(paper review) A Case Study of Deep Learning Based Multi-Modal Methods for Predicting the Age-Suitability Rating of Movie Trailers
이 글에서는 movie trailer를 이용한 video rating을 하는 논문을 리뷰한다. 오로지 공부용으로 작성되었으며 상업, 영리를 목적으로 작성하지 않았음을 밝힙니다.
introduce paper
paper: https://arxiv.org/abs/2101.11704
해당 paper는 2021년도에 나온 최근 paper이다. 필자는 현재 movie trailer를 이용하여 content rating을 하는 연구를 진행하고 있다. 이와 관련하여 survey를 하는 중 좋은 접근방법을 소개하는 해당 논문을 리뷰하고자 한다.
introduce
폭력성, 공격성을 지닌 영상물이 어린 사용자에게 부적절한 영향을 미칠 수 있다. 이와 관련하여 MPAA Guideline에 따라 영상물마다 나이 연령대를 분류하고 있다. 해당 작업을 딥러닝 multi-modal classification system을 통해 분류하는 것이 해당 논문에서 하고자 하는 연구이다. 이때 multi-modal task는 audio, video, text(sub title) 로 이루어 진다.
dataset
해당 논문은 IMDB와 유튜브를 통해 다양한 trailer를 수집하여 직접 dataset을 구축하였다.
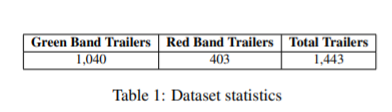
출처 : paper[1]의 table 1
green band trailers은 'all audiences' or appropriate audiences'(G,PG)에 해당하고
red band trailers은 'mature audiences'(not children) 에 해당한다.
위와 같이 label을 나누고 input으로 text, video, audio를 넣어준다(text는 subtitle에 해당하며 해당 과정은 paper[2]를 참고하여 speech recognition tool을 사용하여 추출했다고 한다).
Multi-Modal(MMTR)
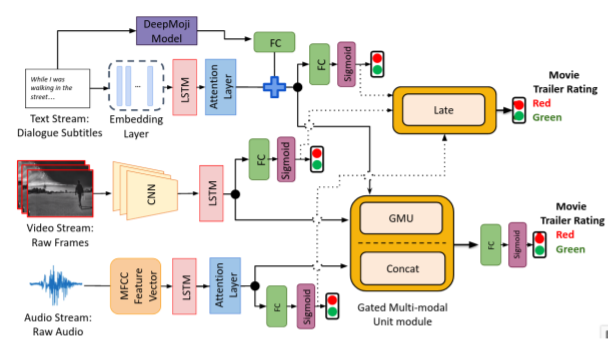
출처 : paper[1]의 figure 1
text Stream
BERT + LSTM with Attention
BERT는 사전훈련된 임베딩을 지닌 모델이라고 생각하면 된다. 이를 통해 단어를 임베딩하여 벡터화 시키고 LSTM with Attention을 통해 시퀀스 연산을 하며 text로부터 feature를 추출하였다. 또한 DeepMoji[3] 을 사용하여 Emotion Vector를 얻어내고 attention으로부터 나온 feature와 concat을 해주었다.
video Stream
[4]의 논문과 같이 CNN + LSTM을 이용하여 frame마다 feature를 추출하고 LSTM을 통해 시퀀스 연산을 해준것으로 보인다. 즉, CNN을 통해 spatial information를, LSTM을 통해 temporal information을 얻은 것이다.
audio Stream
MFCC 방법을 통해 해당 audio파일로부터 Mel Frequency cepstral Coefficient를 추출하고 LSTM에 넣어준 것으로 보인다. 이 방법은 흔히 speech recognition에서 자주 쓰이는 방법으로 오디오 파일을 이미지로 변환하여 CNN으로 분류하는 연구도 진행된 적이 있다.
fusion
GMU
multi-modal에서 각 model들이 상호적으로 영향을 주고받을 수 있도록 일종의 gate이다.
