관측 가능성은 좋은 신호(텔레메트리)를 필요로 한다. 신호가 부정확하면 시스템을 이해하고 근본 원인을 분석하는 것도 부정확할 것이다. 예를 들어, 잘못된 신호, 신호 유실, 신호 중복, 의도되지 않은 신호 등이 보이면 이상치로 분류하고 새로운 패턴으로 정의해서 지속적으로 관리해야 한다. 오픈텔레메트리는 신호 개발의 표준이다. 텔레메트리와 신호(추적, 메트릭, 로그, 프로파일)가 표준화되는 것은 분명 의미있고 중요한 작업이다.
기존 텔레메트리와 오픈텔레메트리를 적재적소 사용해야한다. 기존 텔레메트리는 솔루션에 종속적이고 시스템 증설 및 확대 시 비용이 급격하게 증가하는 반면, 오픈텔레메트리의 스펙과 기능이 아직 완전하지 않으므로 상관관계를 구현하는데 여러 가지 제약이 있다.
6.1 오픈텔레메트리 소개
2019년 초 오픈트레이싱과 오픈세서스가 합병하여 오픈텔레메트리가 등장하였다. 프로젝트 초기에는 추적 기능을 통합하고 기존 사용자들이 오픈텔레메트리로 쉽게 전환할 수 있도록 집중하였다.오픈텔레메트리는 데이터가 생성, 수집, 전송되는 방식을 표준화하는 것을 목표로 한다. 현재 구글, 아마존 등 메이저 클라우드 사업자 등이 참여하고 있으며 관측 가능성을 표준화하고 대중화하기 위해 노력하고 있다. 이 뿐만 아니라 대형 관측 가능성 벤더(데이터독, 뉴렐릭 등)는 자사 제품 내 오픈텔레메트리를 구현하고 수용하기 위해 노력하고 있다.
ref: https://haandol.github.io/2021/12/13/demystifying-observability-and-opentelemetry-2.html
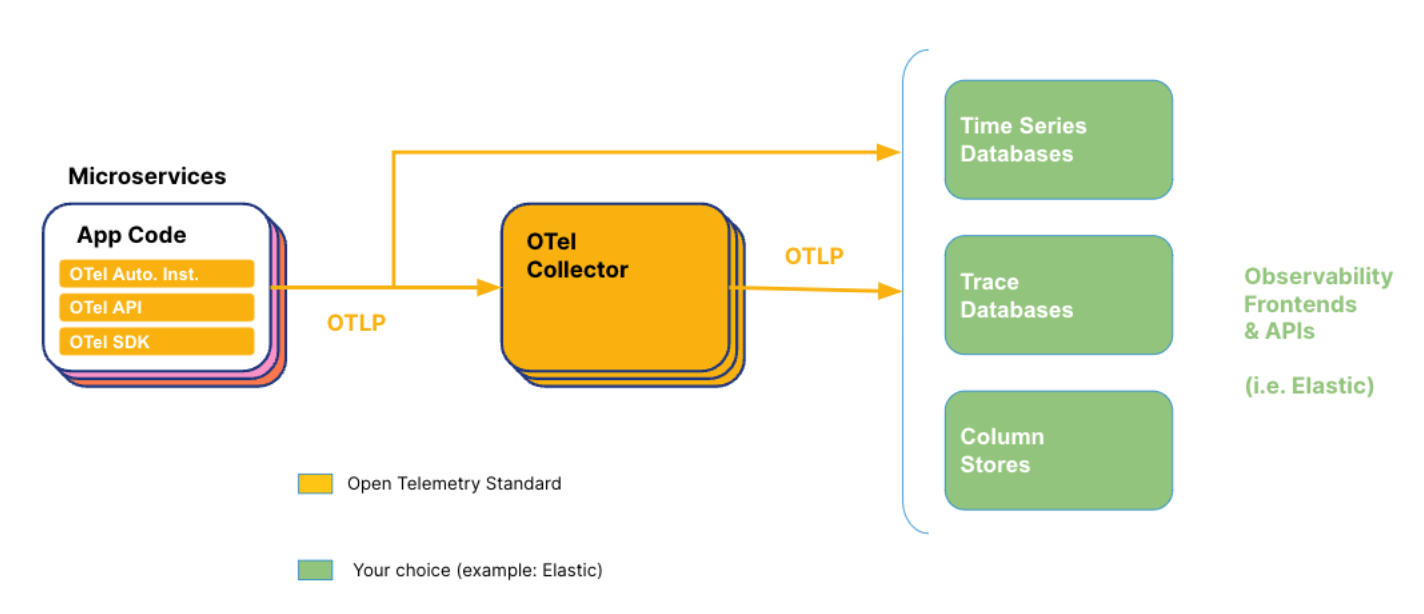
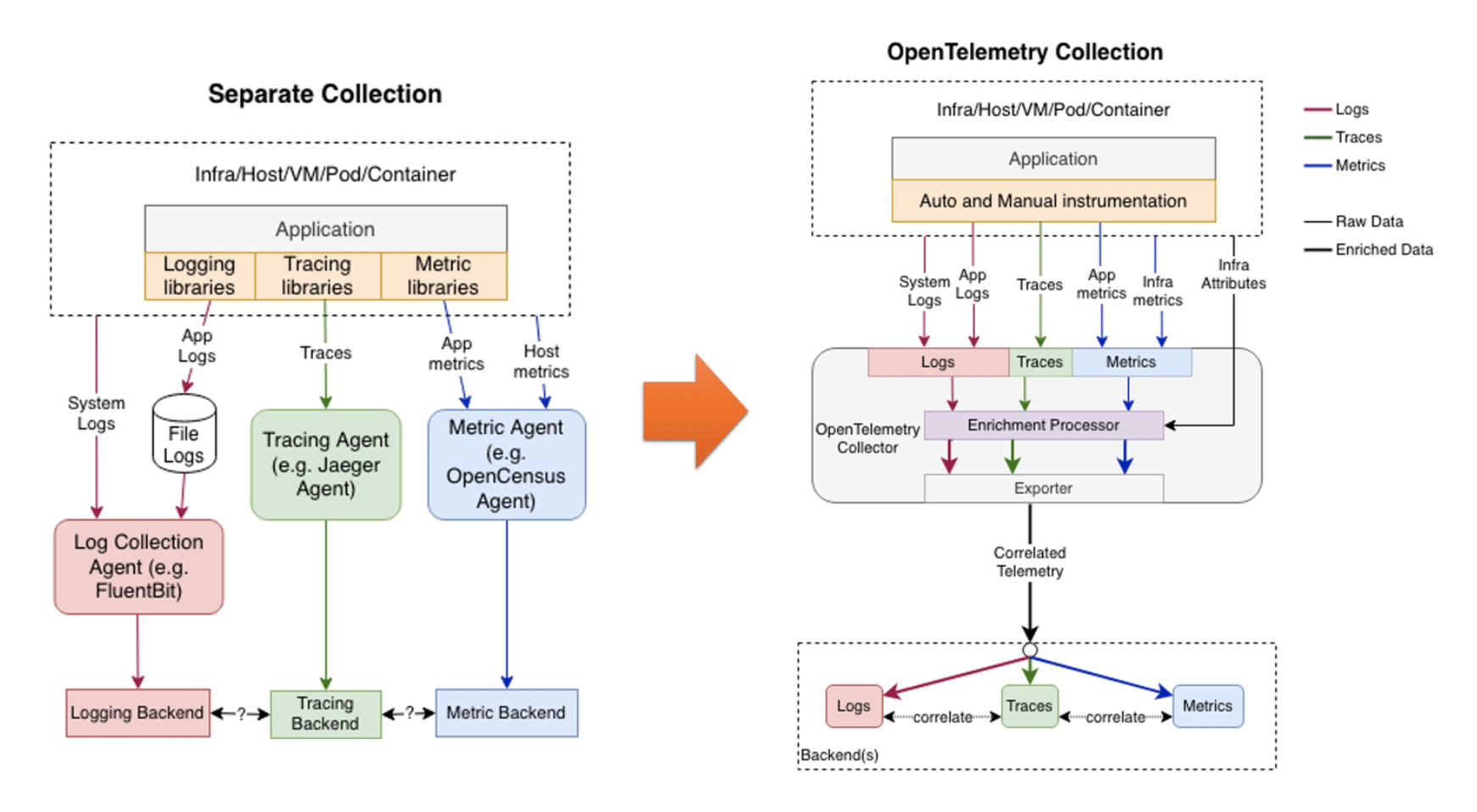
기존에는 옵저버빌리티의 핵심 컴포넌트들을 추적하기 위해서 컴포넌트별로 쌓고 해당 서비스로 내보냈어야 했다. 라이브러리에 따라 비즈니스 로직과 인프라가 너무 밀접하게 얽힌다는 것도 큰 문제이다.
오픈텔레메트리를 이용하면 단일한 라이브러리와 단일한 방법을 통해 옵저버빌리티를 확보할 수 있다. 또한 서비스 코드는 개발자가 어떤 분석도구를 쓰느냐를 알필요가 없어져서 비즈니스 로직과 인프라를 최대한 분리할 수 있다.
종합해보면 오픈텔레메트리는 옵저버빌리티를 쉽게 확보할 수 있도록 도와주는 툴이라고 볼 수 있다.
