뭐긴 뭐야. google.com이 나온다.
[끝]
시작하며 👏
농담이고, 이제 해당 주제에 관한 글을 쓰려고 합니다!
생각보다, 꽤나 브라우저를 이해하는 데 필수에 가까운 문제죠.
저도 다양한 사이트들의 글을 참조하며, 저만의 방식으로 이해한 부분을 쓰려고 합니다.
항상 이상하다 싶은 부분은, 언제든 비판해주시면 감사히 받겠습니다 😋
본론 📃
1. 네트워크
1. DNS 검색
첫 시작은 네트워크에 대한 이해가 전반적으로 요구돼요.
일단 우리가 어떤 페이지를 들어가려면, URL이 뭔지를 알아야 합니다.
이는 네트워크도 마찬가지에요. (사실상 집주소를 알아야, 집을 들어가는 것과 마찬가지죠!)
따라서, DNS 서버에서는 해당 URL 중, 도메인 네임에 해당하는 부분을 찾기 시작해요.
그리고 검색한 결과에는, 그 해당 도메인 주소에 맞는 IP를 찾게 됩니다. 이를 URL 정보와 함께 전달하게 되는 거죠!
1-1. DNS cache
다음 글에서 갖고 온 사진이에요.
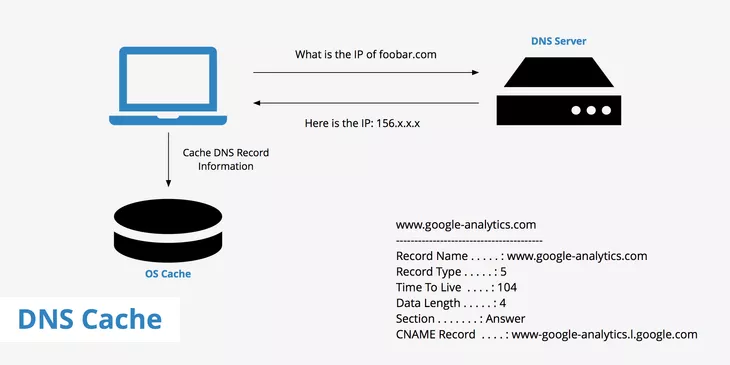
그런데 말이죠, 우리가 정말 자주 전화하는 번호가 있다고 상상해봅시다. 그러면 어떻게 하죠? 어디에다가 외우든가 하겠죠?
DNS 서버도 마찬가지에요. 결국에 자주 갈건데, 왜 추가 시간을 더 걸리게 하냐!라고 말할 수 있는 거죠. 이런 부분을 해결해 주는 게 Browser의 DNS cache입니다.
쉽게 말하자면, 브라우저에서 한 번 요청을 하면, 일단 클라이언트는 TLD서버에 요청하는 루트서버에 또 요청하는 (말이 어렵네요...!) resolver을 요청하게 되는데, 이 시간과 비용이 아까우니 캐싱하자!라고 말할 수 있겠습니다.
정리하자면 캐싱이 없다면 resolver -> root server -> TLD server을 통해 정보를 요청받는 비용이 생긴다는 거죠. (루트서버와 TLD 서버는 DNS의 한 부분이라고 이해하면 되겠습니다. 이 글을 참조해주세요!)
However, this process takes time since once a new website request is made, the client must ask the resolver, which asks the root server, which asks the TLD server, for information.
1-2. OS cache
...그런데도 없다면요?
우리 컴퓨터 네트워크에는 말이죠, 운영체제에 호스트(파일)를 저장하는 기능이 있어요. 여기서 이제 찾는 거죠.
호스트 파일은 컴퓨터 네트워크에서 네트워크 노드 주소 지정을 지원하는 여러 시스템 기능 중 하나입니다. 운영 체제의 인터넷 프로토콜 (IP) 구현 의 공통 부분이며 사람에게 친숙한 호스트 이름을 IP 네트워크에서 호스트를 식별하고 찾는 IP 주소 라고하는 숫자 프로토콜 주소로 변환하는 기능을 제공합니다.
일단 현재 입력한 브라우저에서 캐시가 없으니까, 좀 더 깊숙한 곳에서 찾을 건데, 그 곳이 바로 운영체제인 거죠!
1-3. Router Cache
그래도 없다면 결국 우리의 DNS 조회 기록을 캐싱하고 있는 Router에서 또 조회를 하게 돼요.
1-4. ISP Cache
ISP란 인터넷 사용자들을 지칭하는 거에요. 사실상 우리나라에서 SKT, KT와 같은 곳들이죠!
이곳들에서는 DNS 서버를 갖고 있어요. 여기에서도 이제 기록이 있는지 없는지를 찾기 시작합니다.
정말 복잡합니다!
맞아요. 결국에는 DNS 서버에서 갖고 오면 되는 건데 말이죠.
그럼에도 불구하고, 이렇게 복잡하게 요청하는 이유는, 결국에는 본질은 서버이며, 이는 트래픽 관리가 매우 중요하기 때문입니다!
