메모리 관리
(참고 강의 : http://www.kocw.net/home/search/kemView.do?kemId=1046323)
Noncontiguous allocation
Paging
- 프로세스의 virtual memory를 동일 사이즈의 page 단위로 나눔
- virtual memory 내용이 page단위로 noncontiguous하게 저장됨
- 일부는 backing store, 일부는 physical memory에 저장
basic Method
- physical memory를 동일 크기의 frame으로 나눔
- logical memory를 동일 크기의 page로 나눔(frame과 같은 크기)
- 모든 가용 frame 관리
- Page table로 logical address => physical address 변환
- external fragmentation 발생 안함
- internal fragmentation 발생 가능
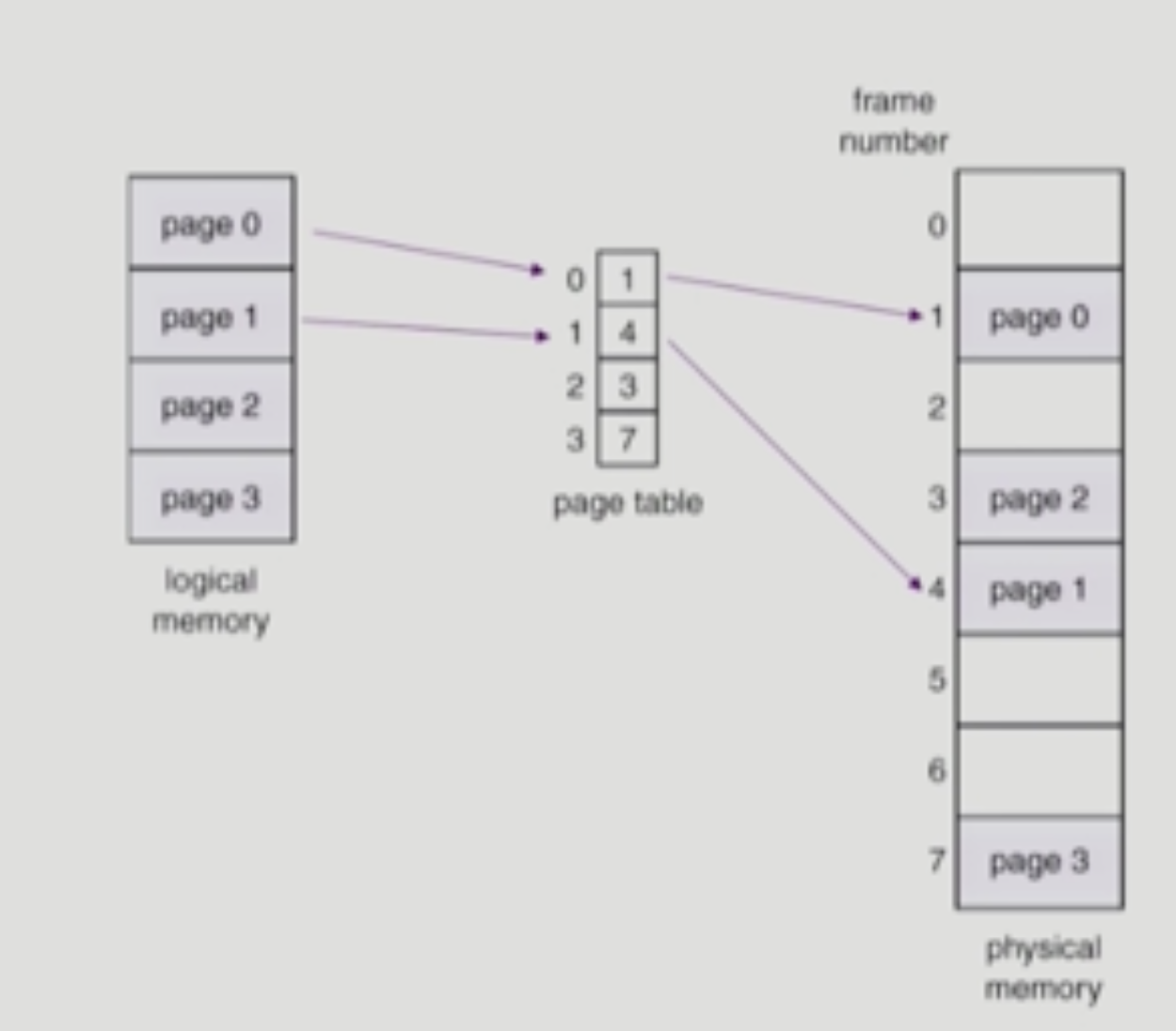
프로세스마다 page table이 존재한다.
page 번호를 인덱스로 사용해서, page n이 실제로 어디에 있는지 찾을 수 있는 것이다.
