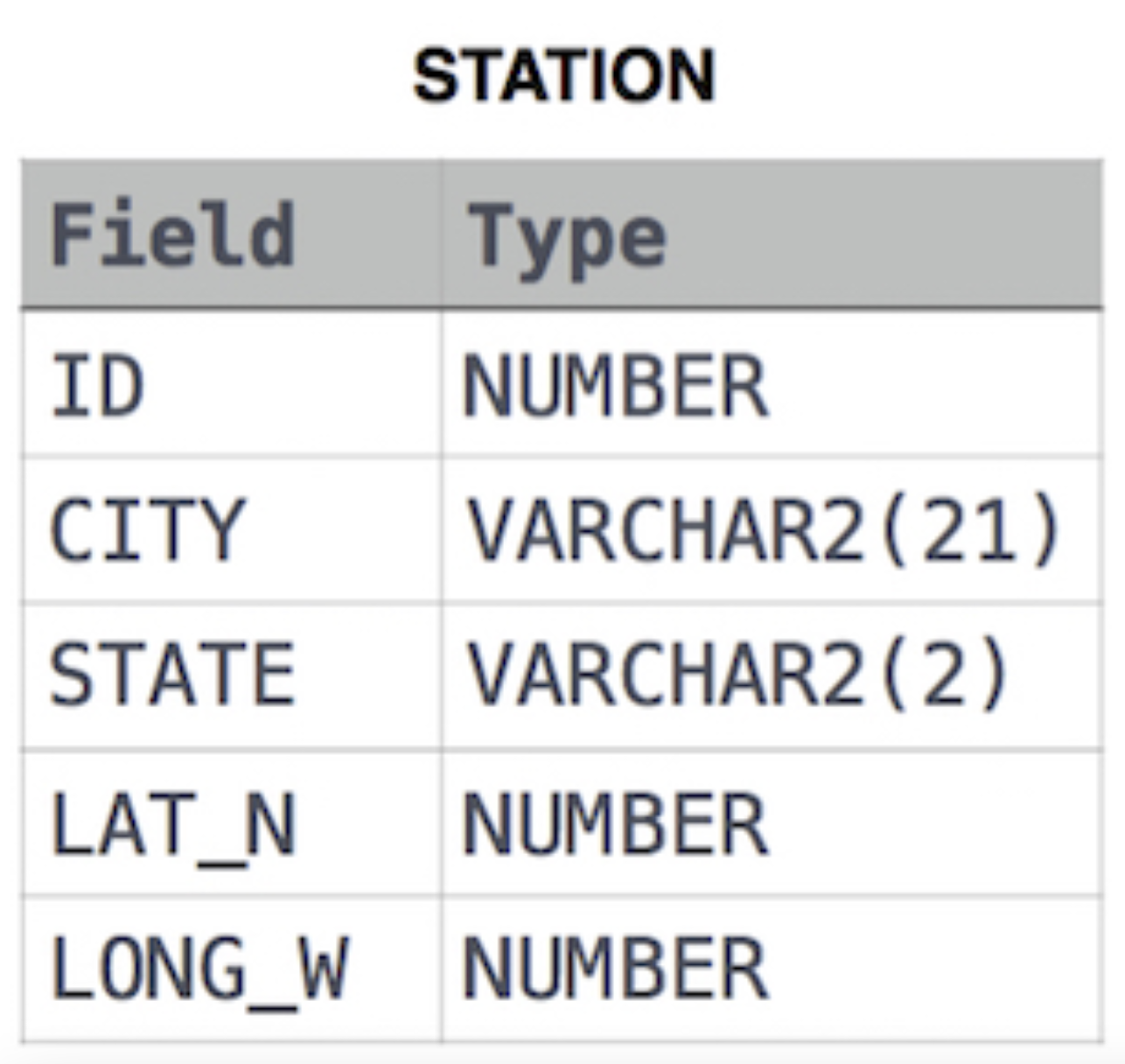
Q1) Query a list of CITY names from STATION for cities that have an even ID number. Print the results in any order, but exclude duplicates from the answer.
STATION에서 도시 이름 목록을 쿼리하여 ID 번호가 짝수인 도시를 찾습니다. 결과를 임의의 순서로 인쇄하되 중복된 항목은 답변에서 제외
A1)
SELECT DISTINCT city FROM station
where MOD(id,2) = 0DISTINCT : 중복을 제거하는 키워드.
MOD(컬럼,n) : 컬럼의 값을 N으로 나눈 몫을 구하는 함수
Q2) Find the difference between the total number of CITY entries in the table and the number of distinct CITY entries in the table.
표의 총 CITY 항목 수와 표의 고유한 CITY 항목 수 사이의 차이를 구하세요.
A2)
SELECT count(*) - count(distinct city) FROM station⭐️ COUNT() 함수에 대하여 ⭐️
단순히 count 라고 하면 컬럼의 수를 카운팅 해주는 단순한 함수라고 생각할 수 있지만 Query문에서 사용할경우 다양하게 사용하고,사용되기에 짤막하게 정리를 하며 다시 한번 상기시켜보자.
