Q) Pivot the Occupation column in OCCUPATIONS so that each Name is sorted alphabetically and displayed underneath its corresponding Occupation. The output column headers should be Doctor, Professor, Singer, and Actor, respectively.
Note: Print NULL when there are no more names corresponding to an occupation.
직업에서 직업 열을 피벗하여 각 이름이 알파벳순으로 정렬되고 해당 직업 아래에 표시되도록 합니다. 출력 열 머리글은 각각 의사, 교수, 가수, 배우가 되어야 합니다.
참고: 직업에 해당하는 이름이 더 이상 없는 경우 NULL을 출력합니다.
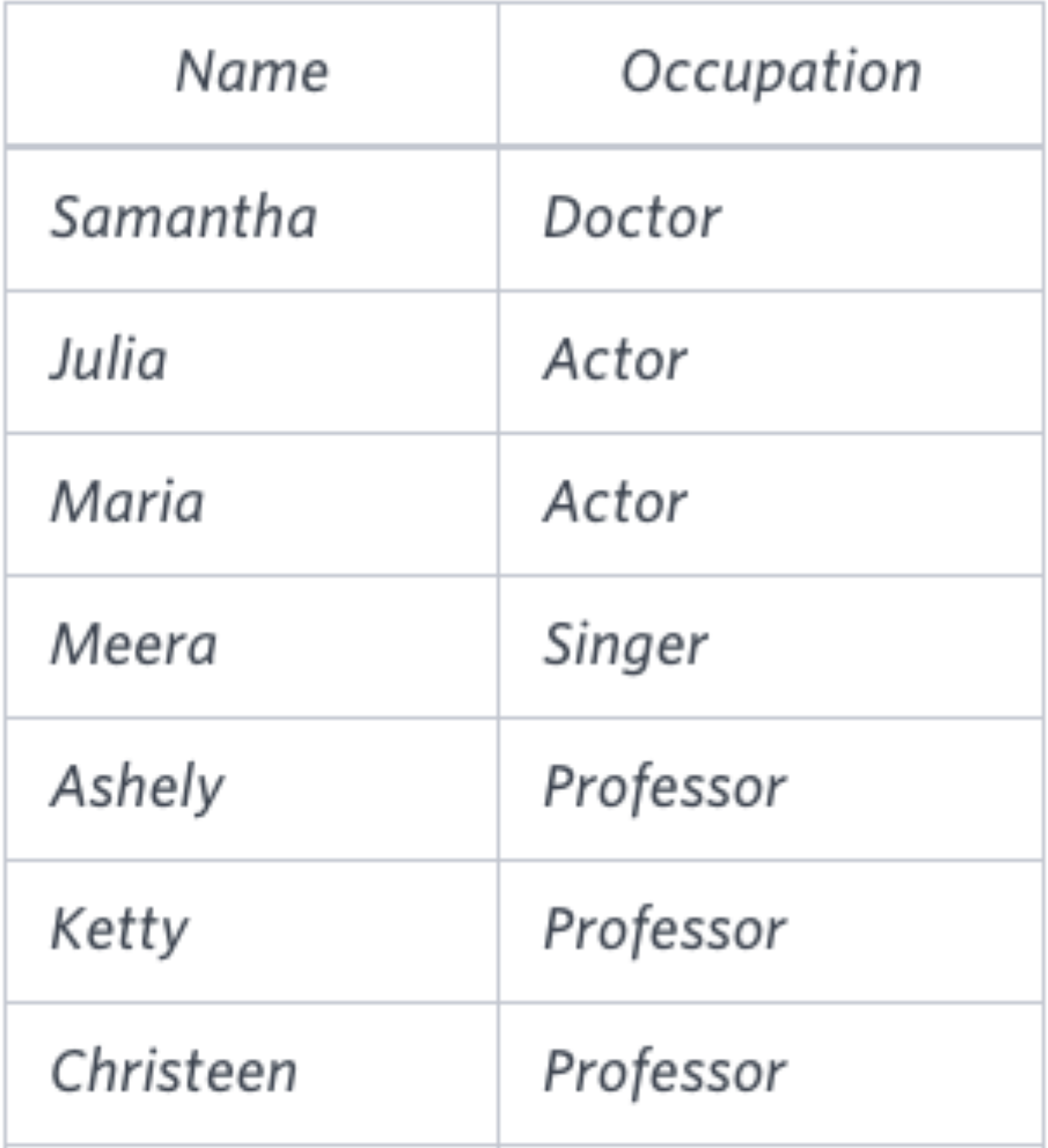
Sample Output
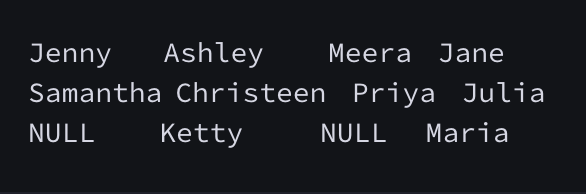
Explation
The first column is an alphabetically ordered list of Doctor names.
