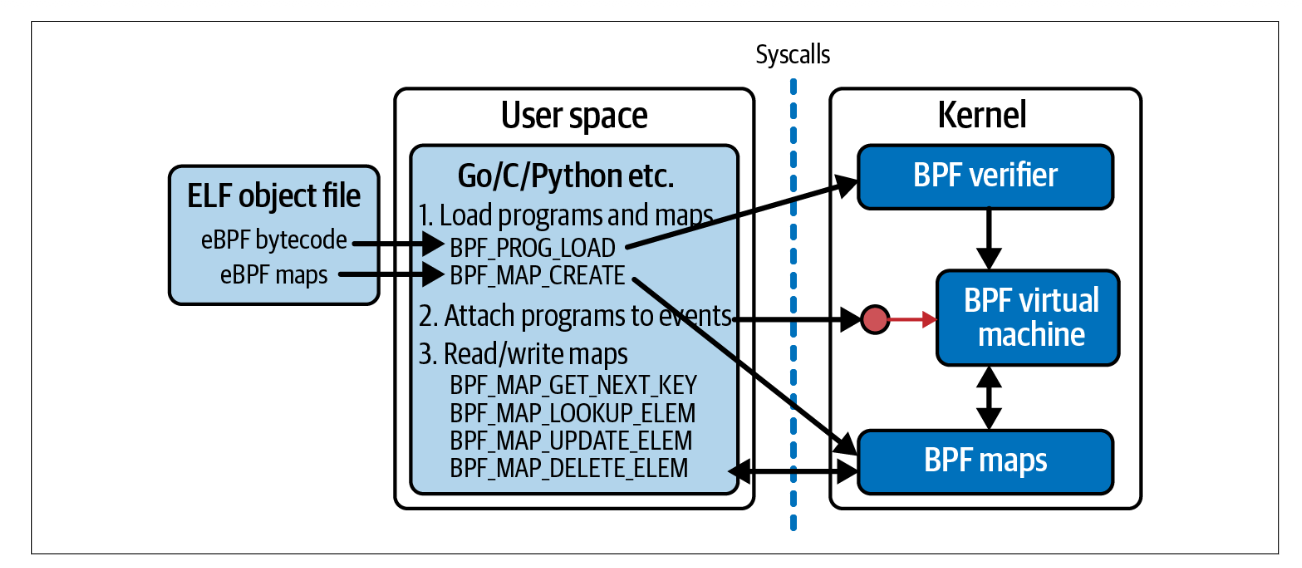
4. The bpf() System Call
사용자 공간 애플리케이션이 커널에게 어떤 작업을 대신 수행하도록 요청할 때는 시스템 콜을 사용한다. 따라서 사용자 공간 애플리케이션이 eBPF 프로그램을 커널에 로드하려면 반드시 시스템 콜이 필요하다. 실제로 bpf()라는 시스템 콜이 존재하며, 이 장에서는 이를 통해 eBPF 프로그램과 맵을 로드하고 상호작용하는 방법을 설명한다.
또한 커널에서 실행되는 eBPF 코드는 맵에 접근하기 위해 시스템 콜을 사용하지 않는다는 점을 주목할 필요가 있다. 시스템 콜 인터페이스는 오직 사용자 공간 애플리케이션에서만 사용된다. 대신 eBPF 프로그램은 헬퍼 함수(helper function)를 이용해 맵을 읽고 쓰며, 이는 앞선 두 장에서 이미 예시를 통해 확인했다.
eBPF 프로그램을 직접 작성하게 되더라도 bpf() 시스템 콜을 직접 호출할 가능성은 크지 않다. 이후 장에서 다루게 될 라이브러리들이 더 높은 수준의 추상화를 제공하여 작업을 쉽게 만들어주기 때문이다.
bpf() 시스템 콜은 eBPF 맵이나 프로그램에 대해 다양한 명령을 수행하는 데 사용된다. 함수 형태는 다음과 같다.
int bpf(int cmd, union bpf_attr *attr, unsigned int size);- cmd는 수행할 작업을 지정하며, 프로그램 로드, 맵 생성, 데이터 접근 등 여러 명령을 처리한다. (아래 이미지 참고)
- attr은 필요한 파라미터를 담고 있다.
