사전지식
XID
PostgreSQL은 트랜잭션을 식별하기 위해 4바이트 정수인 트랜잭션 ID(XID)를 사용한다. 이 값은 시간이 지남에 따라 증가하며, 특정 포인트(약 20억 트랜잭션)에서 "래핑" 또는 오버플로우가 발생할 수 있다. AutoVacuum은 이 문제를 방지하기 위해 오래된 트랜잭션 정보를 정리한다.
ref: https://velog.io/write?id=0fcac206-13ce-4e14-8350-43d8870ba9ea
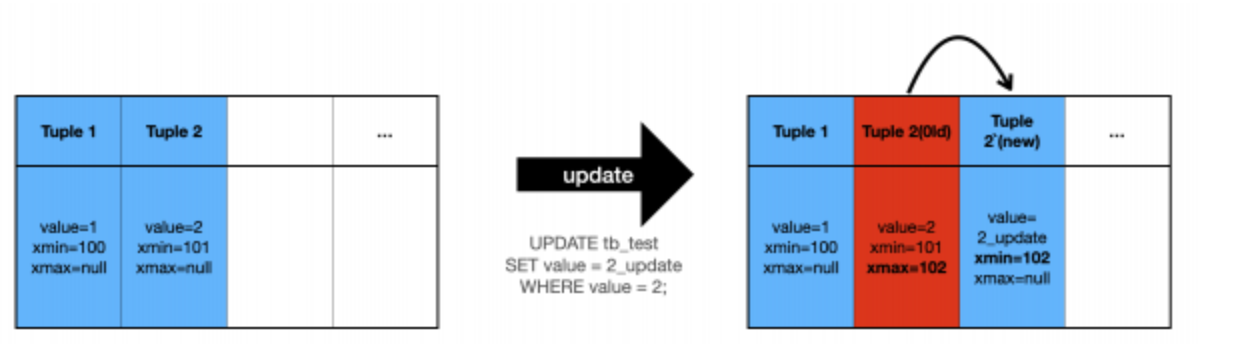
업데이트 쿼리를 보낼 때 postgresql 내부적으로 트랜잭션 ID 내 xmin, xmax 를 비교하여 old version 인지, new version 인지 판단한다. 예를 들어,
xmin | xmax | value
-------+-------+-----
2010 | 2020 | AAA
2012 | 0 | BBB
2014 | 2030 | CCC
2020 | 0 | ZZZTransaction 2015=> ‘AAA’, ‘BBB’, ‘CCC’를 볼 수 있지만, ‘ZZZ’는 xmin이 2020으로 미래의 값이므로 볼 수 없다.
Transaction 2021=> ‘BBB’, ‘CCC’, ‘ZZZ’를 볼 수 있지만, ‘AAA’는 xmax가 2020이므로 2021에서는 볼 수 없다.
Transaction 2031=> ‘BBB’, ‘ZZZ’를 볼 수 있지만, ‘AAA’, ‘CCC’는 각각 xmax가 2020, 2030까지만 존재하던 값으로, 2031에서는 볼 수 없다.
Dead Tuple
PostgreSQL 에서 모든 데이터는 tuple 이라 불리는 형태로 저장된다. 그리고 모든 tuple 은 live tuple, dead tuple 로 나뉘며, 더 이상 사용(참조)되지 않는 tuple 을 dead tuple 이라 부르고, dead tuple 은 PostgreSQL 이 MVCC 를 구현한 방법으로 인해 발생한다.
만일 특정 column 혹은 row 를 업데이트하는 트랜잭션이 수행될 경우 PostgreSQL 은 MVCC 지원을 위해 다음과 같이 동작한다.
- FSM(free space map) 에 여유가 있는지 확인한다. 없으면 FSM 을 추가적으로 확보한다.
- FSM 의 빈 공간에 업데이트 될 데이터를 기록하고, 새로운 tuple 이 추가된다.
- 기록이 완료되면, 기존 column(혹은 row) 를 가리키는 포인터를 새로 기록된 tuple 로 변경한다.