6.2 오픈텔레메트리 컴포넌트
오픈텔레메트리 프로젝트는 다음과 같이 구성된다.
- 신호(메트릭, 로그, 추적)
- 로그, 메트릭, 추적에 대한 기술적인 스펙을 정의
- 콘텍스트 전파
- 다양한 스트림(업, 다운 스트림) 간에 문맥을 전달하는 과정
- 파이프 라인
-오픈텔레메트리에서 컬렉터를 구현하는 구체적인 방법
6.2.1 데이터 모델
메트릭, 추적, 로그에 대한 상세한 레이아웃과 데이터 구조를 기술한다. 오픈텔레메트리 데이터 모델은 메트릭, 추적, 로그 간 상관관계를 쉽게 구현할 수 있는 표준화 메시지와 데이터 형식이며, 벤더 중립적으로 설계되었다. 또한, gRPC 프로토콜 버퍼와 호환성에서도 문제가 없다. 만약 데이터 모델이 존재하지 않다면 비록 전송 프로토콜은 동일하더라도, 스키마 형태가 고정되어 있지않아 애플리케이션과 관측 가능성 간 복잡도가 증가하고, 유지보수가 어려울 수 있다.
메트릭
메트릭에 대한 오픈텔레메트리 데이터 모델은 사전 집계된 메트릭 시계열 데이터 전달을 위한 프로토콜 사양과 의미체계 규칙으로 이루어져 있다.
- 데이터 모델은 기존 시스템에서 데이터를 가져오고 기존 시스템으로 데이터를 내보낼 때 필요하다.
- 스팬 또는 로그 스트림 등 다른 신호에서 메트릭 지표를 생성하기 위한 기술적인 스펙도 지원한다.
- 다양한 차트와 시각화 기능을 제공하는 데이터 모델은 데이터 변환에 적합하다.
기존 데이터 모델과의 호환성을 고려하여 프로메테우승 메트릭 유형 등 기존 데이터 유형을 어떻게 지원하고 호환성을 유지할지에 대해 스펙을 담고있다.
추적
기존의 다양한 추적 표준을 유지하기보다 새로운 오픈텔레메트리 추적으로 통합하는 방식을 사용하고 있다
로그
다양한 언어 별 로그 라이브러리를 사용할 수 있도록 유지하면서 텔레메트리의 로그를 보강하는 방향으로 개선하고 있다
컬렉터는 다양한 형식의 메트릭 데이터를 허용하고, 오픈텔레메트리 데이터 모델을 사용하여 데이터를 전송한 다음 기존 시스템으로 내보낸다. 데이터 모델은 자동으로 속성을 제거하고 히스토그램 해상도를 낮추는 기능을 포함하여 데이터의 잘 정의도니 변호나을 통해 기능이나 의미의 손실없이 프로메테우스 원격쓰기 프로토콜로 변환하는 것이 가능하다
데이터 모델은 다음과 같은 특징을 갖는다
- 텔레메트리가 지원할 수 있는 OTLP(오픈텔레메트리 프로토콜)와 공급업체에 구애받지 않는 의미 체계 규칙의 정의한다
- 데이터 모델은 특정 신호를 형성하는 컴포넌트의 표현을 정의한다. 각 컴포넌트에 있어야 하는 필드에 대한 세부정보를 제공하고 모든 컴포넌트가 서로 상호적으로 작용하는 방식을 설명한다. 또한, 데이터 모델은 표준을 구현하는 개발자에게 데이터가 어덯게 작동해야 하는지 알려준다.
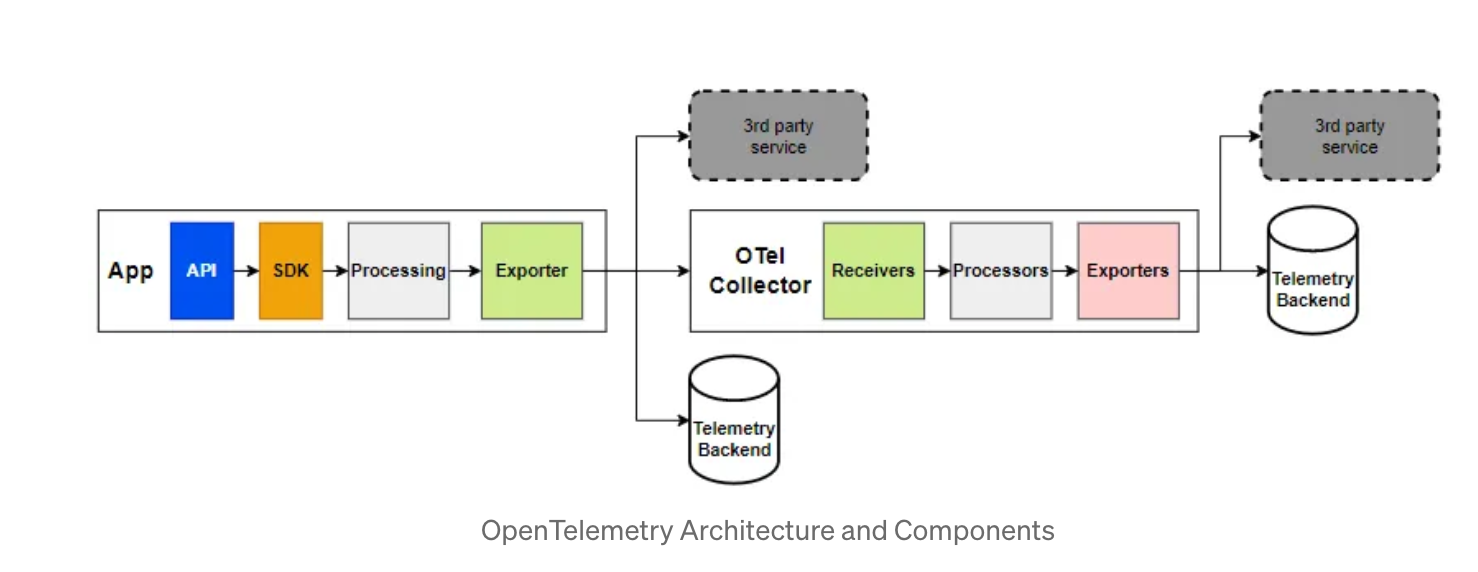
API & SDK
언어별 OpenTelemetry API는 시스템 전체에서 텔레메트리 데이터 수집을 조정하고 코드를 계측한다. 오픈텔레메트리는 11개 언어에 대한 API를 제공한다. 다양한 프레임워크에 자동 계측을 지원하며, 수동 계측에는 백엔드와 프런트엔드 개발 시 텔레메트리 생성을 위한 언어의 차이점을 최대한 배제하고, 공통적인 API 를 제공한다.
API 는 다음과 같은 특징을 갖는다.
- 공급업체에 의존성 없는 방식으로 계측하는 코드를 개발할 수 있다
- 사용자가 빠르게 시작하고 실행할 수 있도록 다양한 언어로 계측 라이브러리를 사용할 수 있다. 예를 들어, 파이썬에서는 계측 라이브러리로 플라스크, 장고 등을 지원한다
- 추적, 메트릭과 로깅 데이터를 생성하고 상호 연관시키기 위한 데이터 유형과 작업을 정의한다
OpenTelemetry SDK는 데이터 수집, 처리 및 내보내기를 지원하는 라이브러리를 통해 API를 구현하고 지원한다
어플리케이션에서 신호가 익스포터까지 전달되는 과정은 다음 이미지를 참고하자
ref: https://medium.com/@dudwls96/opentelemetry-%EB%9E%80-%EB%AC%B4%EC%97%87%EC%9D%B8%EA%B0%80-18b6e4fe6e36
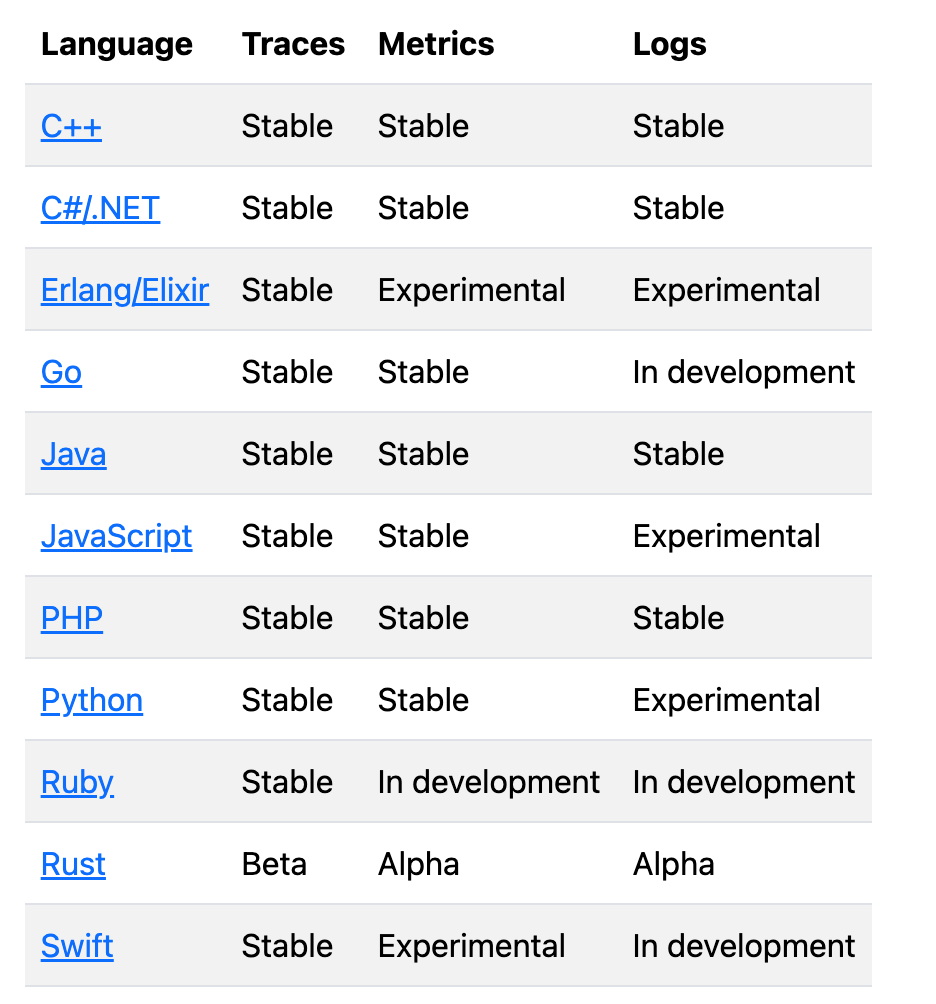
오픈텔레메트릭 계측 라이브러리 지원은 다음 페이지를 통해 확인할 수 있다.