- size는 그 크기를 의미한다.
이 장에서는 strace를 통해 bpf() 호출 방식을 확인하며, 복잡한 부분은 생략하고 핵심 위주로 설명한다.
다음 예제에서는 hello-buffer-config.py라는 BCC 프로그램을 사용한다. 이 프로그램은 이전 예제처럼 execve() 이벤트가 발생할 때 커널에서 사용자 공간으로 메시지를 전달한다. 여기에 추가된 기능은 사용자 ID마다 다른 메시지를 설정할 수 있다는 점이다.
#!/usr/bin/env python3
# -*- coding: utf-8 -*-
from bcc import BPF
import ctypes as ct
program = r"""
struct user_msg_t {
char message[13];
};
BPF_HASH(config, u32, struct user_msg_t);
BPF_PERF_OUTPUT(output);
struct data_t {
int pid;
int uid;
char command[16];
char message[12];
};
int hello(void *ctx) {
struct data_t data = {};
struct user_msg_t *p;
char message[12] = "Hello World";
data.pid = bpf_get_current_pid_tgid() >> 32;
data.uid = bpf_get_current_uid_gid() & 0xFFFFFFFF;
bpf_get_current_comm(data.command, sizeof(data.command));
p = config.lookup(&data.uid);
if (p != 0) {
bpf_probe_read_kernel(data.message, sizeof(data.message), p->message);
} else {
bpf_probe_read_kernel(data.message, sizeof(data.message), message);
}
output.perf_submit(ctx, &data, sizeof(data));
return 0;
}
"""
b = BPF(text=program)
syscall = b.get_syscall_fnname("execve")
b.attach_kprobe(event=syscall, fn_name="hello")
b["config"][ct.c_int(0)] = ct.create_string_buffer(b"Hey root!")
b["config"][ct.c_int(501)] = ct.create_string_buffer(b"Hi user 501!")
def print_event(cpu, data, size):
data = b["output"].event(data)
print(f"{data.pid} {data.uid} {data.command.decode()} {data.message.decode()}")
b["output"].open_perf_buffer(print_event)
while True:
b.perf_buffer_poll()- 먼저
config라는 해시 맵을 정의하고, 키는 u32(UID), 값은 user_msg_t 구조체로 설정한다. hello()함수에서는 현재 프로세스의 PID, UID, 실행 중인 명령어를 가져온다.config.lookup(&data.uid)로 현재 UID에 해당하는 값을 찾는다.- 값이 존재하면(p != 0) 맵에 저장된 메시지를 사용하고, 없으면 기본 문자열 "Hello World"를 사용한다.
- 마지막으로 perf_submit을 통해 이 데이터를 사용자 공간으로 전달한다.
이제 사용자 코드인 파이썬 코드를 보면
b["config"][ct.c_int(0)] = ct.create_string_buffer(b"Hey root!")
b["config"][ct.c_int(501)] = ct.create_string_buffer(b"Hi user 501!")- 사용자 root(0)와 UID 501에 대해 각각 다른 메시지를 설정한다.
이제 출력을 확인해보면
[Terminal 1] [Terminal 2]
$ ./hello-buffer-config.py
37926 501 bash Hi user 501! ls
37927 501 bash Hi user 501! sudo ls
37929 0 sudo Hey root!
37931 501 bash Hi user 501! sudo -u daemon ls
37933 1 sudo Hello World실행한 명령어를 누가 실행했는지에 따라서 메시지가 출력되는 것을 확인할 수 있다.
이제 이 프로그램이 어떤 동작을 하는지 이해했으므로, 실행 과정에서 사용되는 bpf() 시스템 콜을 살펴본다. 이를 위해 strace를 사용하고, -e bpf 옵션으로 bpf() 호출만 필터링한다.
$ strace -e bpf ./hello-buffer-config.py
bpf(BPF_BTF_LOAD, ...) = 3
bpf(BPF_MAP_CREATE, {map_type=BPF_MAP_TYPE_PERF_EVENT_ARRAY, ...}) = 4
bpf(BPF_MAP_CREATE, {map_type=BPF_MAP_TYPE_HASH, ...}) = 5
bpf(BPF_PROG_LOAD, {prog_type=BPF_PROG_TYPE_KPROBE, prog_name="hello", ...}) = 6
bpf(BPF_MAP_UPDATE_ELEM, ...)
