3.1 프로메테우스 바이너리 구성
클라우드 네이티브 구현을 위한 핵심 소프트웨어는 쿠버네티스 => 프로메테우스를 통해 운영 및 관리
프로메테우스의 기능
- 메트릭 모니터링
- 익스포터
- 오토스케일링 설정
- 시계열 데이터베이스
- 서비스 모니터를 사용한 서비스 디스커버리
- 알람
ref: 모니터링의 새로운 미래 관측 가능성
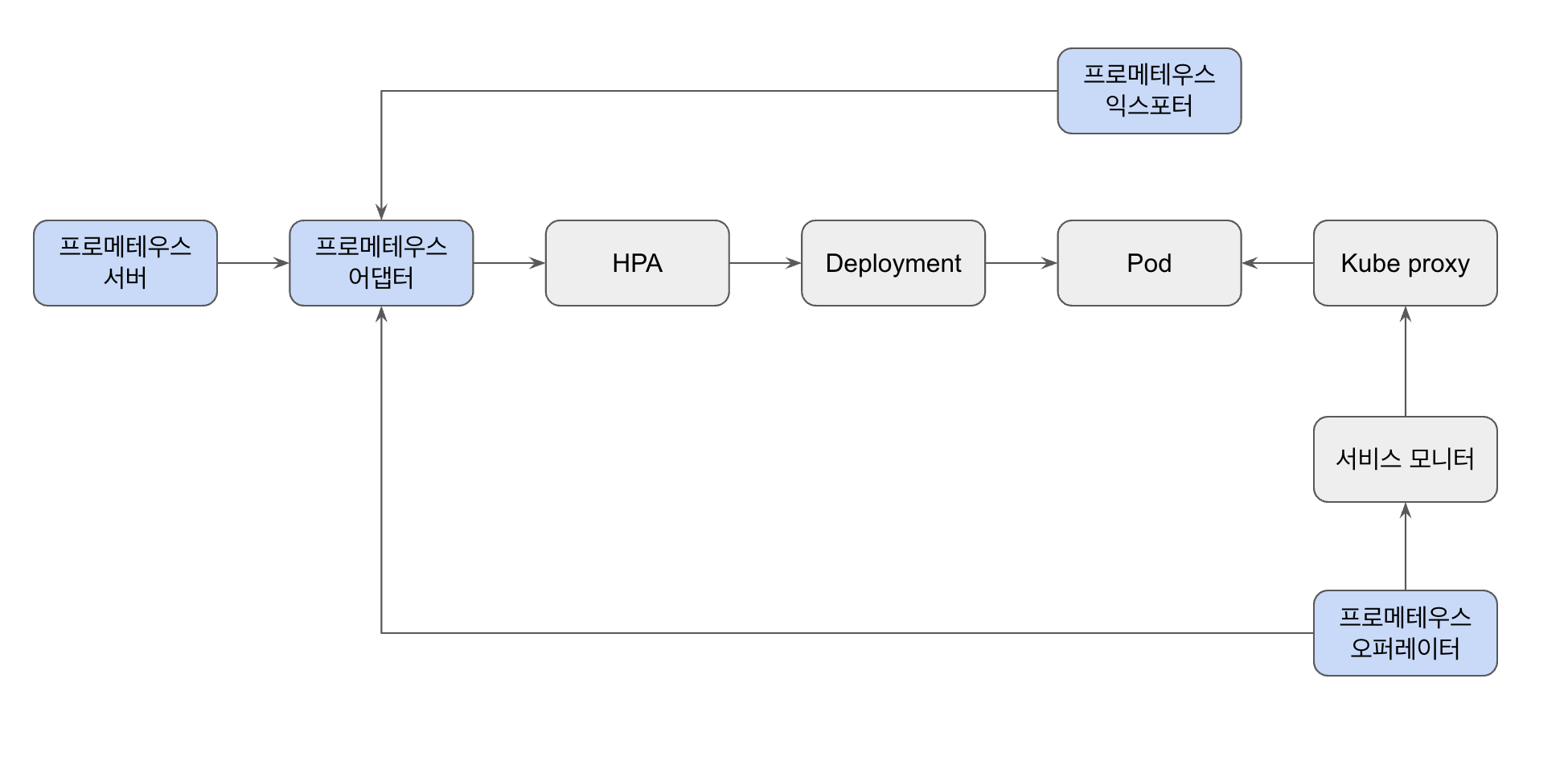
파드에서 익스포터를 통해 서비스 지표를 프로메테우스에 보내주고, (프로메테우스 익스포터)
해당 지표를 통해 오토스케일링을 파드를 증가시키고, (프로메테우스 어댑터)
오퍼레이터 내 서비스모니터, 파드모니터를 통해 서비스 디스커버리 기능을 제공한다 (프로메테우스 오퍼레이터)
쿠버네티스는 어플리케이션을 포함한 컨테이너를 운영하고 스케쥴링하는 것이라면, 프로메테우스는, 쿠버네티스 기반의 어플리케이션이 원활하게 돌아가도록 다양하고 복잡한 역할을 수행한다
프로메테우스 라이프사이클
- 메트릭을 수집하고 시계열로 저장한다
- 메트릭을 측정하고 리소스를 오토스케일링 처리한다
- 변경된 리소스를 자동으로 디스커버리한다
- HPA와 연계해 증가한 리소스로 유저 트래픽을 분배한다
TODO) 프로메테우스 설치 및 서비스 등록까지 해볼 것!
3.2 프로메테우스 시계열 데이터베이스
프로메테우스 데이터는 다음과 같은 구조를 띈다.

