[운영체제] CPU 스케쥴링 1 : CPU burst & I/O burst, Scheduling Criteria, 스케쥴링 알고리즘 : FCFS,SJF,priority Scheduling, Round Robin
[운영체제] 반효경 - 2014 이화여대 강의
본 포스팅은
http://www.kocw.net/home/search/kemView.do?kemId=1046323을 참고했습니다.
프로그램 실행 시 CPU burst & I/O burst
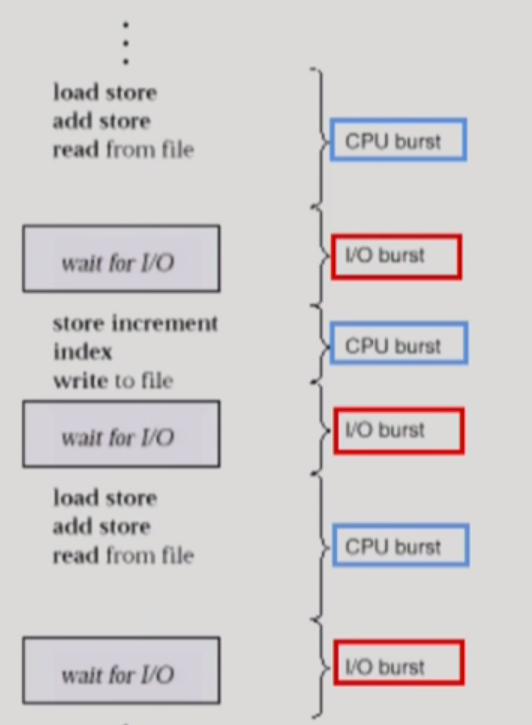
CPU burst는 CPU가 명령어를 수행 중인 것을 말하고,
I/O burst는 I/O 작업 수행 동안 CPU가 기다리는 것을 말한다.
프로그램 실행은 이처럼 CPU burst와 I/O burst를 왔다갔다 하며 실행된다.
CPU burst time의 분포
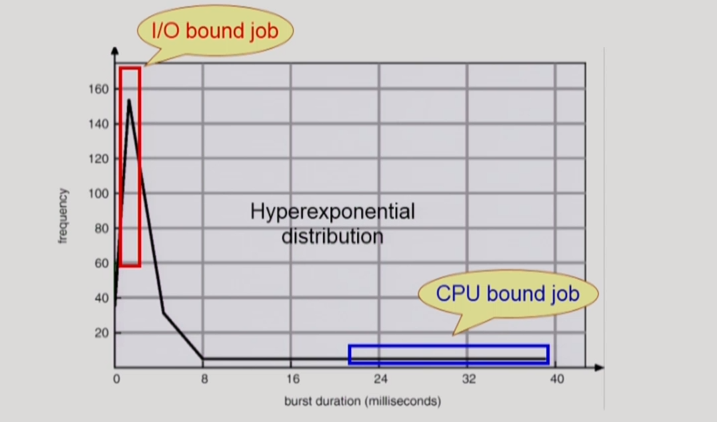
위 그림은 CPU burst가 얼마나 오래가냐를 보여준다.
대부분 I/O burst 때문에 얼마 가지도 못한다. => 요런 job을 'I/O bound job' 이라 한다.
가아끔 CPU 계속 쓰는 경우 있다. => 요런 job을 'CPU bound job'이라 한다.
CPU를 하루 죙일 붙잡고 계산을 하는 것도 문제지만,
반대로 계산은 안하고 하루 종일 I/O 작업을 하러 간다면, CPU를 낭비하는 것이다.
이 때문에 CPU 스케쥴링이 필요한 것이다.
- interactive job에 적절한 response 제공 요망
- CPU와 I/O 장치 등 시스템 자원을 골고루 효율적으로 사용하기 위해
CPU Scheduler & Dispatcher
CPU Scheduler (software)
- Ready 상태의 프로세스 중에서 이번에 CPU를 줄 프로세스를 고르는 것
Dispatcher (software)
- CPU 제어권을 CPU Scheduler에 의해 선택된 프로세스에게 넘긴다.
