메모리 관리 3
(참고 강의 : http://www.kocw.net/home/search/kemView.do?kemId=1046323)
MultiLevel Paging and Performance
- Address space 더 커지면 다단계 페이지 테이블 필요
- 각 단계의 페이지 테이블이 메모리에 존재하므로 여러 번 메모리 접근해야
- TLB로 메모리 접근 시간 줄일 수 있음
- 4단계 페이지 테이블 사용할 때
- 메모리 접근 시간이 100ns, TLB 접근 시간이 20ns, TLB hit ratio 98%라면
- access time = 0.98 x (100 + 20) + 0.02 x (500 + 20) = 128
- 결과적으로 주소 변환을 위해 28ns 소요
(계산 시간의 경우 100ns는 실제 메모리 값에 접근할 때 필요한 거고, 4단계면 페이지 테이블 4개 있으니까 400인거임 ㅇㅋ? 20은 일단 TLB에 가서 있는지 없는지 확인을 해야 하니까 둘다 더한거고)
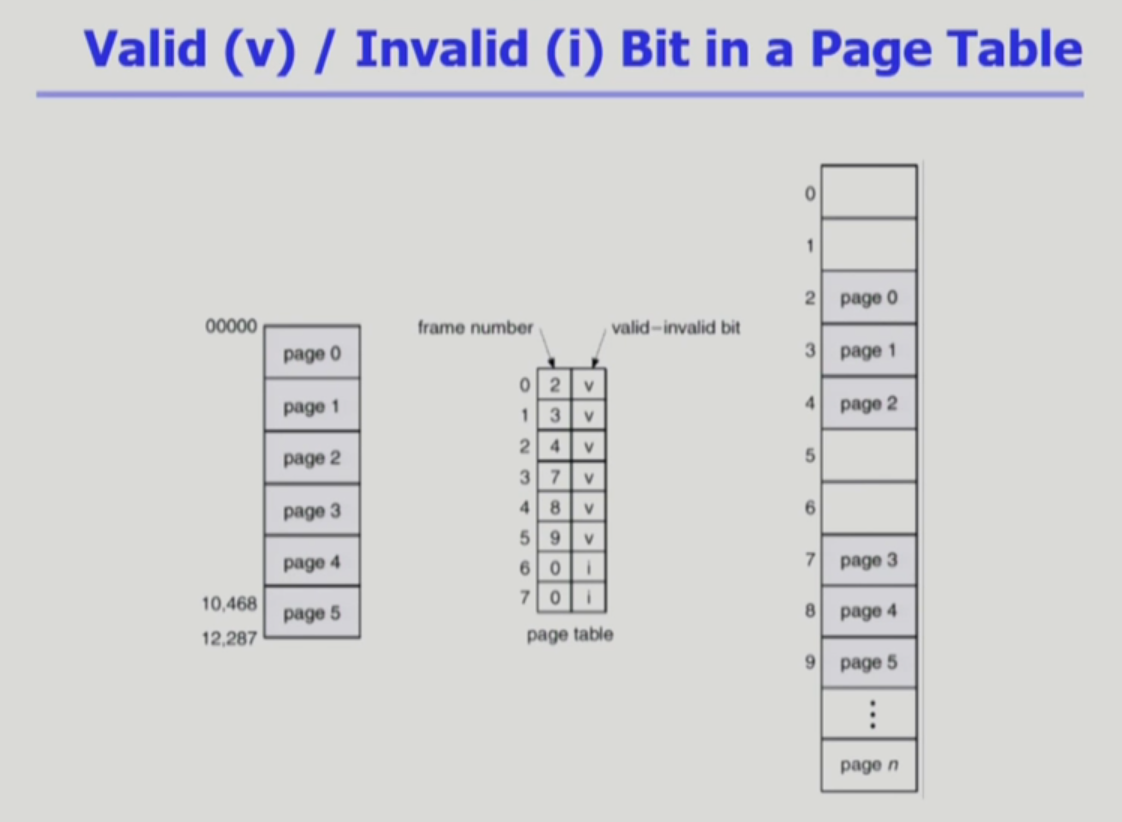
page table에서 frame number가 0이라면 메모리에 페이지가 없다는 뜻인데,
굳이 다시 한번 valid, invalid로 현재 물리 메모리에 페이지가 없다는 뜻을 알려주는 이유는 뭘까?
Memory Protection
PageTable 각 entry 마다 아래의 bit들을 둔다.