ref: https://jjon.tistory.com/entry/prometheus-%EB%8D%B0%EC%9D%B4%ED%84%B0-%EA%B5%AC%EC%A1%B0
- 첫 번째 요소: 메트릭 이름
- 두 번째 요소: 레이블 (커스터마이징 가능)
- 세 번째 요소: 타임스탬프
- 네 번째 요소: 값
TSDB(Time Series Database)
장점
- 데이터 압축과 효율적인 저장
- 오랜된 데이터를 쉽게 삭제할 수도 있다
- 시간 기반 최적화되어있다
- 실시간 변화 추적에 용이하다
- 높은 쓰기 성능 (대용량 데이터를 빠르게 쓸 수 있다)
단점
- 시간 기반 쿼리에 최적화되어 있기 때문에, 복잡한 쿼리(JOIN 등)이 불가능하다
- 주로 시간과 값의 쌍으로 구성되어 데이터 모델링에 한계가 있다
카디널리티와 상관관계
프로메테우스 서버는 특정 칼럼에 대한 인덱싱을 통해 스크래핑을 하게 되는데 이때 높은 카디널리티일 경우 처리해야 될 데이터가 무수히 많아져서 성능 이슈로 이어진다
=> 이때는 로그 기반 시스템에서 처리하는 것을 권장
3.2.2 데이터 관리
프로메테우스 시계열 데이터베이스는
- LRU 알고리즘을 사용한다
- 오래된 페이지를 삭제하는 알고리즘
- 메모리 페이징을 사용한다
- 샘플(청크)을 수집하고 블록 형태로 만들어 디스크에 저장한다
- 무수히 많은 청크, 메타 데이터, 인덱스 = 블록
- 인덱스를 통해 데이터를 빠르게 조회 가능하다
- 데이터 세트 = 데이터 그룹
- 데이터 포인트 = 대시보드 내 시계열로 출력되는 개별 데이터
root@bakery:/home/ubuntu/prometheus$ tree
.
...
├── 01E24YV8YFHGSES1WJ92FYMG6K -> 블록
│ ├── chunks
│ │ └── 000001 -> 블록 Chunk 파일
│ ├── index -> 색인을 위한 index 파일
│ ├── meta.json -> 메타데이터
│ └── tombstones -> 삭제 여부를 나타내는 파일
├── 01E24YX3HF1GTZ4CPF24XZ3MKR
│ ├── chunks
│ │ └── 000001
│ ├── index
│ ├── meta.json
│ └── tombstones
├── lock -> lock 파일 (여러 개의 프로메테우스 실행 방지)
├── queries.active -> 현재 실행 중인 쿼리를 저장. 쿼리 중 crash 시 확인 용도로 쓰임.
└── wal -> WAL (write ahead logging) 파일
├── 00006966 -> 개별 WAL 파일들
├── 00006967
├── 00006968
├── 00006969
├── 00006970
└── checkpoint.006965 -> 복구를 위한 체크포인트 지점
└── 00000000
16 directories, 36 filesref: https://blog.naver.com/PostView.nhn?blogId=alice_k106&logNo=221829384846
WAL 파일: 아직 청크로 플러시되지 않은 데이터에 대한 로그 선행 기입(write ahead logging, WAL)
프로메테우스는 메모리에 우선 저장하고, 주기적으로 플러시해서 디스크에 청크를 생성한다. 청크를 생성하기 전에 메모리에 있는 데이터를 백업하는 용도로 WAL을 생성하고, 프로메테우스 장애 발생시 WAL 을 사용해 장애 발생시 복구할 수 있도록 설계되어있다.
3.2.3 블록 관리
샘플
- 시계열 데이터로, 수집된 데이터 포인트로 시계열의 수치를 나타낸다.
- 샘플을 정의하는데 필요한 구성요소는 float64 값과 타임스태프다.
- 여러 개의 블록들이 병합되어서 더 큰 블록을 만든다
- 이때 물리적 저장소를 효율적으로 사용하고 조회속도를 향상시키기 위해 블록 크기와 저장 개수를 신중히 설정해야한다
블록 생성
- 일정한 시간 간격을 두고 수집한다
- 메모리에 수집된 샘플은 기본 두 시간 단위로 디스크로 플러시되고 블록이 생성된다
블록 병합
- 크기가 작은 파일과 데이터가 다수 존재하면 모든 파일에 대한 인덱스를 만들고 검색해야 하므로 조회속도가 느려진다
- 크기가 너무 크면 효율성이 떨어진다
storage.tsdb.min-block-duration,storage.tsdb.max-block-duration를 적절히 조절하여 효율적으로 블록들이 병합할 수 있도록 한다storage.tsdb.min-block-duration=2라면 한 블록 당 저장된 시간이 2시간이다storage.tsdb.max-block-duration=12라면 한 블록 당 최대로 저장될 수 있는 시간이 12시간이다- 레벨 1 블록(2h) 3개가 합쳐지면 레벨 2 블록(6h)가 만들어질 수 있다
- 그러나 레벨 2 블록(6h) 3개가 합쳐지면 18h 이므로 최대치를 넘었기에 병합될 수 없다
데이터 흐름
메모리 -> 로그 선행 기입 -> 디스크
- 메모리
- 최신 데이터 배치는 최대 두 시간 동안 메모리에 보관한다
- 메모리 상에서 하나 이상의 청크를 만든다
- 이를 통해 무분별한 디스크 쓰기를 방지한다
- 로그 선행 기법
- 프로세스가 비정상적으로 종료하면 메모리에 있는 데이터가 손실될 수 있기 때문에 WAL 을 사용한다
- 디스크
- 두 시간이 지나면 청크가 디스크에 기록된다
- LRU 알고리즘에 의해 메모리에서 디스크로 이동한다
- 디스크의 청크는 메모리와 동일하게 일대일로 대응된다
- promQL 쿼리는 우선적으로 메모리에서 작업을 처리한다
- 메모리 상에 원하는 청크가 없다면 디스크 청크를 메모리로 로드한 후 작업을 처리한다
- 데이터 삭제 시 삭제 표시 파일이 생성된다
- 디스크에 없고 메모리에만 있을 시 장애 발생으로 손실될 수 있기 때문에 체크포인트를 생성한다
3.3 프로메테우스 쿠버네티스 구성
minikube 를 이용해서 프로메테우스 구성하는 방법
Minikube 설치
> brew install minikube
// docker 서비스를 활성화한 후
> minikube start
프로메테우스 설치
프로메테우스 설치
> git clone https://github.com/prometheus-operator/kube-prometheus.git
> cd kube-prometheus
> kubectl create -f manifests/setup
> kubectl create -f manifests
> k get crd -n monitoring
NAME CREATED AT
alertmanagerconfigs.monitoring.coreos.com 2024-02-25T01:28:46Z
alertmanagers.monitoring.coreos.com 2024-02-25T01:28:46Z
podmonitors.monitoring.coreos.com 2024-02-25T01:28:47Z
probes.monitoring.coreos.com 2024-02-25T01:28:47Z
prometheusagents.monitoring.coreos.com 2024-02-25T01:28:47Z
prometheuses.monitoring.coreos.com 2024-02-25T01:28:47Z
prometheusrules.monitoring.coreos.com 2024-02-25T01:28:47Z
scrapeconfigs.monitoring.coreos.com 2024-02-25T01:28:47Z
servicemonitors.monitoring.coreos.com 2024-02-25T01:28:47Z
thanosrulers.monitoring.coreos.com 2024-02-25T01:28:47Z
포드 포워딩
k9s 를 사용해 포드 포워딩한다
프로메테우스 접속
3.4 프로메테우스 오퍼레이터
서비스 모니터를 다수 생성해서 멀티 클러스터 등의 복잡한 런타임 환경에 대응하도록 구성할 수 있다. 즉, 쿠버네티스가 클라우드 네이티브를 위한 동적인 런타임 환경이라면, 프로메테우스는 자주 변경되는 쿠버네티스 리소스를 쉽게 탐색할 수 있어야 하는데 이를 프로메테우스 오퍼레이터를 사용하면 쉽게 구현할 수 있다.
