5장. CO-RE, BTF, and Libbpf
5장. CO-RE, BTF, and Libbpf
많은 eBPF 프로그램이 커널 내부 데이터 구조에 직접 접근하기 때문에, 컴파일 시점에 포함한 Linux 헤더를 기준으로 필드 위치를 계산하게 된다. 문제는 Linux 커널이 계속 변화한다는 점이다. 구조체의 필드 순서나 레이아웃이 바뀌면, 다른 커널에서 동일한 eBPF 바이너리를 실행했을 때 올바르게 동작한다는 보장이 사라진다.
이 문제를 해결하기 위해 등장한 것이 CO-RE(Compile Once, Run Everywhere)다. CO-RE는 프로그램이 컴파일될 때 사용된 데이터 구조 정보를 함께 포함하고, 실제 실행 시점에 대상 커널의 구조와 비교하여 필드 접근 방식을 자동으로 조정한다. 즉, 단순히 고정된 오프셋에 의존하는 것이 아니라, 구조체의 의미를 기반으로 접근을 재구성하는 방식이다.
이 접근 덕분에, 대상 커널에 해당 필드나 구조체 자체가 존재하기만 한다면, 서로 다른 커널 버전에서도 동일한 eBPF 프로그램을 실행할 수 있다. CO-RE는 eBPF의 “한 번 컴파일하고 어디서나 실행”이라는 목표를 현실적으로 가능하게 만든 핵심 기술이다.
BCC의 이식성 접근 방식
초기 eBPF 생태계에서 널리 사용된 BCC는 사용자 공간과 커널 양쪽을 모두 다루는 프레임워크로, 커널 경험이 많지 않은 개발자도 비교적 쉽게 eBPF 프로그램을 작성할 수 있도록 도와준다. 커널 간 이식성 문제를 해결하기 위해 BCC가 선택한 방식은 목적지 머신에서 런타임에 직접 컴파일하는 것이다.
즉, eBPF 코드를 미리 컴파일해 배포하는 대신, 프로그램이 실행되는 시점에 해당 머신의 커널 환경에 맞게 즉석에서 컴파일하는 방식이다. 이 접근은 커널 버전 차이에 따른 문제를 피할 수 있다는 장점이 있지만, 여러 가지 한계를 가진다.
-
모든 대상 머신에 컴파일 도구체인과 커널 헤더 파일이 설치되어 있어야 한다.
- 커널 헤더는 기본적으로 설치되어 있지 않은 경우도 많다.
- 프로그램을 실행할 때마다 컴파일을 수행해야 하므로, 툴이 실행되기까지 몇 초의 지연이 발생할 수 있다.
-
규모가 큰 환경에서는 이 방식의 비효율이 더 두드러진다.
- 동일한 머신이 여러 대 있는 경우에도 각 머신마다 동일한 컴파일을 반복하게 되므로, 불필요한 연산 자원이 낭비된다.
- 일부 BCC 기반 프로젝트는 eBPF 소스 코드와 도구체인을 컨테이너 이미지로 패키징하기도 하지만, 여전히 커널 헤더 문제는 해결되지 않으며, 여러 컨테이너가 중복 설치될 경우 오히려 비효율이 커질 수 있다.
-
임베디드 환경처럼 자원이 제한된 시스템에서는 컴파일 자체가 부담이 될 수 있다.
이러한 이유로, 새로운 eBPF 프로젝트를 본격적으로 개발하고 배포하려는 경우라면, BCC의 기존 방식은 적합하지 않다. 다만 BCC는 eBPF의 기본 개념을 학습하기에는 여전히 유용하다. 특히 Python 기반 사용자 공간 코드는 간결하고 이해하기 쉬워, 빠르게 프로토타입을 만들거나 개념을 익히는 데에는 좋은 선택이다. 그러나 현대적인 eBPF 개발 관점에서는 더 나은 접근 방식이 필요하다.