2024-04-13 기준 테이블
리소스
리소스는 텔레메트리를 생성하는 엔티티에 대한 정보를 나타낸다. 예를 들어, Kubernetes의 컨테이너에서 실행 중인 원격 분석을 생성하는 프로세스는 프로세스 이름, 파드 이름, 네임스페이스, 그리고 배포 이름을 가지고 있는데, 이 네 가지 속성은 모두 리소스에 포함될 수 있다.
배기지
OpenTelemetry에서 Baggage는 스팬 간에 전달되는 컨텍스트 정보이다. 이는 추적에서 스팬 컨텍스트와 함께 존재하는 키-값 저장소로, 해당 추적 내에서 생성된 모든 스팬에서 값을 사용할 수 있게 해준다. 예를 들어, 여러 서비스가 포함된 추적의 모든 스팬에 CustomerId 속성을 갖고 싶지만 CustomerId는 하나의 특정 서비스에서만 사용할 수 있다고 가정해보자. CustomerId 속성은 하나의 특정 서비스와 스팬에서만 사용할 수 있지만, 속성은 특정 서비스와 스팬에 종속적이지 않아야 하면 상위 스팬과 하위 슨팬 간 속성이 다른 경우가 많으므로 콘텍스트 전파에 적합하지 않다. 이러한 단점을 극복하기 위해 OpenTelemetry Baggage를 사용하여 이 값을 시스템 전체에 전파할 수 있다
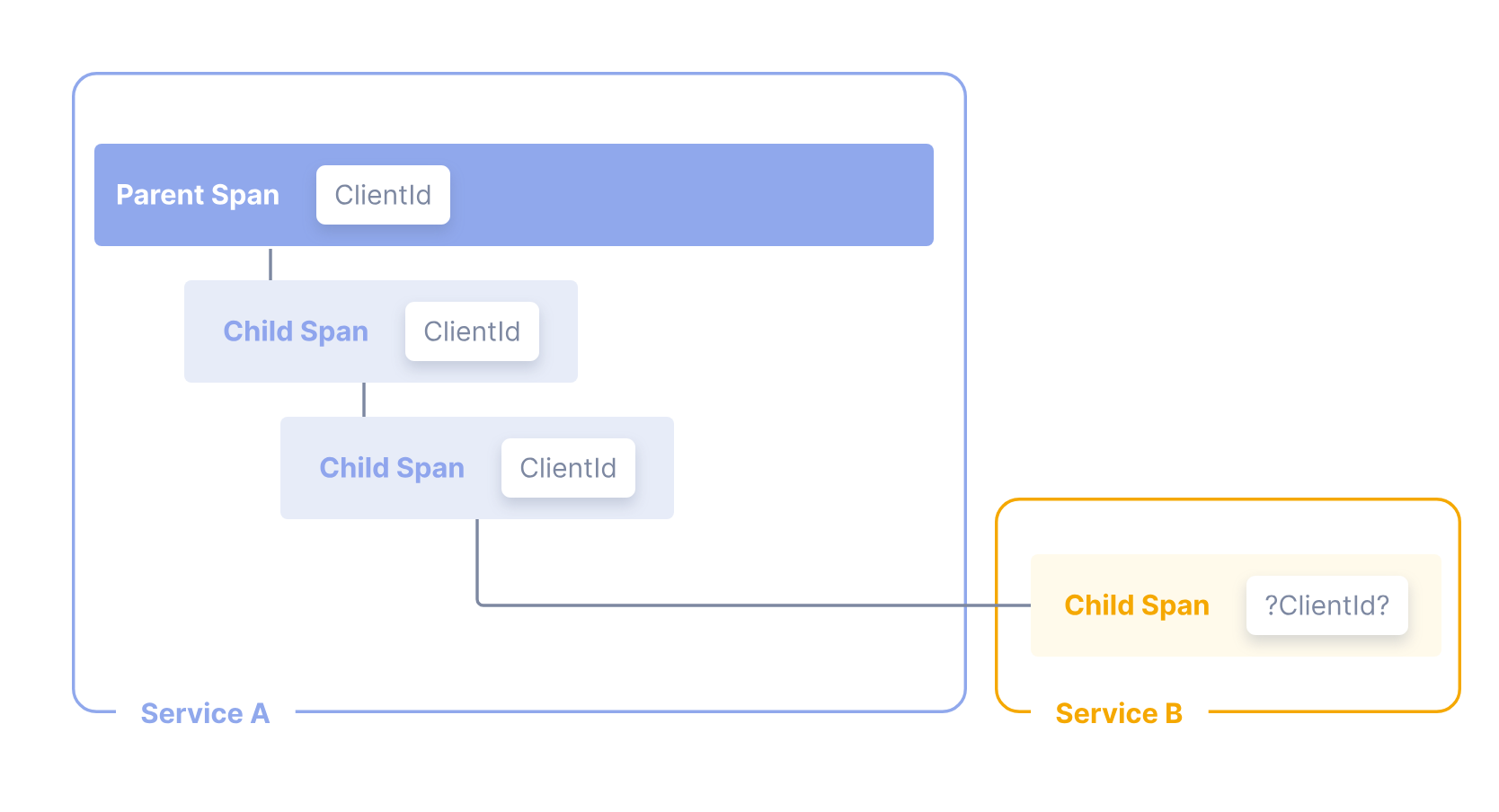
위 이미지에서 ClientId 가 서비스 A 뿐만 아니라 서비스 B 스팬에도 담고 싶을 경우 배기지를 사용하여 전파할 수 있다
OpenTelemetry는 컨텍스트 전파를 사용하여 Baggage를 전달하며, 각 라이브러리 구현에는 사용자가 명시적으로 구현할 필요 없이 해당 Baggage를 파싱하고 사용할 수 있도록 하는 전파자가 있다
배기지란 왜 필요할까?
Baggage는 추적 및 기타 신호 전반에 걸쳐 정보를 저장하고 전파하는 일관된 방법을 제공한다. 예를 들어, 애플리케이션의 정보를 스팬에 첨부하고 나중에 해당 정보를 검색하여 나중에 다른 스팬에서 사용하고 싶을 수 있다. 그러나 OpenTelemetry의 스팬은 일단 생성되면 변경할 수 없으며, 나중에 정보가 필요하기 전에 내보낼 수 있다. Baggage를 사용하면 정보를 저장하고 검색할 수 있는 공간을 제공함으로써 이 문제를 해결할 수 있다. 이로서 백엔드 개발자 등 모니터링할 때 풍부한 정보를 토대로 필터링하여 추적할 수 있다.
배기지 사용시 주의사항
Baggage로 인해 민감한 데이터가 외부 네트워크로 노출될 수 있다. 이는 자동 계측이 대부분의 서비스 네트워크 요청을 담은 Baggage를 포함하기 때문이다. 또한 Baggage 아이템이 누구의 것인지 확인하기 위한 무결성 검사가 내장되어 있지 않으므로 배기지 검색 시 유의해야 한다.
그리고 Baggage의 속성은 스팬 속성의 하위 집합이 아니다. Baggage로 무언가를 추가하면 하위 시스템 스팬의 어트리뷰트에 자동으로 추가되지 않는다. 따라서 Baggage에서 무언가를 명시적으로 가져와서 어트리뷰트로 추가해야 한다.
이벤트
스팬에서 사람이 읽는 메시지를 의미한다
링크
스팬 간 관계를 표현한 것이다. 스팬은 다른 스팬에 연결하는 스팬 링크를 생성할 수 있으며, 이를 만들기 위해서는 스팬 콘텍스트가 필요하다.
6.2.2 콘텍스트 전파
스팬에 담긴 정보(콘텍스트)를 다른 스팬으로 전달하는 것을 콘텍스트 전파라 한다.
아래 그림을 살펴보자.