...
- 먼저 BTF 데이터를 로드한다
- 그다음 perf buffer와 config 맵을 생성한다
- 이후 eBPF 프로그램을 커널에 로드한다
- 마지막으로 맵에 데이터를 업데이트한다
이제 각각의 시스템 콜을 하나씩 살펴보면서, 사용자 공간 프로그램이 eBPF 프로그램과 어떻게 상호작용하는지 핵심 위주로 확인해보자.
Loading BTF Data
가장 먼저 보이는 bpf() 호출은 다음과 같다.
bpf(BPF_BTF_LOAD, {btf="\237\353\1\0..."}, 128) = 3앞서 설명했던 인자 순서와 비교하면 다음과 같다.
- cmd: BPF_BTF_LOAD
- attr: {btf="\237\353\1\0..."}
- size: 128
여기서 사용된 명령은 BPF_BTF_LOAD 로, BTF(BPF Type Format) 데이터를 커널에 로드하는 역할을 한다. BTF는 커널의 데이터 구조 정보를 담고 있어, 서로 다른 커널 버전 간에도 eBPF 프로그램을 호환되게 실행할 수 있도록 도와준다. (다만 커널 버전이 오래된 경우에는 이 호출이 보이지 않을 수도 있다.)
이 시스템 콜의 반환값 3은 파일 디스크립터(fd)다.
즉, 이 단계는 eBPF 프로그램 실행 전에 필요한 타입 정보를 커널에 등록하고, 이를 식별할 핸들을 얻는 과정이다.
파일 디스크립터는 파일이나 객체를 식별하는 번호로, 이후 다른 시스템 콜에서 이 데이터를 참조할 때 사용된다.
Creating Maps
다음 단계에서는 bpf() 시스템 콜을 통해 eBPF 맵을 생성한다.
1. perf buffer 맵 생성
bpf(BPF_MAP_CREATE, {
map_type=BPF_MAP_TYPE_PERF_EVENT_ARRAY,
key_size=4,
value_size=4,
max_entries=4,
map_name="output",
...
}, 128) = 4이 호출은 output이라는 perf 이벤트 배열 맵을 생성한다. 이 맵은 커널에서 사용자 공간으로 데이터를 전달할 때 사용하는 버퍼 역할을 한다.
- map 타입: PERF_EVENT_ARRAY
- key/value 크기: 각각 4바이트
- 최대 엔트리 수: 4개
반환값 4는 이 맵을 가리키는 파일 디스크립터다. 이후 사용자 공간에서 이 값을 사용해 맵에 접근한다.
2. config 해시 맵 생성
bpf(BPF_MAP_CREATE, {
map_type=BPF_MAP_TYPE_HASH,
key_size=4,
value_size=12,
max_entries=10240,
map_name="config",
btf_fd=3,
...
}, 128) = 5이 호출은 config라는 해시 맵을 생성한다.
- key: 4바이트 → 사용자 ID(u32)
- value: 12바이트 → 메시지 구조체 크기
- 최대 엔트리: 10,240개 (BCC 기본값)
반환값 5는 이 맵의 파일 디스크립터다.
여기서 btf_fd=3 은 앞에서 로드한 BTF 데이터를 사용한다는 의미다. (bpf(BPF_BTF_LOAD, {btf="\237\353\1\0..."}, 128) = 3)
이를 통해 커널은 이 맵에 저장되는 데이터 구조의 형태를 이해할 수 있게 된다. 이 정보는 bpftool 같은 도구에서 맵 내용을 사람이 읽기 쉽게 출력할 때 활용된다.
Loading a Program
이제 맵 생성까지 끝났으므로, 다음 단계는 eBPF 프로그램 자체를 커널에 로드하는 것이다.
bpf(BPF_PROG_LOAD, {
prog_type=BPF_PROG_TYPE_KPROBE,
insn_cnt=44,
insns=0xffffa836abe8,
license="GPL",
prog_name="hello",
expected_attach_type=BPF_CGROUP_INET_INGRESS,
prog_btf_fd=3,
...