CO-RE 개요
CO-RE(Compile Once, Run Everywhere)는 단일 기술이 아니라, 여러 요소가 결합되어 동작하는 접근 방식이다. 각 구성 요소는 커널 간 데이터 구조 차이를 해결하기 위해 역할을 나눠 맡는다.
BTF
먼저 BTF(BPF Type Format)가 있다. BTF는 데이터 구조 레이아웃과 함수 시그니처를 표현하는 포맷이다. CO-RE에서는 컴파일 시점과 실행 시점의 데이터 구조 차이를 비교하는 데 사용된다. 또한 bpftool 같은 도구를 통해 커널의 데이터 구조를 사람이 읽을 수 있는 형태로 출력하는 데도 활용된다.
Linux 커널 5.4부터 BTF를 지원한다.
커널 헤더
다음으로 커널 헤더다. Linux 커널 소스에는 데이터 구조를 정의한 헤더 파일들이 포함되어 있으며, 이들은 커널 버전에 따라 변경될 수 있다. eBPF 개발자는 필요한 헤더를 직접 포함할 수도 있지만, bpftool을 사용해 실행 중인 시스템으로부터 vmlinux.h라는 헤더를 생성할 수도 있다. 이 파일에는 BPF 프로그램이 필요로 할 수 있는 커널의 데이터 구조 정보가 모두 담겨 있다.
컴파일러 지원
세 번째는 컴파일러 지원이다. Clang은 -g 옵션으로 eBPF 프로그램을 컴파일할 때, BTF 정보를 기반으로 CO-RE relocation 정보를 함께 포함하도록 확장되었다. GCC 역시 12버전부터 BPF 대상에 대해 CO-RE를 지원한다.
라이브러리
또한 데이터 구조 재배치를 처리하는 라이브러리가 필요하다. 사용자 공간 프로그램이 eBPF 바이트코드를 커널에 로드할 때, 컴파일 시점과 실행 환경 간의 구조 차이를 반영해 코드를 조정해야 한다. 이 작업은 libbpf(C), cilium/ebpf(Go), Aya(Rust)와 같은 라이브러리가 담당한다.
BPF skeleton
마지막으로 선택적으로 사용할 수 있는 것이 BPF skeleton이다. 이는 컴파일된 BPF 오브젝트 파일로부터 자동 생성되며, eBPF 프로그램을 커널에 로드하거나 이벤트에 연결하는 등의 생명주기 관리를 위한 함수들을 제공한다. C에서는 bpftool gen skeleton을 통해 생성할 수 있으며, 저수준 라이브러리를 직접 다루는 것보다 더 편리한 추상화를 제공한다.
이처럼 CO-RE는 여러 구성 요소가 협력하여 커널 버전 차이에 따른 문제를 해결하는 구조다. 다음으로는 이 중 핵심 역할을 하는 BTF가 어떻게 동작하는지 살펴본다.
BPF Type Format (BTF)
BTF는 데이터 구조와 코드가 메모리에 어떻게 배치되는지를 설명하는 정보다. 이 정보는 단순히 CO-RE를 위한 것에 그치지 않고, 다양한 용도로 활용된다.
구조 파악
eBPF 프로그램이 컴파일된 시점의 데이터 구조와, 실제 실행될 커널의 데이터 구조 사이의 차이를 파악할 수 있게 해준다. 이 차이를 기반으로 프로그램 로드 시점에 필요한 조정이 이루어지며, 이를 통해 커널 버전 간 이식성이 확보된다.
하지만 BTF의 활용은 여기서 끝나지 않는다. 구조체의 레이아웃과 각 필드의 타입을 알고 있기 때문에, 내부 데이터를 사람이 읽기 쉬운 형태로 출력할 수 있다. 예를 들어 문자열은 컴퓨터 입장에서는 단순한 바이트 배열이지만, 이를 문자로 해석하면 훨씬 이해하기 쉬워진다. bpftool이 map dump 결과를 사람이 읽을 수 있게 출력하는 것도 이러한 BTF 정보를 활용한 것이다.