전파 안한 경우
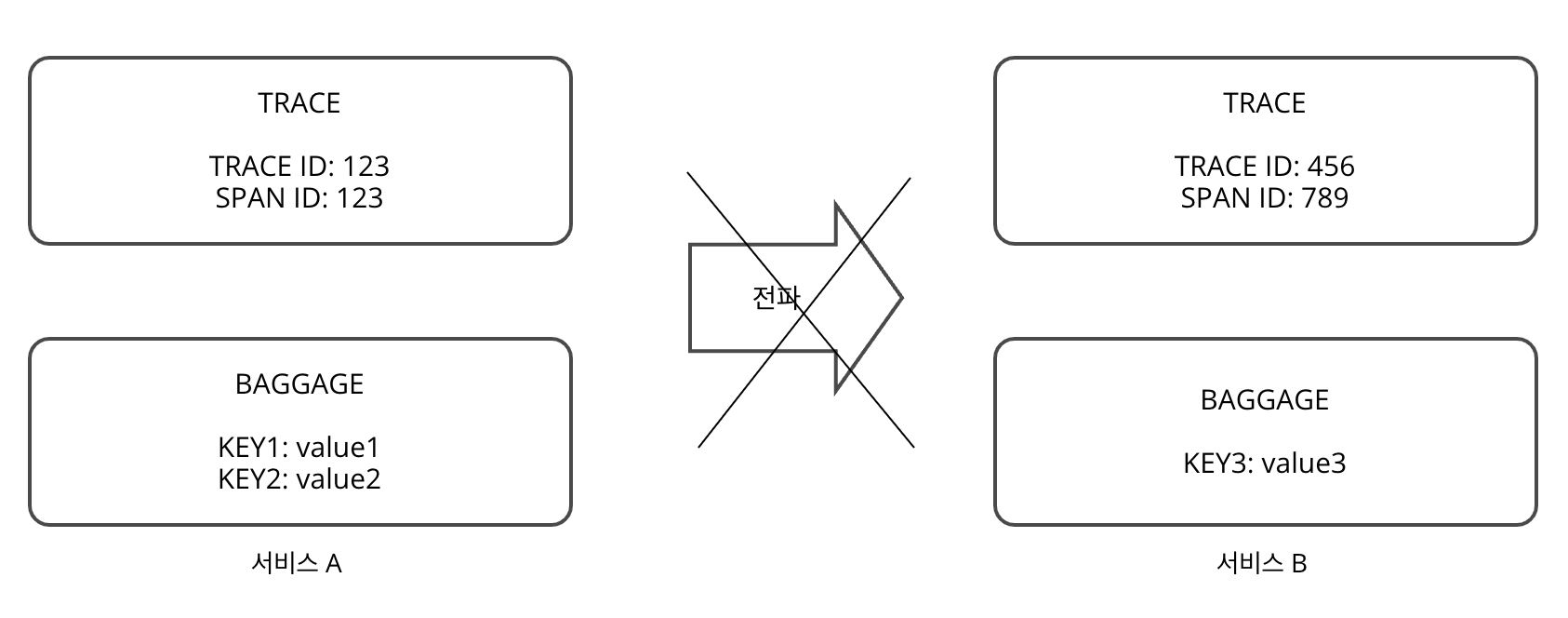
서비스 A 의 콘텍스트가 서비스 B 스팬에 전혀 담기지 않는다
전파 한 경우
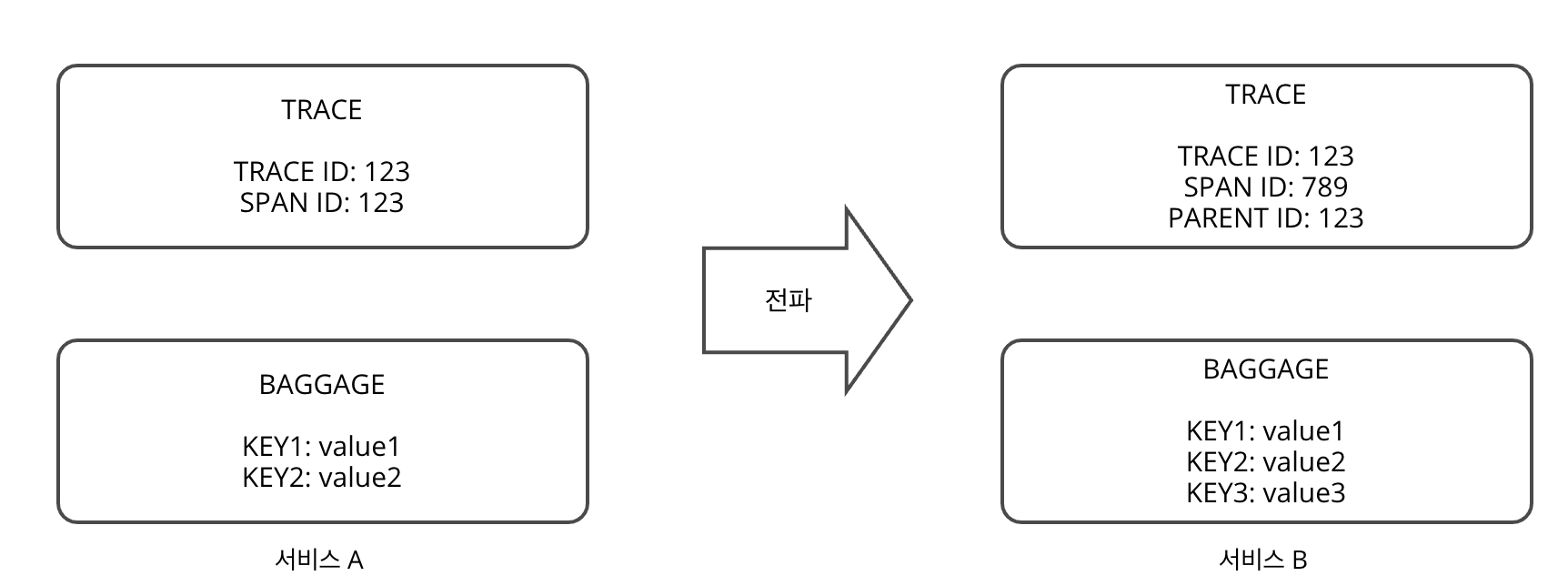
서비스 A 의 콘텍스트를 inject, 서비스 B 스팬에 extract 하여 서비스 B 스팬에 서비스 A 의 콘텍스트를 담는다
6.2.3 파이프라인
애플리케이션 -> 컬렉터 파이프라인
프로바이더 -> 텔레메트리 생성기 -> 프로세서 -> 익스포터 순으로 파이프라인이 구성된다.
- 프로바이더: 텔레메트리 데이터 생성 (SDK 를 통해 디폴트 글로벌 프로바이더를 사용하여 데이터를 생성할 수 있다)
- 텔레메트리 생성기: 텔레메트리 데이터를 생성
- 프로세서: 텔레메트리 데이터 내용을 추가로 수정한다
- 익스포터: 오픈텔레메트리 내부 데이터 모델에 맞춰 변환하여 전달한다.
컬렉터 파이프라인
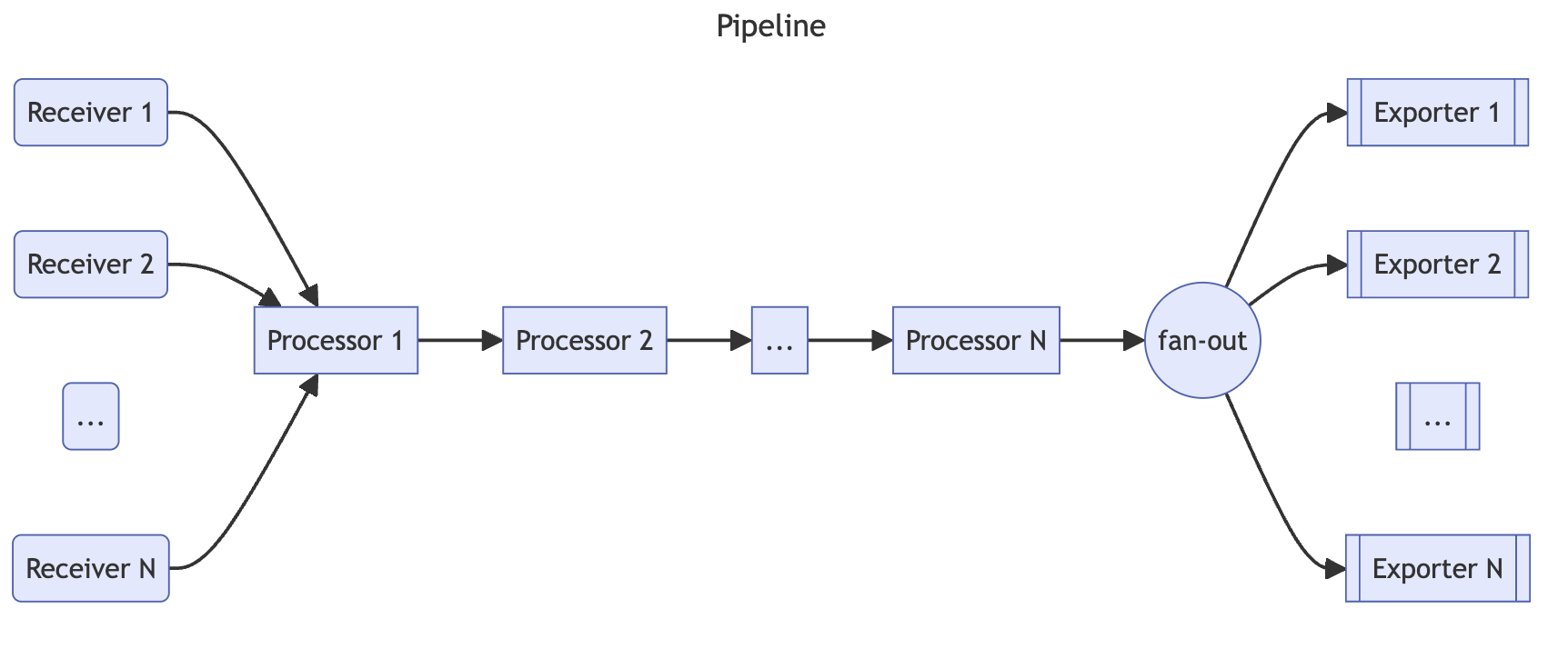
리시버, 프로세서, 익스포터로 구성되면 자세한 내용은 공식 문서를 참고하면 좋을 거 같다.
