학습 목표
- Big O Notation 의 필요성에 대해 이해한다
- Big O Notation 이 무엇인지 설명할 수 있다
- 시간복잡도(time complexity) 와 공간복잡도(space complexity) 의 정의에 대해 이해한다
- Big O Notation 을 이용해서 특정 알고리즘의 시간복잡도와 공간복잡도를 도출해 낼 수 있다
Big O Notation 왜 쓰는가?
오늘 동해바다에서 지진이 발생했다고 가정해보자
우리는 진도를 통해 지진의 크기를 비교한다. 만약 진도가 없다면 "오늘 동해에 심한 지진이 생겼다는데?" 에서 "심한" 처럼 주관적인 언어로 비교를 하게 되어 때에 따라 소통오류가 생길 수도 있을것이다.
하지만 진도가 있기 때문에, 뉴스에서 진도 3.5의 지진이 발생했다고 나올때와, 7의 지진이 발생했다고 했을때의 차이를 우리는 직감적으로 이해할 수 있다.
자 다시 컴퓨터의 세계로 돌아와서, 우리는 하나의 문제를 해결하기 위해서 여러 방식의 알고리즘을 만들 수 있다. 그렇다면 각각의 알고리즘 중 "최선의" 알고리즘이 무엇인지 어떻게 결정할 수 있을까?
우리는 Big-O Notation을 이용해서 특정 알고리즘에서 input이 증가함에 따라 runtime이 어떻게 변화하는지를 보다 더 formal한 방식으로 표현할 수 있다.
(진도의 예시와 다른점이 있다면, Big-O는 구체적인 수치를 나타내지 않고 general trend를 보여준다)
Big-O 단순화하기
1. 시간복잡도 (time complexity) : input의 변화가 runtime에 주는 영향을 표현한다

- 위의 그림에서, addUpTo 함수는 for문 밖에 2개의 작업과 for문 내부에서 5개의 작업을 n번 순회하고 있다. -> 5n + 2
- 대략적으로 n에 비례하여 작업량이 변화한다
- 만약 n의 값이 2배이면, 작업 횟수도 대략적으로 2배가 된다


-
Big-O Notation을 사용할때, 아래와 같이 단순화하여 사용한다.
-
O(2n) → O(n)
-
O(500) → O(1)
-
O(13n²) → O(n²)
-
O(n+10) → O(n)
-
O(1000n+50) → O(n)
-
O(n²+5n+8) → O(n²)
-
n 값이 변화했을 때, 작업량이 항상 일정할경우 -> O(1)
n 값의 변화에 비례하여 작업량이 변화할 경우 -> O(n)
-
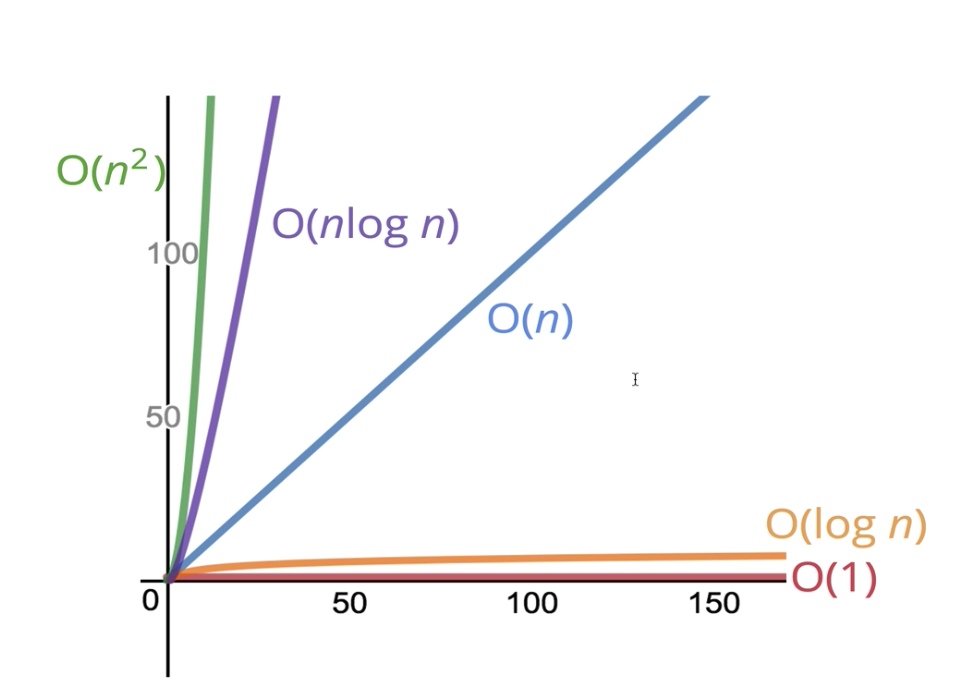
Constant O(1)
Array Lookup, Hash Table Insertion -
Logarithmic O(log n)
Binary Search -
Linear O(n)
for loop -
Quadratic O(n²)
nested for-loops -
Exponential
recursion
