2.5 마이크로서비스
2.5.1 마이로서비스 개발 흐름
- 스프링 부트, Go 로 개발된 소스를 빌드해서 바이너리 생성 -> 도커 파일 등으로 이미지 빌드 -> 생성된 도커 이미지를 참조해서 헬름 차트 생성
- 쿠버네티스 내 어플리케이션은 내부적으로 도커 이미지에 다양한 리소스를 결합하는 형식으로 구성된다
- 디스크
- 디플로이먼트는 상태가 없으므로 PV 사용
- 스테이트풀셋은 상태 유지 (데이터베이스 등 서비스에 사용)
- 네트워크
- 인그레스와 서비스 사용
- 서비스 디스커버리 설정 필요
- 동적인 확장
- HPA, CA, VPA, 디플로이 먼트
- 디스크
2.5.2 관측 가능성의 마이크로서비스
- 그라파나의 관측 가능성은 대게 하나의 어플리케이션의 여러 파드로 이루어져 있다.
- CQRS(Command Query Responsibility Segregation) 패턴이 적용되어 있다
- 읽기와 쓰기를 나눈다
- 데이터를 변경하는 로직과 데이터를 조회하는 로직을 분리함으로써, 시스템의 각 부분을 더 명확하게 이해하고 관리할 수 있다
- 각각 독립적으로 크기 조정할 수 있다
example (grafana mimir)
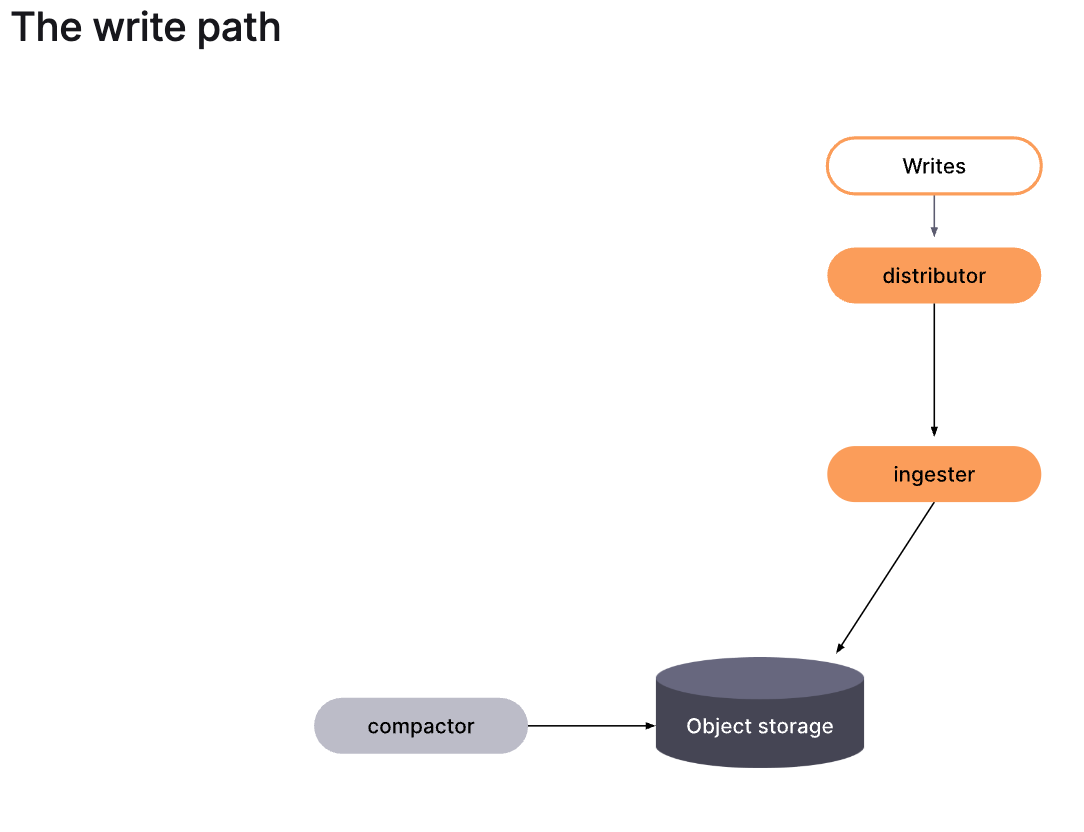