- 업데이트 이전 정보가 기록된 공간은 더 이상 참조가 되지 않게된다. 이 참조가 되지 않는 tuple 을 dead tuple 이라 칭한다.
일련의 과정에서 생성된 dead tuple 은 참조가 되지 않을 뿐 아니라 무의미하게 저장공간만 낭비하고 있는 상태가 된다. 그리고 이런 dead tuple 이 점유하고 있는 공간을 정리하여 FSM 으로 반환하여 재사용 가능하도록 하는 작업을 바로 Vacuum 이라 한다.
정리하면 다음과 같다
- PostgreSQL 의 MVCC 구현체는 update/delete 트랜잭션이 일어날 때 dead tuple 을 남기게 된다
- dead tuple 을 정리하기 위해 Full Vacuum 이라는 task 가 만들어지게 된다.
- Full Vacuum 은 수동으로 구동된다. 그리고 Full Vacuum 이 수행중일 때 해당 테이블은 lock 이 걸리며 모든 트랜잭션이 거부된다. (테이블에 lock 을 걸지 않으면서 dead tuple 을 정리해 주는 Vacuum 명령어를 통해 트랜잭션을 실행시킬 수도 있다. 그러나 이 경우 dead tuple 의 정리 결과로 과다 사용된 저장 공간이 줄어들지는 않는다)
- 또한 Vacuum 을 정기적으로, 그리고 자동으로 vacuuming 을 수행하는 Autovacuum 이 만들어진다.
=> insert/update 가 자주 일어나면 저장공간 사용량이 급속도로 불어나고, 만약 select 쿼리로 청크단위의 데이터를 읽어올 때 정리되지 않은 dead typle 이 포함될어 있을 경우 원하는 live uple 을 읽기 위해 더 많은 I/O 가 발생하여 select 트랜잭션 성능 저하를 가져온다.
PostgreSQL 배포 철학과 Autovacuum
어차피 Autovacuum 이라는게 기본적으로 활성화 되어 있다면, 데이터베이스가 dead tuple 을 알아서 잘 관리하지 않을까? 라는 생각을 가질 수 있다. 그러나 PostgreSQL 의 기본 설정은 최고의 성능을 내기 보다는 가능한 다양한 기기에서 잘 동작할 수 있도록 매우 보수적으로 잡혀있다. 따라서 PostgreSQL 의 Autovacuum 과 관련된 설정들을 서비스 어플리케이션에 알맞게 최적화하여 튜닝할 필요가 있다
Autovacuum 각 원인과 관련된 파라미터 살펴보기
DeadTuple DB 파라미터 튜닝하기
autovacuum_vacuum_threshold: vacuum 이 일어나기 위한 dead tuple 의 최소 개수 (기본 값은 50)autovacuum_vacuum_scale_factor: vacuum 이 일어나기 위한 live tuple 대비 dead tuple 의 최소 비율 (기본 값은 0.2 입니다)
위 두 인자를 통해 dead tuple 의 합을 토대로 autovacuum 동작 여부가 결정된다. 예를 들어 A 라는 테이블에 100,000 건의 레코드가 있을 경우, (100,000 * 0.2) + 50 = 20,050 개의 dead tuple 이 발생할 경우 Autovacuum 이 동작한다. 만약 한번에 처리해야 할 dead tuple 이 증가할 경우 Autovacuum 이 진행되다가 dead tuple 을 모두 처리하지 못하고 중단이 될 수 있다. dead tuple 이 줄어들지 않거나 증가할 수 있으며, Autovacuum 프로세서로 인해 cpu 사용률이 증가하여 데이터베이스 성능에 영향을 끼칠수 있다.
XID wraparound
Dead Tuple 이슈는 DB 성능과 디스크의 비효율적인 사용 이슈를 유발하지만 서비스 중단을 일으킬 정도의 문제는 아니다.