또한 BTF에는 소스 코드의 라인 정보와 함수 정보도 포함되어 있다. 이를 통해 bpftool은 변환되거나 JIT된 프로그램 출력에 원본 소스 코드를 함께 보여줄 수 있다. 이후 verifier 로그에서도 동일하게 소스 코드가 함께 표시되는데, 이 역시 BTF 덕분이다.
BTF는 동시성 제어에도 활용된다. eBPF에서 두 CPU가 동시에 같은 map 값을 접근하지 못하도록 하기 위해 spin lock을 사용할 수 있는데, 이 lock은 map value 구조체 내부에 포함되어야 한다. 커널에서 제공하는 bpf_spin_lock()과 bpf_spin_unlock() helper를 사용하려면, 해당 lock 필드가 구조체 어디에 위치하는지 알아야 하며, 이때 BTF 정보가 필요하다.
struct my_value {
... <other fields>
struct bpf_spin_lock lock;
... <other fields>
};이처럼 BTF는 단순한 타입 정보 이상의 역할을 하며, eBPF 프로그램의 이식성, 디버깅, 가독성, 그리고 동시성 제어까지 다양한 영역에서 중요한 기반이 된다
spin lock은 커널 5.1부터 지원되며, 사용에는 몇 가지 제약이 있다. hash나 array 타입 map에서만 사용할 수 있고, tracing이나 socket filter 유형의 eBPF 프로그램에서는 사용할 수 없다.
bpftool로 BTF 정보 확인하기
bpftool은 프로그램과 map뿐만 아니라 BTF 정보도 조회할 수 있는 도구다. 다음 명령어를 사용하면 현재 커널에 로드된 모든 BTF 데이터를 확인할 수 있다.
> bpftool btf list
1: name [vmlinux] size 5843164B
2: name [aes_ce_cipher] size 407B
3: name [cryptd] size 3372B
...
149: name <anon> size 4372B prog_ids 319 map_ids 103
pids hello-buffer-co(7660)
155: name <anon> size 37100B
pids bpftool(7784)
# 이 중 149에 해당하는것만 본다면
149: name <anon> size 4372B prog_ids 319 map_ids 103
pids hello-buffer-co(7660)
# 이 정보는 다음과 같은 의미를 가진다.
# - ID 149번 BTF 데이터다
# - 약 4KB 크기의 익명 BTF 정보다
# - BPF 프로그램 ID 319와 map ID 103에서 사용된다
# - 프로세스 ID 7660, 즉 hello-buffer-config 프로그램에서 사용 중이다이처럼 BTF는 단순히 타입 정보를 담는 것을 넘어, 어떤 프로그램과 map, 그리고 프로세스가 해당 정보를 사용하는지까지 연결해서 보여준다.
> bpftool prog show name hello
319: kprobe name hello tag a94092da317ac9ba gpl
loaded_at 2022-08-28T14:13:35+0000 uid 0
xlated 400B jited 428B memlock 4096B map_ids 103,104
btf_id 149
pids hello-buffer-co(7660)bpftool 를 이용해서 특정 프로그램을 확인하면 btf_id 149 와 같이 프로그램이 어느 BTF 를 사용하는지도 확인 가능하다.
또한 bpftool은 단순히 목록을 보여주는 것을 넘어서, BTF 내부에 포함된 타입 정보 자체를 직접 출력하는 기능도 제공한다. 이를 통해 커널 데이터 구조를 실제로 어떻게 정의하고 있는지 확인할 수 있다.
프로그램에서 참조하는 모든 map이 BTF에 나타나지 않는다. 예를 들어 perf event buffer map처럼 BTF를 사용하지 않는 map은 이 목록에 포함되지 않는다.
BTF Types 살펴보기
BTF는 단순히 존재하는 것이 아니라, 내부에 구체적인 타입 정의 정보를 담고 있다. 이 정보는 bpftool btf dump id <id> 명령어로 확인할 수 있다. 특정 BTF ID를 기준으로 덤프하면, 여러 줄의 타입 정의가 출력되는데, 각 줄은 하나의 타입을 의미한다.
