힙 정렬 세미 정보
힙 정렬의 시간 복잡도는
O(n).... 인 이유가 본래 O(1/2*nlogn)인데,
(for로 전체 힙화를 거치니 n, 그리고 힙화하면서 logn 만큼 이동)
(그런데 자식이 없는 노드는 탐색하지 않기 때문에, 실제로 절반만 힙화 진행.)
실제 힙화 하는 과정에서 굳이 높이를 다 탐색하는 경우는 없어서
O(n)으로 봐도 괜찮다는 것.
(그렇지만 이론적인 얘기이지,
실제로는 n과 nlogn 사이겠지.)
하지만 배열 전체를 힙화 한다음에
또 하나씩 뽑으면서 한번 더 힙화를 해야하기때문에
기존의 시간 복잡도에서 오버헤드가 더 생긴다.(추가 연산.)
그래서 만약 최대나 최소를 어차피 뽑는다면
힙 정렬을 쓰겠지만,
그럴 필요가 없다면 오버헤드를 감수할 필요가 없으므로
퀵 정렬을 쓰는 게 낫겠지...
라는 J님의 흥미로운 설명.
8시~ 9시 50분 코어
...
malloc 98점짜리 코드를 분석하는 코어.
이 malloc의 구성은
segrement 방식으로 구현했고,
best fit을 채택한 것 외에도,
테스트 케이스에서 높은 점수가 나오도록
실제 취약한 테스트 케이스에 대해서 최적화를 진행하였음.
T님은 이에 대한 분석을
실제 힙의 길이와,
따로 가용 리스트의 상태를
별도로 그려 파악하는데 용이하게 하였음.
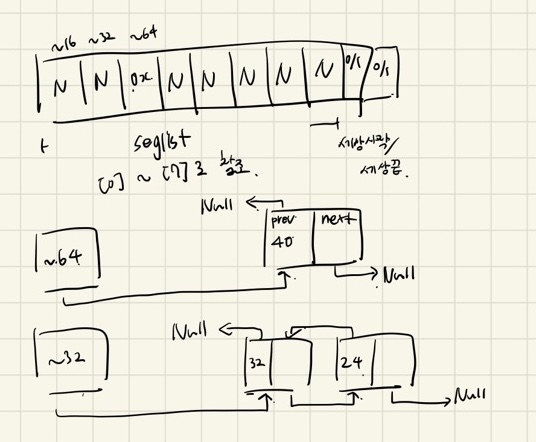
...
(특이점은, seglist[0]... 같은 단위로 인덱스로 진행하는건
32비트에서만 가능하다는 점이다.
64비트에서 돌리면 seglist[0]으로 움직이면
8바이트씩 움직여서 포인터가 어딘가로 가버린다...)
그래서 실제 테스트 케이스에서 들어가는 경우를
하나씩 들어가면서 확인.
아마 16->112->16->112를 번갈아서 넣는데
주어진 길이 자체는 그것만으로 payload의 길이라
헤더, 풋터 넣으면 8바이트를 붙여야해서
24바이트가 됨.
여기선 맨처음에 64바이트만 확장하고,
그 이후에 extend heap할때는 1024바이트씩 확장하는데,
특이하게 place시
앞을 비우고 뒤를 할당한다.
나중에 확인하면, LIFO와 어우러지면서
철창을 방지하기 위한 청사진이었다.
....
그래서 요주의로 봐야하는 사항은 다음과 같다.
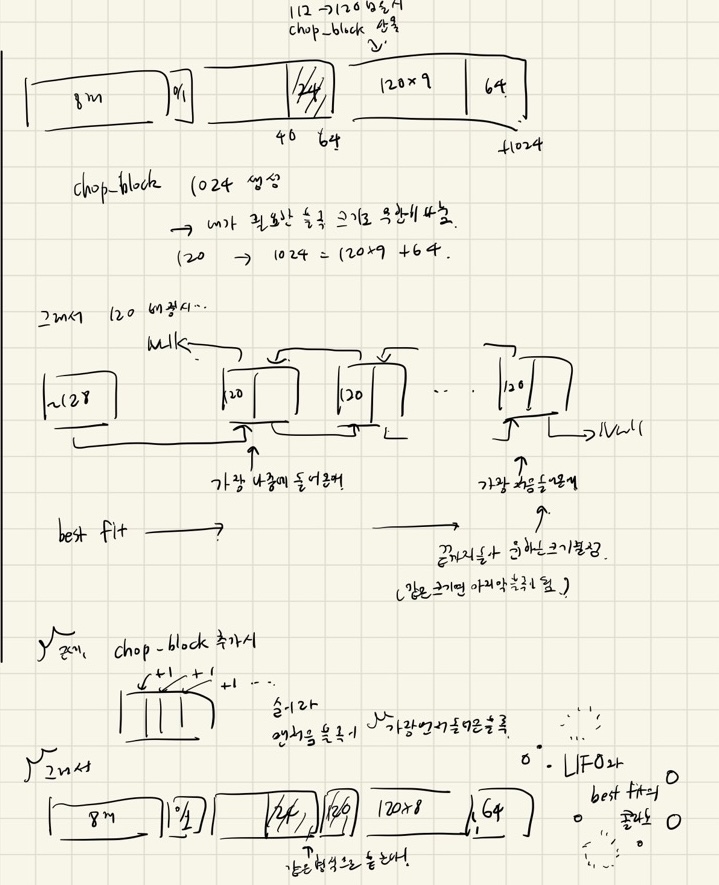
chop_block으로 넣으면 맨 앞 블록이,
가용 리스트의 맨 끝에 위치하게 되는데,
best fit으로 찾으면,
가용 리스트의 맨 끝 블록을 채택하게 되면서,
결과적으로 힙에서 맨 앞 블록이 가장 먼저 나가며
place에서 뒤에 할당된 블록과 딱 붙게 되는 현상을 설명하고 있다.