- write -> distributor -> ingester -> object storage <- compactor
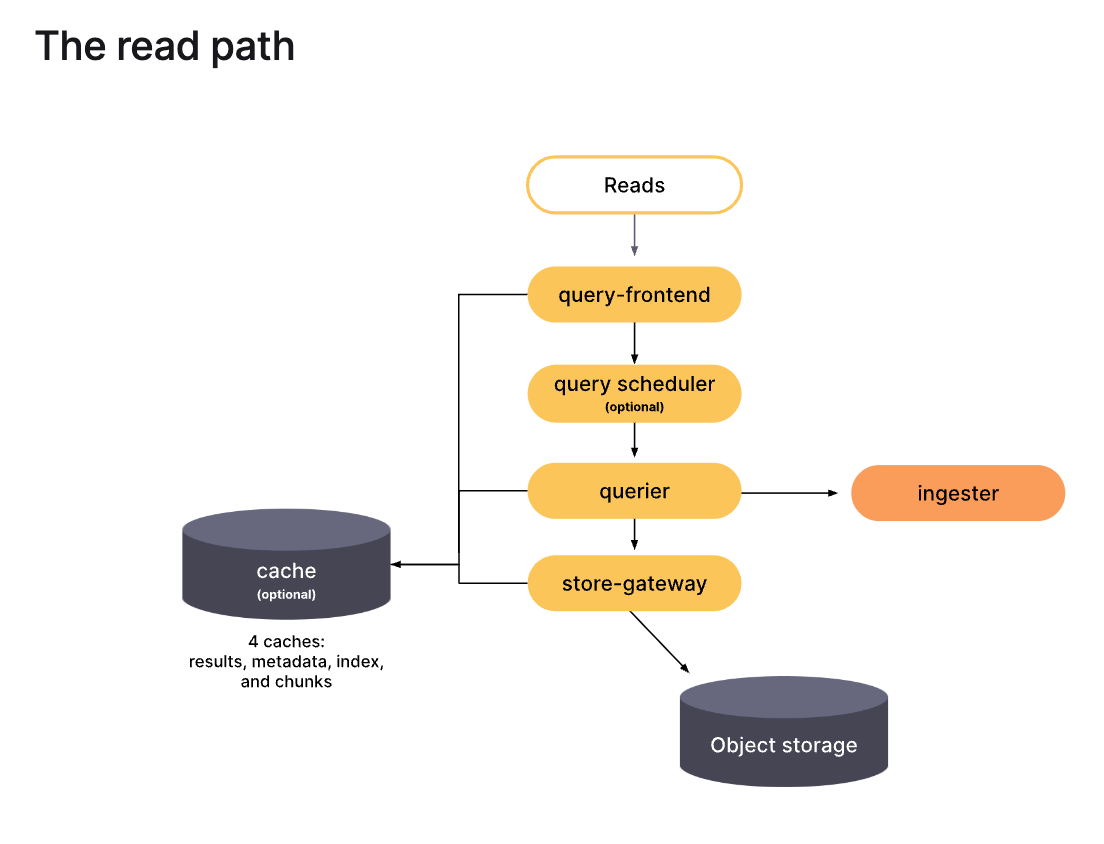
- read -> query-frontend -> querier -> object storage
ref: https://grafana.com/docs/mimir/latest/get-started/about-grafana-mimir-architecture/
2.6 일관된 해시
- 서버가 추가되거나 삭제될 때 서버 풀 개수가 변하면서 노드 간 데이터 분배가 골고루 이루어지지 않아 성능저하를 불러일으킬 수 있음
일반 경우
