전이 학습?!
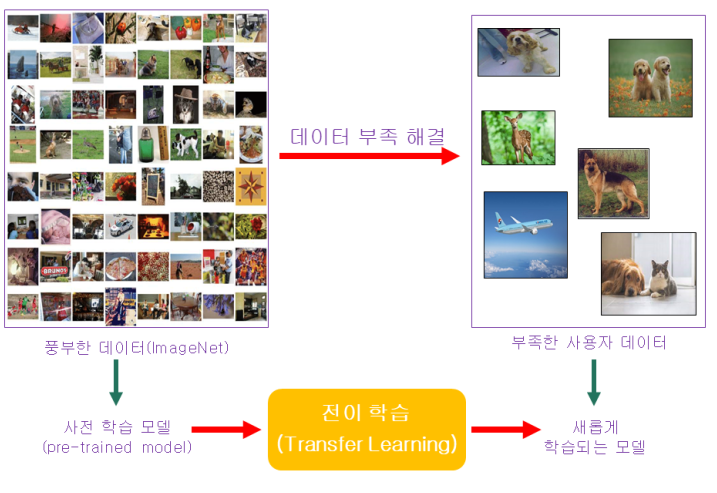
컴퓨터 비전이나 자연어 처리 분야에서는 학습을 위해서 대용량의 데이터셋이 필요하다.
하지만, 데이터를 모으는 일은 생각만해도 까마득한 일이 아닐 수 없다. 충분한 데이터셋을 얻는 것은
돈도 시간도 많이 드는 작업이기 때문에 현실적으로 쉽지 않다.
이를 해결하기 위해서 우리는 사전에 학습된 모델(pre-trained model)을 사용하고
이를 미세 조정(fine-tuning)하는 '전이학습(transfer learning)' 을 수행 할 수 있다.
전이 학습이란, 한 분야의 문제를 해결하기 위해서 얻은 지식과 정보를 다른 문제를 푸는데 사용하는 방식으로 정의된다.
쉬운 예를 하나 들어보도록 하자
양식을 만드는 요리사 인공지능을 만들고 싶은데 양식을 만드는 조리법 데이터가
매우 적다면, 양식을 잘 만드는 인공지능을 만드는 것은 현실적으로 어렵다.
그런데 이미 한식을 굉장히 잘 만드는 인공지능이 존재하고 있다면,
이 인공지능은 아주 적은 양식 조리법만으로도 굉장히 양식을 잘 만드는 인공지능이 될 수 있다.
이는 마치 특정 분야의 지식에 능통한 사람이 비슷한 분야에도 빠르게 적응할 수 있는 특성과 닮았다.
실제로 요리사는 새로운 요리도 빠르게 익힐 수 있고, 한 언어에 능통한 개발자는 다른 프로그래밍 언어도 빠르게 익혀 사용할 수 있는 것과 다르지 않다.
하나의 작업을 위해 훈련된 모델을 유사 작업 수행 모델의 시작점으로 활용하는 딥러닝 접근법인 것이다.
이는 다양한 장점들이 존재하는데,
- GoogLeNet과 ResNet처럼 널리 쓰이는 아키텍처를 포함해 딥러닝 연구 커뮤니티에서 개발되는 모델 아키텍처를 활용할 수 있다.
ImageNet
https://newsroom.koscom.co.kr/26062
https://choice-life.tistory.com/40
https://kr.mathworks.com/discovery/transfer-learning.html
http://www.gisdeveloper.co.kr/?p=8655