- 이 과정을 context swiching
이 둘은 하드웨어가 아니라 소프트웨어다. 정확히는 운영체제 내부의 기능들 중 하나를 이렇게 부르는 것이다.
CPU 스케쥴링이 필요한 경우는
- Running => Blocked (I/O 요청 시스템 콜 : 지가 요청해서 CPU 두고 나왔을 경우)
- Running => Ready ( Timer interrupt)
- Blocked => Ready( I/O 완료 후 인터럽트 : 중요한 프로세스일 경우)
- Terminate (끝나서 다음 차례 골라야 할 경우)
어려울 것 없다. 너무 당연한 경우들이다.
1,4번은 자진 반납 nonpreemptive 이고,
나머지는 preemptive(강제로 빼앗음)의 경우다. 이 영어 단어들은 꼭 암기하라고 하셨다.
Scheduling Criteria (스케쥴링 성능 척도)
1 CPU utilization (CPU 이용률) : CPU 얼마나 이용하냐
2 Throughput (처리량) : 얼마나 프로세스 처리하냐
3 Turnaround time(소요시간) : CPU 쓰러 들어와서 ~ 다 끝내고 나가는 시간
4 Waiting time(대기시간) : CPU 썼다가 대기했다가 끝날 때 까지 대기한 시간의 합
5 response time(응답시간) : CPU 처음 얻기까지 시간
CPU 스케쥴링이 얼마나 효율적인지 기준을 5가지로 나눌 수 있다고 한다.
1,2번은 시스템 입장 / 3~5번은 프로그램 입장이다.
중국집 예로 들면 쉽다.
1~2번은 사장(시스템) 입장이다.
주방장(CPU)는 고급 인력이라 놀리면 아깝다. 최대한 일을 많이 해야 한다.
- CPU utilization : 얼마나 안 쉬고 일하냐
- Throughput : 정해진 시간에 손님(프로세스) 몇 명이나 받냐
3~5번은 손님(프로세스)입장
- Turnaround time : 중국집에 들어와서 먹고 나갈 때 까지 시간
- Waiting time : 중국집 들어와서 나갈 때 까지, 코스 요리 시켰는데 코스마다 대기하는 시간들의 합
- response time : 맨 처음 음식 나올 때 까지 기다린 시간
스케쥴링 알고리즘
FCFS(First Come First Serve)
가장 생각해내기 쉬운, '선착순'이다.
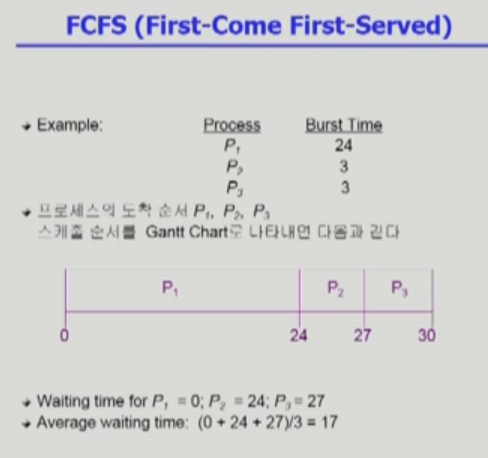
FCFS는 preemptive 방식이다. 끝날 때 까지 강제로 못 뺏는다. 그렇게 되면 어떤 문제가 생긴다?

"먼저 온 놈이 얼마나 길지에 따라 성능차이가 심하다"
먼저 온 프로세스가 100초를 쓰고, 뒤 애들이 1,2초라면, 뒤 애들은 1초 쓰려고 100초를 기다려야 한다.
이를 "Convoy effect"라 한다.
그럼 자연스럽게 어떤 알고리즘이 떠오르는가? 짧게 쓸 놈 먼저 쓰게 하자.
