epoch
한 번의 epoch 는 인공 신경망에서 전체 데이터 셋에 대해 forward/backward pass 과정을 거친 것을 말한다.
즉, 전체 데이터 셋에 대해 한 번 학습을 완료한 상태이다.
신경망에서 사용되는 역전파 알고리즘(backpropagation algorithm)은 파라미터를 사용하여 입력부터 출력까지의 각 계층의 weight를 계산하는 과정을 거치는 순방향 패스(forward pass), forward pass를 반대로 거슬러 올라가며 다시 한 번 계산 과정을 거처 기존의 weight를 수정하는 역방향 패스(backward pass)로 나뉩니다. 이 전체 데이터 셋에 대해 해당 과정(forward pass + backward pass)이 완료되면 한 번의 epoch가 진행됐다고 볼 수 있습니다.
우리는 모델을 만들 때 적절한 epoch 값을 설정해야만 underfitting과 overfitting을 방지할 수 있습니다.
epoch 값이 너무 작다면 underfitting이 너무 크다면 overfitting이 발생할 확률이 높은 것이죠.
overfitting, underfitting?
https://acdongpgm.tistory.com/53
batch size 와 iteration
batch size는 한 번의 batch마다 주는 데이터 샘플의 size. 여기서 batch(보통 mini-batch라고 표현)는 나눠진 데이터 셋을 뜻하며 iteration는 epoch를 나누어서 실행하는 횟수라고 생각하면 이해가 편하다.
메모리의 한계와 속도 저하 때문에 대부분의 경우에는 한 번의 epoch에서 모든 데이터를 한꺼번에 집어넣을 수는 없습니다. 그래서 데이터를 나누어서 주게 되는데 이때 몇 번 나누어서 주는가를 iteration, 각 iteration마다 주는 데이터 사이즈를 batch size라고 합니다.
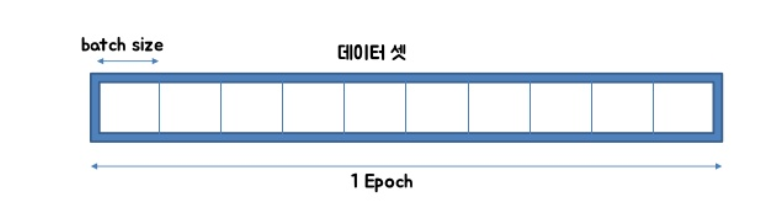
전체 1000개의 데이터가 있고, epoch = 10, batch_size = 200 이라고 가정해보자.
1 epoch 는 각 데이터의 size 가 200 인 batch 가 5 iteration 으로 나누어져 전체적으로 총 10번, iteration 기준으로 50번의 학습이 이루어진 것이다.
batch 의 문제점
batch 단위로 학습을 진행하게 되면 발생하는 문제점이 있는데, 이것이 바로 Internal Convariant Shift 이다.
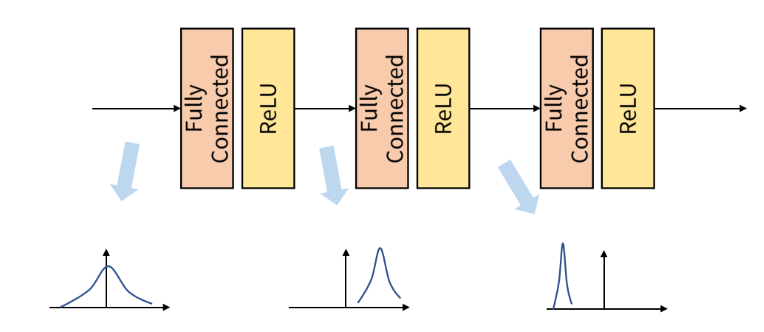
이는 아래 그림과 같이 학습 과정에서 계층 별로 입력의 데이터 분포가 달라지는 현상을 말한다.
각 계층에서 입력으로 feature 를 받게 되고, 그 feature 는 convolution 이나 fully connected 연산을 거친 뒤에 activation function 을 적용하게 된다.
그렇게 되면 연산 전/후로 데이터 간 분포가 달라질 수 있다.
이와 유사하게 Batch 단위로 학습을 하게 되면 Batch 단위 간에 데이터 분포의 차이가 발생할 수 있다.
즉, Batch 간의 데이터가 상이하다고 말할 수 있는 데 이것이 Internal Convariant Shift 이다.
이 문제를 개선하기 위한 개념이 바로 Batch Normalization 이다.