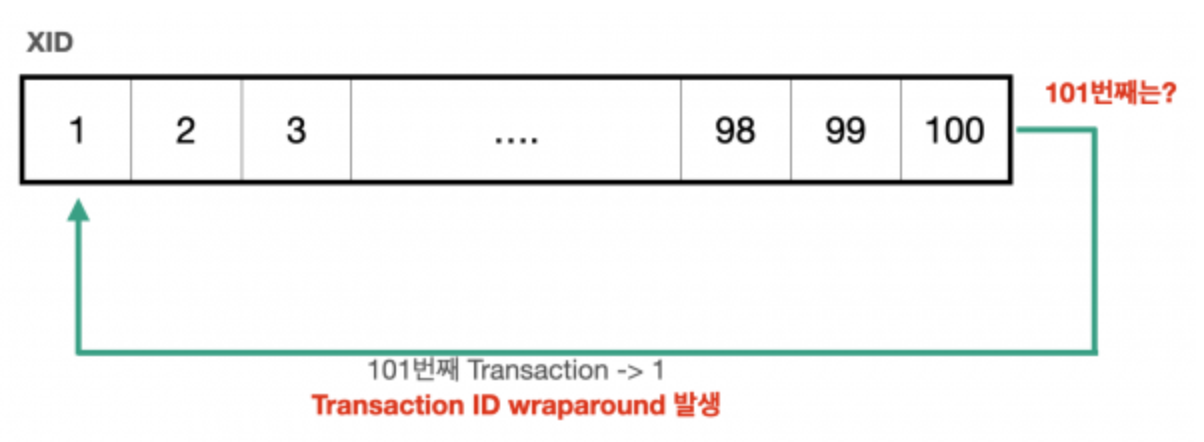
그러나 Transaction ID Wraparound 이슈는 다르다. 제때 vacuum이 수행되지 않아 Transaction ID 정리가 안 되면 DB의 모든 write 작업이 멈출 수 있는 중요한 이슈라서
DB에서 AutoVacuum을 OFF 해놔도 관련 임계치를 초과하면 DB에서 강제로 수행하게 된다.
ref: https://techblog.woowahan.com/9478/
한 바퀴 돌고 난 뒤의 Transaction ID 1은 기존의 데이터보다 최신 데이터임에도 불구하고
기존의 데이터들은 모두 Transaction ID가 1보다 크기 때문에 과거의 데이터인 기존의 데이터들이 모두 미래에 있는 것처럼 되어 보이지 않게된다. 즉, 과거 데이터들이 모두 손실되는 Transaction ID Wraparound 현상이 발생한다.
freeze
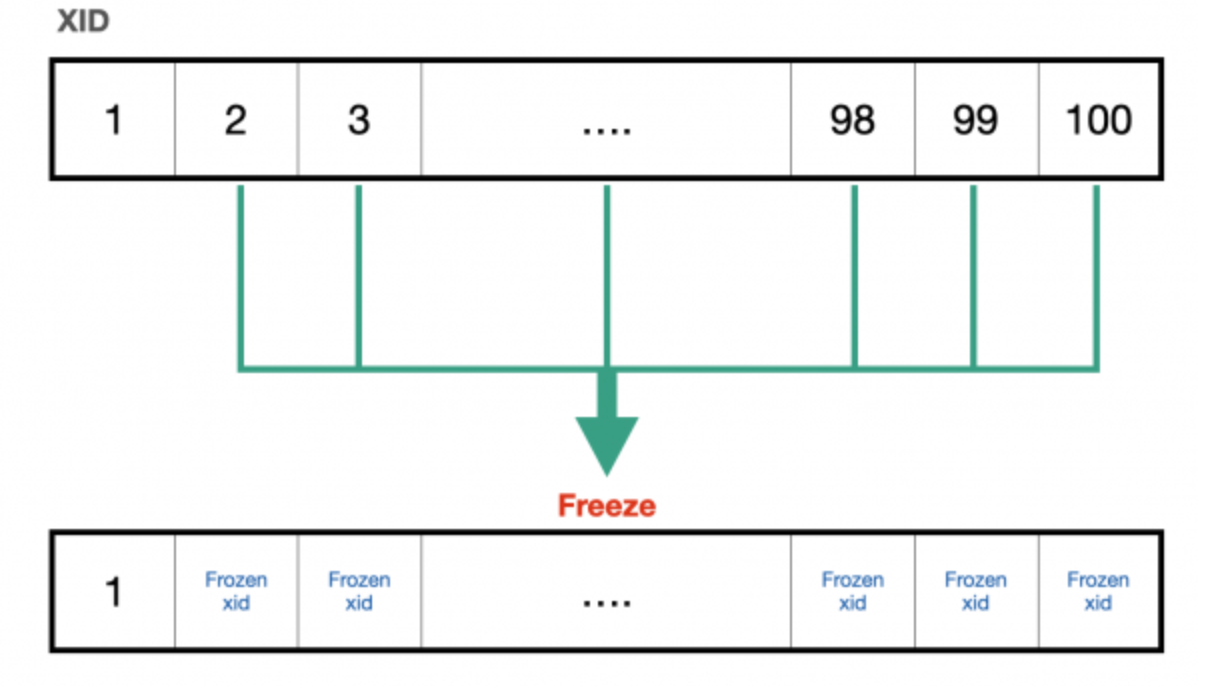
PostgreSQL에서는 Transacion ID를 재사용하기 위해 과거 데이터의 Transaction ID를 계속 증가시키는 게 아니라 특정 시점에서 모두 frozen XID = 2라는 특별한 Transaction ID 로 바꿔버린다
Age