타깃 정보는 프로메테우스 config 파일에서 관리한다. 그러나 타깃이 변경될 떄 config 를 수동으로 변경하면 실수할 가능성이 있다. 이 때문에 타깃이 변경되면 서비스 모니터/파드 모니터를 담당하는 오퍼레이터에서 자동으로 이를 추적할 수 있도록 한다.
서비스 모니터
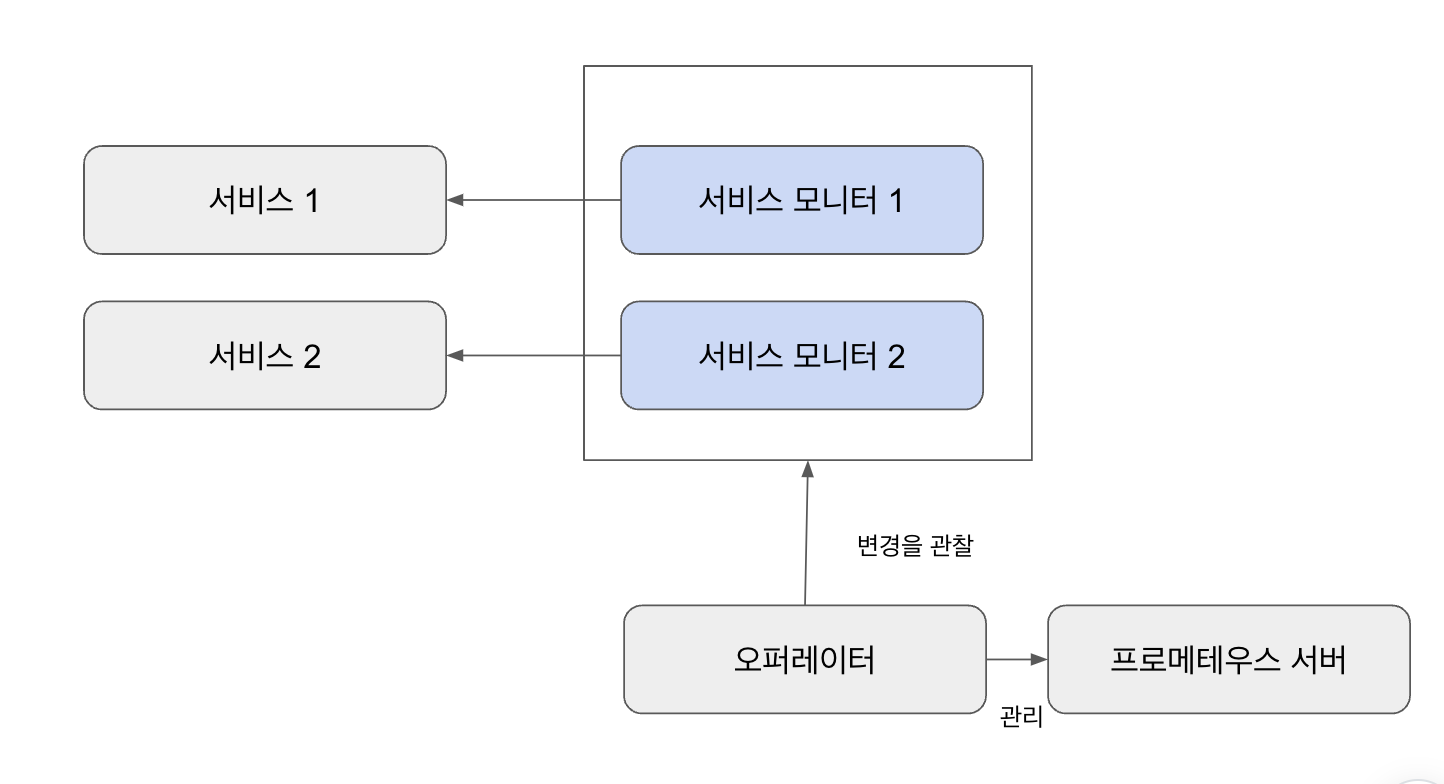
쿠버네티스의 서비스는 레이블 셀렉터로 파드를 발견하고 이를 IP 주소 목록으로 엔드포인트에 추가한다. 프로메테우스 오퍼레이터 서비스 모니터는 차례로 해당 엔트포인트를 검색하고 파드를 모니터링 하도록 프로메테우스를 구성한다. 다음은 오퍼레이터에서 기본적으로 설치한 서비스 모니터이다.