Batch Normalization
Batch Normalization 은 2015년 arXiv에 발표된 후 ICML 2015에 게재된 아래 논문에서 나온 개념이다.
https://arxiv.org/pdf/1502.03167.pdf
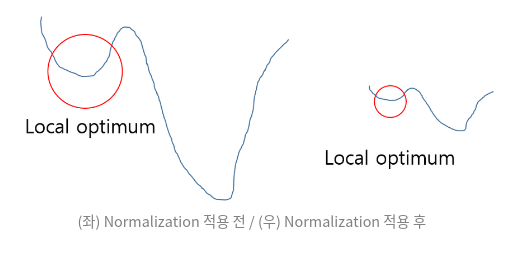
기본적으로 정규화를 하는 이유는 학습을 더 빨리 하기 위해서, 혹은 Loacl optimum 문제에 빠지는 가능성을 줄이기 위해서이다.
Batch Normalization 논문에서는 학습에서 불안정화가 일어나는 이유를 "Internal Convariance Shift" 라고 주장하고 있는데, 이는 네트워크의 각 레이어나 Activation 마다 입력값의 분산이 달라지는 현상을 뜻한다.
- Covariate Shift : 이전 레이어의 파라미터 변화로 인하여 현재 레이어의 입력의 분포가 바뀌는 현상
- Internal Covariate Shift : 레이어를 통과할 때 마다 Covariate Shift 가 일어나면서 입력의 분포가 약간씩 변하는 현상
이를 해결하기 위한 것이 각 레이어의 입력의 분산을 평균 0, 표준편차 1인 입력값으로 정규화 시키는 방법으로, 이를 Whitening 이라고 한다.
단순하게 Whitening만을 시킨다면 이 과정과 파라미터를 계산하기 위한 최적화(Backpropagation)과 무관하게 진행되기 때문에 특정 파라미터가 계속 커지는 상태로 Whitening 이 진행 될 수 있다. Whitening 을통해 손실(Loss)이 변하지 않게 되면, 최적화 과정을 거치면서 특정 변수가 계속 커지는 현상이 발생할 수 있다.
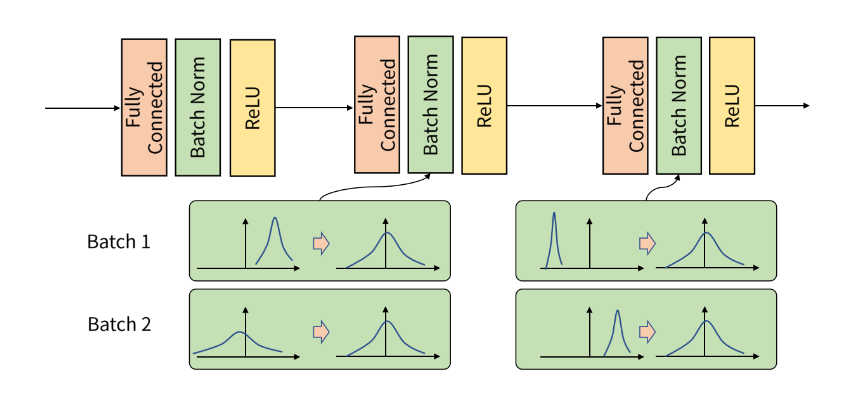
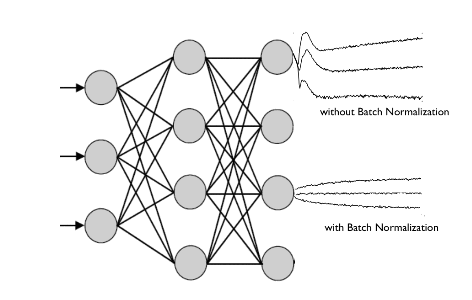
batch normalization은 학습 과정에서 각 배치 단위 별로 데이터가 다양한 분포를 가지더라도 각 배치별로 평균과 분산을 이용해 정규화하는 것을 뜻 한다.
[ref]
https://blog.naver.com/qbxlvnf11/221449595336
https://gaussian37.github.io/dl-concept-batchnorm/#:~:text=batch%20normalization%EC%9D%80%20%ED%95%99%EC%8A%B5%20%EA%B3%BC%EC%A0%95,%EC%A0%95%EA%B7%9C%ED%99%94%ED%95%98%EB%8A%94%20%EA%B2%83%EC%9D%84%20%EB%9C%BB%ED%95%A9%EB%8B%88%EB%8B%A4.
https://bskyvision.com/entry/%EB%B0%B0%EC%B9%98batch%EC%99%80-%EC%97%90%ED%8F%AC%ED%81%ACepoch%EB%9E%80
https://towardsdatascience.com/epoch-vs-iterations-vs-batch-size-4dfb9c7ce9c9