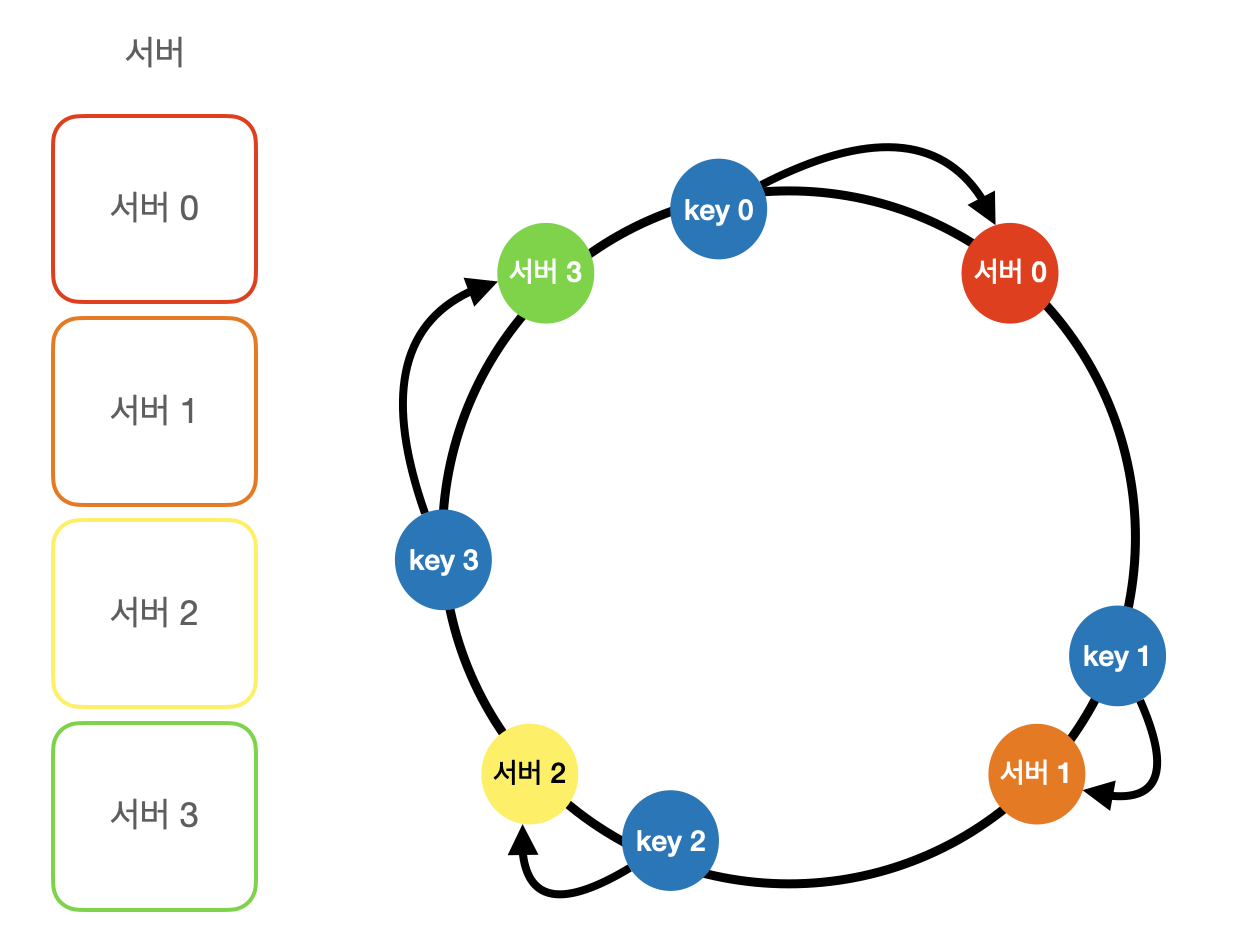
- 키의 시계방향 기준으로 가장 가까운 서버에 할당된다
서버 추가된 경우
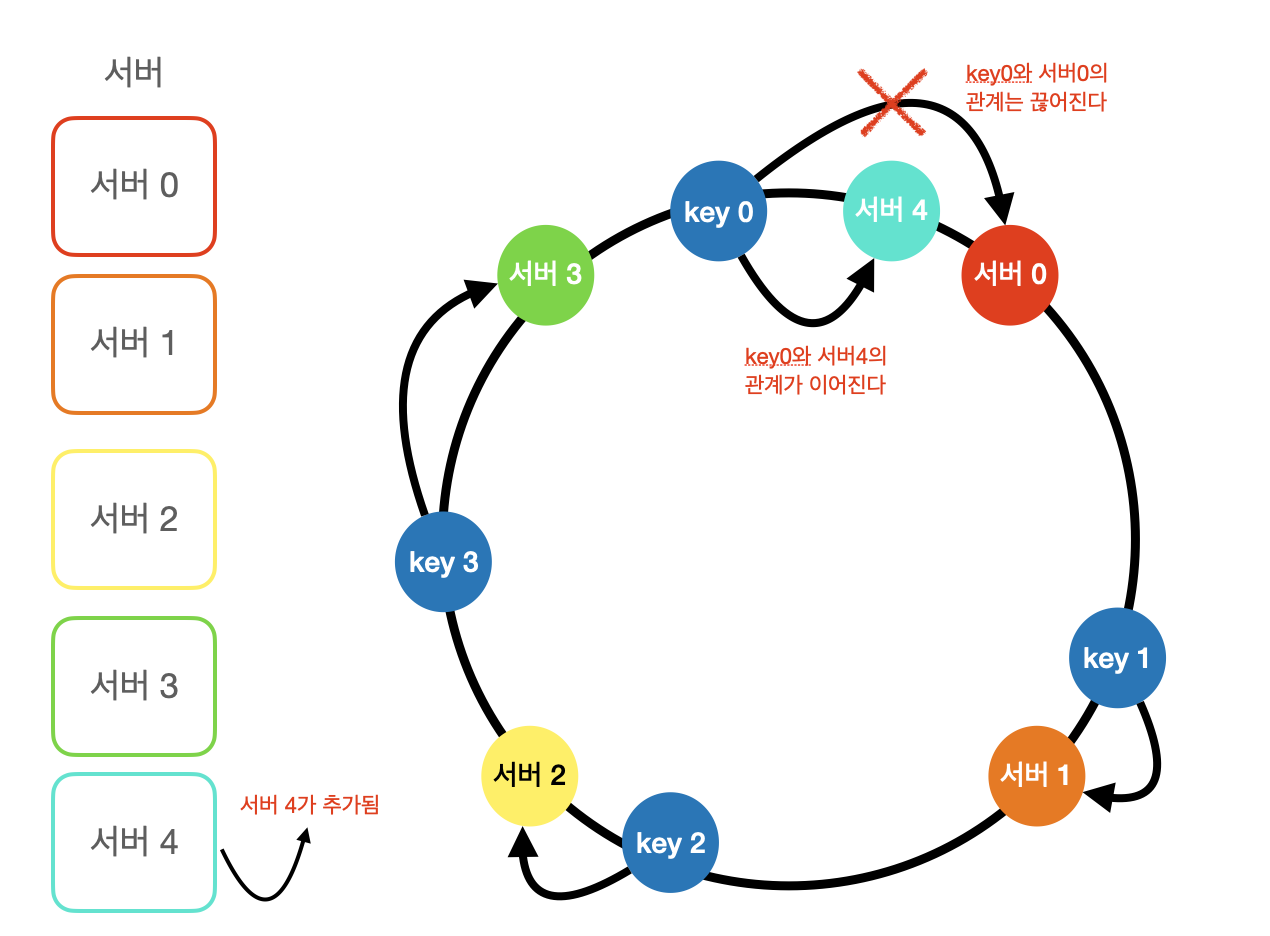
- 서버1 과 서버 3 사이에 서버 4가 추가된다 가정하면
- 기존 서버1 과 서버 3 사이에 있던 키(서버 1에 할당된)가
- 서버1 보다 서버4가 가까워졌기 때문에 서버4로 할당된다
서버 삭제된 경우
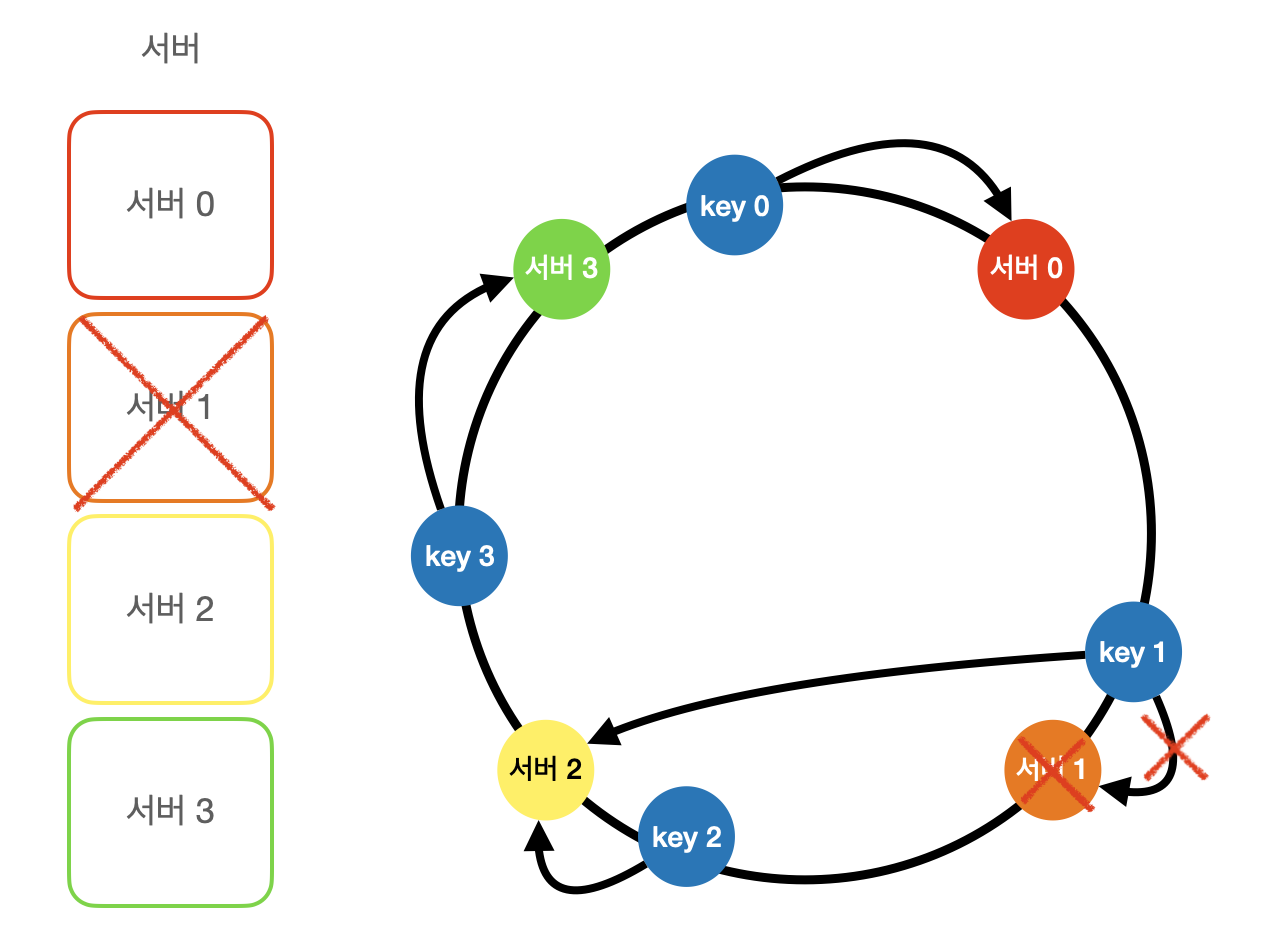
- 서버1 삭제된다 가정하면
- 기존 서버0 과 서버 2 사이에 있던 키(서버 1에 할당된)가
- 시계방향으로 가장 가까운 서버2로 할당된다
2.7 관측 가능성 시각화
- 일반적인 바, 차트 라인은 단순한 값의 증감을 나타내기 때문에 관측 가능성의 복잡한 의미를 모두 표현할 수 없다
- 상관, 분포, 변동폭, 절차, 증감, 관계, 군집, 순서 등
- 시계열 차트 + 히스토그램, 히트맵
- 플레임 그래프 (프로파일 시각화)
- 노드 그래프, 폴리스탯 차트
=> 사용 예시를 많이 봐야될 듯!
2.8 키-값 저장소
- redis, dynamoDB
- 그라파나 관측 가능성에서는 redis 보다는 memcached 를 권장하고 읽기에 주로 사용된다.