> k get servicemonitor -n monitoring
NAME AGE
alertmanager-main 20m
blackbox-exporter 20m
coredns 20m
grafana 20m
kube-apiserver 20m
kube-controller-manager 20m
kube-scheduler 20m
kube-state-metrics 20m
kubelet 20m
node-exporter 20m
prometheus-adapter 20m
prometheus-k8s 20m
prometheus-operator 20m기본적으로 검색된 엔드포인트는 메타데이터와 레이블을 저장하고 있다.
이제 sample-app 을 만들고 서비스가 어떻게 등록되는지 확인해보자
sample-app
- deployment
apiVersion: apps/v1
kind: Deployment
metadata:
name: sample-app
labels:
app: sample-app
spec:
replicas: 1
selector:
matchLabels:
app: sample-app
template:
metadata:
labels:
app: sample-app
spec:
containers:
- image: luxas/autoscale-demo:v0.1.2
name: metrics-provider
ports:
- name: http
containerPort: 8080 - service
apiVersion: v1
kind: Service
metadata:
name: sample-app
labels:
app: sample-app
spec:
ports:
- name: http
port: 80
protocol: TCP
targetPort: 8080
selector:
app: sample-app
type: ClusterIP- service monitor
kind: ServiceMonitor
apiVersion: monitoring.coreos.com/v1
metadata:
name: sample-app
labels:
app: sample-app
spec:
selector:
matchLabels:
app: sample-app
endpoints:
- port: http위 리소스를 생성한 후 프로메테우스에서 서비스가 등록되었는지 확인해보자
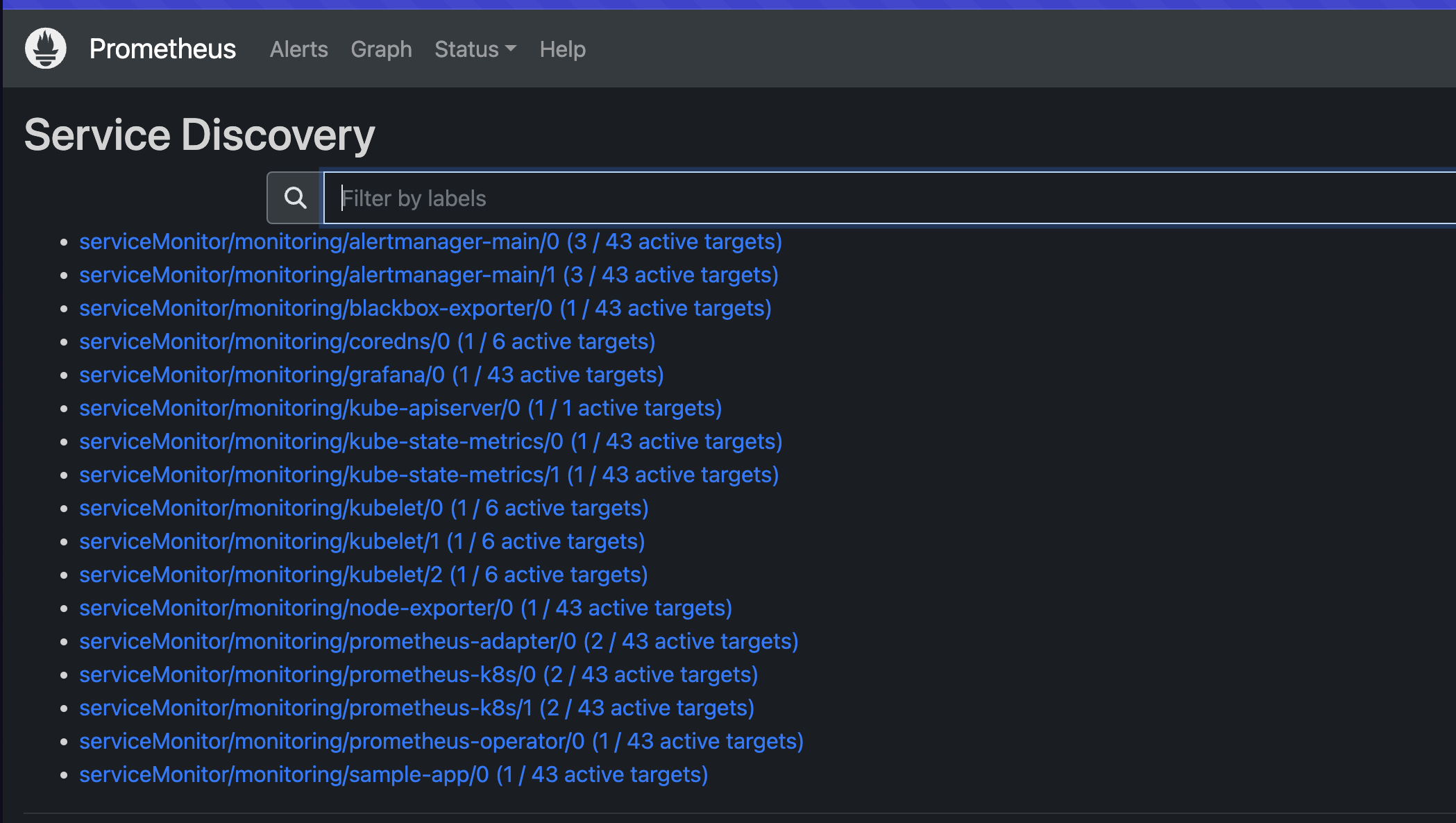
1. 서비스 디스커버리
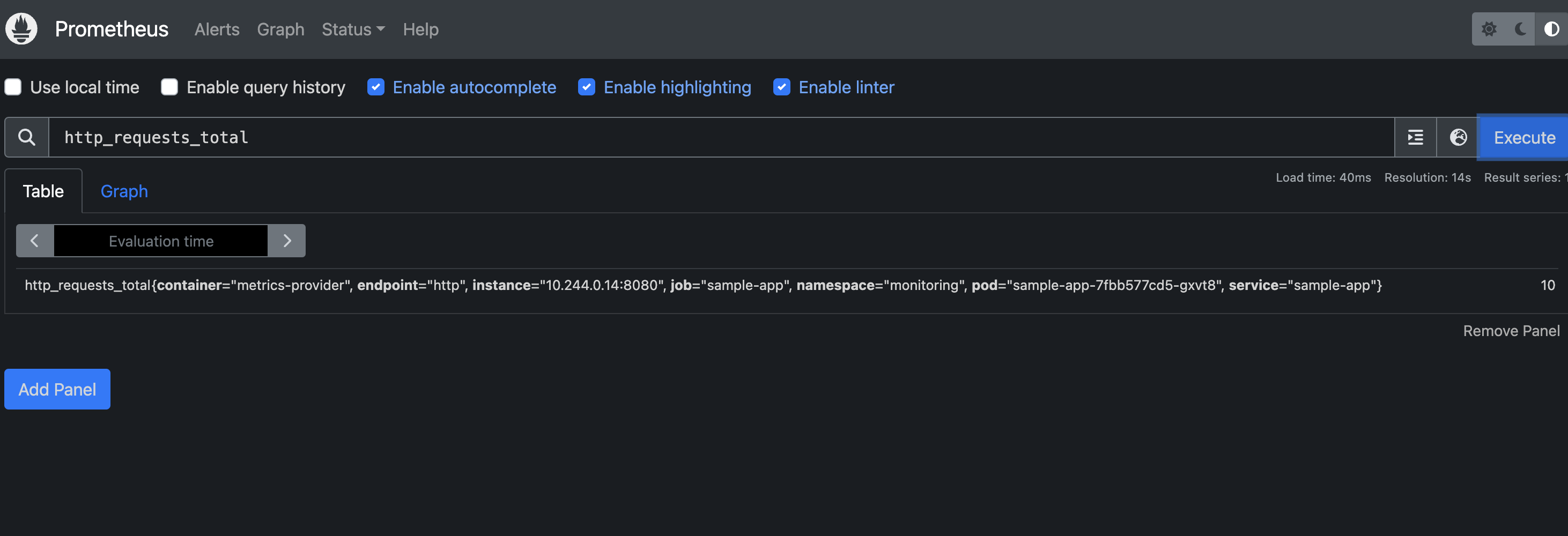
2. 메트릭 확인
3.5 프로메테우스 오토스케일링
3.5.1 프로메테우스
helm chart reference: https://github.com/philllipjung/o11ybook/tree/main/3.5
이전에 사용했던 환경을 제거한 후 다시 태초마을 상태부터 시작한다
> minikube stop
> minikube delete
> minikube start
> k create namespace monitoring이후 위에 언급한 레퍼런스로부터 헬름차트를 이용해 프로메테우스 설치한다
> helm install prom .
NAME: prom
LAST DEPLOYED: Sun Feb 25 11:19:43 2024
NAMESPACE: monitoring
STATUS: deployed
REVISION: 1
TEST SUITE: Noneinstall prom .
# 만약 다음과 같이 Install Error 가 발생하면 helm dependency build 를 실행한 후 다시 시도한다
Error: INSTALLATION FAILED: An error occurred while checking for chart dependencies. You may need to run `helm dependency build` to fetch missing dependencies: found in Chart.yaml, but missing in charts/ directory: kube-state-metrics