또한 자주 들락나락거리는 주소라면, 서버 요청보다는 이미 갖고 있는 데이터에서 조회하는 게 더욱 비용이 절약될 수 있기도 하죠.
어떻게 보면, DNS를 캐싱한다는 것도 이러한 목적들에서였겠죠!
2. DNS Query
만약에 이래도 저장된 기록이 없다면 어떻게 할까요?
우씨... 없으니 직접 찾을 수밖에!
라고 생각하며 ISP 서버는 직접 IP를 찾기 위해 Query를 날리게 됩니다!
그런데 사실 www.google.com을 입력한다는 건 정확히 www.google.com의 ip를 갖고와야겠죠?
여기서 이제 서울에서 어떤 택시를 탄 상황을 가정해봅시다.
기사: 어디로 가세요?
나: 한...
기사: 한양대요?
나: 한강...
기사: 한강 어디요?
나: 한강현대아파트요.
기사: 거긴 또 어디있는 거요!
기사: 암사역쪽에 있는 한강현대아파트로 가주세요 😂
사실 주소라는 것도 정말 체계를 갖고 말해야겠죠!
더군다나 만약 대구에서 탔다면? 부산에서 탔다면?
더욱 정확히 서울시 암사역에 있는 한강현대아파트라고 말해야됩니다.
그래야 네비게이션을 검색하는 시간 동안 일단 서울로 가는 방향에서 -> 암사역으로 갔다가 -> 한강현대아파트로 갈 수 있는 거니까요!
이런 체계성을 띄기 위해 DNS Server structure은 다음과 같은 형태를 띄고 있어요. 이 글에서 갖고 왔답니다!

DNS 구조는 이렇게 계층적 트리 구조로 되어 있어요. 여기서 잠깐 용어 정리를 하죠.
recusor: 일반적으로 원하는 IP를 탐색하기 위한ISP DNS server
name server: 인터넷을 통해 접근할 다른DNS server(ex: com, microsoft.com, sales.microsoft.org, ...)
recursive search:root name server에서 쭉~ 밑name server까지 검색하는 과정
IP를 찾기까지 DNS 서버를 오가면서 에러를 반환할 때까지 계속해서 반복적인 진행하게 돼요.
한 번 응용해볼까요? 우리의 목적에 맞게, www.google.com을 한다면,
recursor→root name server: .root name server→Top-level domains: .com.Top-level domains→Second-level domains: google.com.Second-level domains→Third-level domains: www.google.com.
이런 식이 되는 거겠죠! (recursor: 엄마 나 찾았어!)
결국 이러한 검색 단위는 매우 작은 데이터 패킷단위로 진행되는데, 여러 네트워킹 장비를 통해 결과를 다시 또 recursor로 재귀적으로 리턴하게 되는 거죠.
그리고 이왕이면 목적지에 도착할 가장 빠른 길을 찾는 게 바람직하죠! 이때 사용되는 게 routing table인 겁니다.
그리고 만약에 길을 찾다가 데이터가 없어지게 된다면, 그때는 request fail error가 반환되겠죠. 반대로, 데이터가 패킷에 온전히 담아져 있다면 recursor은 올바른 ip를 획득하게 됩니다.
3. TCP
TCP는 이 글을 참고하면서 제 지식과 덧붙여 이해한 바탕으로 글을 써보겠습니다!
후하, DNS 하나만으로도 이렇게 꽤나 많은 시간이 소요가 됐네요!
그만큼 우리가 일반적으로 돌아가는 브라우저 내에는 꽤나 거대한 작업들이 이루어지고 있음을 실감합니다.
우리는 지금까지 DNS로 IP를 획득하는 방법을 확인했어요. 이미 충분히 어썸한 지식을 쌓았답니다. 👍 이후에는 어떤 작업을 거치는 지 살펴보죠!
IP주소를 받게되면 말이죠, IP는 높은 수준의 프로토콜인 TCP와 결합을 하게 돼요. 그 이유는 브라우저(클라이언트)를 이제 서버와 연결시키기 위해서입니다.
그러면, 우리는 이러한 질문이 생겨요.
왜 TCP와 결합하게 되는데요?!
간단히 말하자면 주고받은 데이터의 신뢰성과 연결성 확보 때문입니다.
TCP - 연결지향적
IP는 말이죠, 스스로 연결되는 성질을 갖고 있지 않습니다. 다만 데이터를 어디로 보내야할 지에 대한 정보를 갖고 있는 거죠.
또한 막상 연결되더라도, 도중에 연결이 끊어지면 어떨까요? 그러면 과연 그 데이터가, 기존 송신 위치에서 받아온 것이라고 확신할 수 있을까요?
이러한 면에서 TCP는 연결지향적이기 때문에, 이를 해결해줄 수 있어요.
TCP - 신뢰성
TCP는 SYN과 ACK 패킷을 통해
SYN: 나 연결 돼?
ACK: 응 가능해!
NACK, NAK: 너 제대로 한 거 맞아? 오류났어. 다시 해봐!