Protection bit
- page에 대한 접근 권한 (read/write/read-only)
Valid-invalid bit
- valid : 해당 주소 frame에 유효한 내용이 있음을 뜻함 (접근 허용)
- invalid : 유효한 내용이 없음 (swap area에 있는 경우)
Protection bit은 다른 프로세스에 접근하는 걸 방지하는 용이 아니다.
그런건 애초에 주소 변환시에 걸러진다.
page는 stack, data, code 영역들 중에 하나일텐데, code는 읽기만 해야 하고, stack은 쓸 수도 있고, 이렇게 역할이 다르지 않은가. 그걸 표현하기 위해 존재하는 것이다.
Inverted page table
page table이 매우 큰 이유
- 모든 process 별로 그 logical address에 대응하는 모든 page에 대해 page table entry가 존재
- 대응하는 page가 메모리에 있든 없든 page table에 entry로 존재
몇 번 봤다. 페이지 번호가 page table의 인덱스와 일치하기에, 빈 페이지라도 할당해야 하니까.
Inverted page table
- Page frame 하나당 page table에 하나의 entry를 둔 것
- 각 page table entry는 각각의 물리적 메모리의 page frame이 담고 있는 내용을 표시(pid,logical address)
- 단점 : 테이블 전체 탐색해야
- 조치 : associative register 사용 (비쌈)
뭔소린지 모르겠지? 아래 그림을 보자.
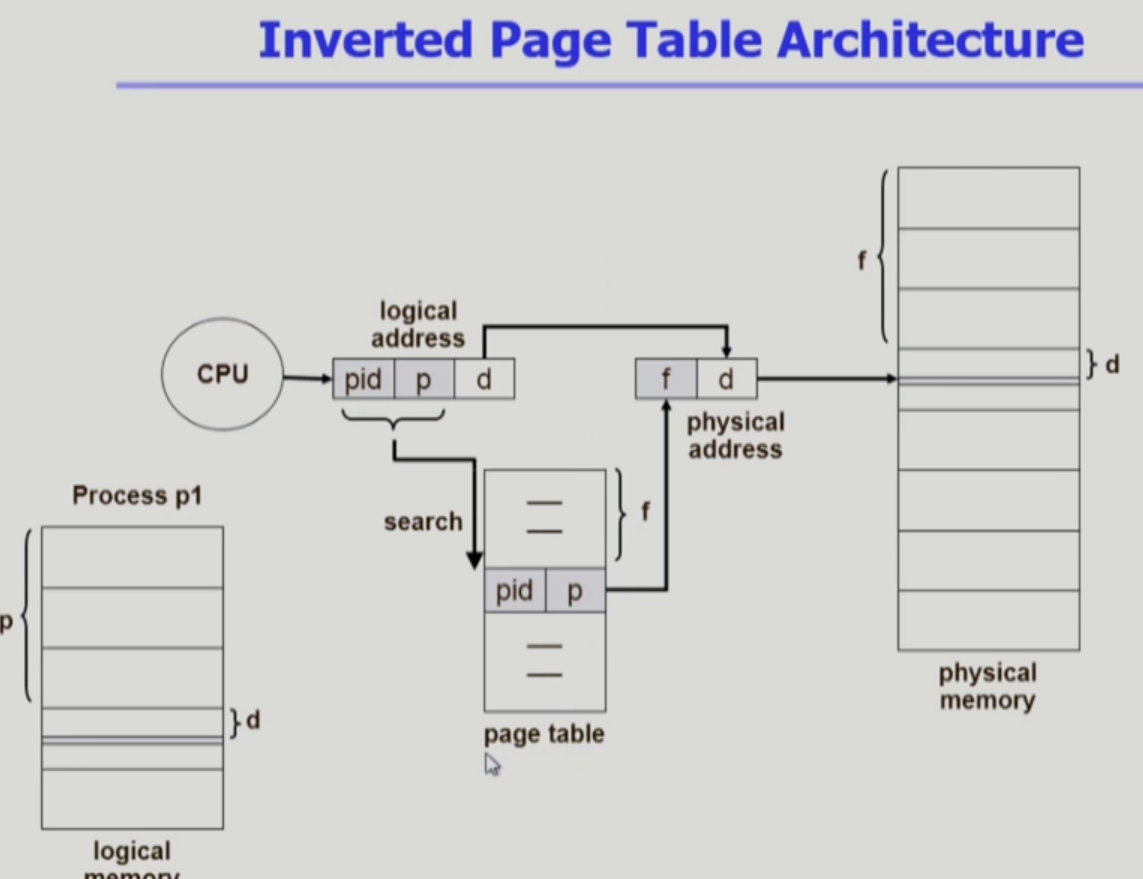
이제 모든 프로세스는 하나의 페이지 테이블로 관리한다.