- 추측컨데 memcached 가 redis 보다 메모리도 덜 사용하고, 내부 라이브러리의 consistent hashing 을 이용해 장애가 발생하더라도 안정적으로 읽기가 가능하기 때문이 아닐까 싶다
- redis vs memcached 관련해서는 링크 참고하면 좋을 듯 하다
2.9 객체 스토리지
- 빅데이터는 주소 분산형 DB 또는 객체 스토리지를 사용한다
- 객체 스토리지는 네트워크를 통해 읽기/쓰기가 실행되며, 다수의 하드웨어에 데이터를 분산함으로써 데이터 양이 늘어나도 성능이 떨어지지 않게 고안되어있다
- 그러나 객체 스토리지는 소량의 데이터를 가질 경우 비효율적이기 때문에 대부분 작은 파일을 읽고 쓰기보다는 블록 형태로 저장한다 (작은 데이터의 경우 데이터 양보다 통신 오버헤드가 큼)
- 파티셔닝을 적용하여 어플리케이션에서 병렬처리하면 월등히 높은 성능을 보장한다
2.10 안정적 데이터 관리
- 데이터 파티션
- 데이터를 여러 파티션으로 나눠 분할 저장하는 방법이다
- 데이터를 고르게 분산하고, 노드 추가 및 삭제 시 데이터 이동 최소화 등 문제를 해결하기 위해 안정 해시를 사용한다
- 데이터 다중화
- 높은 가용성과 안정성을 확보하기 위해 여러 서버에 저장하는 방법이다
- 안정 해시를 사용한다 가정하고, 데이터를 저장할 N개 서버 고르는 방법
- 해시 링에서 시계 방향으로 N개 서버까지 저장한다
- 데이터 일관성
- 다중화된 데이터는 동기화가 되어야 한다.
- 정족수 합의 프로토콜을 사용하면 읽기/쓰기 연산 모두에 일관성을 보장할 수 있다
- N: 복제본 수
- W: 쓰기 연산에 대한 정족수
- R: 읽기 연산에 대한 정족수
- 만약 N=3 이고 W=1 이라면 중재자가 3개의 서버에서 쓰기 성공 응답을 1개 받았을 때 성공했다고 판단하는 것이다. 예를 들어, s1, s2, s3 서버 3개에 쓰기를 시도했는데, 중재자가 s2 에서 쓰기 성공 응답을 받았다면 s1과 s3의 쓰기 응답과 상관없이 성공한걸로 간주한다.
- 만약 쓰기/읽기 연산에 대한 정족수가 높아진다면 데이터 간 일관성이 높게 유지되지만 그만큼 응답 지연 등 문제점이 있다.
- 보통 W=1, R=N 을 사용하며 높은 일관성을 보장하고 싶은 경우 W+R > N 을 사용한다
- 장애 감지
-
멀티 캐스팅 방법
- 노드끼리 멀티 캐스팅하는 방법이다.
- 특정 노드가 죽었을 때 다른 노드들이 장애를 감지하고 알린다.
- 단, 해당 방법은 노드가 증가할수록 비효율적이다.