...
그렇게 최종적으로
realloc을 하면
resize block이라는 함수를 쓰던데,
만약 앞이나 뒤가 가용이고,
걔를 잡아서 늘리는 걸로 따로 malloc 하지 않아도 된다면(can_expand),
늘려서 기존 데이터는 옮겨가지고 진행하고(expand block),
그걸로 안 된다면 그냥 새로 할당한다.(reallocate block)
(그냥 malloc과 다른건 memcpy인가 memmove로 기존 데이터를 복사하는 점.)
...
그렇게 마지막 팀 코어가 끝났다.
그래서 여태까지의 코어는 어땠는지 여쭤봤다.
T님 : 이번 malloc 주제가 그전처럼 집중하기가 좀 어려웠다. 실제로 어떻게 돌아가는지 확인하기도 어려웠고, malloc이 특수하여 대개 무언갈 구현하기 보다는 코드를 이해하고 설명하는 식이었어서 그랬던 것 같다. 마감때문에 좀 피말리긴 했는데 확실히 맨처음에 malloc을 이해하고 나니 그 뒤에 코드를 이해하기 수월했다.
J님 : 설명하면 다 짚어주시니 좋았다. 어쩐지 다 잘못 조사한 것 같다.(T님 : 아니다. 정말 궁금해서 물어본 거다. 잘했는데 너무 겁먹을 필요 없다.) (나 : 맞다. 그리고 알던 것도 서서 말하면 기억이 안 난다.) (H님 : 면접 연습에 도움이 될 것이다.)
H님(?)(참관) : 늘 주제를 딱 잡고 진행하는게 보기 좋아보였다. 코어를 이렇게 진행하는 거구나 영감을 받았다. (그 외 다들 설명을 잘해주셔서 좋았다, 내가 막힌 부분은 이미 T님이 막혔다 푸신 부분이라 많은 도움을 받았다, 등도 들은 듯.)
나 : 실제 진행하는 진도가 적당한지 궁금했다. 이번에 연휴에 공부를 했어서 좀 빡세게 잡았고, 그래서 좋았지만 반대로 두 분이 맞춰주시는 편이라 무리하신 건 아닌지 여쭤보고 싶었다.
또 힙 정렬 코어 때는 사실 마감이 좀 빠듯했는데 T님이 또 야망있게(라는표현은 안 쓴듯) 잡으시니까 동기 부여도 받고, 그래서 그만큼 하고 싶어서 시간이 없어도 했는데 숨겨진 능력을 알수 있어서 좋았다..
유난히 이번 팀이 좋았던 점은, 진도를 정했다면 정해진 만큼의 진도는 다 해오셔서 좋았다... 등등.
10시 10분 ~ 11시 D님 설명
...
D님이 J님에게 >가상 메모리 페이징<에 대해 여쭤봄.
(이전에 뭐 여쭤보셨나 기억이 안남.)
같이 했던 내용이니 J님이 설명하심.
전반적인 그림은 그리셨지만 정확히 무엇이 무슨 역할을 하는지 어려워하심.
D님이 짚으신 키워드는
TLB, VA(VPN, VPO), PTE...
Translocation Lookaside Buffer,
Virtual address, Page Table entity.
....
프로세스가 실행되면서
MMU로 이동.
MMU에 페이지 테이블이 있음.
페이지 테이블을 MC(memory controler)가 관리함.
프로세스에서 쓸 메모리들이 있을 것이 아닌가?
그래서 그 프로세스 전반에서 쓸 메모리 내역이
페이지 테이블에 채워짐.