> helm dependency build어댑터는 discovery 규칙을 통해 노출할 메트릭과 이를 노출하는 방법을 결정한다. 각 규칙은 독립적으로 실행되며, 어댑터가 API 에서 메트릭을 노출하기 위해 수행해야 하는 각 단계를 지정한다.
- discovery 는 어댑터가 이 규칙에 대한 모든 프로메테우스 메트릭을 찾는 방법을 지정한다. 즉, 사용자 지정 메트릭 API 에서 노출하려는 메트릭을 찾는 프로세스를 관리한다.
- series: 프로메테우스 시리즈는 메트릭 이름을 의미한다
- seriesQuery:
- seriesFilters: seriesQuery 에서 시리즈 목록이 반환되면 필터링하여 최종 결과물 반환한다
seriesQuery: '{__name__=~"^container_.total",containrt!="POD",namespace!="",pod!=""}' seriesFilters: - isNot:"^continer_."_seconds_total" - association 은 어댑터가 특정 메트릭이 연결된 쿠버네티스 리소스를 결정하는 방법을 지정한다
- naming 은 어댑터가 사용자 정의 메트릭 API 에서 메트릭을 노출하는 방법을 지정한다.
name: matches: *^(.*)_total$" as: "${1}_per_second" - querying 은 하나 이상의 쿠버네티스 개체의 특정 메트릭에 대한 요청을 프로메테우스의 쿼리로 변환하는 방법을 지정한다
- metricQuery: 특정 메트릭에 대한 값을 실제로 가져오는 프로세스에서 사용하는 필드로서 다음 필드를 포함하고 있다
- Series: 메트릭 이름
- LabelMatchers: 주어진 객체와 일치한 레이블 matchers 에서 쉼표로 구분된 목록