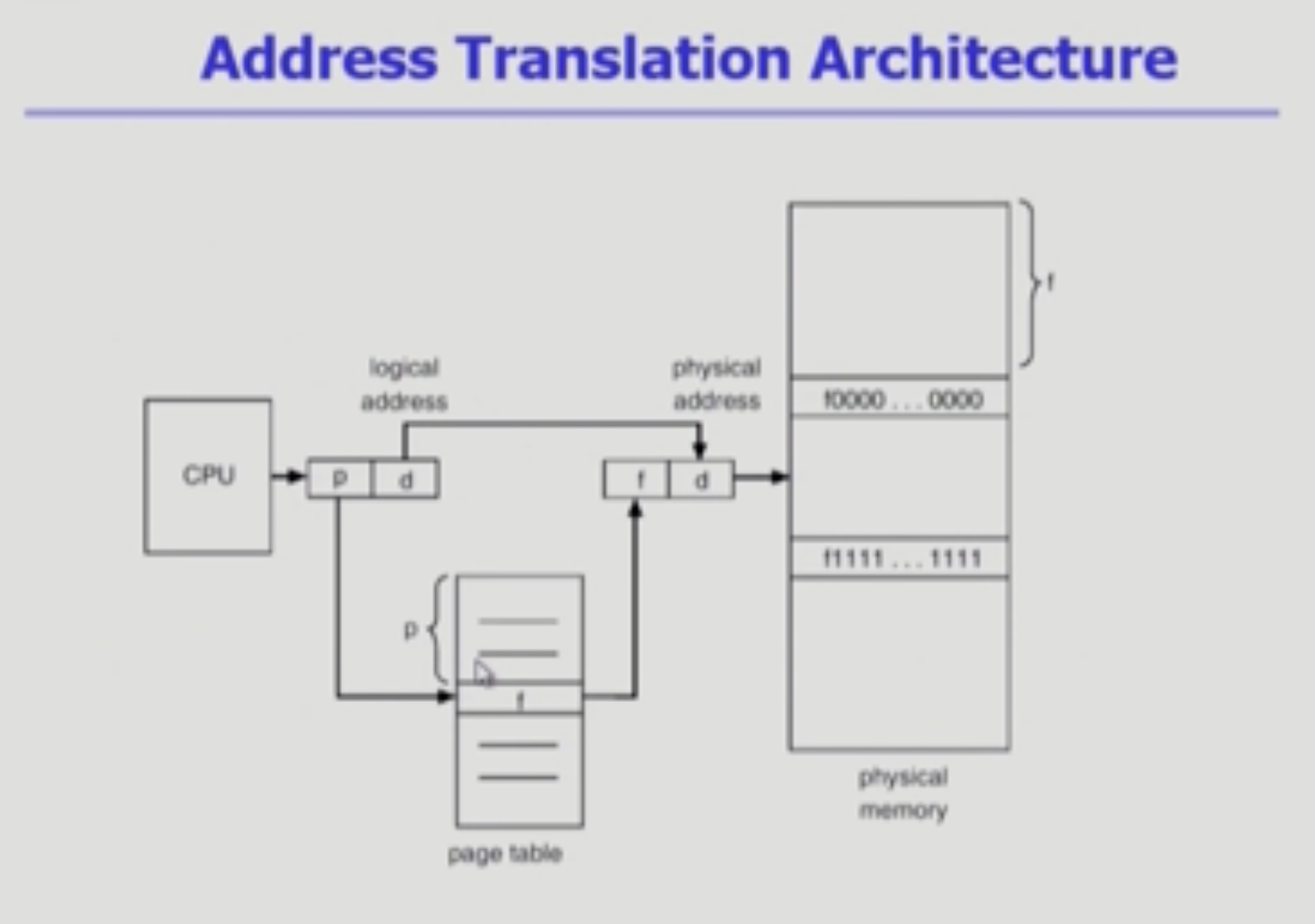
CPU는 P(page 번호)와 d(페이지 내에서 얼마나 떨어져있나)를 가지고 page table로 간다.