대신 프로세스를 구별해야 되니까 Process-id(PID)가 있어야 겠지.
CPU는 PID와 페이지 번호(p)를 가지고 page table에 간다.
전부 다 뒤져야 한다. 모든 프로세스들이 섞여 있으니까.
찾으면 맨 위부터 얼마나 떨어져 있는지(f)값을 구할 수 있을 것이다.
이 f와 d로 물리적 메모리에 어디 있는지 찾을 수 있다.
page table 전부 뒤져야 한다고 했는데, TLB처럼 병렬으로 싹다 동시에 찾아야 효율이 나올 것이다.
Shared code
shared code
- re-entrant Code (=pure code)라고도 불린다.
- read-only로 하여 프로세스 간에 하나의 code만 메모리에 올림
- shared code는 모든 프로세스의 logical address space에서 동일 위치에 있어야
Private code and data
- 각 프로세스들은 독자적으로 메모리에 올림
- Private data는 logical address space 아무데나 둬도 무방
컴퓨터에서 한글 프로그램을 3개 실행해놨다고 하자.
프로세스 3개가 생성될 것이고, 각 프로세스에서 뭘 타이핑 했냐에 따라 data,stack은 달라지겠지만
(1: 안녕하세요/2 : hello/3 : hi)
프로그램 code는 3개 다 동일할 거 아닌가? 이런 것들은 한번만 올리면 얼마나 좋을까?
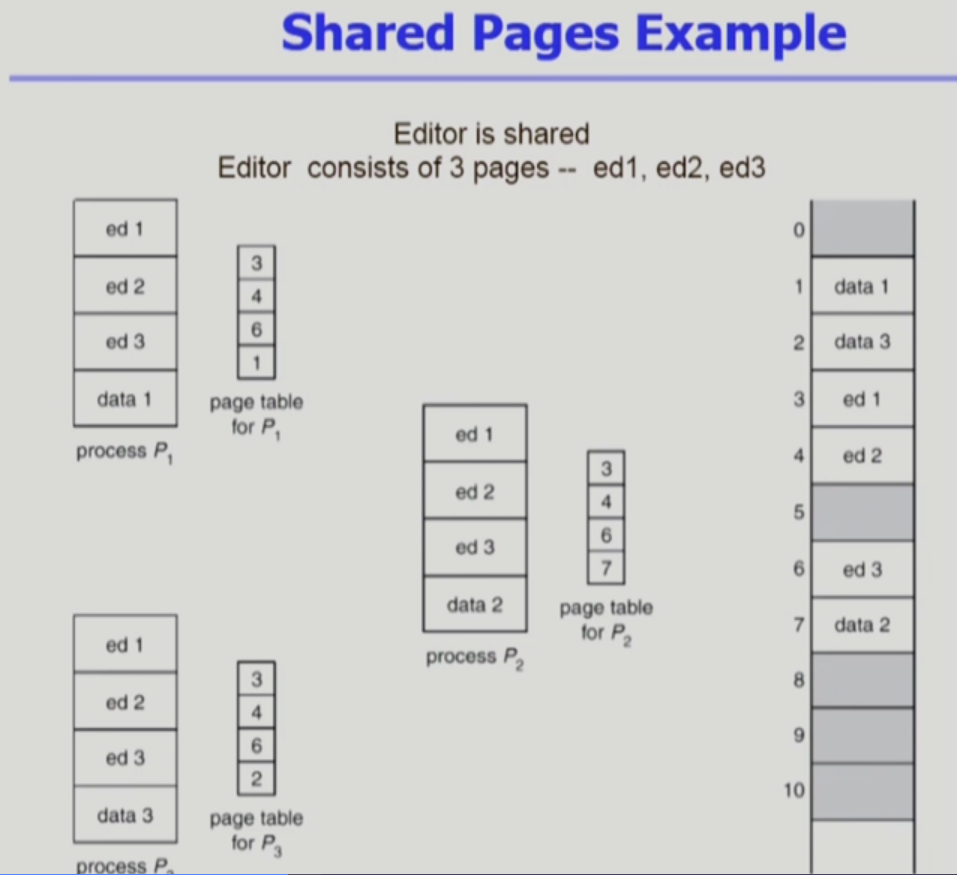
프로세스 1,2,3 모두 ed1,2,3가 겹친다면, 한번만 올리는 것이다.