- GroupBy: LabelMatchers 에서 사용되는 group 리소스 레이블을 포함
metricsQuery: "sum(rate(<<.Series>>{<<.LabelMatchers>>,container!="POD"}[2m])) by (<<.GroupBy>>) - metricQuery: 특정 메트릭에 대한 값을 실제로 가져오는 프로세스에서 사용하는 필드로서 다음 필드를 포함하고 있다
sample-app
apiVersion: apps/v1
kind: Deployment
metadata:
name: autoscaling-deploy
namespace: custom-metrics
spec:
replicas: 1
template:
metadata:
labels:
app: autoscaling
release: prom
spec:
containers:
- name: autoscaling
image: quay.io/brancz/prometheus-example-app
ports:
- containerPort: 8080
selector:
matchLabels:
app: autoscaling
release: prom
=> 위 리소스를 생성한 후 해당 어플리케이션에 부하를 주어 http_requests_total 를 증가시키면 프로메테우스 어댑터에서 해당 지표를 보고 hpa 를 통해 파드를 증가시킨다
(내 컴퓨터는 arm 이고 위에서 제공하는 이미지는 x86 아키텍쳐라 실행이 되지 않음 ㅠㅠ)
3.6 프로메테우스 알람
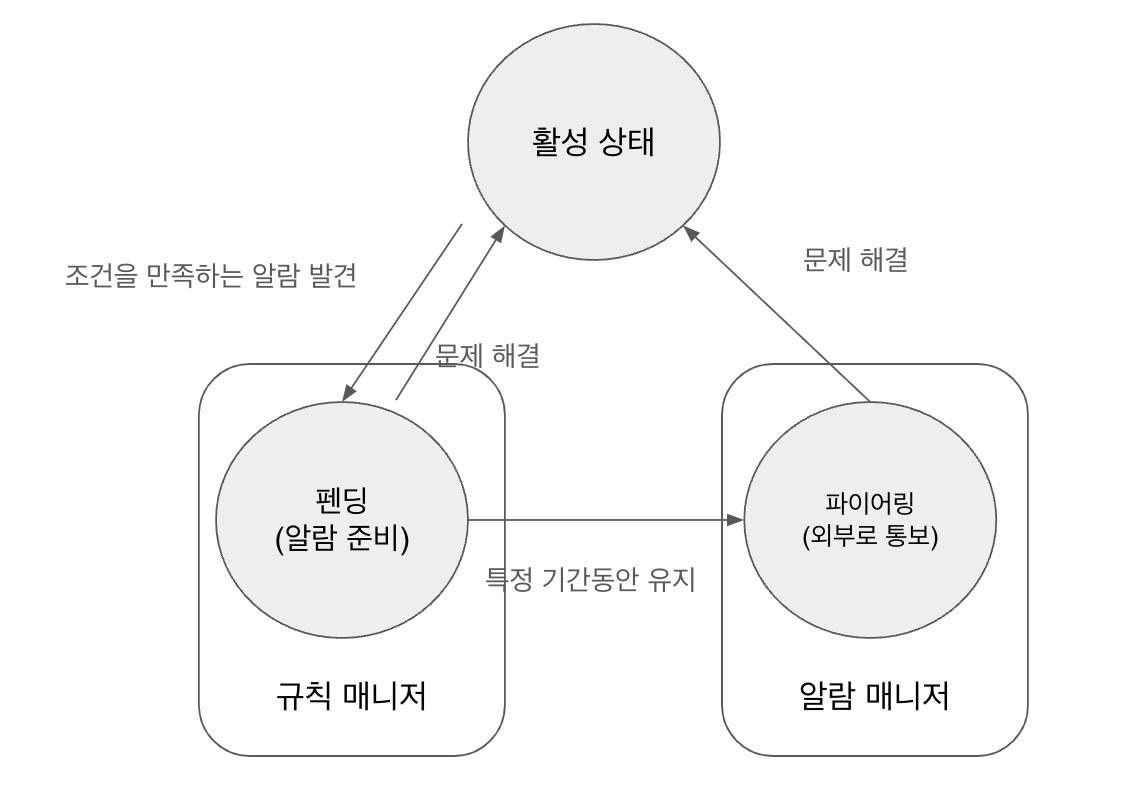
1. 알람 규칙을 작성하면
2. 규칙매니저에서 주기적으로 규칙에 따라 평가한다. 만약 특정 기간동안 실패한다면
3. 알람 매니저를 통해 외부로 통보한다
해당 알람은 프로메테우스 Alert 에서 확인 가능하다