페이지 번호는 table의 인덱스와 동일하기에,
페이지 번호로 프레임 번호(f)를 찾을 수 있다.
메모리에서 f를 찾으면 해당 페이지의 주소를 찾을 수 있고, 그 안에서 d를 더해 정확한 위치를 가져올 수 잇다.
(d가 그대로 인 이유는 페이지 통째로 움직이기에, 페이지 내에서의 정확한 위치는
논리적 위치와 물리적 위치가 동일하기 때문이다.)
Implementation of Page Table
page table은 어디에 저장되어 있을까?
1개 프로세스를 일정 크기 page로 자르고,
이 page길이 만큼 page table이 있어야 한다.(인덱스가 페이지 번호니까)
그리고 프로세스 마다 page table이 있다.
레지스터, cpu 캐시 메모리에 들어가기엔 너무 너무 크다.
- Main memory에 상주
- Page-table base register(PTBR)이 page table을 가리킴
- Page-table length register(PTLR)이 테이블 크기 보관
- 모든 메모리 접근 연산에 2번의 메모리 액세스 필요
(page table 접근 1번 + data 접근 1번) - 속도 향상 위해 associative register 혹은 translation look-aside buffer(TLB)라 불리는 고속 lookup hardware cache 사용
MMU에서 base, limit register 2개가 paging에서는
page table을 가리키는 base register와,
page table 길이 가리키는 length register로 사용된다.
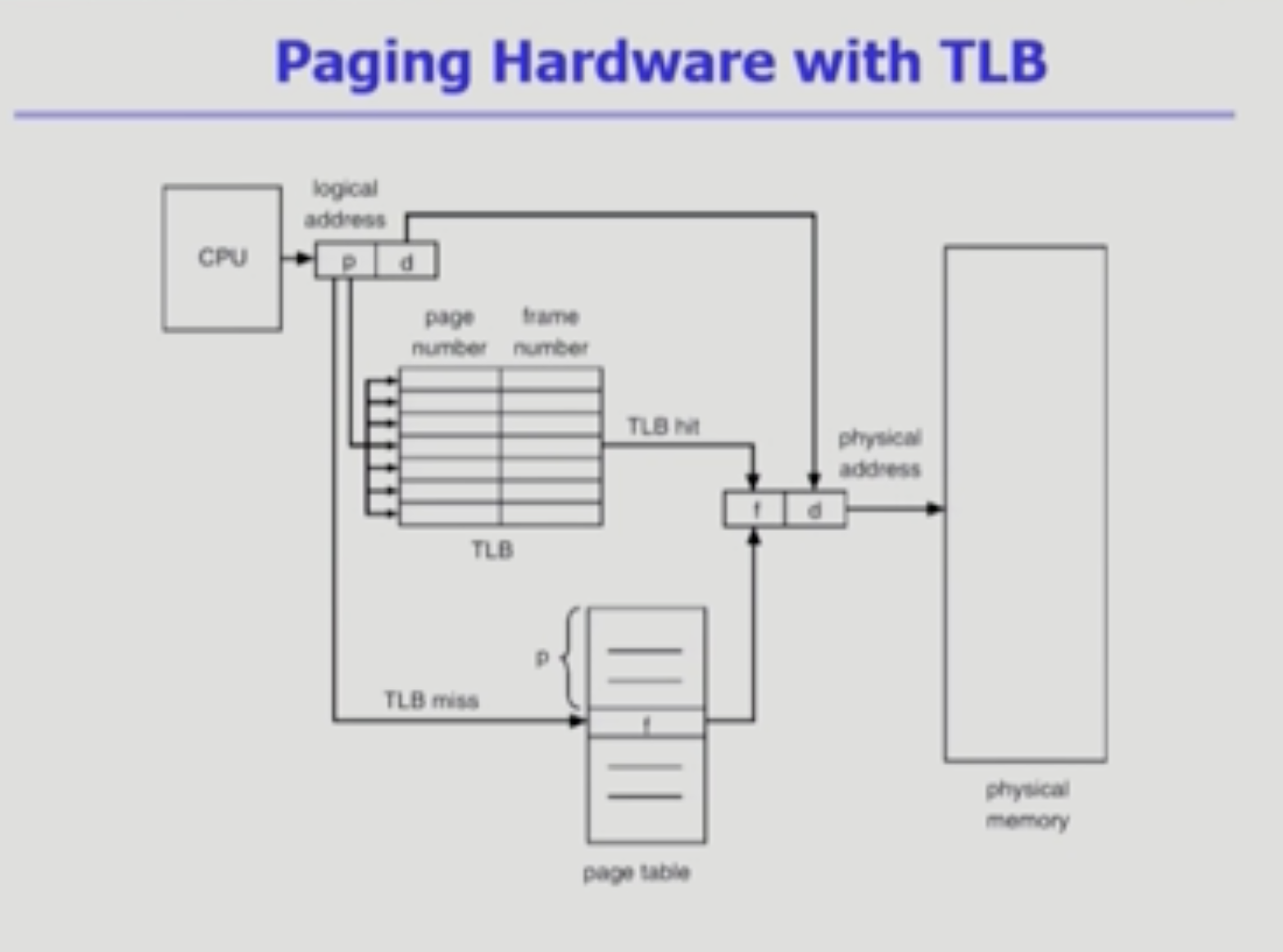
원래 2번 메모리 접근을 해야 하니, 속도가 느리다고 했다.