와 같은 요청을 주고 받습니다. 이를 3-way Handshaking이라 하는 거죠. 한편, 종료될 때도 친절하게 이를 서로 요청을 주고 받습니다. 이를 4-way Handshaking라 해요.
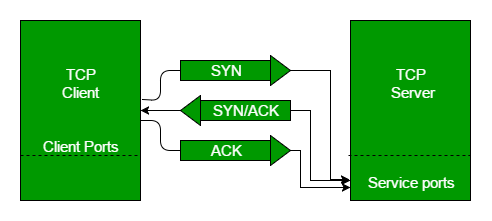
또, TCP는 흐름을 제어해주기도 해요. 보통 데이터를 주고 받을 때 데이터는 작은 패킷 단위로 쪼개져서 보내지고, 나중에 합쳐지는 과정을 수행합니다.
- 그런데 만약 송신측은 엄청 데이터를 빠르게 전달했는데, 정작 수신측은 그만큼 빨리 받을 수 없는 상황이라면?
- 갑자기 트래픽이 몰리는 바람에 재전송이 막 몰려들어올 경우에는?
이런 경우 네트워크 상에서 혼란이 오게 되겠죠.
이러한 것들을 흐름제어하기도 하고, 혼잡제어의 역할도 담당합니다.
결과적으로 우리 네트워크에서 데이터 손실이 일어나지 않도록 방지해주죠.
정말 좋지 않나요 😉
여튼 이러한 목적으로 TCP Socket을 연결하고, 서버와 3-way Handshaking하게 됩니다. 결과적으로 TCP connection이 성공적으로 이뤄졌습니다!
4. HTTP 요청
이제 TCP를 통해 연결로를 확보하였으니, 데이터 전송을 시작해보도록 합시다!
클라이언트는 이제 GET / POST 요청을 보내고, 헤더를 통해 추가 정보들을 요청하기도 해요. 그리고 이러한 과정에서 해당 도메인에 대해 저장한 쿠키들도 주고 받게 되는 거죠 :)
5. 서버의 Request 처리 및 Response
서버는 꽤나 상냥한 게, 요청을 읽고 응답을 처리하는 웹 서버를 갖고 있기 때문에 요청을 받으면 어떻게든 응답합니다. (대표적으로 Apache가 있죠!)
또한, 요청된 내용을 가지고 서버의 정보를 업데이트하거나, 헤더 및 쿠키를 읽는 프로그램도 있어요. (PHP 등등)
결과적으로 특정 형식에 맞게 JSON, XML, HTML을 응답해냅니다!
6. 서버의 HTTP Response
서버는 이제 HTTP 응답을 보내게 되는데요!
이 안에 들어 있는 정보들은
- 상태 코드
- 캐시 방법 (Cache-Control)
- 압축 유형 (Content-Encoding)
- 설정할 쿠키
- 개인 정보
등이 있어요.
7. 렌더링
결과적으로 HTML 콘텐츠를 렌더링하게 되는 겁니다!
이 역시 굉장히 엄청난 일들이 많이 생기는데요, 이에 관한 글은 전에 포스팅한 Reflow, Repaint글을 참조하시면 될 것 같습니다.
(어쩌다 보니 virtual DOM을 알기 위해 포스팅했던 글이, 여기에도 쓸모가 있네요. 하하!)
3. 마치며 🌈
후, 저 역시 이를 포스팅하면서, 그동안 몰랐었던 많은 부분을 배워가네요.
특히, 저는 네트워크 지식이 굉장히 약한데, 이러한 글을 보다 보면
아, 네트워크도 꽤나 재밌는 일들이 많이 생기는구나!
라는 생각이 듭니다.
뭐든지 너무 급하게 하지 말고, 천천히 이해하다 보면, 언젠가 네트워크랑 좀 더 친해질 수 있을 것 같아요 😁 다들 읽느라 고생하셨습니다!
마지막으로,
P.S. 초보의 글입니다. 틀린 부분에 대한 비판 적극적으로 수용하겠습니다! 감사합니다~
참고자료
-
DNS
https://ko.wikipedia.org/wiki/%EB%A3%A8%ED%8A%B8_%EB%84%A4%EC%9E%84_%EC%84%9C%EB%B2%84 -
DNS cache
https://www.keycdn.com/support/dns-cache -
hosts(file) https://en.wikipedia.org/wiki/Hosts_%28file%29#Location_in_the_file_system
-
TCP
https://steemit.com/tcpipacknak/@znxkznxk1030/tcp
https://jwprogramming.tistory.com/36
https://gmlwjd9405.github.io/2018/09/19/tcp-connection.html -
참조하는 데 많은 도움을 준 글 https://medium.com/@maneesha.wijesinghe1/what-happens-when-you-type-an-url-in-the-browser-and-press-enter-bb0aa2449c1a
https://bohyeon-n.github.io/deploy/network/internet-2.html -
DNS에 관해 잘 설명된 글
https://webhostinggeeks.com/guides/dns/
.jpg)