오늘의 짤 : 나쁜 습관은 하루면 몸을 잠식한다.

오늘의 컨디션 : 4(아침) => 6.2 / 10
늦은 밤 운동 + 부족한 수면 시간으로 몸이 무너지는 것 같았다. 거기에 어제 늦잠 하루 잤다고 악마가 유혹했다. 오늘도 좀 더 자면 어떻냐고, 너 이미 1주일 치 미리 해놨다며 라고. 근데 어찌어찌 책상에 앉아 정신을 차리게 되었다. 페어 시간 끝부턴 졸 정도로 힘들었지만, 그건 뭐 끝날 즘이니까 괜찮지
무엇을 배웠나 ? : 자료 구조
- 자료 구조 : 여러 데이터 묶음을 저장하고, 사용 방법 정의
- 데이터 : 실생활 구성하는 값. 분석 정리 활용이 되어야 의미 있음
- 필요에 따라 데이터 특징을 잘 파악하고 정리하고 활용해야
- 데이터를 체계적으로 정리하여 저장하는게 활용할 때 좋겠지?
- 자주 등장하는(코테) 자료 구조 - Stack, Queue, Tree, Graph
- 다 특정 상황 해결에 특화. 많이 알 수록 바로 바로 적용 가능하겠지?
Stack
쌓다. 데이터를 순서대로 쌓는 구조. 입출력 하나의 방향으로 이루어진 제한적 접근
LIFO(Last In First Out) 혹은 FILO(First In Last Out)
push: 넣기 / pop: 빼기
하나씩 넣고 빼고 + 하나의 입출력 방향
예시 : 브라우저 앞으로 뒤로 가기
Queue
대기 행렬 (톨게이트, 진입 순서대로 통과)
LILO or FIFO
enqueue / dequeue
입력 순서대로 처리할 때 사용, 데이터 입 출력 방향 다름. 하나씩
컴퓨터 장치들 사이 데이터 주고 받을 때 속도, 시간 차이 극복위해 임시 기억 장치 자료구조로 queue 사용 : 버퍼
Graph
복잡한 네트워크 망 모습
구조 : 직접적 관계 있으면 선, 간접이면 거쳐서
점 : 정점 (vertex)
선 : 간선 (edge)
언제 사용? : 가장 빠른 경로 or 두 정점 사이 관계 있는지 확인
인접 리스트 : 각 정점이 어떤 정점과 인접하는지 리스트 형태로 표현
인접 리스트 : 메모리를 효율적으로 사용하고 싶을 때(연결 가능한 모든 경우의 수 저장해 메모리 많이)
예시 : 검색 엔진, sns, 길찾기
그래서 Graphql이었구나
비 가중치 그래프 : 이어진 거 밖에 정보 없음
가중치 그래프 : 연결 정도(거리 등)
인접 정점(adjacent vertext) : 직접 연결되어 있는 정점