테이블 생성 시 혹은 Tuple을 처음 insert 할 때의 age는 1부터 시작하며 해당 테이블에 대한 트랜잭션이 아니더라도 DB에서 트랜잭션이 발생할 때마다 모든 오브젝트와 Tuple의 age가 1씩 증가한다.
age가 계속 증가하다가 age 관련 특정 파라미터의 임계치에 도달하면 Transaction ID Wraparound를 방지하기 위한 Anti Wraparound Vacuum의 대상이 되고 Anti Wraparound Vacuum이 수행된 후에는 테이블과 Tuple의 age가 다시 돌아간다.
Tuple Age
Tuple은 Anti Wraparound Vacuum이 수행될 때 freeze 되는 대상 그 자체이며, freeze 대상이 되는 기준은 vacuum_freeze_min_age(default 5천만) 설정값보다 age가 높은 Tuple이 대상이 된다.
Table Age
반면에 Table은 Tuple과는 달리 freeze의 대상이 아니다. 다만, Table의 age는 이 테이블에 속한 Tuple의 age 중 가장 높은 값으로 설정이 되기 때문에 Tuple의 age를 대표하는 특성이 있다. (Table Age = Tuple Age 중 가장 높은 값)
그렇기 때문에 Table에 속한 Tuple의 age를 모두 찾아볼 필요 없이, Table의 age만 보고도 ‘아 이 테이블에는 Freezing이 필요한 Tuple가 있구나’ 라는 판단을 할 수 있다.
