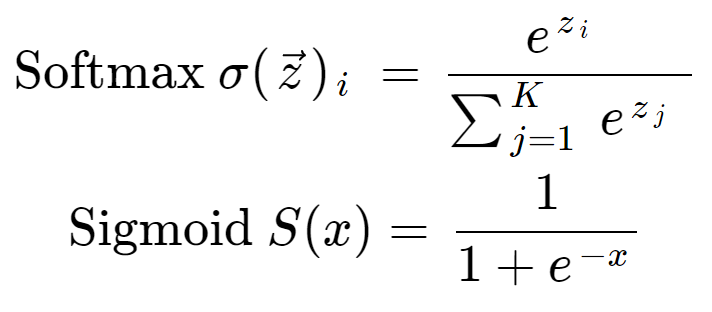
항등 함수
identity function, 항등 함수는 입력을 그대로 출력한다.
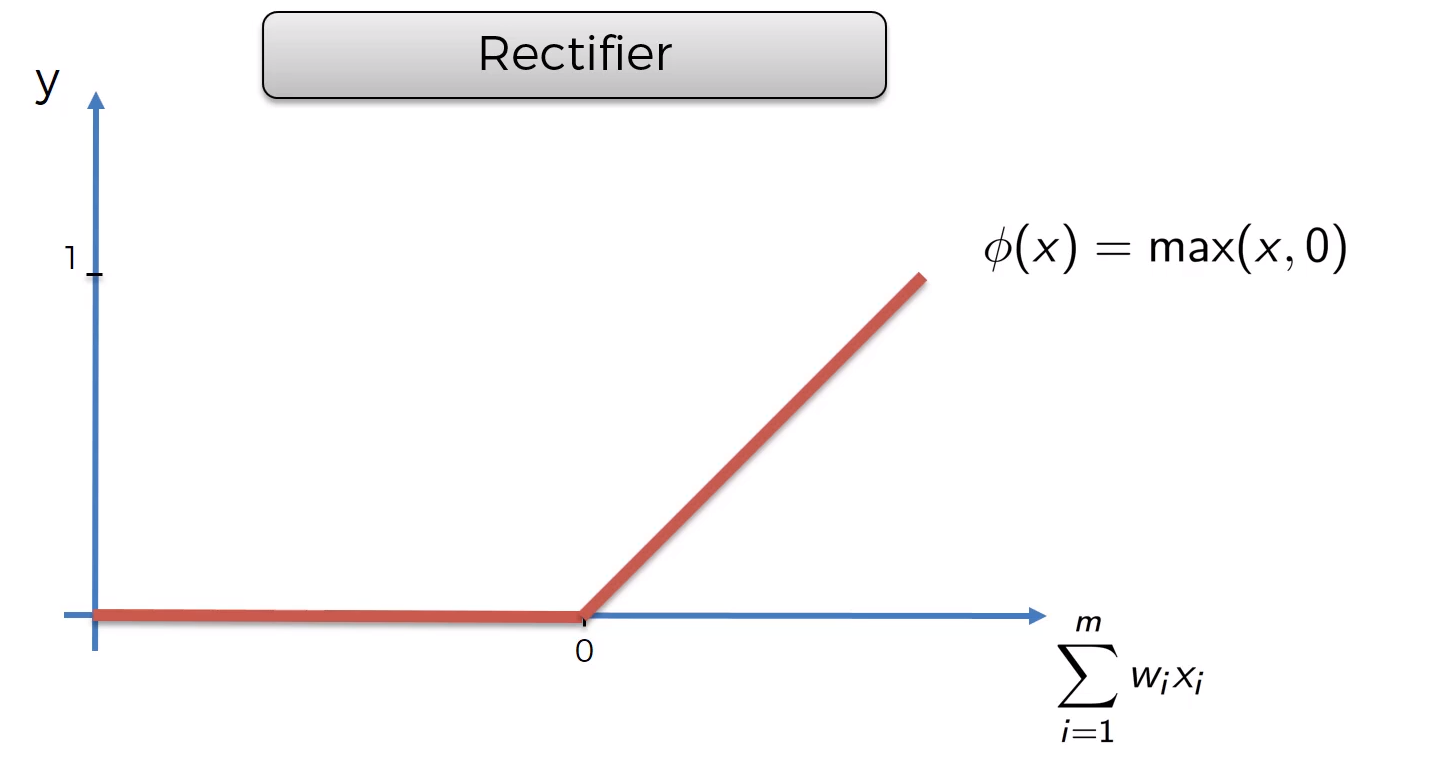
Rectifier
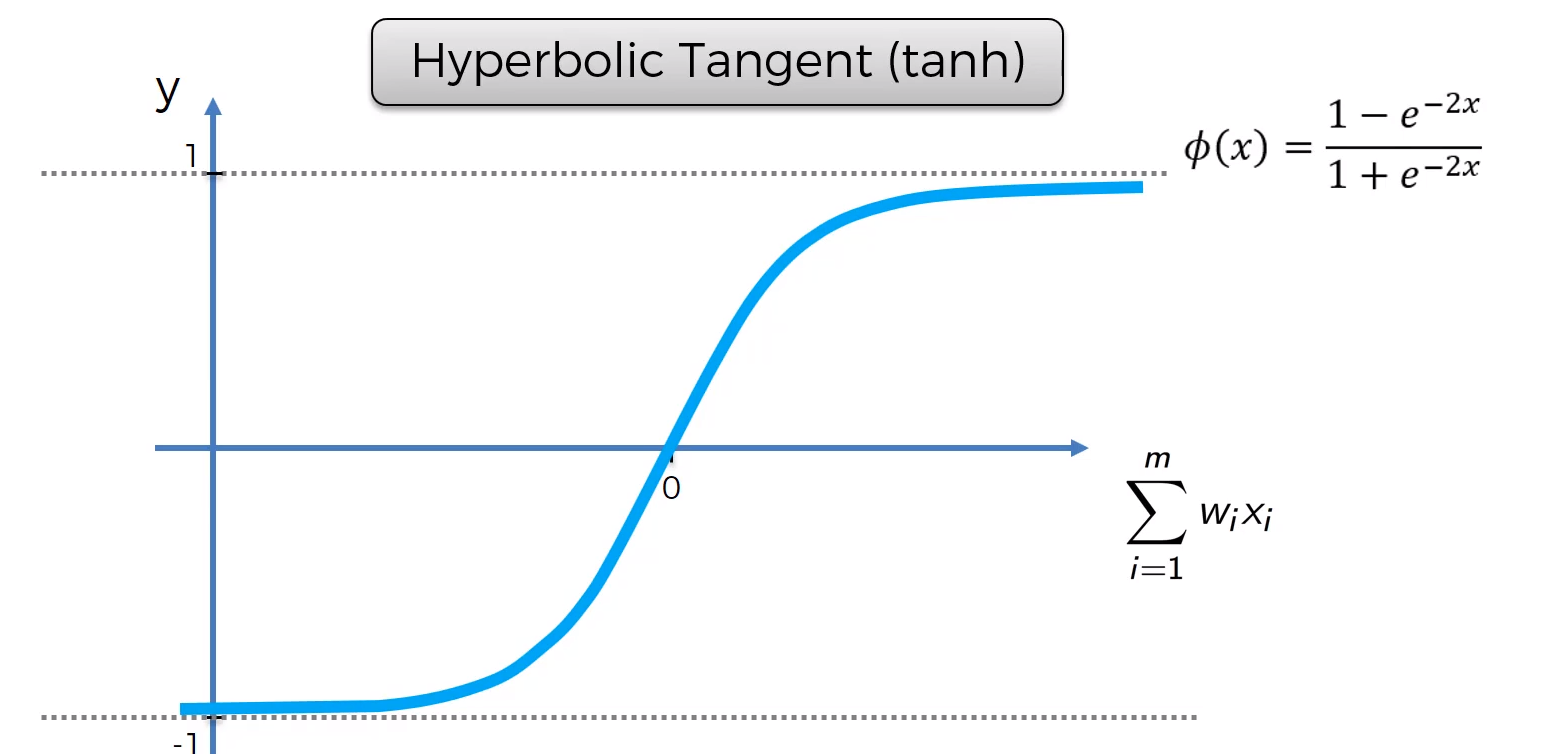
Hyperbolic Tangent (tanh)
Sigmoid function
Softmax function
소프트맥스 함수는 다중 클래스 분류 모델을 만들 때 사용한다.
결과를 확률로 해석할 수 있게 변환해주는 함수로 높은 확률을 가지는 class로 분류한다. 이는 결과값을 정규화시키는 것으로도 생각할 수 있다.
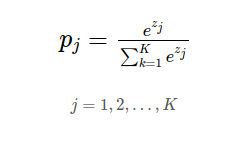
- K는 class 수
- zj 는 소프트맥스 함수의 입력값
직관적으로 해석해보면 j번째 입력값 / 입력값의 합 으로 이해 할 수 있다.
softmax 함수는 입력 값을 정규화하여 출력하게 된다.