무향, 방향 그래프 : 단방향이냐 양방향이냐
진입차수(in-degree) / 진출차수(out-degree)
자기 루프 : 간선이 바로 자기한테 올 때
사이클 : 한 정점에서 출발해 여러 거쳐서 나한테 올때
Tree
단방향 구조, 하나의 뿌리로부터 가지 사방으로
깊이 : root 0 / 그 밑 1
레벨 : 같은 깊이 가지고 있는 노드 묶어서, 형제 노드
높이 : 리프 노트 기준으로 루트까지의 높이
서브 트리 : root에서 뻗어 나오는 큰 트리 내부에 트리 구조를 갖춘 작은 트리
이진트리(binary) : 자식 노드가 최대 두개인 노드들의 트리
정 이진트리 (Full binary tree) : 각 노드가 0 or 2
포화 이진트리(Perfect) : 정 이진 + 완전 . 레벨 동일하면서 꽉 차있는
이진 탐색트리(binary search) : 모든 왼쪽 자식 값이 루트나 부모보다 작고, 오른쪽 자식은 루트나 부모보다 큼
트리 순회 : 목적을 위해 모든 노트 한 번씩 방문 (무조건 왼쪽부터)
전위 순회(preorder) : 왼쪽따라 확인하면서 내려가고, 끝나면 하나 올라와서 오른쪽
중위 순회(inorder) : 확인 안하고 왼쪽 끝 내려가 확인 후, 올라와서 확인, 오른쪽 확인 후 올라가 올라가
후위 순회(postorder) : 확인 안하고 왼쪽 끝 확인 후, 그 옆 확인, 부모로 올라가
- 그래프 탐색 : 모든 정점들 한 번씩 방문
- BFS(Breadth First Search) 너비 우선 탐색 : 최단 경로 찾을 때, 같은 레벨 쭉, 다음 레벨 쭉 찾으면 끝
- DFS(Depth First Search) 깊이 우선 탐색 : 미국가는 비행기 찾을 때, 하나 경로 끝까지 내려가면서 파고 없으면 다음
심화 1. Linked List 연결 리스트
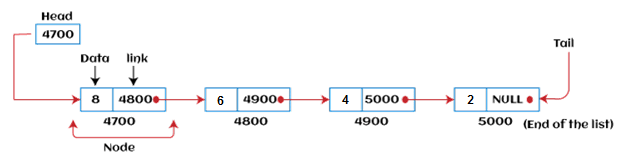
- C, JAVA의 배열 : 크기 고정, 못 늘려
- Linked List 자료 구조 : 선형으로 그룹화된 데이터 집합, 데이터 + 다음 데이터 주소 포함, 흩어진 공간에 이어진
- 배열 : 연속된 공간에 메모리 차지, 데이터 넣으려면 나머지 다 이동하고 집어 넣어야
- 특징 1. 노드 추가 삭제 빠르고 쉽다(배열은 다 이동시켜야 하는데 얜 앞뒤 주소만 바꾸면 돼)