예를 들어 다음과 같은 eBPF 코드가 있다고 가정해보자:
struct user_msg_t {
char message[12];
};
BPF_HASH(config, u32, struct user_msg_t);이 코드는 key 타입으로 u32, value 타입으로 user_msg_t인 hash map을 정의한다. BTF는 이 구조를 그대로 타입 정보로 풀어서 표현한다.
BTF 출력의 앞부분에는 다음과 같은 타입들이 등장한다:
[1] TYPEDEF 'u32' type_id=2
[2] TYPEDEF '__u32' type_id=3
[3] INT 'unsigned int' size=4 bits_offset=0 nr_bits=32 encoding=(none)이 구조는 타입이 어떻게 연결되는지를 보여준다.
앞에 [1] 은 type id 를 가리킨다. 즉,
- type id 1에서 u32 는 type_id 2를 가리킨다
- type id 2에서 __u32는 다시 type_id 3을 가리킨다
- 최종적으로 type_id 3에서 unsigned int (4바이트 정수)로 정의된다
이 세 가지 유형은 모두 32비트 부호 없는 정수 유형의 동의어이다. C 언어에서 정수의 길이는 플랫폼에 따라 다르기 때문에, 리눅스에서는 u32와 같은 유형을 정의하여 특정 길이의 정수를 명시적으로 한다.
이 시스템에서 u32는 부호 없는 정수와 일치한다. 이를 참조하는 사용자 공간 코드는 __u32와 같이
밑줄이 붙은 동의어를 사용해야 한다.
그 다음 출력으로
[4] STRUCT 'user_msg_t' size=12 vlen=1
'message' type_id=6 bits_offset=0
[5] INT 'char' size=1 bits_offset=0 nr_bits=8 encoding=(none)
[6] ARRAY '(anon)' type_id=5 index_type_id=7 nr_elems=12
[7] INT '__ARRAY_SIZE_TYPE__' size=4 bits_offset=0 nr_bits=32 encoding=(none)이 부분은 user_msg_t 구조체를 설명한다.
