
추천 시스템
요즘 기업들의 추천 시스템 알고리즘은 완전히 공개되지는 않았지만, 어찌보면 나 자신보다 추천 알고리즘이 내 취향을 잘 알고있다는 생각이 든다.
그래서 미니 프로젝트의 주제로 추천 시스템을 선정했다. 추천시스템에 대한 공부 내용과 프로젝트 진행 결과를 적어봐야겠다:)
추천 시스템의 개념
📌 추천시스템의 중요 용어: 사용자(User)와 상품(Item)
📌 특정 사용자가 좋아할 상품을 추천 or 비슷한 상품을 좋아할 사용자를 추천
📌 추천시스템은 User가 좋아하는 것을 정확히 모르지만 좋아할 것 같은 Item을 추천해줌
컨텐츠 기반 필터링
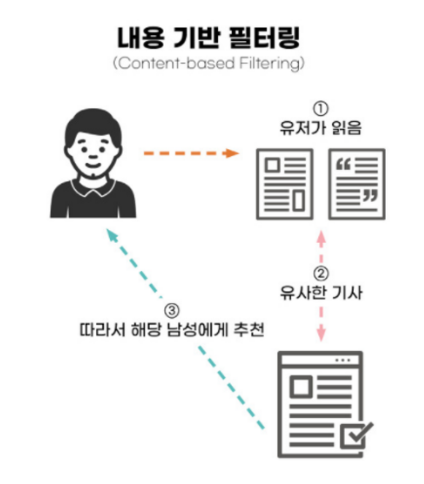
📌 기본적으로 생각하는 수집된 데이터를 기반으로 유사도를 계산해서 추천하는 알고리즘. 이때, 책이라면 책의 제목, 장르, 출판일등의 속성과 사용자의 과거 이력등의 프로필 정보등을 활용.
한마디로 정리하자면 " 사용자 A가 아이템 c에 관심이 있었다면 미래에도 이 아이템에 관심이 있을 테니, c와 비슷한 다른 아이템을 추천하자!" 이다.
내가 <언어의 온도>라는 책을 읽었다면, 이 책과 비슷한 책 소개, 저자, 장르를 가진 책을 추천해주는 것이다. 이 때 사용하는 방법이 유사도를 구하는 것이다. <언어의 온도>와 유사도가 높은 책을 추천해주는 것이다. 이 때 유사도를 구하는 방법은? 정말 많다.
컨텐츠 기반 필터링은 TF-IDF, Word2Vec(NLP에서만 사용 되는 방법)와 같은 Feature Extraction 방법론이 사용된다.
추출 된 Feature를 통해 아이템 간의 유사도는 코사인 유사도, 유클리어드 유사도, 자카드 유사도, 피어슨 상관관계를 통해 측정된다.
유사도 함수들을 통해 각각 순위를 매긴 후 정렬을 한다. 보통 많이 쓰는 것은 코사인유사도이다.
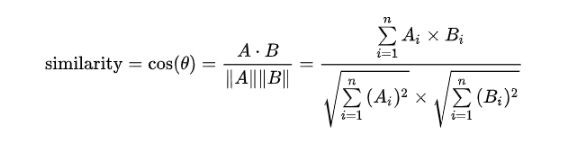
- -1은 서로 완전히 반대되는 경우
- 0은 서로 독립적인 경우
- 1은 서로 완전히 같은 경우
협업 필터링
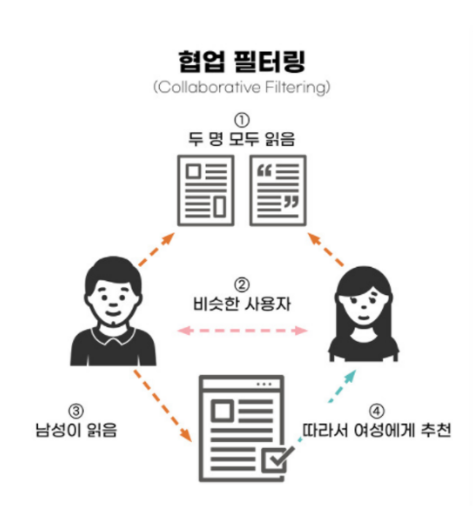
비슷한 성향/취향을 가진 다른 유저가 좋아한 아이템을 현재 유저에게 추천하는 것!