대신
"shared code는 모든 프로세스의 logical address space에서 동일 위치에 있어야"
는 것인데,
logical address가 ed 1 / 2 / 3 순서로 모두 동일해야 한다는 것이다.
왜?
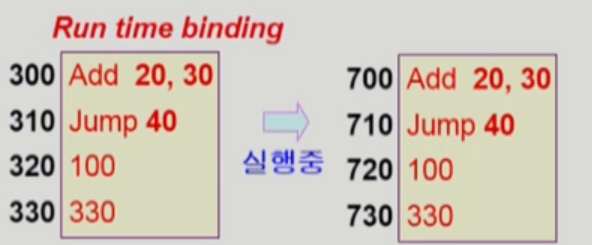
code 안에 logical address가 적혀있는데, 저 위의 20,30의 위치가 동일해야 참조해서 불러올 거 아닌가?
여기까지가 불연속 메모리 할당(Noncontiguous allocation) 중 Paging 방법이었다.
다음은 Segmantation이다.
Segmentation Architecture
paging이 동일한 크기의 page로 잘랐다면,
segmentation은 "의미" 단위로 자른다.
- Logical Address는 2가지로 구성 : segment-number,offset
- Segment table
- 각 entry에는- base : 물리적 주소의 segment 시작점
- length : segment 길이
- Segment-table base register(STBR)
- 물리적 메모리에서의 segment table 위치 - Segment-table length register(STLR)
- 프로그램이 사용하는 segment 수- segment number s < STLR이어야 한다.
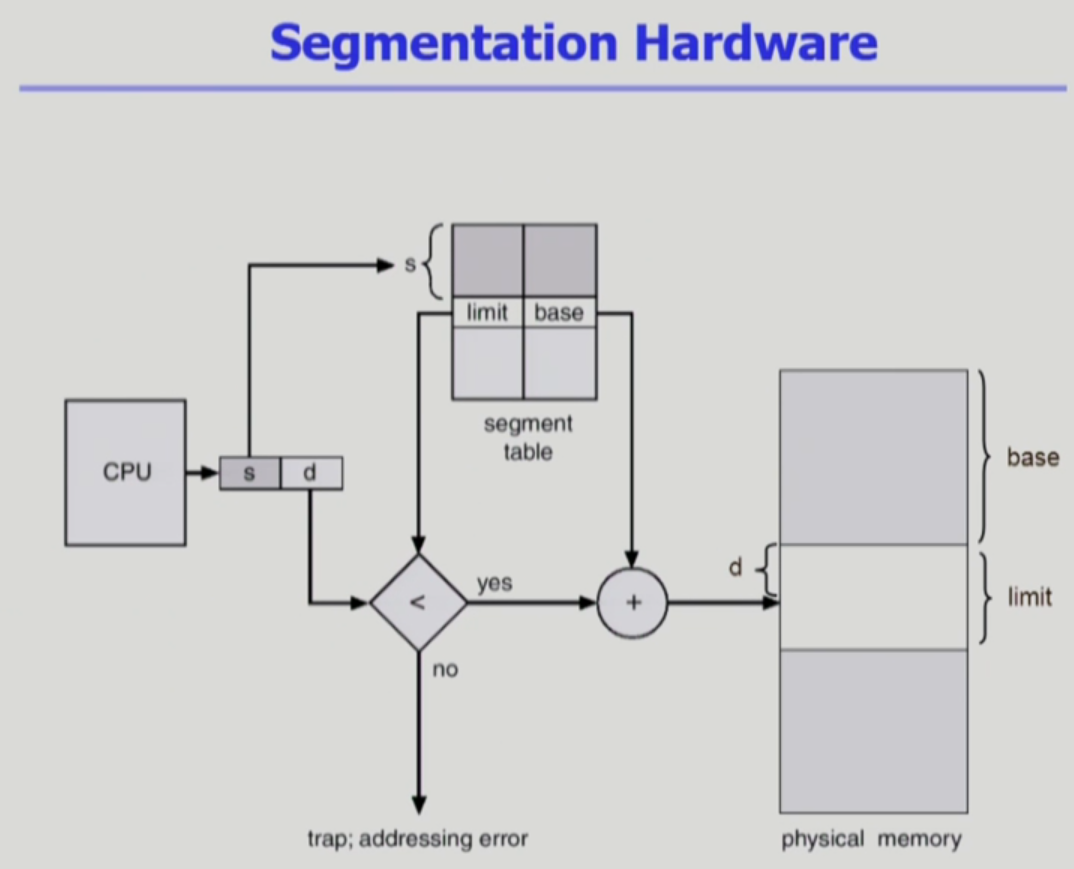
2가지 필터가 있다.