}, 128) = 6- prog_type
- 프로그램 타입을 의미하며, 여기서는 kprobe에 붙는 프로그램이다.
- insn_cnt
- eBPF 바이트코드의 명령어 개수(44개)를 의미한다.
- insns
- 실제 eBPF 바이트코드가 저장된 메모리 주소다.
- license="GPL"
- GPL 라이선스를 명시해야 일부 BPF 헬퍼 함수 사용이 가능하다.
- prog_name="hello"
- 프로그램 이름이다.
- expected_attach_type
- 일부 프로그램 타입에서만 의미가 있으며, 여기서는 실제로 사용되지 않는다. (값이 0이라 기본값처럼 들어간 상태다)
- prog_btf_fd=3
- 앞에서 로드한 BTF 데이터(fd 3)를 사용한다는 의미다.
반환값은 6이고, 이는 로드된 eBPF 프로그램을 가리키는 파일 디스크립터다. 만약 검증(verifier)에 실패했다면 음수 값이 반환된다.
현재까지의 파일 디스크립터 정리하면 다음과 같다.
FD 의미
3 -> BTF 데이터
4 -> output perf 버퍼 맵
5 -> config 해시 맵
6 -> hello eBPF 프로그램Modifying a Map from User Space
앞에서 본 Python 코드처럼, 사용자 공간에서는 맵을 수정할 수 있다. 아까 맵에 직접 값을 넣는 코드를 보면,
b["config"][ct.c_int(0)] = ct.create_string_buffer(b"Hey root!")
b["config"][ct.c_int(501)] = ct.create_string_buffer(b"Hi user 501!")이 동작은 내부적으로 다음과 같은 bpf() 시스템 콜로 수행된다.
bpf(BPF_MAP_UPDATE_ELEM, {
map_fd=5,
key=0xffffa7842490,
value=0xffffa7a2b410,
flags=BPF_ANY
}, 128) = 0- BPF_MAP_UPDATE_ELEM
- 맵에 키-값 쌍을 추가하거나 수정하는 명령이다
- map_fd=5
- 앞에서 생성한 config 맵을 의미한다
- flags=BPF_ANY
- 키가 없으면 새로 생성하고, 있으면 덮어쓴다
이 호출이 두 번 실행되며, 각각 UID 0과 501에 대한 값이 저장된다.
위 코드를 보면 key/value가 보이지 않는다. 이는 key와 value는 포인터이기 때문에 strace 출력에서는 실제 값이 아니라 메모리 주소만 보인다.
따라서 실제 데이터를 보려면 bpftool 로 확인해야 한다.
$ bpftool map dump name config
[
{
"key": 0,
"value": {
"message": "Hey root!"
}
},
{
"key": 501,
"value": {
"message": "Hi user 501!"
}
}
]bpftool이 위처럼 구조체 형태로 출력할 수 있는 이유는, 맵 생성 시 전달된 BTF 정보 덕분이다.
즉, 커널이
- key는 u32
- value는 struct user_msg_t
라는 구조를 알고 있기 때문에 사람이 읽기 쉽게 표현할 수 있다.
References
bpf() 시스템 콜로 eBPF 프로그램을 로드하면 파일 디스크립터(fd)가 반환된다. 이 fd는 커널 내부에서 해당 프로그램을 가리키는 참조(reference) 역할을 한다.
사용자 공간 프로세스가 이 fd를 소유하며, 프로세스가 종료되면 fd가 해제되고 참조 카운트가 감소한다. 참조가 0이 되면 커널은 해당 eBPF 프로그램을 제거한다.
Pinning (핀 고정)
프로그램을 로드한 프로세스가 종료되면 fd가 해제되고, 참조 카운트가 0이 되면서 eBPF 프로그램이나 맵이 커널에서 삭제된다. 즉, 그냥 로그만 하면 프로세스가 끝나는 순간 아무것도 남지 않는다.