SJF(Shortest Job First)
- 각 프로세스의 다음번 CPU burst time을 가지고 스케쥴링 할당
- CPU burst time 짧은 놈 먼저 써라
- 두 가지 방식으로 구현 가능
- Nonpreemptive : 일단 CPU 잡으면 CPU burst 완료까지 쓸 수 있음
-Preemptive : CPU burst 중에 남은 CPU burst time보다 짧은 놈 나오면 뺏김(SRTF 라고도 함)
- 모든 알고리즘 중 평균 대기 시간 제일 짧음

먼저 Non-preemptive 방식을 보자.
0초에는 P1만 들어왔으니, 7초 먼저 사용한다. 7초 동안 P2,P3,P4가 ready queue에 대기해있고, burst time도 알고 있다.
7초 지나서 P1 끝나면, 1초 쓰는 P3가 들어가는 방식이다.

다음 preemptive 방식을 보자.
0초에는 P1 밖에 안 들어왔으니 일단 쓰고 있는다. 2초에, 4쓰는 P2가 들어왔는데, 이 때 P1은 5초 써야 한다. 너 나와.
P2가 쓰고 있는데, 4초에 1 쓰는 P3 들어온다. 야 꺼져.
이런 방식이다.
여기까지 읽었으면 당신 머리 속에 의문이 2개 남아야 한다.
"미래 CPU burst time을 어떻게 암?"
"그럼 CPU burst time ㅈㄴ 길면 계속 밀려서 못 쓸 수도 있는 거임?"
이 2가지가 SJF의 단점이다.
- starvation : 우선순위가 밀려 CPU를 영원히 할당 못 받는 상태
- 미래 CPU burst time? => 과거를 보고 '추정'밖에 할 수 없다.(수식은 넘어가겠다.)
Priority Scheduling
- 우선 순위(정수)를 각 프로세스마다 할당하고, 우선 순위 높은 놈(숫자는 낮음) 먼저 할당
- 2가지 방식으로 구현 가능 : preemptive or nonpreemptive
- SJF는 일종의 priority scheduling이다.
- 단점 : starvation : 우선 순위 낮은 프로세스는 실행 못 할수도
- 단점 해결법 : aging : 시간 지날수록 우선순위 높여줘
그럼 이제 이런 생각이 들어야 한다.
"우선순위를 뭘 보고 매기는데?"
- 정적 우선순위 : 작업 생성 때 미리 할당된 우선순위가 존재할 경우
- 동적 우선순위 : 작업 특성, 상태에 따라 동적으로 조정, 예) 실행 기간이 길 경우 먼저 받음
- 데드라인 기반 : 완료 기한이 가까우면 우선순위 높음
- 반응 시간 기반
등으로 기준을 삼을 수 있다.
☆☆☆Round Robin(RR)☆☆☆
대부분의 현대 시스템에서 실제로 사용하는 스케쥴링 알고리즘이다.
컴퓨터에 하드웨어인 타이머가 있다고 하지 않았나? 이것이 그 이유이다.
- 각 프로세스는 동일한 할당 시간(time quantum)을 가짐
- 끝나면 preemptive 당하고 ready queue의 끝으로 감
- 어떤 프로세스든 일정시간 이상 기다리지 않는다.
- 할당 시간이 너무 길면 : FIFO에 가까워 짐
- 할당 시간 너무 짧으면 : context switching overhead 커짐

Starvation은 예방을 했고, 대신 average turnaround time은 길다.
또한 간혹, 20개의 프로세스가 모두 1000초 짜리 작업을 한다고 하면,
RR 방식에서는 20 * 1000초에 20개의 프로세스가 거의 동시에 끝날 것이다.
이럴 경우 CPU가 노니까 비효율적일 수 있는데,
대부분의 경우 CPU burst time이 뒤죽박죽이라 괜찮다고 한다.