파라미터 살펴보기
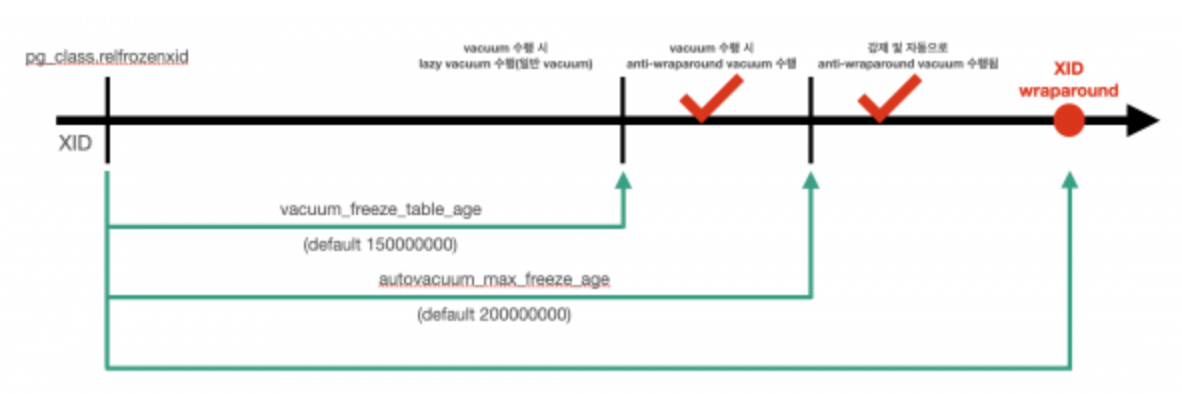
Vacuum 이 동작하는 경우는 다음과 같다
1. 테이블의 Age(tuple age 의 최대값) 가 autovacuum_freeze_max_age(default 2억) 파라미터 임계치를 초과한 경우
2. vacuum_freeze_table_age < 테이블의 Age < autovacuum_freeze_max_age
XID autovacuum 관련해서 살펴볼 파라미터는 정리하면 다음과 같다
autovacuum_freeeze_max_age: 해당 값을 초과하는 age의 테이블에 대해 Anti Wraparound AutoVacuum을 수행함 (AutoVacuum 설정을 끄더라도 강제로 수행된다)
vacuum_freeze_min_age: 해당 값을 초과하는 age의 Tuple을 vacuum 작업 시 Transaction ID freeze 작업의 대상으로 한다. Anti Wraparound AutoVacuum 수행 이후 테이블의 age는 최대 vacuum_freeze_min_age 값으로 설정된다
vacuum_freeze_table_age: 해당 값을 초과하는 age의 테이블에 대해 vacuum이 호출될 때 frozen 작업도 같이 수행함
오래된 XID 를 추적하기 위해 pg_class 와 pg_database 를 살펴볼 수 있다.
SELECT relname, age(relfrozenxid) FROM pg_class WHERE relkind = 'r';
SELECT datname, age(datfrozenxid) FROM pg_database;첫번째 쿼리는 pg_class 시스템 카탈로그에서 모든 "실제(relation)" 테이블의 이름(relname)과 그 테이블의 relfrozenxid (가장 오래된 트랜잭션 ID)의 "나이"를 조회한다. 여기서 relkind = 'r'는 실제 테이블만을 대상으로 한다는 의미이다. age(relfrozenxid)는 현재 데이터베이스의 xmin (가장 오래된 트랜잭션 ID)과 relfrozenxid 사이의 차이를 나타내며, 이 값이 클수록 해당 테이블이 오랫동안 vacuum 처리되지 않았음을 의미한다.
두번째 쿼리는 pg_database 시스템 카탈로그에서 모든 데이터베이스의 이름(datname)과 각 데이터베이스의 datfrozenxid (데이터베이스 내 모든 테이블에서 사용된 가장 오래된 트랜잭션 ID)의 "나이"를 조회한다. age(datfrozenxid)는 현재 데이터베이스 전체에 대한 "나이"를 나타내며, 이 값이 크다면 데이터베이스가 전반적으로 오랫동안 vacuum 처리되지 않았다는 신호이다.
이를 해결하기 위해 AutoVacuum 동작 트리거 임계치를 조정할 필요가 있으며 앞서 threshold 값을 수정하는 거 뿐만 아니라 다음 동작도 고려할 수 있다.