따라서 프로그램이 바로 사라지는 것을 방지하기 위해 pinning을 사용한다.
bpftool prog load hello.bpf.o /sys/fs/bpf/hello- 이 명령은 프로그램을 /sys/fs/bpf라는 가상 파일 시스템에 고정한다.
- 이 파일들은 실제 디스크에 저장되는 것이 아니라 메모리에 존재한다.
그리고 pinning을 하면 파일 디스크립터 외에 추가 참조가 생성되며, 참조 카운트가 증가한다. 이로 인해 프로그램이 프로세스 종료 후에도 참조 카운트가 0을 초과하여 프로그램이 유지된다.
attach로 인한 참조 증가
프로그램을 특정 이벤트(예: kprobe, tracepoint, XDP 등)에 연결하면
참조 카운트가 추가로 증가한다.
tracing 계열(kprobe 등)은 사용자 프로세스와 연결되어있기 때문에 프로세스 종료 시 같이 제거되고 참조 카운트가 줄어들지만, 네트워크/XDP/cgroup 은 프로세스와 독립적이기 때문에 프로그램이 계속 유지된다.
예를 들어:
ip link set dev eth0 xdp obj hello.bpf.o sec xdp이 경우 ip 명령은 종료되지만, 프로그램은 계속 커널에 남아 있다.
$ bpftool prog list
…
1255: xdp name hello tag 9d0e949f89f1a82c gpl
loaded_at 2022-11-01T19:21:14+0000 uid 0
xlated 48B jited 108B memlock 4096B map_ids 612이처럼 attach 자체가 참조를 유지하는 역할을 수행할 수 있다.
맵(Map)의 참조
맵도 동일하게 참조 카운트 기반으로 관리되며, 참조가 0이 되면 맵도 자동으로 삭제된다.
참조가 증가하는 경우:
- eBPF 프로그램이 해당 맵을 사용할 때
- 사용자 공간에서 fd를 가지고 있을 때
프로그램 코드에 맵이 정의되어 있어도, 실제로 사용하지 않으면 참조가 생성되지 않아 맵이 바로 삭제될 수 있다. 이 경우 다음 BPF_PROG_BIND_MAP syscall을 사용하여 프로그램과 맵을 명시적으로 연결해 참조를 유지할 수 있다. 또한 맵도 pinning이 가능하며, 경로를 통해 여러 프로그램이 공유할 수 있다.
BPF 링크 (BPF Links)
BPF 링크는 eBPF 프로그램과 이벤트 사이에 존재하는 중간 추상화 계층이다. 즉, 프로그램을 이벤트에 직접 붙이는 대신, 링크를 통해 연결하는 방식이다.
BPF 링크에서 파일 시스템에 직접 pin 하고, 프로그램에 대한 추가 참조가 생성된다.
- 사용자 공간 프로그램이 eBPF 프로그램을 로드한다
- BPF 링크를 생성하여 이벤트에 연결한다
- 링크를 pin하면 추가 참조가 유지된다
이 상태에서 사용자 프로세스 종료하여 fd는 사라지고 참조 카운트는 하나 감소한다. 그러나 BPF 링크가 남아있어 참조 카운트는 0이 아니기에 프로그램이 유지된다.
Additional Syscalls Involved in eBPF
지금까지 bpf() 에서 BTF 데이터, 프로그램, 맵 등을 커널에 등록하는 과정들을 살펴보았다. 이제 strace 출력을 통해 perf 버퍼를 설정하는 과정을 살펴보자.
Perf 버퍼 초기화
bpf(BPF_MAP_UPDATE_ELEM, {map_fd=4, key=..., value=..., flags=BPF_ANY}, 128) = 0위 코드를 통해서 config 맵에 엔트리를 넣는다. 이때 fd 가 4인데 이는 perf 버퍼 맵을 의미한다.
여기서 몇가지 의문이 생긴다.
1. BPF_MAP_UPDATE_ELEM 호출이 4번만 발생하는데 왜그럴까?
2. 4번 호출한 이후 bpf() 시스템 콜이 나타나지 않는다. 사용자 공간에서 데이터가 계속 출력되고 있음에도 불구하고 말이다. 어떻게 데이터가 전달되는걸까?
