강화 학습?
강화 학습은 머신 러닝의 종류 중 하나이다.
이는 특정 상황에서 최대한의 보상을 위해서 이에 맞는 행동을 하는 것을 의미한다.
여기에서 정답 키를 가지고 학습을 진행하는 supervised learning 과 다르게,
강화 학습은 주어진 정답 없이 과제를 수행하며 학습하게 된다. 즉, 주어진 학습 데이터 없이
오직 경험을 통해서 학습한다는 말이다.
강화 학습의 메인 포인트
- Input: 모델이 학습을 시작하는 초기 값이다.
- Output: 행동의 결과값이다. 특정 문제에는 다양한 해결책들이 존재하기 때문에 많은 경우의 수가 나오게 된다.
- Training: 학습은 입력된 Input 에 대한 Output 값에 따라서 reward 혹은 punish 를 결정하는 방식으로 진행된다.
- 모델은 학습을 계속하고, 최적의 해결책은 best reward 에 따라서 결정된다.
Q-Learning
Q learning 에서, agent 는 행동을 통해 얻은 'Q' 값을 최대화 하는 것이 목적이다.
시작점에서, Q table 은 Q(s,a) 의 카디널리티가 action space * observation space 로 정의 될 것이다. 다양한 학습이 진행되면서, agent 는 q table 을 만들어 갈 것이다.
첫번째로, epsilon greedy 알고리즘을 통해서 움직임을 정할 것이다. 주로, 학습이 진행 될 수록 epsilon decay factor 를 추가해서 exploration 의 확률을 줄이는 식으로 진행된다.
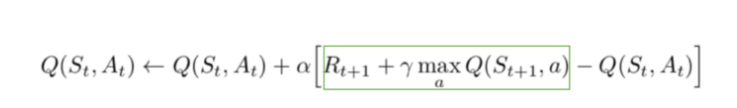
agent 가 실제로 학습하기 위해서, 위와 같은 식을 이용하게된다.
max_a Q(S_t+1, a) 는 agent 가 best action 뒤에 갖는 q 의 값이다.
Q(S_t, A_t) 는 q 의 현재 상태이다. next step인 Q(S_t+1, a) 에는 감마 값이 붙게 되는데, 이는 미래의 값보다 현재의 값이 더 중요하기 때문이다. R_t+1 은 행동 이후에 갖게되는 reward 이다. target value 는 알파만큼 곱해지게 되는데, 이는 true 값을 받기 위해서 다수의 학습을 거치기 때문이다.
Epsilon Greedy
Greedy Algorithm 은 미래를 생각하지 않고 각 단계에서 가장 최선의 선택을 하는 기법이다.
즉, 각 단계에서의 최선이 전체에서의 최선이라고 생각하는 알고리즘이다. 이는 미래를 생각하지 않았기 때문에, 항상 최선의 결과를 반환하지는 않는다.
이를 개선시킨 전략이 E-greedy Algorithm 이다. 이는 Epsilon 이라는 Hyper-parameter 를 통해서 행동을 결정하는 것이다. 일정한 확률인 E 일 경우 Random 으로 선택하고,
1-E 의 확률로는 최상의 결과를 냈던 행동을 선택하는 것이다. ( exploration vs exploitation 활용 과 탐험 )
[ref]
https://medium.com/nerd-for-tech/first-look-at-reinforcement-learning-67688f36413d
(greedy algorithm) https://mangkyu.tistory.com/65