6.3 추적
추적은 다수의 스팬으로 구성되며 스팬은 다음과 같은 데이터를 포함한다.
- Name
- Parent span ID (empty for root spans)
- Start and End Timestamps
- Span Context
- Attributes
- Span Events
- Span Links
- Span Status
스팬 메시지는 다음과 같이 나타난다.
{
"name": "/v1/sys/health",
"context": {
"trace_id": "7bba9f33312b3dbb8b2c2c62bb7abe2d",
"span_id": "086e83747d0e381e"
},
"parent_id": "",
"start_time": "2021-10-22 16:04:01.209458162 +0000 UTC",
"end_time": "2021-10-22 16:04:01.209514132 +0000 UTC",
"status_code": "STATUS_CODE_OK",
"status_message": "",
"attributes": {
"net.transport": "IP.TCP",
"net.peer.ip": "172.17.0.1",
"net.peer.port": "51820",
"net.host.ip": "10.177.2.152",
"net.host.port": "26040",
"http.method": "GET",
"http.target": "/v1/sys/health",
"http.server_name": "mortar-gateway",
"http.route": "/v1/sys/health",
"http.user_agent": "Consul Health Check",
"http.scheme": "http",
"http.host": "10.177.2.152:26040",
"http.flavor": "1.1"
},
"events": [
{
"name": "",
"message": "OK",
"timestamp": "2021-10-22 16:04:01.209512872 +0000 UTC"
}
]
}스팬 컨텍스트
스팬 컨텍스트는 모든 스팬에서 다음을 포함하는 불변 객체이다
- Trace Id: 스팬이 속한 트레이스를 나타내는 트레이스 ID
- Span Id: 스팬의 스팬 ID
- Trace Flag: 트레이스에 대한 정보를 포함하는 이진 인코딩인 트레이스 플래그
- Trace State: 공급업체별 트레이스 정보를 전달할 수 있는 키-값 쌍의 목록이다
스팬 컨텍스트는 분산 컨텍스트 및 Baggage 와 함께 직렬화되고 전파되는 스팬의 일부이다.
스팬 컨텍스트에는 추적 ID가 포함되어 있으므로 스팬 링크를 만들 때 사용된다.
어트리뷰트
속성은 추적 중인 작업에 대한 정보를 전달하기 위해 스팬에 주석을 달 때 사용할 수 있는 메타데이터를 포함하는 키-값 쌍이다.
이벤트
스팬 이벤트는 스팬에 대한 구조화된 로그 메시지(또는 주석)로 생각할 수 있으며, 일반적으로 스팬의 지속 시간 중 의미 있는 단일 시점을 나타내는 데 사용된다.
예를 들어 웹 브라우저에서 페이지 로드 추적한 스팬은 시작과 끝이 있는 연산이므로 이벤트를 넣기 적합한 스팬이지만, 페이지가 인터랙티브해지는 시점 표시를 담은 스팬같은 경우 시작과 끝이 모호하므로 이벤트를 넣기 적합하지 않다.
링크
링크는 하나의 스팬을 하나 이상의 스팬과 연결하여 인과 관계를 파악할 수 있도록 존재한다
상태
각 스팬에는 세 가지 상태 값이 있다.
- Unset
- Error
- Ok
기본값은 Unset 이다. 스팬 상태가 Unset 인 경우 추적한 작업이 오류 없이 성공적으로 완료되었음을 의미한다. 즉, 개발자가 Ok 를 명시하지 않은 경우 에러없이 성공적으로 완료했다면 Unset 으로 설정된다. (에러가 발생한 게 아님)
종류
스팬이 생성될 때 스팬의 종류는 Client, Server, Internal, Producer, Consumer 중 하나이다. 이 스팬 종류는 추적 백엔드에 추적을 어떻게 조합해야 하는지에 대한 힌트를 제공한다. OpenTelemetry 사양에 따르면, 서버 스팬의 부모는 종종 Client 스팬인 경우가 많고 Client 스팬의 자식은 일반적으로 Server 스팬이다. 마찬가지로, Consumer 스팬의 부모는 항상 Producer이고 생산자 스팬의 자식은 항상 Consumer 이다. 스팬 종류가 제공되지 않으면 스팬 종류는 내부 스팬으로 간주된다.
6.4 메트릭
메트릭은 보통 Name, Kind, Description, Unit 으로 구성되어있다. 예를 들어, 해당 블로그의 데모 API 를 통해 출력한 결과 중 일부를 살펴보면 다음과 같이 metrics 내 name, description, unit, data 가 있다. (kind 는 최근에 나온 instrument 인가보다)
# 메트릭 결과
...
"metrics": [
{
"name": "counter",
"description": "",
"unit": "",
"data": ...
}, ...
]또한 오픈텔레메트릭의 메트릭은 프로메테우스와 다르게 총 6개의 메트릭을 제공한다.
- Counter
- Asynchronous Counter
- UpdownCounter
- Asyncronous UpDownCounter
- (Asyncronous) Gauge
- Histogram
집계
집계는 많은 수의 측정값을 결합하여 특정 기간 동안 발생한 메트릭 이벤트에 대한 정확한 통계 또는 추정 통계로 만드는 기술이며, OTLP 프로토콜은 이러한 집계된 메트릭을 전송한다.
OpenTelemetry API는 views를 사용하여 재정의할 수 있는 각 계측기에 대한 기본 집계를 제공한다.
요청 수명 주기를 캡처하고 개별 요청에 대한 컨텍스트를 제공하기 위한 요청 추적과 달리, 메트릭은 통계 정보를 집계하여 제공하기 위한 것이며, 메트릭 사용 사례로서 다음은 둘 수 있다.
- Reporting the total number of bytes read by a service, per protocol type.
- Reporting the total number of bytes read and the bytes per request.
- Reporting the duration of a system call.
- Reporting request sizes in order to determine a trend.
- Reporting CPU or memory usage of a process.
- Reporting average balance values from an account.
- Reporting current active requests being handled.6.5 로그
추적 및 메트릭의 경우, OpenTelemetry는 클린 시트 설계 방식을 취하고, 새로운 API를 지정하며, 이 API의 전체 구현을 여러 언어 SDK로 제공한다.
하지만 로그를 다루는 OpenTelemetry의 접근 방식은 다르다. 기존 로깅 솔루션은 언어와 운영 에코시스템에 널리 퍼져 있기 때문에, OpenTelemetry는 이러한 로그, 추적 및 메트릭 신호, 기타 OpenTelemetry 구성 요소 사이의 '다리' 역할을 한다. 실제로 이러한 이유로 로그용 API를 "로그 브리지 API"라고 부르기도 한다.
책 내용과는 다르게 2022년 10월 이후 LogExporter를 LogRecordExporter로, LogProcessor를 LogRecordProcessor로, LogEmitter를 Logger로 등의 주요 클래스 이름 변경된 거 같다 (참고 링크)
따라서 공식 문서에 적혀있는 내용을 토대로 글을 작성한다.
Log Appender / Bridge
로그 브리지 API는 로깅 라이브러리 작성자가 로그 애펜더/브리지를 구축할 수 있도록 제공되므로 애플리케이션 개발자가 직접 호출해서는 안된다. 대신 선호하는 로깅 라이브러리를 사용하고 로그를 OpenTelemetry LogRecordExporter로 내보낼 수 있는 로그 애펜더(또는 로그 브리지)를 사용하도록 구성하기만 하면되며, OpenTelemetry 언어 SDK는 이 기능을 제공하고 있다.
Logger Provider
Logs Bridge API의 일부이며 로깅 라이브러리의 작성자인 경우에만 사용해야한다.
로거 프로바이더(로거 프로바이더라고도 함)는 로거를 위한 팩토리다. 대부분의 경우 로거 공급자는 한 번 초기화되며 그 수명 주기는 애플리케이션의 수명 주기와 일치한다. 로거 프로바이더 초기화에는 리소스 및 익스포터 초기화도 포함된다.
Logger
Logs Bridge API의 일부이며 로깅 라이브러리의 작성자인 경우에만 사용해야한다.
로거는 로그 공급자에서 생성되고 로그 레코드를 생성한다.