3. eBPF 프로그램이 kprobe 이벤트에 어떻게 연결되는걸까?
위와 같은 의문점들을 해결하기 위해 strace 에서 더 많은 시스템 콜을 추적한다.
strace -e bpf,perf_event_open,ioctl,ppoll ./hello-buffer-config.pyKprobe 이벤트에 연결하기
eBPF 프로그램 hello가 커널에 로드된 후, 파일 디스크립터 6이 이 프로그램을 가리키는 것으로 할당된 것을 이미 확인했다.
eBPF 프로그램을 어떤 이벤트에 연결하려면, 해당 이벤트를 나타내는 파일 디스크립터도 필요하다.
다음은 strace 출력에서 execve() kprobe에 대한 파일 디스크립터를 생성하는 부분이다.
perf_event_open({type=0x6 /* PERF_TYPE_??? */, ...}, ...) = 7perf_event_open() 시스템 호출의 매뉴얼에 따르면, 이 호출은 성능 정보를 측정할 수 있는 파일 디스크립터를 생성한다.
출력을 보면 type=6 값에 대해 strace는 정확히 해석하지 못하고 있다. 하지만 매뉴얼을 더 살펴보면, Linux는 동적인 Performance Measurement Unit(PMU) 타입을 지원한다고 설명되어 있다.
각 PMU 인스턴스마다 /sys/bus/event_source/devices 아래에 디렉터리가 존재하며,
그 안에는 type 파일이 있고, 그 값(정수)을 type 필드에 사용할 수 있다.
실제로 해당 디렉터리를 확인해 보면
$ cat /sys/bus/event_source/devices/kprobe/type
6이를 통해 perf_event_open() 호출에서 type=6은 kprobe 타입의 perf 이벤트를 의미한다는 것을 알 수 있다.
perf_event_open()의 반환값은 7이며, 이는 kprobe perf 이벤트를 나타내는 파일 디스크립터다.
정리하면:
- 파일 디스크립터 6 → eBPF 프로그램 (hello)
- 파일 디스크립터 7 → kprobe 이벤트
이 두 개를 연결해야 한다.
perf_event_open() 매뉴얼에는 ioctl()을 사용해 이 둘을 연결하는 방법이 설명되어 있다.
PERF_EVENT_IOC_SET_BPF는 기존 kprobe tracepoint 이벤트에 BPF 프로그램을 연결할 수 있게 해준다. 인자는 이전 bpf() 시스템 호출로 생성된 BPF 프로그램의 파일 디스크립터이다.
위를 토대로 ioctl 을 실행하면 다음과 같다.
ioctl(7, PERF_EVENT_IOC_SET_BPF, 6) = 07(kprobe 이벤트 FD) 를 6(eBPF 프로그램 FD) 에 연결. 즉, eBPF 프로그램을 kprobe 이벤트에 연결하는 과정이다.
ioctl 의 또 다른 사용으로 kprobe 이벤트를 활성화하는 방법도 있다.
ioctl(7, PERF_EVENT_IOC_ENABLE, 0) = 0위 설정이 완료되면 시스템에서 execve() 가 실행될 때마다 해당 eBPF 프로그램이 실행된다.
Perf 이벤트 설정 및 읽기
앞에서 출력용 perf 버퍼와 관련된 bpf(BPF_MAP_UPDATE_ELEM) 호출이 총 네 번 발생한다고 언급했다.
추가 시스템 호출까지 포함해 strace를 보면, 다음과 같은 호출 묶음이 네 번 반복된다.
perf_event_open({type=PERF_TYPE_SOFTWARE, size=0,
config=PERF_COUNT_SW_BPF_OUTPUT, ...}, -1, X, -1, PERF_FLAG_FD_CLOEXEC) = Y
ioctl(Y, PERF_EVENT_IOC_ENABLE, 0) = 0
bpf(BPF_MAP_UPDATE_ELEM, {map_fd=4, key=..., value=..., flags=BPF_ANY}, 128) = 0여기서 X는 각 호출에서 0, 1, 2, 3으로 나타난다. perf_event_open() 매뉴얼에 따르면 이 값은 CPU 번호를 의미하며, 그 앞의 -1은 PID(프로세스 ID)를 나타낸다.