유저 A와 유저 B 모두 같은 아이템에 대해 비슷한/같은 평가를 했다
이때, 유저 A는 다른 아이템에도 비슷한 호감 나타냄
따라서 유저 A, B의 성향은 비슷할 것이므로 다른 아이템을 유저 B에게도 추천
협업 필터링의 한계
- 콜드 스타트(Cold start)
협업 필터링을 사용하기 위해서는 기존 데이터를 활용해야 합니다. 사용자 기반 추천방식에서는
신규 사용자의 행동이 기록되지 않으면, 어떤 아이템도 추천하지 못한다는 문제가 발생합니다.
아이템 기반 추천방식에서도, 신규 상품이 출시되더라도 이를 추천할 수 있는 정보가 쌓일 때까지
추천을 할 수 없다는 의미입니다. 즉, 시스템이 아직 충분한 정보를 모으지 못하면 사용자에 대한 추론을 이끌어 내지 못해 추천을 할 수 없는 한계가 있습니다. - 계산 효율 저하
협업 필터링은 계산량이 많은 알고리즘이기 때문에 사용자가 많아질수록 계산 시간 증가하게
됩니다. 사용자가 많아야 정확한 추천 결과를 도출할 수 있지만, 동시에 계산 시간도 증가하기 때문에 길게는 며칠이 걸리기도 합니다. 이렇게 알고리즘의 정확도와 걸리는 시간이라는 상충되는 문제점은 협업 필터링의 딜레마입니다. - 롱테일(Long-Tail) 문제
파레토 법칙(전체 결과의 80%가 전체 원인의 20%에서 일어나는 현상)을 그래프로 나타내었을 때
꼬리처럼 긴 부분을 형성하는 80%의 부분을 롱테일이라고 합니다. 이는 사용자들이 관심을 많이
보이는 소수의 인기 있는 콘텐츠를 주로 추천하여 ‘비대칭적 쏠림 현상'이 발생한다는 의미입니다.
사용자들은 소수의 인기 있는 항목에만 관심을 보이고 관심이 저조한 아이템은 정보가 부족하여
추천되지 못하여, 다양성이 떨어지는 문제가 발생합니다.
하이브리드 시스템
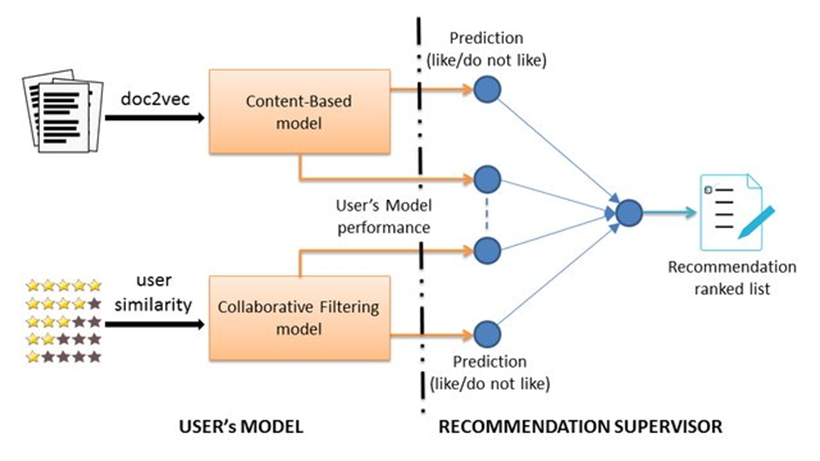
컨텐츠 기반 필터링, 협업 필터링 모두 장단점을 가지고있다. 이 때 두가지 방법을 모두 이용한 하이브리드 시스템을 이용한다. 두 가지 알고리즘을 모두 적용하여 아이템마다 가중평균을 구해 랭킹을 매기는 방법, 점 데이터와 아이템 프로필을 조합해 사용자 프로필을 만들어 추천하는 방법 등 다양한 기법이 있다. 실제로 넷플릭스는 협업 필터링을 사용해 유사한 사용자간의 시청/검색 기록을 비교할 뿐만 아니라, 컨텐츠 기반 필터링을 사용해 사용자가 높게 평가한 영화의 특징을 공유하는 영화를 제공한다고 알려져 있다.
