Entropy 란?
물리를 들어본 사람이라면 엔트로피 에 대해서 들어본 적이 있을 것이다. 엔트로피 란, 흔히 '무질서도' 로 정의된다. 그렇다면 머신러닝에서 쓰이는 엔트로피는 정확히 어떤 의미로 사용되는 것일까? 머신러닝에서 엔트로피란, 머신 러닝에서 사용되는 정보들의 무작위성, 혹은 무질서도를 의미한다. 그림으로 보면 그 이해가 더 쉽다.
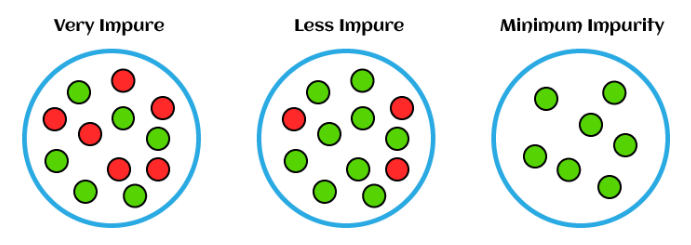
그림의 왼쪽에서 오른쪽으로 진행 할 수록 엔트로피는 낮아지며, 엔트로피는 정보들의 예측성과 정보의 순도를 나타내는 척도가 되는 것이다.
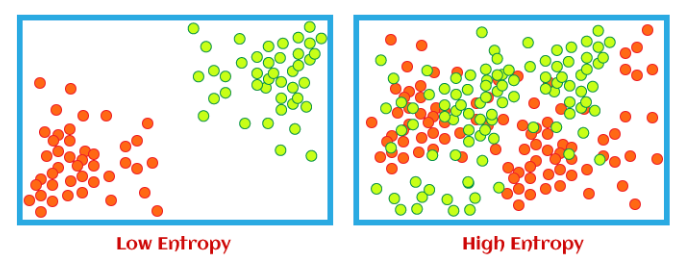
다음 같은 경우에도 마찬가지 이다.
주어진 데이터 set 의 크기가 C 라고 했을 때, 엔트로피를 구하는 공식은 다음과 같다.
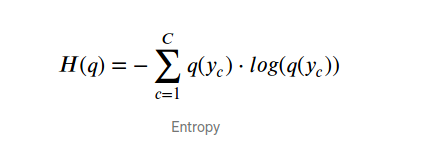
여기서 q(yc) 란, yc 데이터가 들어갔을 때의 확률을 말한다.
https://curt-park.github.io/2018-09-19/loss-cross-entropy/
[ref]
https://towardsdatascience.com/understanding-binary-cross-entropy-log-loss-a-visual-explanation-a3ac6025181a
https://www.javatpoint.com/entropy-in-machine-learning#:~:text=Entropy%20is%20defined%20as%20the,or%20impurity%20in%20the%20system.

개발 기록