- 특징 2. 노드 값 찾으려면 최대 전체를 순회해야(배열은 다 붙어있는데 얜 흩어져 있잖아. 마지막 찾으려면 다 돌아야돼)
- 어디에 사용 ? : 삽입 삭제 중요한 곳 + 동적 기억 장소 관리(실행되는 작업에 필요한 크기만큼 메모리 할당) + garbage collection (참조 자료형의 데이터 타입을 관리하는) + 해시 테이블 충돌시 chaining 사용할 때 활용
심화 2. Dequeue(Double Ended Queue) 양방향 대기열 열려있는
- stack + queue 사용 가능 (원하는 대로 통제 가능)
- 양방향 데이터 추가 삭제 용이
- 양방향 끝 아니면 안돼
심화 3. Hash Table
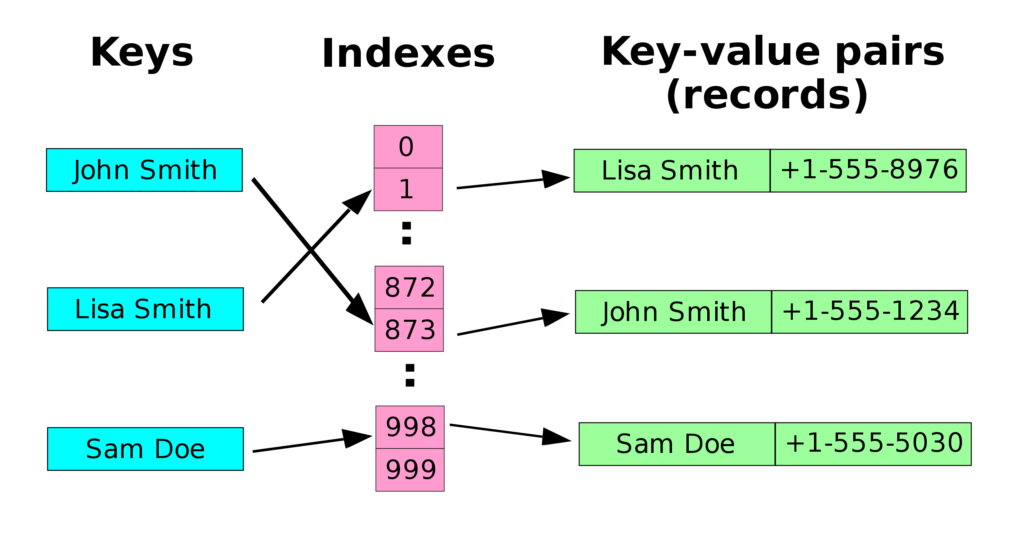
구성 요소
- key : 해시 함수의 입력 값
- 해시 함수 : 키를 해시로 바꿔주는 역할
- 해시 : 키를 해시함수로 돌린 결과. 저장소에서 데이터와 매칭되어 저장. 배열의 색인과 같이 사용
- 데이터 : 저장소에 최종 저장되는 값으로 색인과 매칭되어 저장
- 특징 : 저장, 삭제, 검색이 0(1)의 시간 복잡도, but 해시 충돌 가능성, 미리 저장공간 만들어놔야 돼 공간 효율성 떨어짐, 해시 함수 의존도 높음
- 해시 함수에 키 넣어 해시값과 색인 찾아 저장, 삭제, 검색
심화 4. Heap Tree
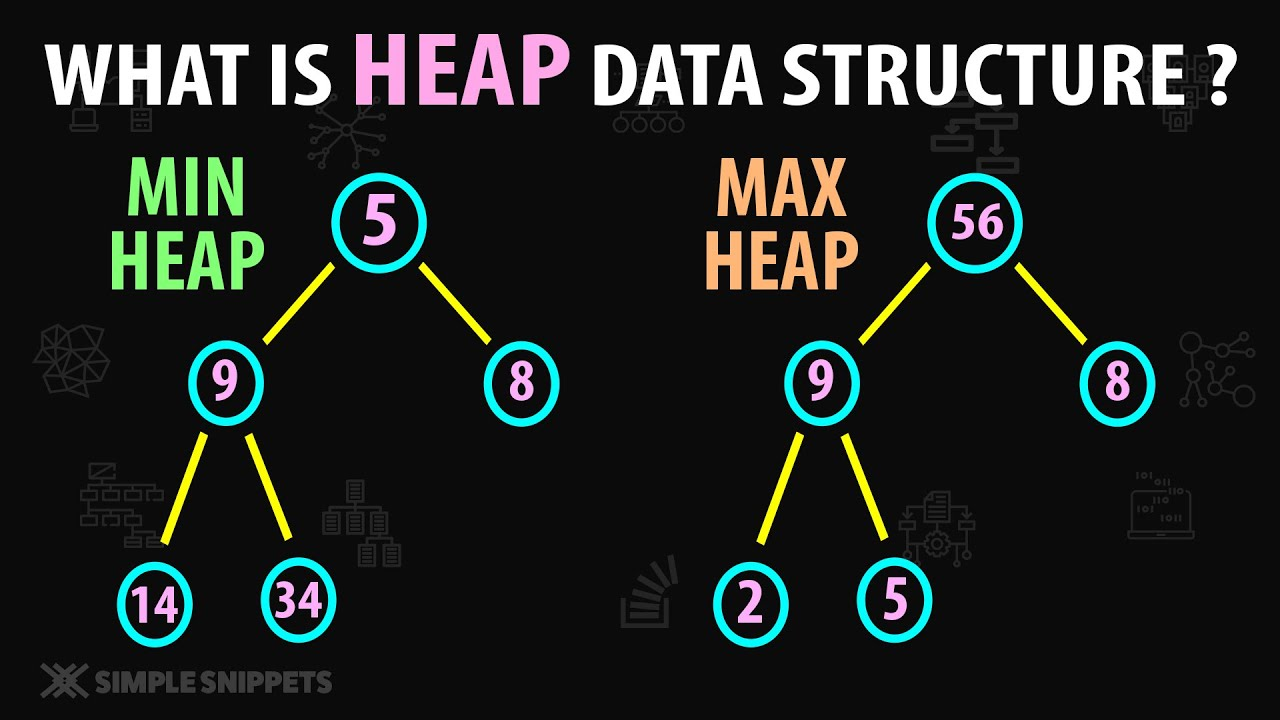
- 트리인데 우선순위에 따라 빠르게 자료 검색할 수 있는 구조
- 느슨한 정렬 구조 : 부모는 자식보다 항상 크거나 (작거나), but 자식 노드 끼리 좌우 정렬 맘대로
- 완전 이진 트리로 이루어짐
- 일반적 이진 탐색 트리와 다르게 중복값 저장 가능 >> 단순히 최대/최소 찾아내기 위한 구조이기 때문에
- 최소 힙 / 최대 힙
- 최대 최소 검색 : 그냥 루트만 보면 끝
- 삽입 : 맨 마지막에 넣고, 위랑 비교 하면서 올려
- 삭제 : 루트 지우고, 루트에 마지막 노드 넣어. 그리고 내려(둘 다 작으면 큰 값과 바꿔)
- 배열화 : 빈 노드 없으니까, 위치 찾기 쉽게 0번째 인덱스 안 씀
- depth는 1,3,7,15 대로 깊이 늘어남
- 부모 인덱스 x 2, 부모 인덱스 *x 2 + 1이 자식 노드 인덱스
- 사용 : 우선순위 큐, 힙 정렬
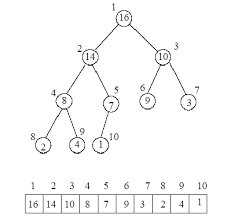