-
가십 프로토콜 방법
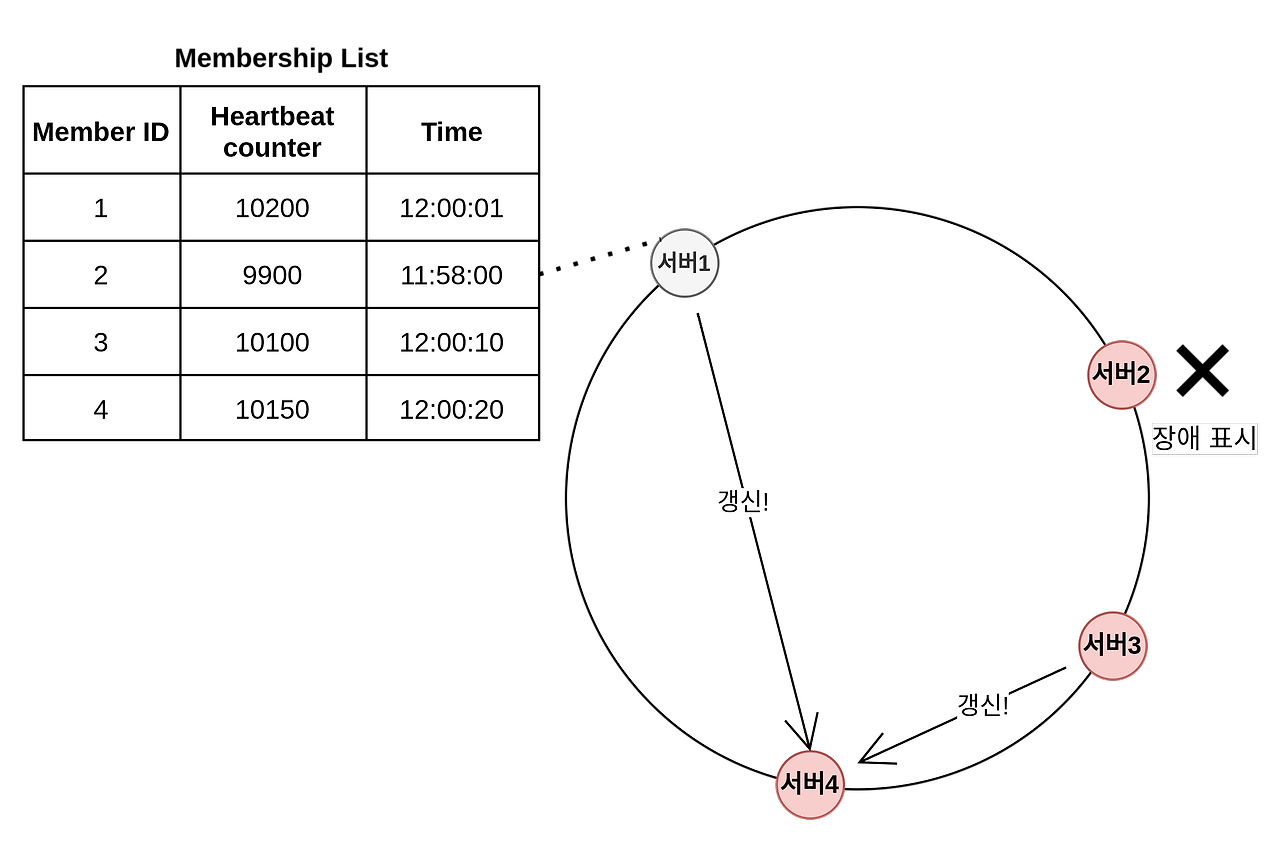
- 모든 서버는 멤버십 목록을 가진다 (멤버십 목록에는 각 노드의 아이디와 heartbeat counter, time이 저장되어 있다)
- 그리고 각자 자신의 heartbeat counter 를 증가시킨다
- 이후 무작위로 다른 노드에 자신의 멤버십 목록을 전달한다
- 멤버십 목록을 전달받은 노드는 자신의 멤버십 목록을 최신화한다
- 만약 heartbeat counter값이 지정된 시간 동안 갱신되지 않으면 해당 멤버는 장애 상태인 것으로 간주한다
- 위 이미지에서 서버1은 서버2가 오랜시간동안 heartbeat가 증가되지 않은 것을 확인하고 서버 4에게 전달한다 (서버1에서 서버2의 장애를 감지함)
- 이후 서버4에서도 서버2가 오랜시간동안 heartbeat가 증가되지 않은 것을 확인할 것이다 (서버4에서 서버2의 장애를 감지함)
-
2.11 시계열 데이터 집계
- 이벤트 시간에 대한 인덱스를 생성하여 풀스캔을 피한다 (카산드라에서는 시계열 인덱스에 대응하는 데이터베이스를 이용하면 처음부터 이벤트 시간으로 인덱스된 테이블을 만들 수 있다)
- 장기간에 걸쳐서 대량의 데이터를 수집할 경우 집계 효율이 좋은 열 지향 스토리지를 사용해야 한다 (칼럼 단위로 통계정보를 통해 최적화가 이루어진다)
- 이벤트 발생 시간으로 테이블을 분할하는 방법도 있다