- type id 4는 user_msg_t는 전체 크기 12바이트, 필드는 1개를 의미하며, 그 필드 message는 type_id 6을 사용한다.
- type id 5 에서는
char에 대해서 정의한다. - type id 6은 길이 12의 배열이다
- type id 7은 4-byte integer 를 의미한다.
위 정의한거를 토대로 user_msg_t 를 표현하자면 다음과 같다.
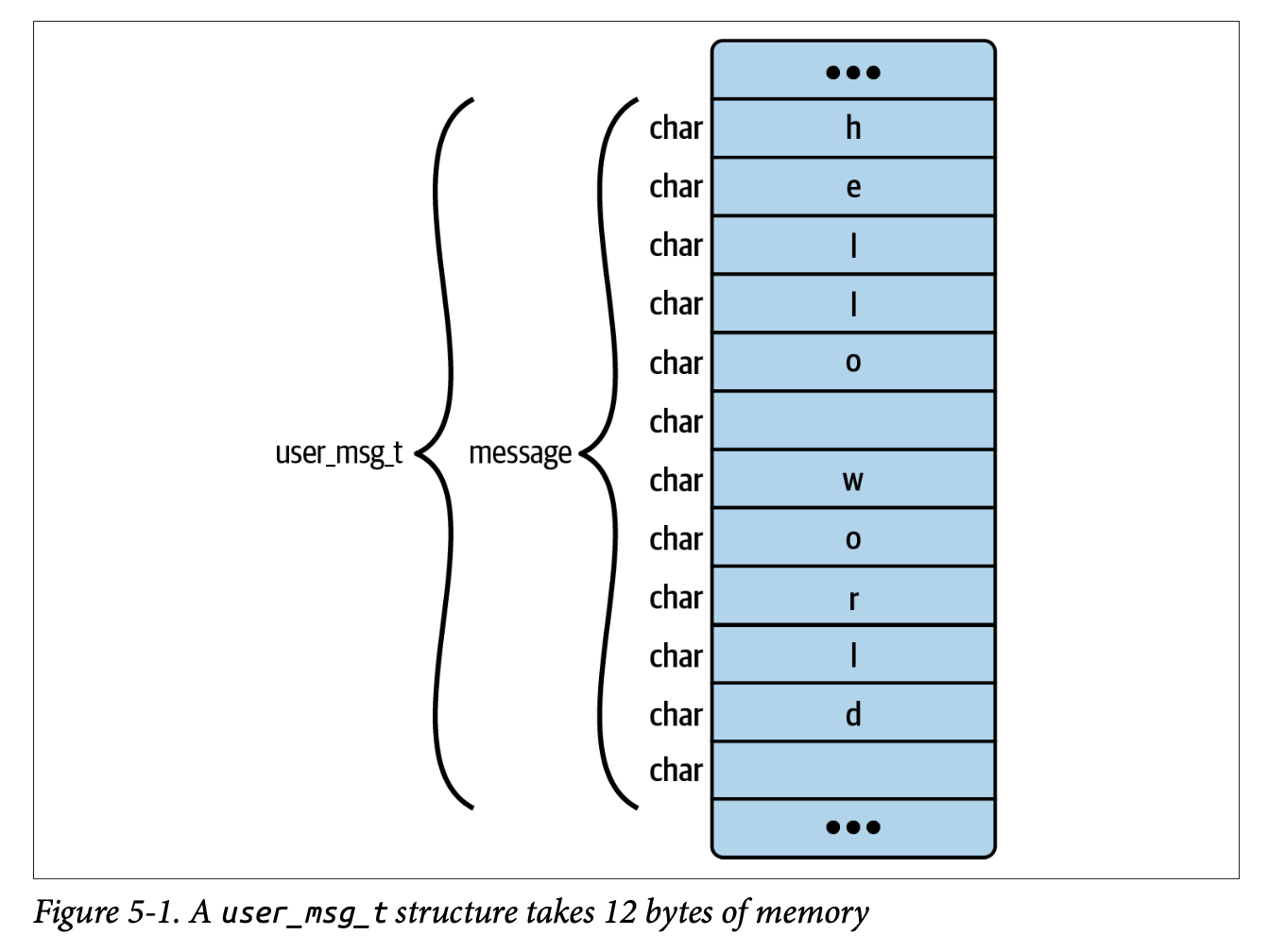
지금까지 살펴본 BTF 출력에서는 bits_offset 값이 모두 0이었다. 하지만 그 다음 출력을 보면,
[8] STRUCT '____btf_map_config' size=16 vlen=2
'key' type_id=1 bits_offset=0
'value' type_id=4 bits_offset=32이것은 config라는 맵에 저장된 키-값 쌍에 대한 구조체 정의이다. 이 __btf_map_config 유형은 소스 코드에서 직접 정의한 것이 아니라, BCC에 의해 생성된 것이다. 키는 u32 유형이고, 값은 user_msg_t 구조체이다. 이는 앞서 봤던 유형 1과 4에 해당한다.
이 구조체에 대한 BTF 정보에서 또 다른 중요한 점은 값 필드가 구조체 시작 지점에서 32비트 뒤에 시작된다는 것이다. 이는 첫 32비트가 키 필드를 저장하는 데 필요하기 때문에 32비트 뒤에서 시작하는 것이다.
C 구조체에서는 항상 필드마다 이전 필드 뒤에 바로 붙는게 아니다
struct something { char letter; u64 number; };위와 같이 코드가 있을 때
letter1 바이트 뒤에 number 가 배치되는게 아니라 8바이트 경계에 정렬된다. 이는 C 의 성능과 정렬 기능 때문이다. 따라서 BTF 는 구조체의 타입 뿐만 아니라 실제 메모리 배치까지 설명함으로써 eBPF 가 커널 데이터를 정확하게 해석할 수 있도록 돕는 기반이 된다.