Log Record Exporter
로그 레코드 내보내기는 로그 레코드를 컨슈머에게 보낸다. 이 컨슈머는 디버깅 및 개발 시간을 위한 표준 출력, OpenTelemetry 수집기 또는 사용자가 선택한 오픈 소스 또는 공급업체 백엔드를 의미한다.
Log Record
로그 레코드는 이벤트의 기록을 나타낸다. 그 기록에는 다음과 같은 필드들로 구성되어있다
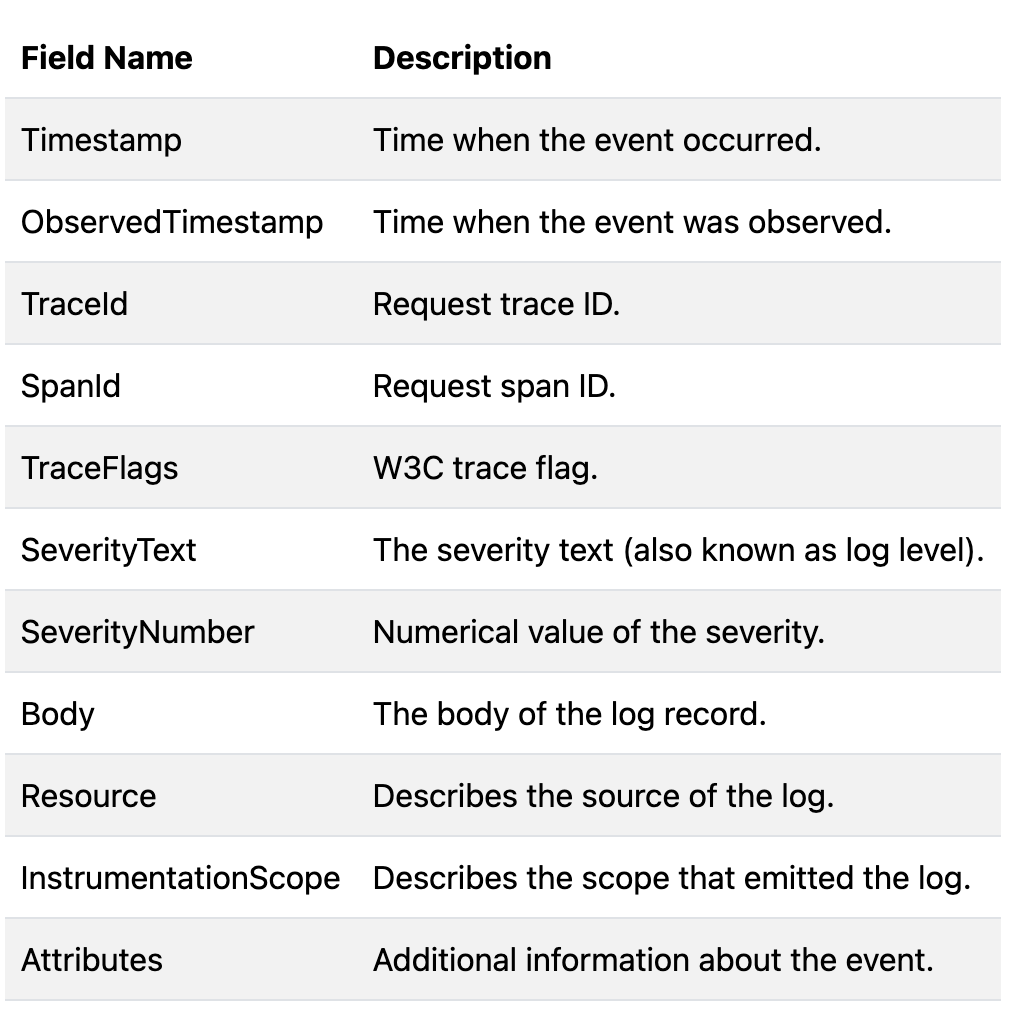
6.6 컬렉터
오픈 텔레메트리 수집기는 텔레메트리 데이터를 수신, 처리 및 내보내는 방법을 공급업체에 구애받지 않고 구현할 수 있다. 따라서 여러 에이전트/수집기를 실행, 운영 및 유지 관리할 필요가 없다. 확장성이 향상되었으며 하나 이상의 오픈 소스 또는 상용 백엔드로 전송하는 오픈 소스 통합 가시성 데이터 형식(예: Jaeger, Prometheus, Fluent Bit 등)을 지원한다.
컬렉터는 다음과 같은 목표가 있다
- 사용성: 합리적인 기본 구성, 인기 있는 프로토콜 지원, 즉시 실행 및 수집이 가능하다.
- 성능: 다양한 부하와 구성에서 매우 안정적이고 뛰어난 성능을 발휘한다.
- 관찰 가능성: 관찰 가능한 서비스의 모범 사례이다.
- 확장성: 핵심 코드를 건드리지 않고도 사용자 정의할 수 있다.
- 통합: 추적, 메트릭 및 로그를 지원하는 에이전트 또는 수집기로 배포 가능한 단일 코드베이스이다. (향후)
컬렉터는 데이터 수신, 처리 및 내보내기 파이프라인을 사용하여 수행된다.
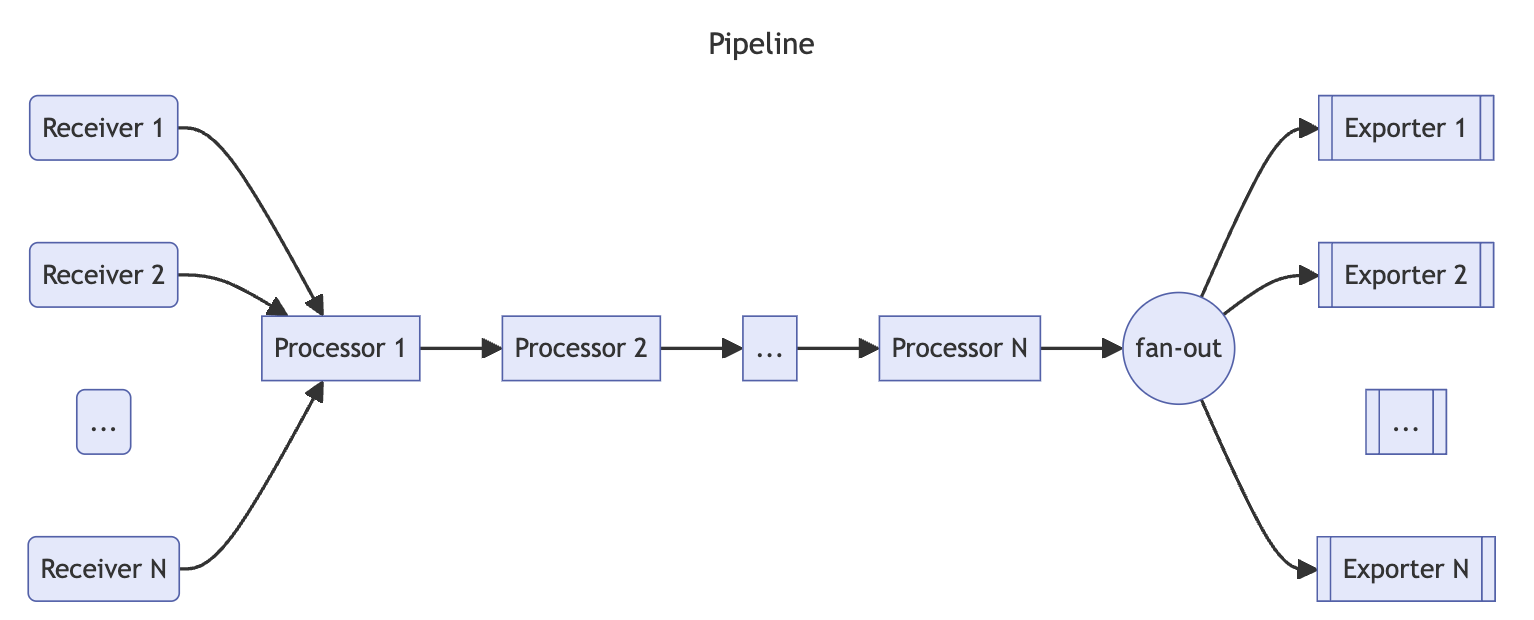
- receiver: 데이터를 수집하는 일련의 수신기.
- processor: 수신기로부터 데이터를 받아 처리하는 일련의 선택적 프로세서.
- exporter: 프로세서에서 데이터를 가져와서 수집기 외부로 보내는 일련의 내보내기.
동일한 수신기가 여러 파이프라인에 포함될 수 있으며 여러 파이프라인에 동일한 내보내기가 포함될 수 있다.