The second column is an alphabetically ordered list of Professor names.
The third column is an alphabetically ordered list of Singer names.
The fourth column is an alphabetically ordered list of Actor names.
The empty cell data for columns with less than the maximum number of names per occupation (in this case, the Professor and Actor columns) are filled with NULL values.
첫 번째 열은 알파벳 순으로 나열된 의사 이름 목록입니다.
두 번째 열은 알파벳순으로 나열된 교수 이름 목록입니다.
세 번째 열은 알파벳 순으로 나열된 가수 이름 목록입니다.
네 번째 열은 알파벳순으로 나열된 배우 이름 목록입니다.
직업별 최대 이름 수보다 적은 열(이 경우 교수 및 배우 열)의 빈 셀 데이터는 NULL 값으로 채워집니다.
A)
-- doctor,professor,singer,actor
select
MAX(case when occupation = 'Doctor' then name end) as 'Doctor',
MAX(case when occupation = 'Professor' then name end) as 'Professor',
MAX(case when occupation = 'Singer' then name end) as 'Singer',
MAX(case when occupation = 'Actor' then name end) as 'Actor'
from (
select ROW_NUMBER() OVER(PARTITION BY Occupation ORDER BY name) as rownumber
,occupation
,name
from OCCUPATIONS
) as tmptable
group by rownumber
order by rownumber;우선 쿼리의 첫번째 동작이 되는 쿼리문을 살펴보자
select ROW_NUMBER() OVER(PARTITION BY Occupation ORDER BY name) as rownumber,
occupation,
name
from OCCUPATIONSROW_NUMBER()
해당 함수는 결과 집합의 각 행에 고유한 순서 번호를 부여하고,이 번호는 지정된 기준에 따라 생성된다.
우선 이 함수를 사용한 이유는 이 함수를 사용하면 각 직업(occupation) 내에서 이름(name)을 알파벳 순으로 정렬하고, 각 이름에 번호를 부여할 수 있게된다.
이를 통해 각 직업별로 이름을 그룹화하고, 나중에 피벗 테이블을 만들 때 각 직업의 이름을 정렬된 상태로 가져올 수 있기 때문에 해당 함수를 사용하였다.
PARTITION BY()
PARTITION BY 절은 결과 집합을 특정 열을 기준으로 그룹으로 나누어 각 그룹 내에서 ROW_NUMBER() 등의 집계 함수가 적용되도록 할 수 있다.
이 함수를 사용한 이유는 occupation을 기준으로 그룹을 나누어 각 직업 내에서 이름을 정렬하고 번호를 부여하고, 이를 통해 각 직업에 대해 독립적으로 번호를 매길 수 있기때문에 사용하였다.
ORDER BY()
테이블 결과를 정렬하기 위해 사용되며, 여기선 각 직업 내에서 이름을 알파벳 순서로 표현하기 위해서 이 함수를 사용하였다.