(그래서 그 한 개의 논리적 메모리의 단위가 페이지임.)
그러한 지점 하나를 엔트리라고 하는데
그 페이지 테이블 엔트리에
페이지가 물리 메모리에 할당되었는지 비트와,
실제 메모리 주소가 기록됨.
(정확히는 VPN과 VPO.)
(VPN으로 내가 찾으려는 페이지의 번호를 찾고,
VPO로 실제 DRAM에 적재된 offset 주소로 찾아감.)
(이 때 남는 비트에 할당 여부를 기재하는 것임.)
그렇게 프로세스가 실행되며 페이지에 접근할 때
할당 여부 확인하고
만약 할당되지 않았다면
희생자 페이지를 가져와서 매핑 시키는데....
그 희생자 페이지만 빠르게 가져오는
데이터 범위가 있음. 그걸 swap file 이라고 함.
(왜냐하면 전체 데이터가 1TB라면,
어떤 페이지를 가져올지 1TB를 전체 탐색한다면
시간이 너무 걸리지 않겠는가?)
대개 20MB 정도로 구성.
애초에 프로세스가 실행된 순간
앞으로 어떤 메모리를 쓸 건지,
어떤 건 메모리를 새로 매핑해야하는지 알게되기때문에
여기서 벨라디 알고리즘을 써서 swap file을 미리 지정할 수 있는 것임.
이 때 이미 MMU가 크기가 좀 있으므로
캐시 역할을 할 TLB를 씀.
MMU와 CPU사이에 TLB가 중간 레지스터로
자주 쓰는 데이터는 TLB에 저장해두고
MMU까지 가지 않고 빠르게 가져오는 것임.
그래서 실제 가상 메모리 주소 자체에
애초에 TLB에 적재되어있는지, MMU에 적재되었는지 적혀있다.
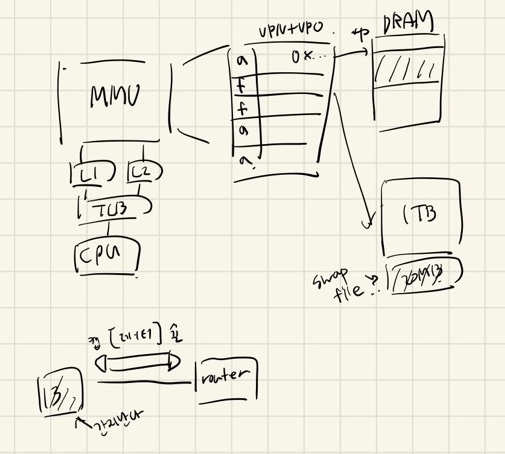
(아! 그래서 저 가상 메모리 주소에
권한 여부도 적혀있기때문에
권한 없는데 접근 -> segment fault)
(page를 못 찾음 -> page fault)
...
이더넷.
이더넷은 정확히 따지자면,
네트워킹 프로토콜임.
(LAN 기술이지만, LAN 기술 중에서도
encapsulation으로 진행하는 네트워킹 기술을 말함.)
(나는 다른 허브 간 기술 호환 용 정도로 이해했었는데,)
(어디서 쓴댔는데 까먹었다...)
허브, 브릿지, 라우터 까지 얘기했었는데
거기서 확장하여
라우터도 루트 라우터가 존재하고,
그 루트 라우터 끝에
시작점인 13개의 ..... DNS가 있음.
Domain Name System 으로,
도메인 이름 -> 컴퓨터가 쉽게 인식할 수 있는 IP 주소로,
만약 네이버에 접근한다고 했을때,
그 네이버 시작지점 IP등을 13개의 컴퓨터가 나누어 저장하여,
컴퓨터 중 하나가 죽어도 모든 인터넷이 죽지 않게 해줌...
아무튼
이더넷은 요즘 쓰지 않는 기술인지, 아직까지 쟁쟁한 기술인지
...쟁쟁한 거 아닌지 잘 모르겠고
아무튼
전선으로 그렇게 데이터 송신 시
단위가 16비트, 32비트도 아니고 1비트씩 송신하는데
데이터 손실도 막기 위함이지만
속도가 빠르고....
단 그렇게 하면
만약 데이터 하나를 전부 보낼때
온전히 도착했는지 확인하기 위해 나온 게
TCP와 UDP.
단방향인 UDP는 확인을 따로 안 하고 깨져서 올수도 있으나
대신 속도가 빠르고
TCP는 확인을 하고, 만약 제대로오지 않았다면
다시 데이터를 보내라고 송신하는 양방향.
아!
그래서 캡슐화가 중요한 이유가
1비트씩 송신하기때문에
그 데이터의 시작과 끝을 알리는게
캡슐화의 역할이라는 점!