심화 5. Priority Queue
- 선입선출이 아닌 우선 순위 기준 삭제
- 우선 순위 같으면 삽입된 시점으로 삭제
- 배열, 연결 리스트, 힙 기반으로 구현 가능 but 힙 트리가 가장 효율 좋음
// 우선순위 저장 위해 사용되는 클래스 정의
class QElement {
constructor(element, priority)
{
this.element = element;
this.priority = priority;
}
}
// 우선 순위 큐 클래스
class PriorityQueue {
constructor()
{ this.items = [];
}
// 메소드들
// 삽입 메소드
enqueue(element, priority)
{
// qElement 생성
const qElement = new QElement(element, priority);
let contain = false;
// 전체 데이터 순회하며 우선 순위에 맞는 위치 탐색
for(let 1 = 0 ; i < this.items.length ; i ++) {
if(this.items[i].priority > qElement.priority) {
this.items.splice(i,0,qElement);
contain = true;
break
}
}
// 가장 낮은 우선 순위면 마지막에
if(!contain) {
this.items.push(qElement)
}
// 삭제 메소드 shift() = 첫 번째삭제하고 반환
dequeue() {
if(this.isEmpty())
return "우선 순위 큐가 비어 있습니다.";
return this.items.shift();
}
// 첫, 끝 반환 걍 this.items[0], this.items[this.items.length -1]세션 리뷰 (고차 함수)
- 매개 변수 vs 인자
함수 선언할 때 쓴 받는 값 : 매개 변수 (추상적)
함수를 사용할 때 넣는 값 : 인자 (구체적)
- 고차 함수
콜백 함수 : 콜백 함수를 받는 함수
고차가 콜백일 수도, 콜백이 고차일 수도
메소드 : 객체 내부 함수(arr.map or arr["map"])
arr.reduce((acc,cur))에서 초기값 안 넣으면 1번이 acc에, 2번이 cur에, 리턴 값을 다시 acc에
추상화를 통한 효율성 증대!