Receiver
수신기는 일반적으로 네트워크 포트에서 수신 대기하고 원격 분석 데이터를 수신한다. 또한 스크레이퍼처럼 능동적으로 데이터를 가져올 수도 있다. 일반적으로 하나의 수신기가 수신된 데이터를 하나의 파이프라인으로 보내도록 구성된다. 그러나 동일한 수신기를 구성하여 동일한 수신 데이터를 여러 파이프라인으로 보내도록 구성할 수도 있다. 이렇게 하려면 여러 파이프라인의 수신자 키에 동일한 수신자를 나열하면 된다.
receivers:
otlp:
protocols:
grpc:
endpoint: localhost:4317
service:
pipelines:
traces: # a pipeline of “traces” type
receivers: [otlp]
processors: [memory_limiter, batch]
exporters: [otlp]
traces/2: # another pipeline of “traces” type
receivers: [otlp]
processors: [transform]
exporters: [otlp]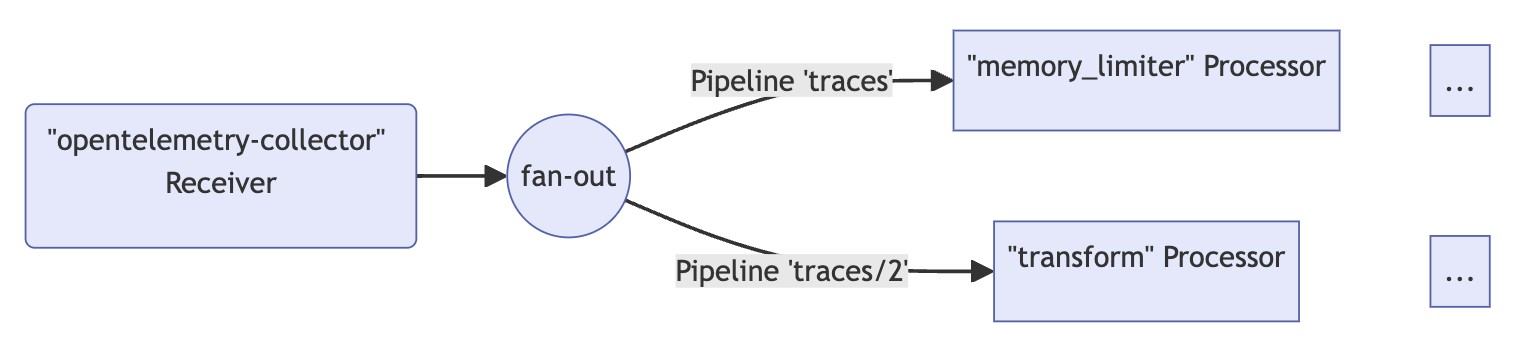
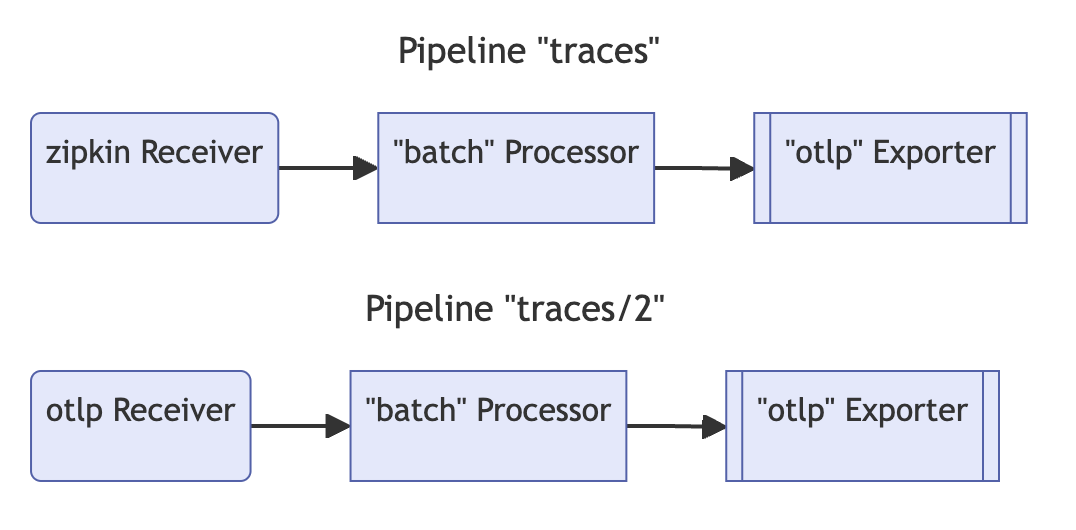
하나의 리시버로부터 두 개의 파이프라인 (traces, traces/2) 를 구성한 예시이다. 이렇게 할 경우 주의사항이 있다. 동일한 리시버가 둘 이상의 파이프라인에서 참조되는 경우, 리시버는 런타임에 데이터를 팬아웃에게 보내는 수신기 인스턴스를 하나만 생성한다. 팬아웃은 차례로 각 파이프라인의 첫 번째 프로세서로 데이터를 전송한다. 리시버에서 팬아웃으로, 그리고 프로세서로의 데이터 전파는 동기식 함수 호출을 사용하여 완료됩니다. 즉, 한 프로세서가 호출을 차단하면 이 리시버에 연결된 다른 파이프라인이 동일한 데이터를 수신하지 못하도록 차단되고 리시버 자체는 새로 수신한 데이터의 처리와 전달을 중단한다.
Exporter
익스포터는 일반적으로 수신한 데이터를 네트워크의 대상으로 전달하지만 데이터를 다른 곳으로 보낼 수도 있다. 예를 들어, 디버그 익스포터는 원격 분석 데이터를 로깅 대상에 쓴다.
이 구성을 사용하면 동일한 파이프라인에서도 동일한 유형의 익스포터를 여러 개 사용할 수 있다. 예를 들어, 두 개의 OTLP 익스포터를 정의하여 각각 다른 OTLP 엔드포인트로 전송할 수 있다.
exporters:
otlp/1:
endpoint: example.com:4317
otlp/2:
endpoint: localhost:14317익스포터는 일반적으로 하나의 파이프라인에서 데이터를 가져온다. 하지만 앞서 리시버와 같은 방법으로, 동일한 익스포터에서 데이터를 보내도록 여러 파이프라인을 구성할 수 있다.
exporters:
otlp:
protocols:
grpc:
endpoint: localhost:14250
service:
pipelines:
traces: # a pipeline of “traces” type
receivers: [zipkin]
processors: [memory_limiter]
exporters: [otlp]
traces/2: # another pipeline of “traces” type
receivers: [otlp]
processors: [transform]
exporters: [otlp]위와 같이 구성한다면 두 개의 파이프라인(traces, traces/2) 는 동일한 익스포터로 데이터를 전달한다.
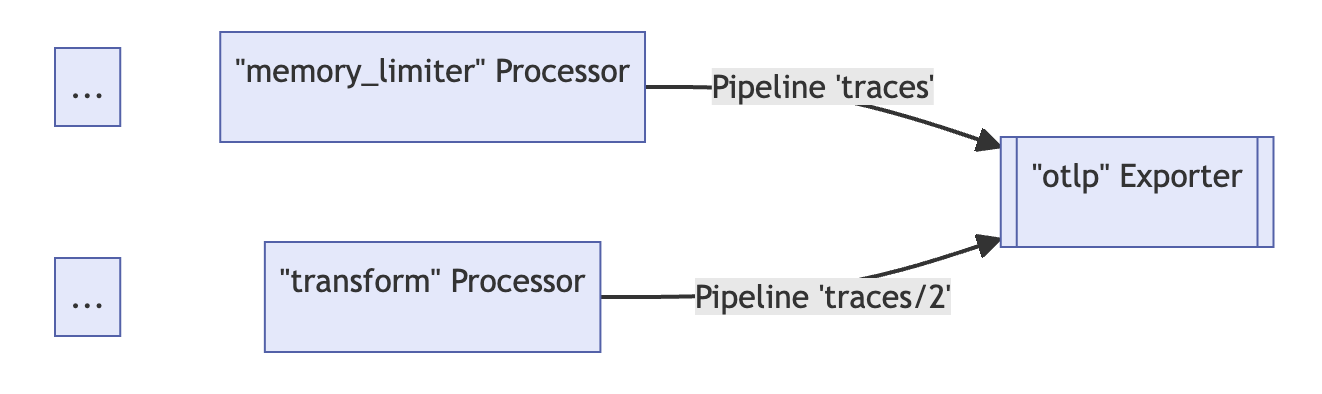
Processor
파이프라인에는 순차적으로 연결된 프로세서가 포함될 수 있다. 첫 번째 프로세서는 파이프라인에 대해 구성된 하나 이상의 리시버로부터 데이터를 가져오고, 마지막 프로세서는 파이프라인에 대해 구성된 하나 이상의 익스포터로 데이터를 보낸다. 첫 번째 프로세서와 마지막 프로세서 사이의 모든 프로세서는 앞선 프로세서 하나에서만 데이터를 수신하고 뒤따르는 프로세서 하나에만 데이터를 보낸다.
프로세서는 데이터를 전달하기 전에 스팬에 속성을 추가하거나 제거하는 등 데이터를 변환할 수 있다. 또한 데이터를 전달하지 않기로 결정하여 데이터를 삭제할 수도 있다. 또는 새로운 데이터를 생성할 수도 있다.
앞서 리시버와 익스포터는 멀티 파이프라인 구성시 각 파이프라인 별로 동일한 리시버 또는 익스포터를 넣은 경우 파이프라인 개수와 상관없이 하나만 생성됐다. 예를 들어, 리시버의 경우 하나의 리시버가 데이터를 수신하고 팬아웃을 통해 여러 프로세서로 데이터를 전달한다. 익스포터의 경우 여러 프로세서로부터 하나의 익스포터가 데이터를 전달받아 외부로 전달한다.