예를들어 다음과 같은 테이블이 있고, 위 쿼리를 사용했다고 하면 해당 쿼리는 다음과 같은 결과를 얻을 수 있다.
| name | occupation |
|---|---|
| Alice | Doctor |
| Bob | Doctor |
| Jone | Singer |
| Mike | Actor |
| Emily | Singer |
- 위 쿼리를 실행한 결과는 다음과 같은 결과를 얻을 수 있음.
| rownumber | occupation | name |
|---|---|---|
| 1 | Doctor | Alice |
| 2 | Doctor | Bob |
| 1 | Singer | Emily |
| 2 | Singer | Jone |
| 1 | Actor | Mike |
이처럼 직업(occupation)을 기준으로 그룹을 나눠 이름을 기준으로 정렬을 하여 번호를 부여하여 직업별로 정렬된 이름의 순서 정보를 얻기 위해 ROW_NUMBER() PARTITION BY() 를 활용할 수 있다.
즉, ROW_NUMBER()를 이용해 각 행에 고유 번호를 부여하고,
PARTITION BY()를 이용해 직업별로 그룹화하고,
ORDER BY() 를 통해 이름을 알파벳 순으로 정렬하였다.
이 후 사용된 2번째 쿼리를 살펴보자
select
MAX(case when occupation = 'Doctor' then name end) as 'Doctor',
MAX(case when occupation = 'Professor' then name end) as 'Professor',
MAX(case when occupation = 'Singer' then name end) as 'Singer',
MAX(case when occupation = 'Actor' then name end) as 'Actor'
from (
...
) as tmptable
group by rownumber;이와 같은 쿼리의 형태는 피벗테이블 형태로 만들기 위한 쿼리형태다.
마찬가지로 하나씩 뜯어서 봐보자.
MAX(CASE WHEN ...)
CASE 문은 조건에 따라 다른 값을 표현하는 조건부 표현식이고, MAX() 함수는 지정된 값 중 가장 큰 값을 찾아내는 함수이다.
이들을 사용한 이유는 각 직업에 대한 이름들을 선택하고 그 이름이 NULL 이 아닌 경우에만 반환되고, MAX() 함수를 통해 그룹화된 결과에서 유일한 값을 가져오게 된다. 즉 해당 직업에서 가장 높은 값을 가져오는 형태로 동작하게 된다.
이렇게 말로 풀어놓으니 이해가 잘안되는거같아 예시를 하나 들어봐보자.
만약에 다음과 같은 테이블에 다음과 같이 쿼리를 동작시켰다면
| rownumber | occupation | name |
|---|---|---|
| 1 | Doctor | Alice |
| 2 | Doctor | Bob |
| 1 | Singer | Emily |
| 1 | Actor | Mike |
| ... | ... | ... |
SELECT
MAX(CASE WHEN occupation = 'Doctor' THEN name END) AS 'Doctor'
FROM
tmptable
GROUP BY rownumber;위 쿼리는 rownumber가 1인 경우 Doctor 직업에 대한 Alice 를 선택하고, rownumber가 2인경우 Doctor 직업에 대한 Bob 을 선택한다.
즉 CASE 문과 MAX() 문을 이용해서 각 직업별로 이름을 열로 변환시키고, GROUP BY 절을 통해 각 직업의 이름을 행으로 나열하는 피벗테이블로 생성하고, 없을 경우 NULL 을 반환하도록 구현할 수 있다.
이러한 구현방식은 SQL 을 이용해 피벗테이블을 구성하는 방식이므로 기억해두고 있는게 좋다.
다시말해 이러한 구현방식이라 함은 피벗테이블을 구현하기 위해선 피벗의 컬럼(Column)이 되어줄 Key를 지정해줘야 하고 그 방법은 MAX(CASE WHEN ...) 방식으로 구현할 수 있다.
Advanced Select 문제로 넘어가다 보니 생각보다 어려운(?) 문제가 많이 나오는 것 같다.
실제로 회사생활을 할 때 사용하던 간단하게 Select, Join 문들을 사용할 때와 다른 유형의 문제가 나타나 새로 알게되는게 많은것 같다.