-
Segment-table length register(STLR)에 프로그램이 사용하는 segment 수를 저장한다고 했는데,
만약 s가 더 크면, 말이 안된다. 탈락! -
offset인 d가 limit보다 큰 값을 요구한다? 탈락!
segment table은 page table보다 많은 정보가 들어간다. 왜? 크기가 다 다르니까!
따라서 frame이 아닌 base로 정확한 위치를 찾아야 한다.
(paging에서는 몇 번 프레임 하면 바로 찾을 수 있었다. 왜? 크기가 다 같으니까)
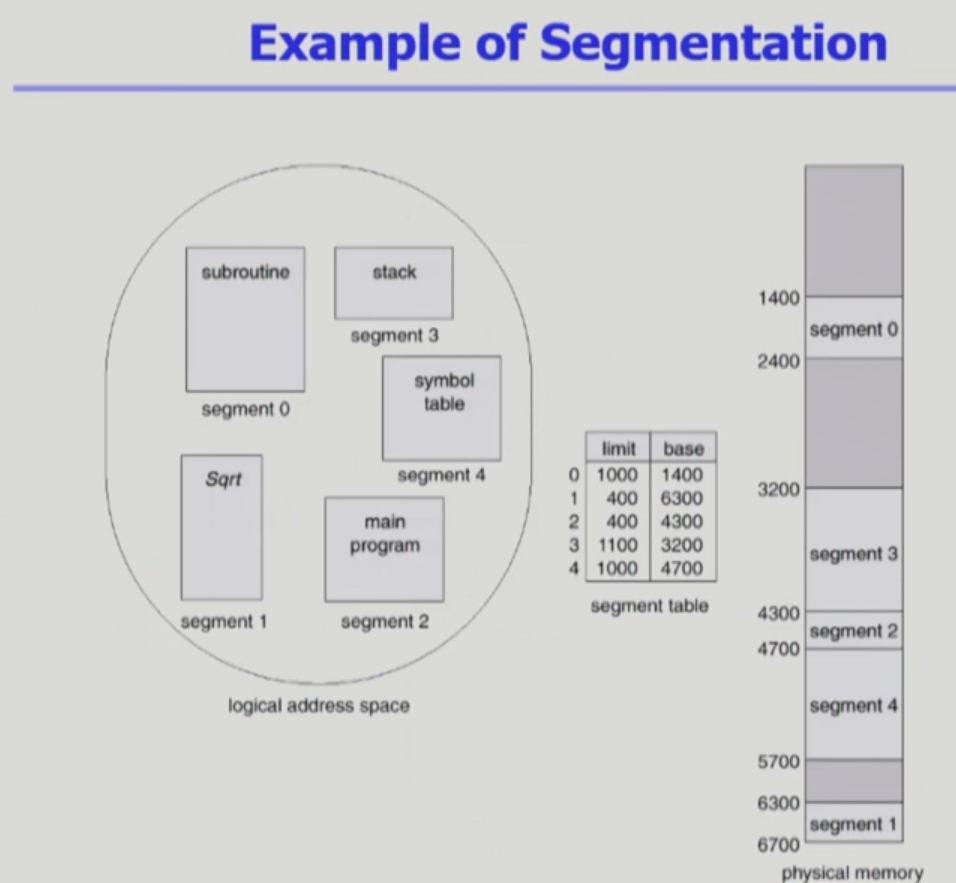
이렇게 한 프로세스를 여러 의미있는 단위인 segment로 잘라 메모리에 적재한다.
특징
Protection
- 각 세그먼트 별 protection bit이 있음
- Valid / Invalid bit
- Read/Write/Execution 권한 bit
Sharing
- shared segment
- same segment number
의미 단위로 잘랐으니 공유, 보안에 있어 훨씬 효과적이다.
Allocation
- first fit/ best fit
- external fragmentation 발생
segment 길이가 동일하지 않으므로 가변분할 방식과 동일한 문제점 발생