하지만 프로세서의 경우 다르다. 다음 예시를 살펴보자.
processors:
batch:
send_batch_size: 10000
timeout: 10s
service:
pipelines:
traces: # a pipeline of “traces” type
receivers: [zipkin]
processors: [batch]
exporters: [otlp]
traces/2: # another pipeline of “traces” type
receivers: [otlp]
processors: [batch]
exporters: [otlp]위와 같이 구성된 경우 각 파이프라인 별로 batch 프로세서가 들어가며 동일한 인스턴스가 아닌 서로 연결고리가 없는 독립적인 인스턴스 2개가 생성된다.
Running As Agent
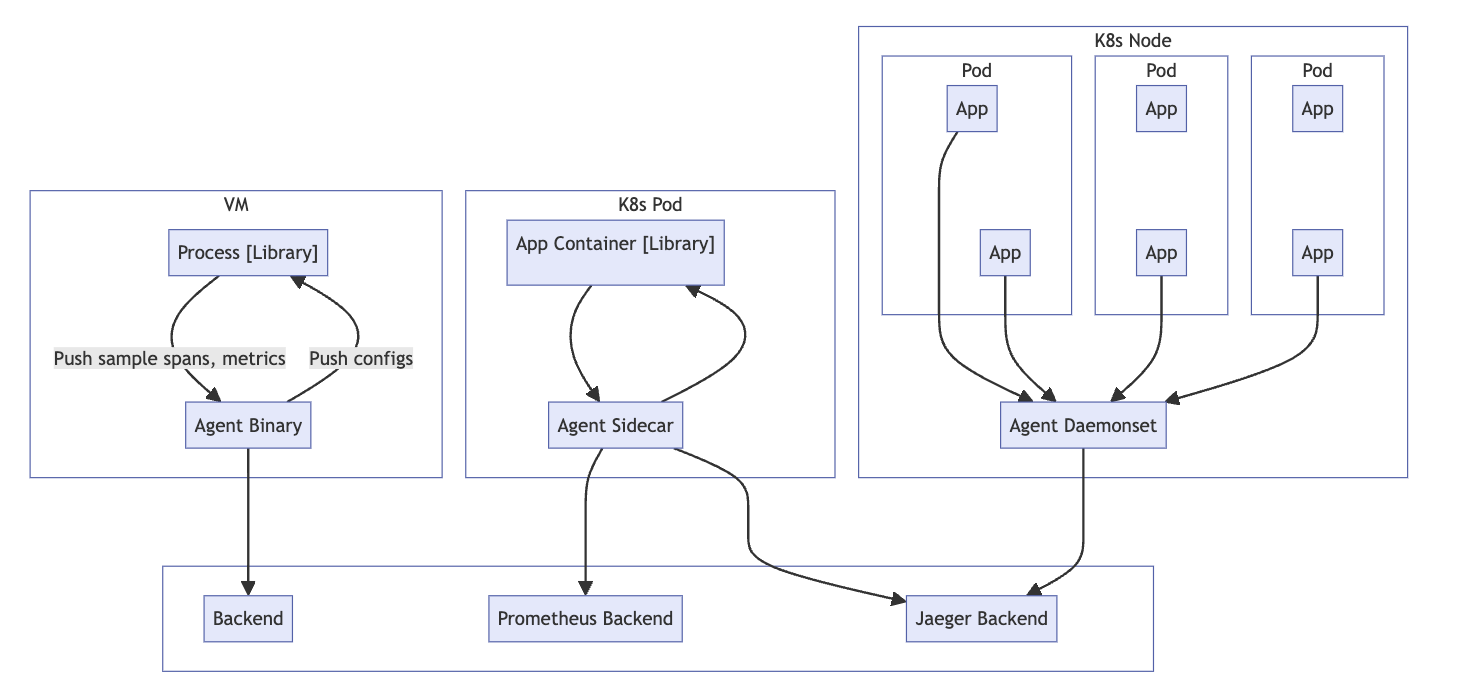
애플리케이션과 함께 실행되거나 애플리케이션과 동일한 호스트에서 실행되는 컬렉터 인스턴스(e.g. binary, sidecar, or daemonset)를 사용하는 방법이다.
에이전트 모드는 워크로드에 "가까운" OpenTelemetry 수집기를 실행하는 것을 의미한다. Kubernetes의 맥락에서, 이것은 사이드카(앱 포드에서 수집기를 실행하는 다른 컨테이너)일 수 있다.
이 모드의 가장 큰 장점은 컬렉터가 로드에 "가깝게" 실행되므로 불필요한 노드 간 트래픽이 생성되지 않는다는 것이다.
또한 에이전트 모드는 클러스터에 워커 노드가 1개 이상 있는 경우 확장성이 더 뛰어나다.
Running As Gateway
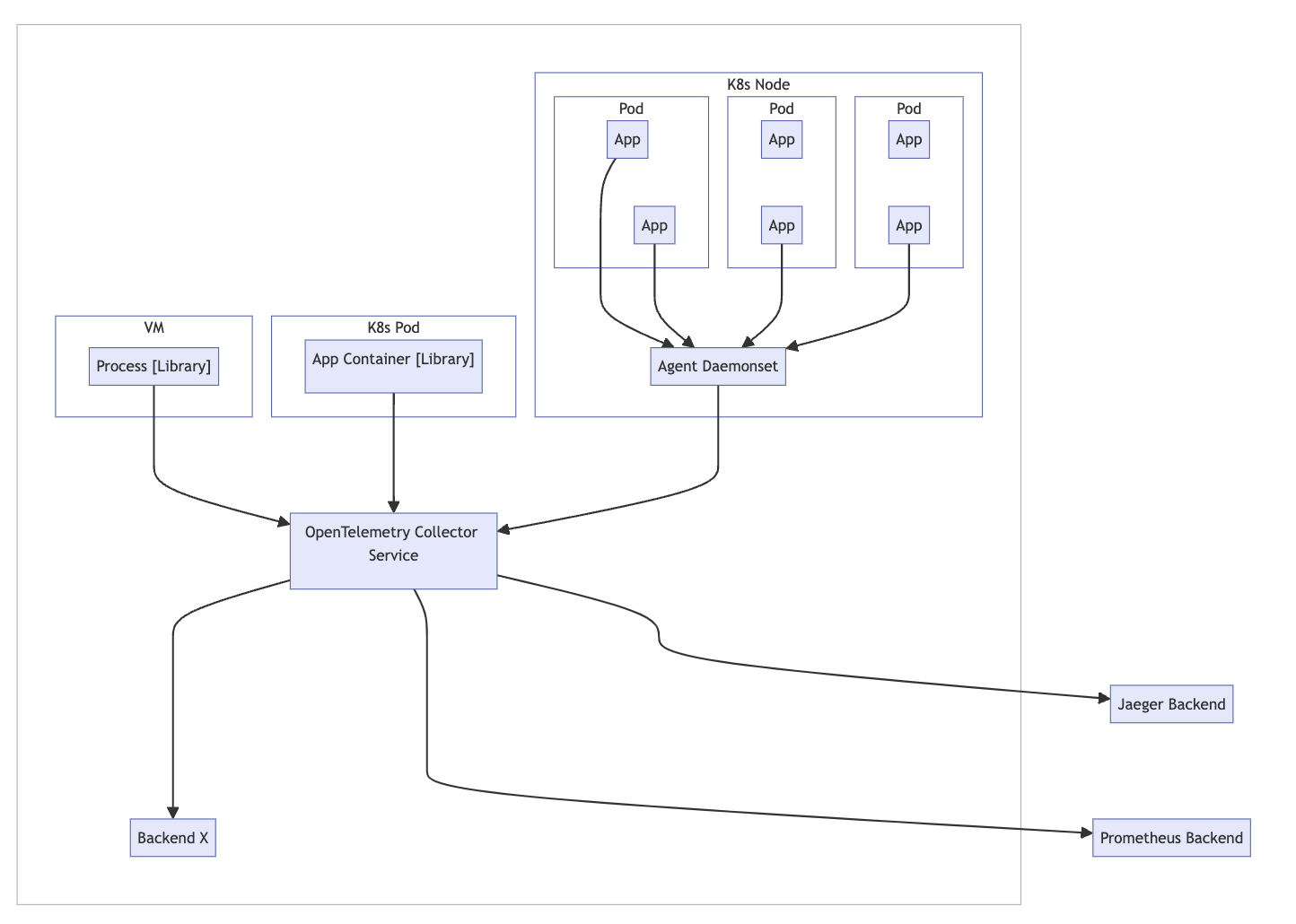
클러스터나 데이터 센터 등에서 독립 실행형 서비스로 실행되는 하나 이상의 컬렉터 인스턴스(e.g. container or deployment)를 이용하는 방법이다.
컬렉터의 중앙(독립형) 운영으로 다음을 수행할 수 있다.
- 민감한 로그 항목 필터링, 추적을 위한 샘플링 결정, 특정 메트릭 삭제 등과 같은 정책을 중앙에서 시행한다.
- 중앙에서 권한과 자격 증명을 관리할 수 있다. 예를 들어, Prometheus 원격 쓰기 익스포터를 사용해 메트릭을 Prometheus용 Amazon 관리형 서비스로 수집하려면 컬렉터는 특정 IAM 정책이 첨부된 IAM 역할을 사용해야 한다.