매뉴얼에 따르면, pid == -1이고 cpu >= 0이면 해당 CPU에서 실행되는 모든 프로세스/스레드를 측정을 의미한다.
즉, 이 호출이 네 번 반복되는 이유는 사용 중인 시스템에 CPU 코어가 4개 있기 때문이다.
이로부터 다음을 이해할 수 있다.
- perf 버퍼 맵에 엔트리가 4개 있는 이유 → CPU 코어마다 하나씩 존재
- BPF_MAP_TYPE_PERF_EVENT_ARRAY라는 이름에서 “array”의 의미 →
하나의 버퍼가 아니라 CPU별로 여러 개의 버퍼 배열
각 perf_event_open() 호출은 파일 디스크립터를 반환하며, 실제 값은 8, 9, 10, 11이다. (이를 Y로 표시함)
이후 ioctl() 호출은 각각의 파일 디스크립터에 대해 perf 출력 기능을 활성화한다. 그리고 BPF_MAP_UPDATE_ELEM 호출은 각 CPU에 해당하는 perf 링 버퍼를 맵에 연결하여, 데이터를 어디로 보낼지 설정한다.
이제 사용자 공간에서는 이 파일 디스크립터들을 사용해 데이터를 읽을 수 있다. 이를 위해 ppoll()을 사용하여 네 개의 출력 스트림을 모두 감시한다.
ppoll([{fd=8, events=POLLIN}, {fd=9, events=POLLIN},
{fd=10, events=POLLIN}, {fd=11, events=POLLIN}],
4, NULL, NULL, 0) = 1 ([{fd=8, revents=POLLIN}])이 ppoll() 호출은 읽을 데이터가 생길 때까지 대기(block) 한다. 실제로 프로그램을 실행해 보면, execve()가 발생하기 전까지는 아무 결과도 출력되지 않는다. execve()가 발생하면 eBPF 프로그램이 데이터를 생성하고, 그 데이터가 사용자 공간으로 전달되며 ppoll() 호출이 반환된다.
링 버퍼 (Ring Buffers)
링 버퍼는 perf 버퍼보다 선호된다. 그 이유는 성능뿐만 아니라, 여러 CPU 코어에서 데이터가 생성되더라도 데이터 순서가 유지되도록 보장하기 때문이다. 링 버퍼는 모든 코어가 공유하는 하나의 글로벌한 버퍼만 사용한다.
코드 변경사항은 다음과 같다.
| perf 버퍼 코드 | 링 버퍼 코드 |
|---|---|
| BPF_PERF_OUTPUT(output); | BPF_RINGBUF_OUTPUT(output, 1); |
| output.perf_submit(...) | output.ringbuf_output(...) |
| open_perf_buffer(...) | open_ring_buffer(...) |
| perf_buffer_poll() | ring_buffer_poll() |
출력 버퍼만 바뀌었기 때문에, 프로그램 로드, config 맵 생성, kprobe 연결과 관련된 시스템 호출은 그대로 유지된다.
링 버퍼를 생성하는 bpf() 호출은 다음과 같다.
bpf(BPF_MAP_CREATE, {
map_type=BPF_MAP_TYPE_RINGBUF,
key_size=0,
value_size=0,
max_entries=4096,
map_name="output",
...
}, 128) = 4perf 버퍼와의 핵심 차이
perf 버퍼에서는
- perf_event_open(), ioctl(), BPF_MAP_UPDATE_ELEM 호출이 CPU마다 반복됨
- 각 cpu 마다 파일 디스크립터 사용
링 버퍼에서는
- 이런 반복 호출이 없음
- 하나의 파일 디스크립터만 사용 (모든 CPU 공유)
또한 perf 버퍼에서는 ppoll() 를 사용해 데이터를 기다린다.
ppoll([{fd=8}, {fd=9}, {fd=10}, {fd=11}], ...) = ...이러한 방식은 매번 호출할 때마다 감시할 파일 디스크립터 목록을 다시 전달해야한다.
반면 링 버퍼에서는 epoll() 를 사용한다.