BTF 정보와 Map 생성
앞에서 map과 관련된 BTF 정보를 살펴봤다면, 이제 이 정보가 실제로 어떻게 커널에 전달되는지 볼 차례다.
eBPF에서 map은 bpf(BPF_MAP_CREATE) 시스템 콜을 통해 생성되며, 이때 bpf_attr 구조체를 인자로 전달한다. 이 구조체에는 map의 기본 정보뿐 아니라, BTF 관련 정보도 함께 포함될 수 있다.
struct { /* anonymous struct used by BPF_MAP_CREATE command */
__u32 map_type; /* one of enum bpf_map_type */
__u32 key_size; /* size of key in bytes */
__u32 value_size; /* size of value in bytes */
__u32 max_entries; /* max number of entries in a map */
...
char map_name[BPF_OBJ_NAME_LEN];
...
__u32 btf_fd; /* fd pointing to a BTF type data */
__u32 btf_key_type_id; /* BTF type_id of the key */
__u32 btf_value_type_id; /* BTF type_id of the value */
...
};- key_size, value_size: key와 value의 크기 (바이트 단위)
- btf_fd: BTF 타입 정보를 가리키는 파일 디스크립터
- btf_key_type_id: key 타입의 BTF ID
- btf_value_type_id: value 타입의 BTF ID
BTF가 도입되기 전에는, 커널은 key와 value를 단순한 바이트 덩어리로만 인식하여 크기만 알 뿐 내부 구조에 대해서는 전혀 알지 못했다. 하지만 BTF 정보가 함께 전달되면서 상황이 달라진다. 이제 커널은 key와 value의 구조와 타입을 이해할 수 있게 된다. 이 덕분에 bpftool 같은 도구가 map 데이터를 사람이 읽기 쉬운 형태로 출력할 수 있다.
여기서 중요한 점은, key와 value에 대해 각각 별도의 BTF type_id가 전달된다는 것이다. 즉, 커널은 key와 value를 하나의 구조체로 묶어서 보는 것이 아니라, 각각 독립적인 타입으로 인식한다.
앞서 살펴본 __btf_map_config 같은 구조체는 실제로 커널이 사용하는 정의가 아니다. 이것은 BCC가 사용자 공간에서 편의를 위해 만들어낸 형태일 뿐이다. 커널 입장에서는 key와 value의 타입 정보만 따로 전달받아 처리한다.
함수와 함수 프로토타입에 대한 BTF 정보
지금까지는 BTF가 주로 데이터 타입과 구조체를 설명하는 데 사용되는 모습을 살펴봤다. 하지만 BTF는 여기서 더 나아가, 함수와 함수 프로토타입 정보까지 포함한다.
예를 들어 다음과 같은 BTF 정보가 있다고 하자.
[31] FUNC_PROTO '(anon)' ret_type_id=23 vlen=1
'ctx' type_id=10
[32] FUNC 'hello' type_id=31 linkage=static이 출력은 hello라는 함수에 대한 정보를 나타낸다.
- type id 32 에서 FUNC 타입에서 hello 함수가 정의되어 있고, 이는 type id 31인 FUNC_PROTO를 따른다.
- type id 31 에서 FUNC_PROTO 정의를 보면 type id 23 을 반환하고 type_id 10 을
ctx인자를 통해 받는걸 알 수 있다.
type id 10 과 23을 살펴보면 다음과 같다.
[10] PTR '(anon)' type_id=0
[23] INT 'int' size=4 bits_offset=0 nr_bits=32 encoding=SIGNED- type_id=10 → void 포인터 (void *)
- type_id=23 → 4바이트 signed int
즉, hello 라는 함수는 다음과 같다.
int hello(void *ctx);BTF는 단순히 데이터 구조만 설명하는 것이 아니라,
- 함수 이름
- 반환 타입
- 파라미터 타입
까지 모두 포함하여, 프로그램의 전체 타입 정보를 표현한다. 이 덕분에 eBPF 프로그램은 단순한 바이트코드를 넘어, 함수 수준의 의미까지 포함된 형태로 커널에 전달된다.