COUNT(*)
: 테이블의 모든 ROW의 수를 샌다
COUNT("column")
: 테이블의 column 이 Not Null 인 ROW의 수만 샌다.
COUNT(DISTINCT column)
: 해당 컬럼의 중복을 제거하고 Not Null 인 ROW의 수를 샌다.
COUNT(DISTINCT CASE WHEN condition THEN result)
: 조건에 해당되는 column의 Not Null 인 Row의 수를 샌다.
Q3) Query the two cities in STATION with the shortest and longest CITY names, as well as their respective lengths (i.e.: number of characters in the name). If there is more than one smallest or largest city, choose the one that comes first when ordered alphabetically.
STATION에서 가장 짧은 도시와 가장 긴 도시 이름과 각각의 길이(즉, 이름의 글자 수)를 가진 두 도시를 쿼리하세요. 가장 작거나 큰 도시가 두 개 이상인 경우 알파벳순으로 정렬했을 때 가장 먼저 오는 도시를 선택합니다.
A3)
select city,length(city)
from station
order by length(city),city
limit 1;
select city,length(city)
from station
order by length(city) desc, city
limit 1;문제에 대해서 해석을 잘하지 못해 좀 고생했던 문제이다... ( 영어 공부도 해야겠다..)
기본적으로 쿼리를 단순히 조회하면 정렬되지 않기 때문에 ORDER BY 를 통해 정렬이 필요하고 어떻게 정렬할지 생략할경우 오름차순이 기본값으로 설정되어 있기 때문에 필요에 따라 선택하여 사용하여야 한다 ( ASC,DESC )
여기서는 도시이름의 길이를 정렬했으며 도시이름의 길이가 동일한경우 알파벳순으로 앞선것을 가져와야 했기 때문에 다음과 같이 정렬기준을 잡아 사용하였다.
Q4) Query the list of CITY names starting with vowels (i.e., a, e, i, o, or u) from STATION. Your result cannot contain duplicates.
STATION에서 모음(예: a, e, i, o 또는 u)으로 시작하는 도시 이름 목록을 쿼리합니다. 결과에는 중복된 항목이 포함될 수 없습니다.
A4)
select distinct city
from station
where city
like "a%" or
city like "e%" or
city like "o%" or
city like "u%" or
city like "i%";비슷한 문제의 연속이였고, 어떤 문자로 시작하는지 끝나는지 조회하기 위해서 LIKE 키워드와 % 매직키워드를 사용하였다.
LIKE : WHERE 절에 주로 사용되며, 부분적으로 일치하는 값을 찾을 때 주로 사용한다.
% : 모든 문자
예를들면 SELECT NAME FROM FOOD WHERE NAME LIKE "%라면%" 이라는 쿼리를 실행하면 "삼양라면삼양" 처럼 라면 앞뒤로 문자가 존재하는 Row를 조회하고
SELECT NAME FROM FOOD WHERE NAME LIKE "라면%" 을 실행할경우
"라면삼양" 처럼 라면 뒤에 문자가 존재하는 Row를 조회.
SELECT NAME FROM FOOD WHERE NAME LIKE "%라면" 을 실행할경우
"삼양라면" 처럼 라면 앞에 문자가 존재하는 Row를 조회.
_(underbar) : 한글자
SELECT NAME FROM FOOD WHERE NAME LIKE "라면" 을 실행할경우
"진라면진" 처럼 라면 앞뒤에 문자가 존재하는 Row를 조회.
SELECT NAME FROM FOOD WHERE NAME LIKE "라면" 을 실행할경우
"라면진" 처럼 라면 뒤에 문자가 존재하는 Row를 조회.
SELECT NAME FROM FOOD WHERE NAME LIKE "_라면" 을 실행할경우
"진라면" 처럼 라면 뒤에 문자가 존재하는 Row를 조회.
Q5)Query the list of CITY names from STATION which have vowels (i.e., a, e, i, o, and u) as both their first and last characters. Your result cannot contain duplicates.
모음이 첫 번째와 마지막 문자로 모두 모음(예: a, e, i, o, u)인 STATION의 도시 이름 목록을 쿼리합니다. 결과에는 중복된 항목이 포함될 수 없습니다.
A5)
select DISTINCT CITY
from station
where left(city,1) in ('a','e','i','o','u')
and right(city,1) in ('a','e','i','o','u')4번 유형과는 다르게 모음으로 시작하여 모음으로 끝나는 경우를 조회하는 경우 이기 때문에 매우 많은 경우의 수가 발생하여 시작하는 문자, 끝나는 문자를 검색하기 위해 LEFT,RIGHT 라는 함수를 사용하여 해당 값이 모음의 경우에 속하는지 검사한다음 조회하는 방식으로 해결하였다.
LEFT(COL,n) : 해당 Col 값에서 왼쪽에서부터 n번째 까지의 값을 가져온다.