# 1. epoll 인스턴스 생성
epoll_create1(EPOLL_CLOEXEC) = 8
# 2. 감시할 FD 등록
epoll_ctl(8, EPOLL_CTL_ADD, 4, {...}) = 0 # FD 4 (링 버퍼)를 FD 8(epoll)에 등록
# 3. 데이터 대기
epoll_pwait(8, [...], 1, -1, NULL, 8) = 1 # 데이터 생길 때까지 대기 및 생기면 반환Reading Information from a Map
다음 명령은 bpftool이 config 맵의 내용을 읽을 때 호출하는 bpf() 시스템 호출 일부를 보여준다.
strace -e bpf bpftool map dump name config위 명령어는 모든 맵을 순회하면서 이름이 config 인 맵을 찾고, 그 안의 모든 요소를 순회한다.
맵 찾기
bpftool 은 모든 맵을 하나씩 확인하면서 config 라는 이름을 찾는다.
bpf(BPF_MAP_GET_NEXT_ID, {start_id=0,...}, 12) = 0
bpf(BPF_MAP_GET_FD_BY_ID, {map_id=48...}, 12) = 3
bpf(BPF_OBJ_GET_INFO_BY_FD, {info={bpf_fd=3, ...}}, 16) = 0
bpf(BPF_MAP_GET_NEXT_ID, {start_id=48, ...}, 12) = 0
bpf(BPF_MAP_GET_FD_BY_ID, {map_id=116, ...}, 12) = 3
bpf(BPF_OBJ_GET_INFO_BY_FD, {info={bpf_fd=3...}}, 16) = 0- BPF_MAP_GET_NEXT_ID
- start_id 이후의 다음 맵 ID를 가져온다
- BPF_MAP_GET_FD_BY_ID
- 해당 맵 ID에 대한 파일 디스크립터를 반환한다
- BPF_OBJ_GET_INFO_BY_FD
- 파일 디스크립터가 가리키는 객체(여기서는 맵)의 정보를 가져온다
- 이 정보에는 맵의 이름이 포함되어 있어, config인지 확인할 수 있다
모든 맵을 확인하면 반복이 종료되고 다음과 같이 출력된다. 이는 더이상 확인할 맵이 없다는 것을 의미한다.
bpf(BPF_MAP_GET_NEXT_ID, {start_id=133,...}, 12) = -1 ENOENT (No such file or directory)맵 요소 읽기
이제 실제로 맵의 데이터를 읽는 시스템 호출 흐름을 살펴보자.
bpf(BPF_MAP_GET_NEXT_KEY, {map_fd=3, key=NULL, next_key=...}, 24) = 0
bpf(BPF_MAP_LOOKUP_ELEM, {map_fd=3, key=..., value=..., flags=BPF_ANY}, 32) = 0
[{
"key": 0,
"value": {
"message": "Hey root!"
}
bpf(BPF_MAP_GET_NEXT_KEY, {map_fd=3, key=..., next_key=...}, 24) = 0
bpf(BPF_MAP_LOOKUP_ELEM, {map_fd=3, key=..., value=..., flags=BPF_ANY}, 32) = 0
},{
"key": 501,
"value": {
"message": "Hi user 501!"
}
bpf(BPF_MAP_GET_NEXT_KEY, {map_fd=3, key=..., next_key=...}, 24) = -1 ENOENT
}
]- 우선 맵 안에 유효한 키를 찾아야한다. 첫번째
BPF_MAP_GET_NEXT_KEY에서key가 NULL 인 상태로 호출하면 맵에서 첫번째 키를 가져오라는 의미이다. 커널은next_key포인터가 지정한 위치에 키를 기록한다. - 키가 주어졌다면
BPF_MAP_LOOKUP_ELEM을 통해 값을 가져온다. 결과값은value포인터가 지정한 위치에 기록한다. BPF_MAP_GET_NEXT_KEY를 이용해 다음 키를 얻는다. 이후 동일하게BPF_MAP_LOOKUP_ELEM로 값을 조회한다.- 더이상 읽을 요소가 없다면
BPF_MAP_GET_NEXT_KEY → ENOENT로서 더이상 키가 없음을 나타내고 종료한다.