입력받은 값을 정규화 하는 이유가 무엇일까?
우리가 가장 쉽게 접하는 예시인 손글씨 숫자 인식에서는,
입력값에 대한 결과로 다양한 값을 반환 받는다.
0부터 9 까지의 숫자를 분류 (10개의 클래스 분류)한다고 하면, 마지막 층에서는
총 10개의 값을 반환 받게 될 것이다.
어떻게 하면 이를 우리 인간에게 조금 더 의미있는 숫자로 반환 할 수 있을까?
우리가 알고싶은 것은 입력값이 10개의 클래스 중 어느 클래스에 속할 확률이 가장 높은지 일 것이다.
이를 위해서 softmax 함수가 존재하는 것이다.
입력 받은 값을 정규화해서 반환해주면, 10개의 입력값이 정규화되어
도합이 1인 확률로 나오게 된다. 우리는 이것을 보고, 입력값이 어느 클래스에 속할
확률이 가장 높은지 직관적으로 알 수 있게 된다.
이는 다른 말로했을 때 답을 하나만 도출해내는 경우, 가장 높은 점수만 알면되니
이 경우는 softmax 계층을 사용하는 것이 부적절한 경우가 되겠다.
실제로 적용되는 예시를 들어보자
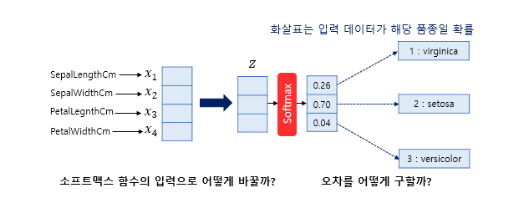
다음과 같은 다중 클래스 분류 예시에 있는 두가지 질문에 답을 해보자.
소프트맥스 함수의 입력으로 어떻게 바꿀까?
모델은 4개의 독립변수, 즉 4차원 벡터를 입력으로 받게 된다.
하지만 소프트맥스 함수를 통해 분류하고자 하는 클래스가 3개라면 어떻게 할까?
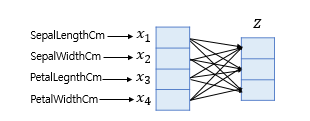
간단하다. 소프트맥스 함수의 입력 벡터 z 의 차원수만큼 결과값이 나오도록 가중치 곱을 진행한다.
위의 그림처엄 총 4 * 3 = 12 개의 화살표(가중치) 를 갖게 되고, 이(가중치)는 학습 과정에서 점차적으로 오차를 최소화하는 방향으로 업데이트된다.
오차를 어떻게 구할까?
소프트맥스 함수의 출력은 분류하고자 하는 클래스의 갯수만큼 차원을 가지는 벡터로 각 원소는 0과 1 사이의 값을 가지며, 이 각각은 특정 클래스가 정답일 확률을 나타낸다. 그림으로 보자면, 다음과 같은 원-핫 벡터로 표현되는 것이다.

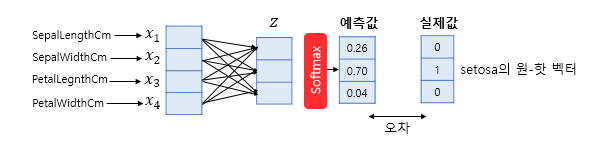
데이터의 실제값이 setosa 라고 한다면, setosa 의 원-핫 벡터는 [0, 1, 0]이다. 이 경우에, 실제값[0, 1, 0]과 예측값[0.26, 0.70, 0.04]의 차이를 통해서 오차를 계산 할 수 있다.
오차 계산을 위해서 사용되는 것이 바로 손실 함수 이다.
손실함수에 대한 자세한 내용은 다음 링크를 참고하도록 하자
https://velog.io/@younghwan/%EC%86%90%EC%8B%A4%ED%95%A8%EC%88%98
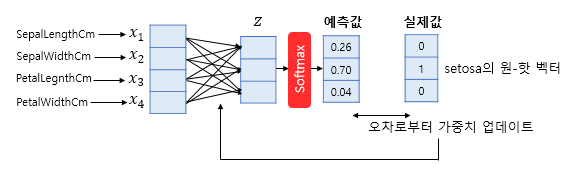
손실 함수를 통해서 구한 오차를 줄여나가는 방향으로 학습 시키는 역할을 하는 것이 최적화 함수(optimizer) 이다.
[ref]
https://syj9700.tistory.com/38
https://proceedings.mlr.press/v15/glorot11a/glorot11a.pdf
