[운영체제] CPU 스케쥴링 2 : Multi Level Queue, MultiLevel Feedback queue, Multi Processor Scheduling, Thread Scheduling
[운영체제] 반효경 - 2014 이화여대 강의
본 포스팅은
https://core.ewha.ac.kr/publicview/C0101020140401134252676046?vmode=f 강의를 참고하여 정리했습니다.
(반드시 이전 포스팅을 학습하고 읽어주세요)
Multi Level Queue
이제 ready queue를 어떻게 설계할지 알아본다. (진짜 단순한 1차원 queue인줄 알았다면 ㄴㄴ)
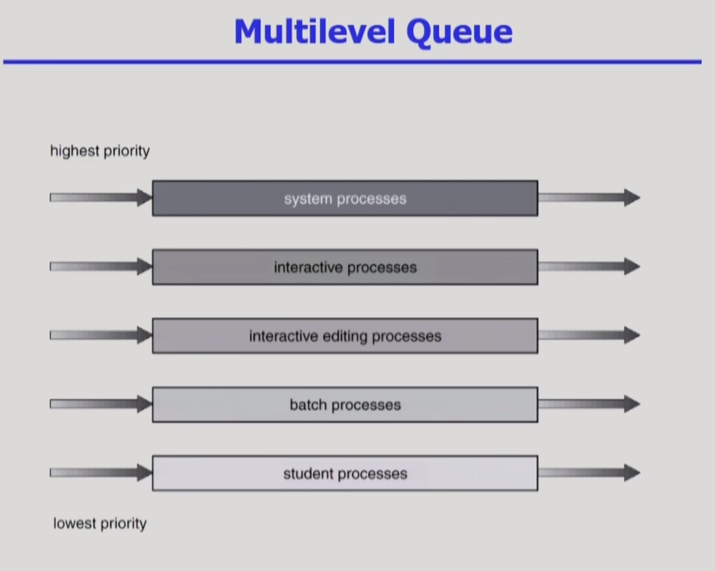
- interactive process : 사용자와 상호작용 많은 프로세스
- interactive editing process : 사용자와 상호작용 덜 있는 프로세스
- batch - CPU 작업을 많이 하는
위 순위 큐가 빌 때 까지 돌리고 없으면 아래로 내려오는 방식이다.
1순위 큐가 비어야 2순위 실행하고, 2순위 비어야 3순위 큐를 돌리는 방식.
각 큐마다 스케쥴링 알고리즘이 다를 수 있다.
- Ready queue를 여러 개로 분할
-foreground(interactive)
-background(batch- no interactive) - 각 큐는 독립적인 스케쥴링 알고리즘 가짐
-foreground - RR
-background - FCFS - 큐에 대한 스케쥴링 필요
-Fixed priority scheduling : 위에서 말한 위 순위가 비어야 아래로 내려오는
-Time slice : 각 큐에 적절한 CPU time을 할당 (fore 80%, background 20% 식으로 )
여기까지 읽었으면 2가지 의문이 들어야 한다.
- 프로세스가 생성되서 어떤 큐에 넣어줄 것인가?
- Fixed priority 방식에서 starvation 나오면 어떻게 하나?
이에 따라 좀 더 발전한 방식이
MultiLevel Feedback queue
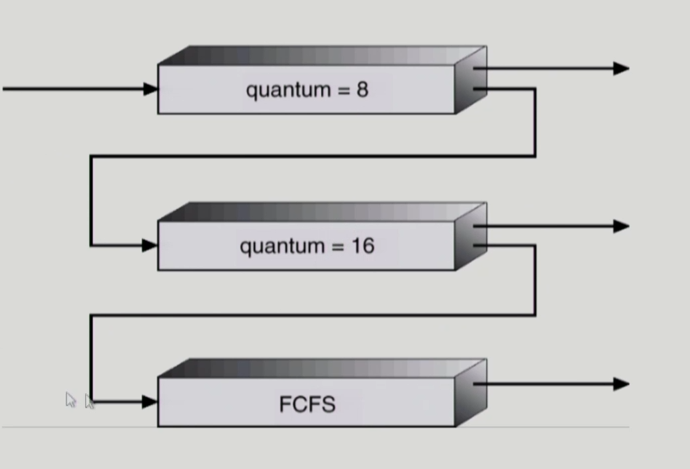
(위 그림은 예시이다. 밑에서 올라가는 큐도 있을 수 있는데, 그림은 우선순위가 떨어지는 방법만 있는 경우)
멀티 레벨 큐에서, 줄 이동이 가능하고, CPU 수행시간이 짧은 프로세스가 유리한 방식이다.