속도 개선을 위해 별도의 TLB를 두는 것이다.
(프로세스 마다 TLB 있다.)
마치 캐시 메모리처럼, 주소 변환을 위한 캐시 메모리인 TLB이다.
메인 메모리보다 빠른 캐시 메모리.
자주 쓰이는 페이지를 TLB에 저장하고,
page table을 찾기 전에 먼저 TLB에서 페이지가 있는지 탐색한다.
페이지 전체가 아닌 일부를 저장하고 있으니, p로 한번에 찾을 수 없다. 다 뒤져야 한다.
그래서 병렬적으로 동시에 쫙 서치하는 방법이 사용된다.
Associative Register (TLB)
- 병렬 서치가 가능
- 페이지 일부가 associative register에 보관
- TLB는 context switch 때 flush(remove old entries)됨

TLB 사용하면 그냥 page table 뒤지는 것보다 빠르다 ! 정도만 알고 넘어가자.
참고 : 32비트 vs 64비트 컴퓨터
컴퓨터 쇼핑을 위해 검색하다 한번 쯤 들어봤을 것이다.
대체 무엇이 32비트, 64비트란 말인가?
1. 데이터 처리량
한번에 처리할 수 있는 데이터 양을 말한다.
32비트 시스템은 한번에 32비트(4바이트)크기 데이터 처리 가능
64비트 시스템은 한번에 64비트(8바이트)크기 데이터 처리 가능
2. 메모리 크기 (메모리 주소 공간)
32비트 시스템은 최대 4GB 메모리를 가질 수 있다.
왜냐하면 32비트 컴퓨터는 레지스터 크기가 32비트라는 것이고,
이는 한번에 처리할 수 있는 데이터 크기가 32비트라는 것이다.
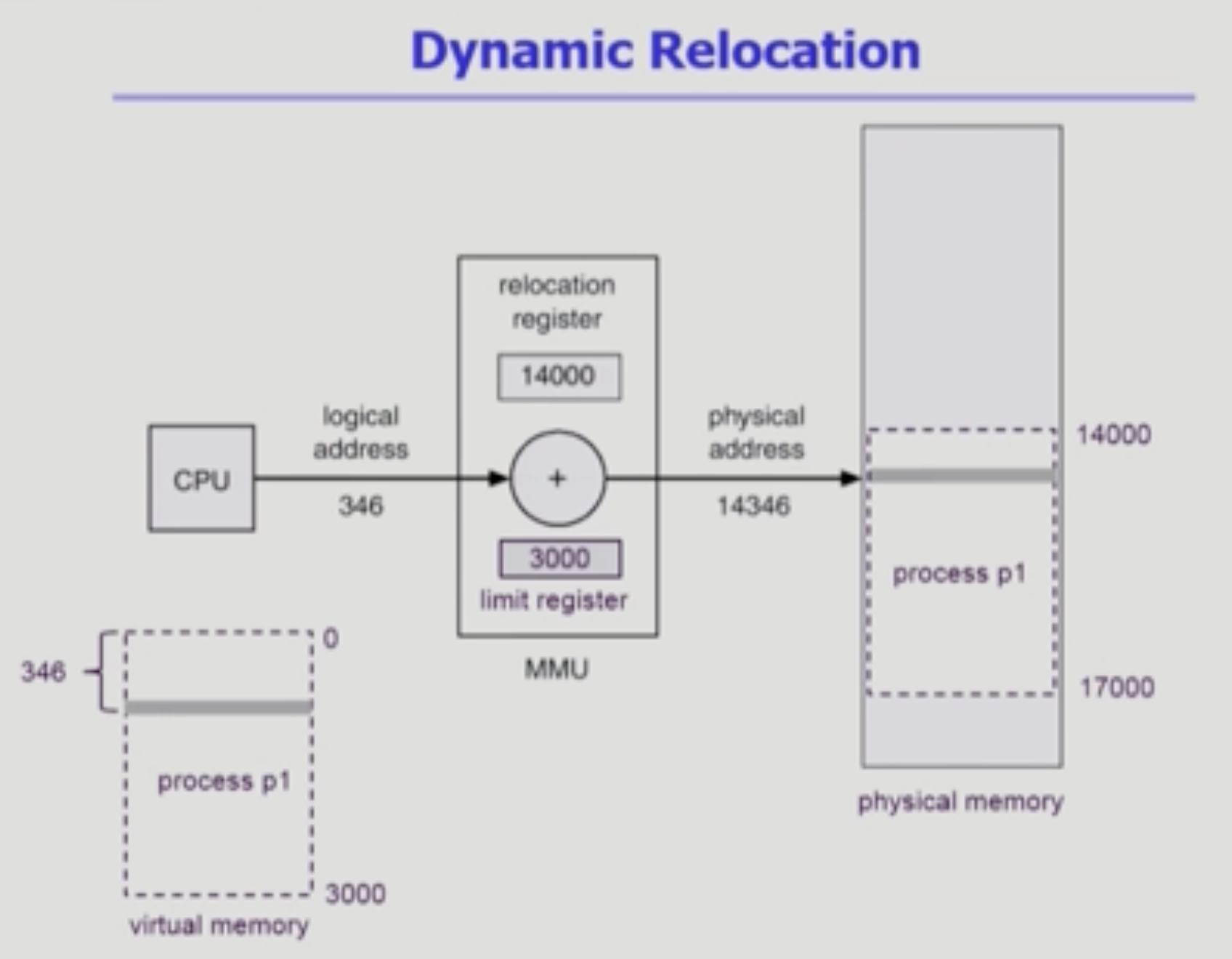
CPU가 메모리 주소를 참조할 때를 다시 보자.
"346번 가져와"
주소의 기본 단위는 비트가 아닌 바이트(byte)이다.
주소가 1 증가할 때 마다 1byte(8bit)씩 증가한다.
결과적으로 레지스터가 계산할 수 있는
주소의 맥시멈은 1byte * 2의 32승 = 4GB
이기 때문이다.
3. 레지스터 크기 32비트 vs 64비트
4. 소프트웨어 호환성
Two-level Page Table
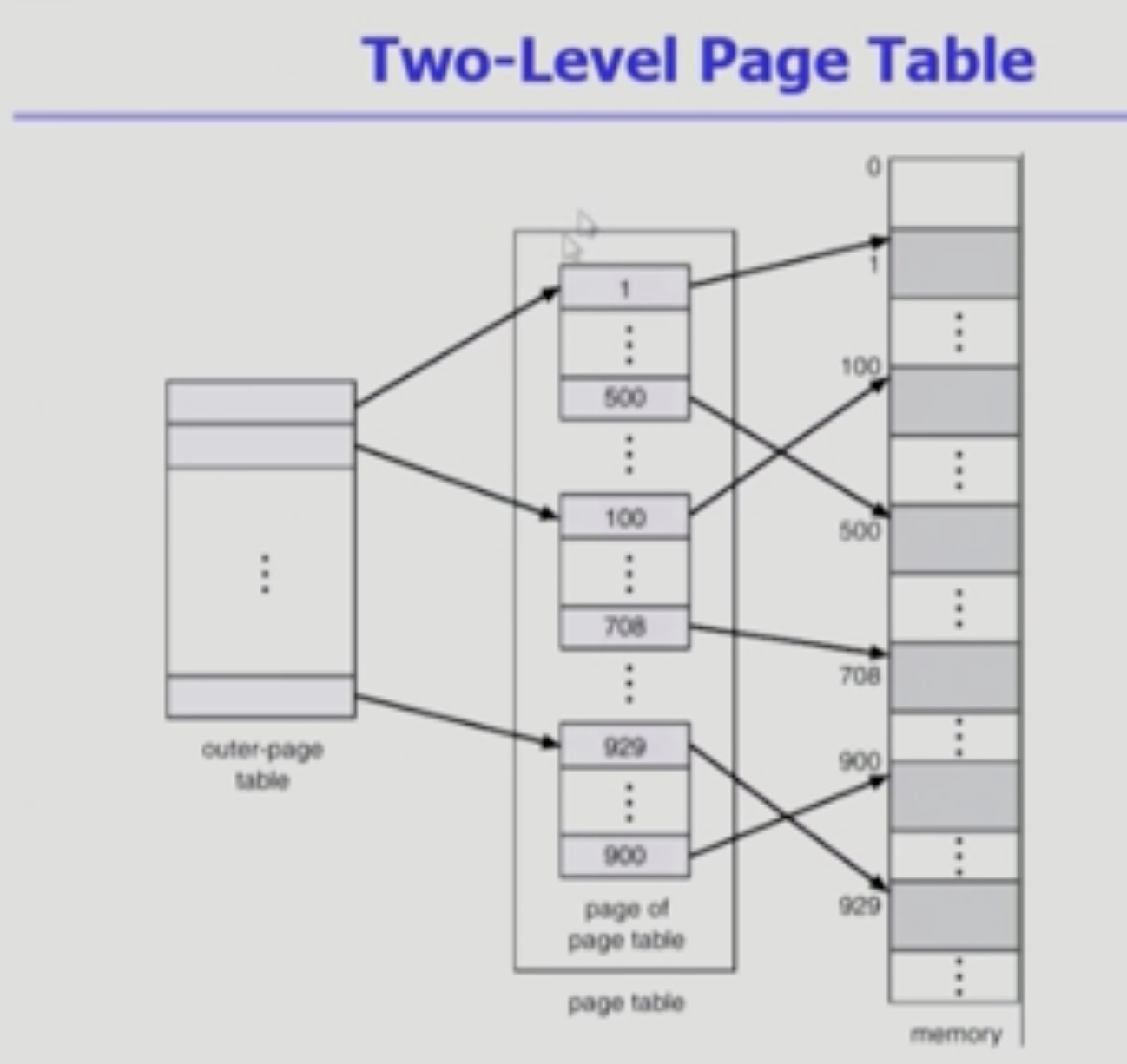
왜 2단계의 page table이 등장했을까?
- 속도 향상
- 공간 효율성 향상
둘 중 하나일텐데, search를 2번 해야 하니 속도는 아닐거고,
공간 효율성 떄문일 것이다.
현대 컴퓨터는 address space가 매우 큰 프로그램 지원한다.
(2014년 강의라 64비트가 아닌 32비트를 기준으로 설명하는 것 양해)
- 32 bit address 사용 시 : 2의 32승(4gb) 주소 공간 (RAM이 4GB)
- page size가 4K시 1M개의 page table entry 필요- 각 page entry가 4B시 프로세스 당 4M page table 필요
- 그러나 대부분 4G 주소 공간 중 지극히 일부만 사용하므로 page table 공간이 심하게 낭비됨
프로세스마다 코드, 스택, 힙 등으로 영역이 나뉘는 거 알 것이다.
그리고 빈 부분도 존재하는데, 이 부분도 페이지 번호가 매겨진다.
페이지 번호를 매겼다는건 페이지 테이블 숫자도 그만큼 늘려야 된다는 뜻이고,
쓸데없이 페이지 테이블이 존나게 커진다는 뜻이다.
그냥 page table 공간 낭비가 존나게 심하다 정도만 알고 가도 된다.