autovacuum_vacuum_cost_limit = 200
vacuum_cost_delay = 0
vacuum_cost_page_hit = 1
vacuum_cost_page_miss = 10
vacuum_cost_page_dirty = 20
# autovacuum_vacuum_cost_limit = 200: AutoVacuum(Vacuum) 이 한 번 수행될 때 마다 해당 Vacuum 프로세스는 200의 credit을 가집니다.
# vacuum_cost_delay = 0: AutoVacuum이 autovacuum_vacuum_cost_limit 만큼 완료되면 다음 AutoVacuum은 이 몇 밀리초 동안 sleep합니다.
# vacuum_cost_page_hit = 1: page_hit (shared_buffer)에 있는 데이터를 Vacuum 할 때 마다 1 의 credit을 소모합니다.
# vacuum_cost_page_miss = 10: page_miss (디스크 영역)에 있는 데이터를 Vacuum할 때마다 10의 credit을 소모합니다.
# vacuum_cost_page_dirty = 20: Dead Tuple을 Vacuum할 때마다 20의 credit을 소모합니다.주어진 200의 credit 이 모두 소진되면 해당 AutoVacuum 프로세스는 종료된다.
따라서 이 값이 너무 작으면 AutoVacuum이 Dead Tuple을 충분히 다 정리하지 못한 채 끝나고, Dead Tuple이 계속 누적되는 경우가 생길 수 있다.
반면 autovacuum_vacuum_cost_limit 파라미터를 증가시키면 한 번 AutoVacuum이 돌 때 좀 더 오래 돌게 되어 Dead Tuple을 미처 정리하지 못하는 경우가 줄어드는 효과가 있을 수 있다.
AutoVacuum 이 돌아가지 않을 수도 있다
autovacuum 이 너무 느리다면 정상적으로 돌아가지 않는 것일 수도 있다. postgresql 에러로그를 확인할 때 다음과 같이 출력된다면 아래 경우를 살펴보는 것을 추천한다
2024-04-02 05:49:07.514 +08 [64931] WARNING: oldest xmin is far in the past (11833)
2024-04-02 05:49:07.514 +08 [64931] HINT: Close open transactions soon to avoid wraparound problems.
You might also need to commit or roll back old prepared transactions, or drop stale replication slots오래된 트랜잭션이 있을 경우
현재 활성 상태인 가장 오래된 트랜잭션이 시작된 이후에 설정된 트랜잭션 ID를 PostgreSQL이 동결할 수 없는 경우가 있을 수 있다. 이는 MVCC가 작동하는 방식 때문에 발생하는 것으로서, 때때로 트랜잭션이 너무 오래되어 20억 개의 트랜잭션 ID wraparound 한도 전체에 대해 VACUUM이 정리할 수 없어 시스템이 더 이상 새 DML을 수락하지 않을 수 있다.
SELECT age(transaction),* FROM pg_prepared_xacts; 명령어를 통해 오래된 트랜잭션이 있는지 검색해보고 수동으로 커밋하거나 롤백이 필요하다.
비활성화 상태의 replication slot 이 있는 경우
postgresql 9.4 버전에서 안정적으로 replication 에 데이터를 보존하기 위해 메인서버에 WAL 을 보관하고 복제본 서버가 다시 띄워질 경우 메인 서버에 보관중인 WAL 을 통해 데이터를 보존한다. 해당 기능은 데이터 보존을 안정적으로 이뤄내지만 replication slot 이 알아서 삭제되지 않아 운영자가 직접 삭제해야되는 단점이 있다. 또한 비활성화 상태인 replication slot 이 있다면 autovacuum 이 정상적으로 돌아가지 않을 수 있다.
이럴 경우엔 다음과 같이 제거하여 autovacuum 이 정상 실행될 수 있도록 한다.
1. stale replication slot 이 있는지 확인
- SELECT slot_name FROM pg_replication_slots WHERE active='f';
2. inactive replication slot 제거하기
- SELECT pg_drop_replication_slot('slot_name');
reference
https://nrise.github.io/posts/postgresql-autovacuum/
https://techblog.woowahan.com/9478/
https://www.postgresql.org/docs/8.2/routine-vacuuming.html
https://www.postgresql.fastware.com/blog/how-to-fix-transaction-wraparound-in-postgresql
https://aws.amazon.com/ko/blogs/database/best-practices-for-amazon-rds-postgresql-replication/