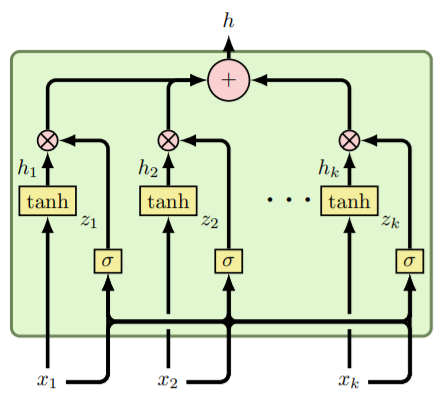
출처 : paper[5]의 figure 2
위처럼 tanh로 activation 한 것과 k개의 output vector를 sigmoid하여 연산을 함으로써 상호적으로 output을 추출한다. paper[5]에서는 movie poster와 text를 통해 genre classification을 진행하는데 이때 GMU를 통해 훈련을 하였을 때 좋은 성능을 보여줬다.
Feature Concatnation Fusion
각 model에서 나온 feature들을 concat 시키는 작업이다.
Late Fusion
해당 논문에서는 majority voting, averaging 등의 규칙을 통해 각 modalities를 merge해주는 작업을 하였다.
Experiment
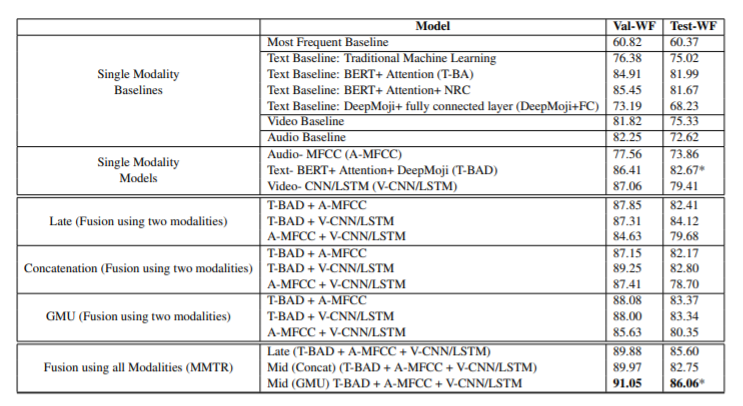
출처 : paper[1]의 tabel 2
해당 논문에서는 각 stream마다 single modality를 진행하고, 또 multi-modality로도 진행하였다. 역시 논문에서 소개한 MMTR이 가장 좋은 성능을 보여주었다.
개인적인 생각
해당 논문에는 필자가 진행하는 movie rating 연구에 많은 도움을 줄 기술들이 소개되었다. 필자 또한 text, audio, video를 통해서 연구를 진행하는데 해당 논문과 차별성을 두기 위해서 구체적으로 문제점을 정의하고 모델링 과정을 진행할 것이다.
reference
[1] Shafaei, Mahsa, et al. "A Case Study of Deep Learning Based Multi-Modal Methods for Predicting the Age-Suitability Rating of Movie Trailers." arXiv preprint arXiv:2101.11704 (2021).
[2] Joe Yue-Hei Ng, Matthew Hausknecht, Sudheendra Vijayanarasimhan, Oriol Vinyals, Rajat Monga, and
George Toderici. 2015. Beyond short snippets:
Deep networks for video classification. In Proceedings of the IEEE conference on computer vision and
pattern recognition, pages 4694–4702.
[3] Bjarke Felbo, Alan Mislove, Anders Søgaard, Iyad
Rahwan, and Sune Lehmann. 2017. Using millions
of emoji occurrences to learn any-domain representations for detecting sentiment, emotion and sarcasm
[4] Jeffrey Donahue, Lisa Anne Hendricks, Sergio Guadarrama, Marcus Rohrbach, Subhashini Venugopalan,
Kate Saenko, and Trevor Darrell. 2015. Long-term recurrent convolutional networks for visual recognition and description. In In Proc. IEEE Conference
on Computer Vision and Pattern Recognition
[5] Arevalo, John, et al. "Gated multimodal units for information fusion." arXiv preprint arXiv:1702.01992 (2017).