따라서
=> page table 자체를 page로 구성
=> 사용되지 않는 주소 공간에 대한 outer page table의 엔트리 값 NULL (대응하는 inner page table이 없음)

32비트 시스템에서 페이지 사이즈가 4K일 경우,
- 20 bit page number
- 12 bit page offset
으로 나누고, 다시 Page number는
- 10 bit page number
- 10 bit page offset
로 나눌 수 있다.
p1 = outer page table의 index
p2 = outer page table의 page에서의 offset(얼마나 떨어져 있나)
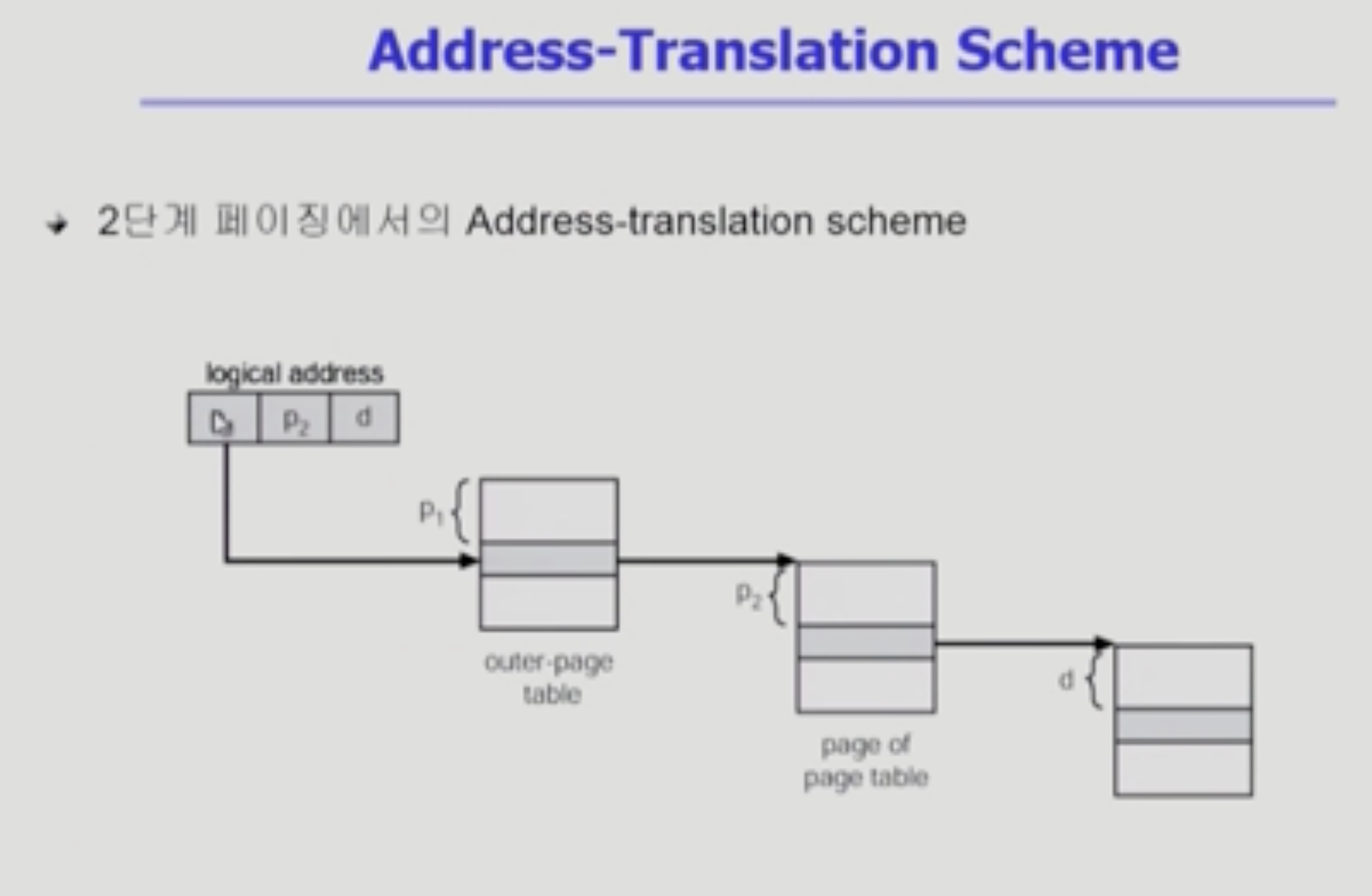
outer table에서 p1으로 안 쪽 여러 테이블 중 어떤 테이블인지 정보를 찾는다.
안 쪽 테이블에서, 아까 찾은 테이블에서 p2(offset)만큼 떨어진 곳에서 physical address의 시작을 알 수 있다.
그리고 d로 얼마나 떨어졌는지 계산해서 실제 메모리 주소를 찾을 수 있는 것이다.