지난 포스팅의 우선순위 스케쥴링에서 aging방법을 이처럼 구현할 수 있다.
MultiLevel Feedback queue 스케쥴러를 정의하는 파라미터들
- queue 갯수
- 각 큐 스케쥴링 알고리즘
- process를 상위 큐로 보내는 기준
- process를 하위 큐로 내쫓는 기준
- 프로세스가 CPU 서비스 받으려 할 때 들어갈 큐를 결정하는 기준
위 그림을 보며 동작 방식을 생각해보자.
- 방금 생성된 프로세스는 무조건 맨 위 queue에 들어간다.
- 8 동안 CPU 잡아서 실행한다.
- 다 못 끝냈으면 밑 큐로 내려간다.
- 기다렸다가 16동안 CPU 잡아서 실행한다.
- 그래도 못 끝내면 더 밑으로 내려간다.
Multi Processor Scheduling
지금까진 CPU가 하나인 경우를 가정했는데, CPU가 여러 개인 경우를 생각해보자.
크게 다를 거 없다. 화장실 한칸이 여러 칸으로 늘어났다. 대신 조금 알고리즘이 복잡해진다.
- CPU가 여러 개일 경우 스케쥴링이 복잡해짐
- Homogeneous processor(CPU들이 동일한 모델)인 경우
- Queue에 한 줄로 세워서 각 프로세서가 꺼내가게
-반드시 특정 프로세서에서 수행되어야 하는 프로세스가 있다면 복잡해짐 - Load sharing
-일부 프로세서에 몰리지 않도록 적절히 분배하는 매커니즘 필요
-별개 큐 두기 vs 공동 큐 사용하기 - Symmetric Multiprocessing(cpu 코어들이 동일한 역할일 경우)
- 각 프로세서가 알아서 스케쥴링 결정 - Asymmetric Multiprocessing(cpu 코어들이 역할이 다를 경우)
-하나의 프로세서가 시스템 접근, 공유를 책임지고 나머지가 따름(작업반장 한놈두기)
Real Time Scheduling
정해진 시간 안에 반드시 끝내야 하는 작업이 있을 수 있다.
- Hard Real Time Scheduling : 정해진 시간 안에 반드시 끝내도록 스케쥴링해야
- Soft Real Time Scheduling : 일반 프로세스에 비해 높은 우선순위 줘야, 반드시 못끝낼 수도
이 정도까지 설명하고 넘어간다. 이거까지 고려해서 스케쥴링 짜면 ㅈㄴ 복잡해지니까
Thread Scheduling
스레드도 결국 CPU 수행단위이다. 프로세스 스케쥴링과 별로 다르지 않다.
다만, 이전에 얘기했던, '커널이 멀티 스레드의 존재를 아느냐 모르냐'에 따라 달라진다.
Local scheduling
- User level thread의 경우 사용자 라이브러리에 의해 어떤 스레드를 스케쥴할지 결정
=> 커널은 멀티 스레드들의 존재를 모른다. 그냥 CPU를 한 프로세스에게 주면, 프로세스 내부에서 알아서 스레드를 스케쥴링하는 경우
Global scheduling
- Kernel level thread의 경우 일반 프로세스와 마찬가지로 커널의 단기 스케쥴러가 어떤 thread를 스케쥴할지 결정
=> 운영체제가 멀티 스레드의 존재를 알 경우, 커널의 중기, 단기 스케쥴러 중 단기 스케쥴러로 결정한다.
Alogrithm Evaluation
지금까지 여러 스케쥴링 알고리즘, 큐 종류를 살펴보았다.
이들의 성능을 평가하려면 3가지 방법이 있다.
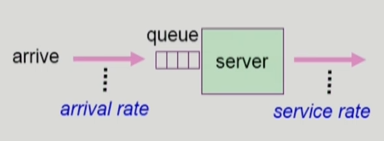
1. Queueing models(이론 한정, 올드스쿨)
- arrival rate * service rate을 통해 performance index 계산
2. Implementation(구현) & Measurement(성능 측정)
- 실제 컴퓨터에 알고리즘 구현해서 성능 비교
리눅스라면 소스 코드를 보고 알고리즘을 내가 만든걸로 바꾸고 실제로 성능 측정을 해 비교하는 방법
3. Simulation
- 모의 프로그램 작성후 결과 비교
걍 그렇구나 하고 넘어가면 된다.