이후 미미르 또는 로키에서 데이터소스에 프로메테우스를 연결하여 메트릭에 기반한 알람을 생성할 수도 있다
3.7 프로메테우스 운영 아키텍처
프로메테우스 구성을 위한 기보넉인 가이드라인은 높은 카디널리티 메트릭 생성을 지양하고, 샤딩을 구성하는 것이다. 샤딩을 구성하는 방법은 수직 샤딩과 수평 샤딩이 있다.
- 수직 샤딩: 프로메테우스 서버가 기준
- 수평 샤딩: 샤드를 기준
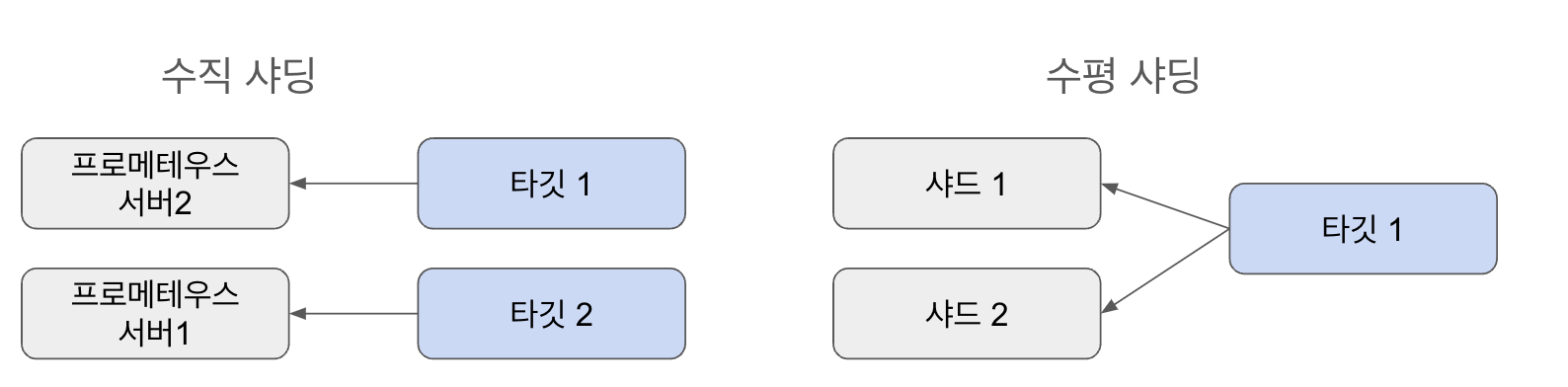
수직 샤딩
단일 프로메테우스 인스턴스만으로는 충분하지 않을 때 스케일링을 위한 좋은 출발점은 스크래핑 작업을 논리 크룹으로 분할한 후, 그룹을 다른 프로메테우스 인스턴스에 할당하는 것이다
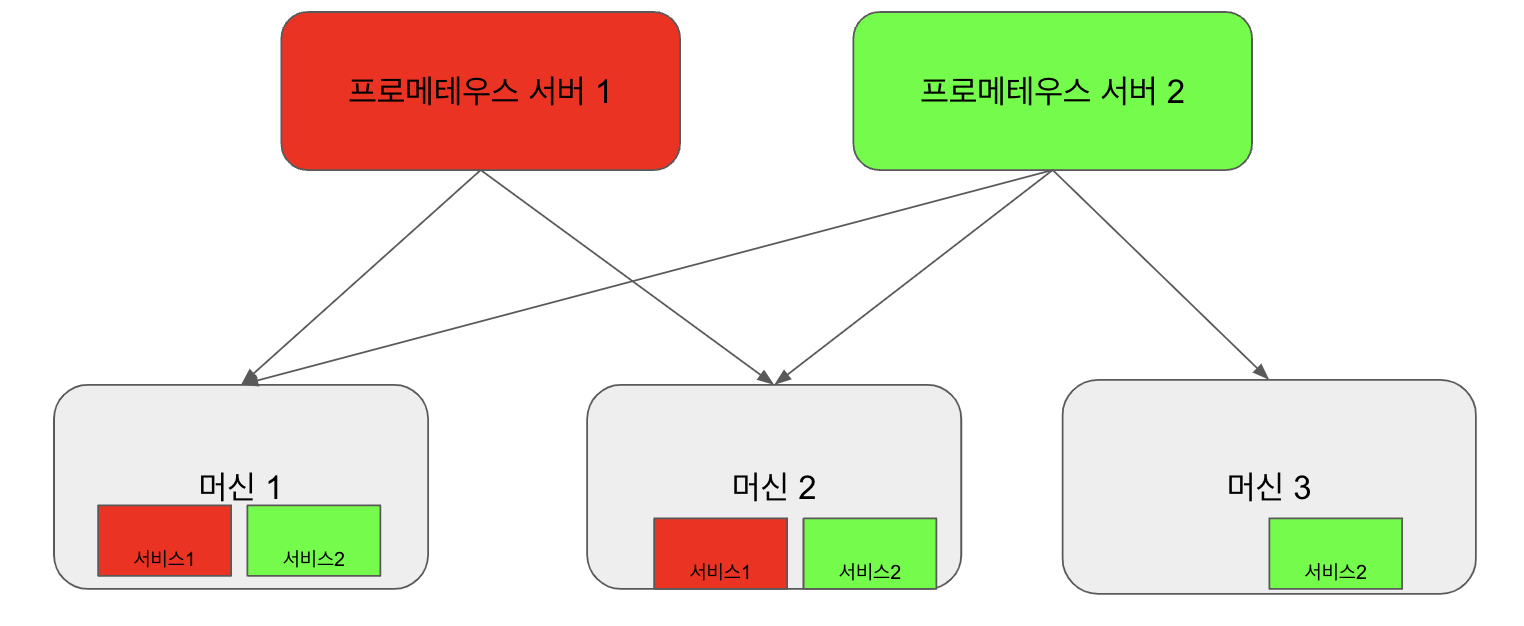
- 프로메테우스 서버 1은 다양한 머신에 분산된 서비스 1에 대해 스크래핑한다
- 프로메테우스 서버 2는 다양한 머신에 분산된 서비스 2에 대해 스크래핑한다
수평 샤딩
하나의 프로메테우스 서버가 여러 인스턴스를 갖는 것을 의미하며, 각 인스턴스는 주어진 작업에 대한 타깃 하위 세트를 스크래핑한다. 즉, 하나의 프로메테우스 서버를 여러 개로 분산하여 수평으로 분할한다.
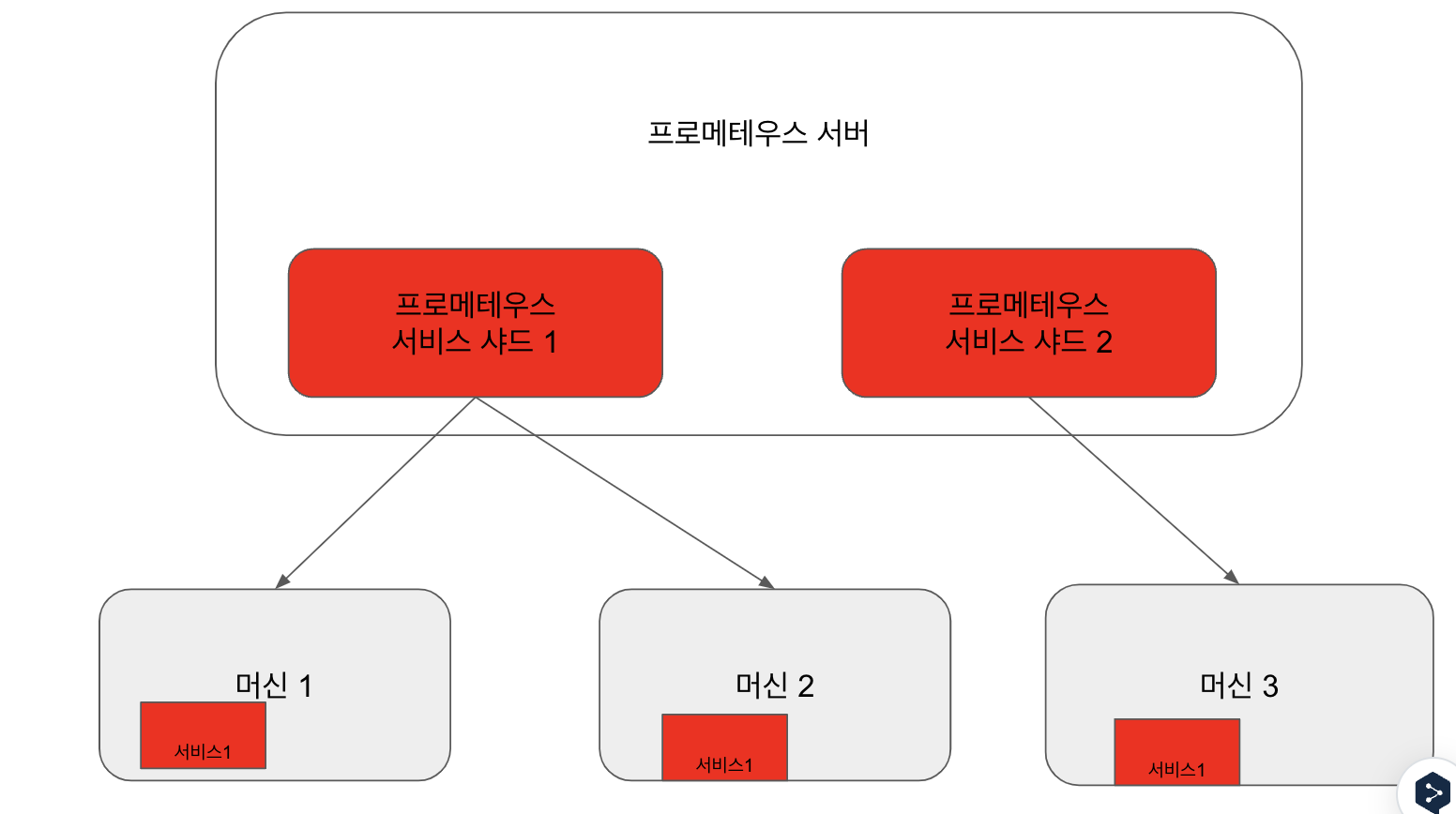
3.7.2 페더레이션 아키텍쳐
각 서비스를 스크래핑하는 하위 프로메테우스 서버로부터 프로메테우스 글로벌 서버가 집계한다
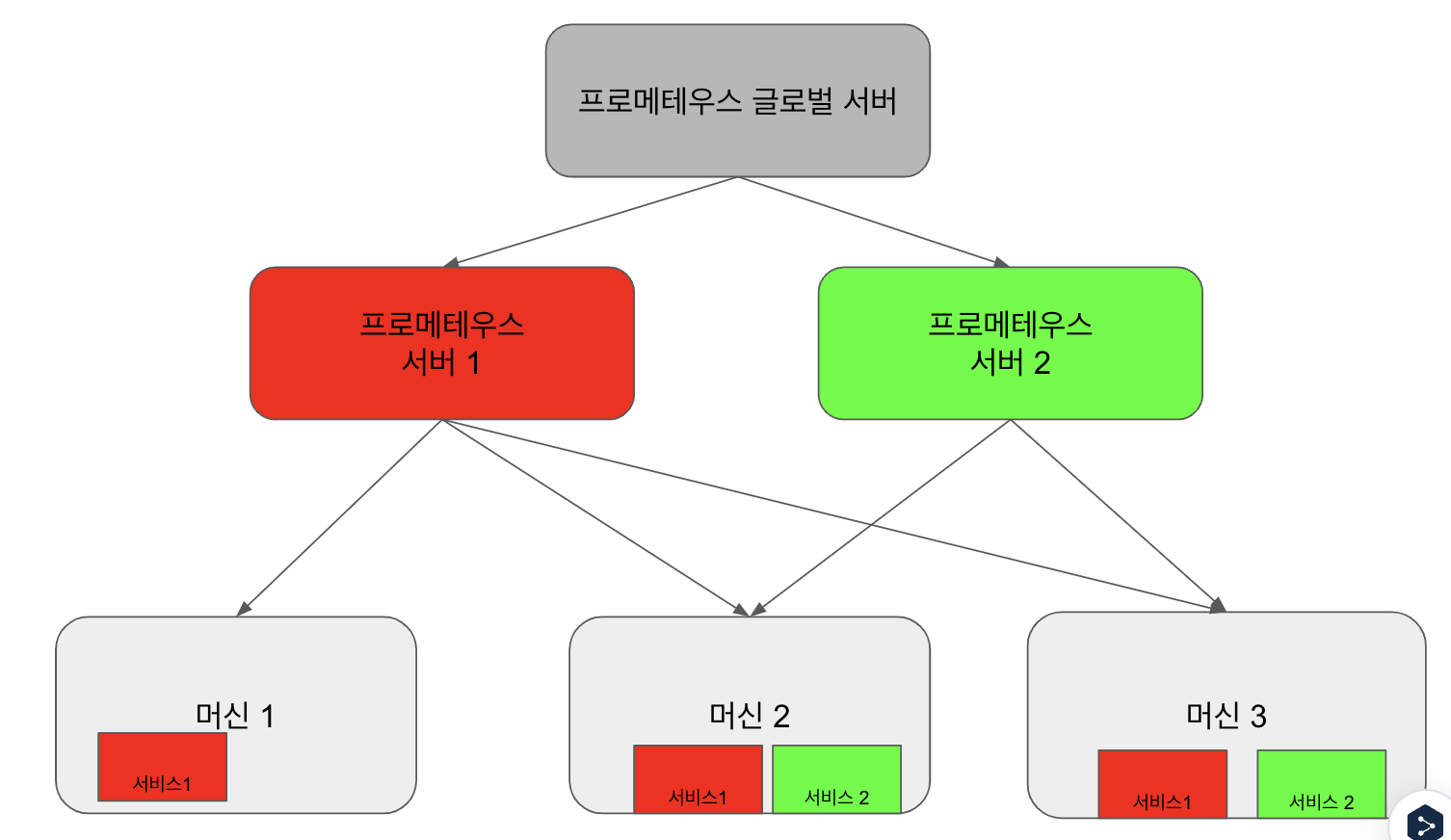
그러나 페더레이션 아키텍쳐는 다음과 같은 단점이 있다.
- 각 스크래핑으로부터 많은 데이터를 가져와 그것을 소비하는 상위 및 하위 프로메테우스 서버에 부하가 끼칠 수 있다
- 페더레이션은 해시 알고리즘을 사용해서 균등하게 분배하지 않는다. 따라서 스크래핑 처리는 격리되지 않으므로 타겟팅되는 프로메테우스 인스턴스는 경쟁으로 인해 시계열의 불완전한 스냅샷이 나타날 수 있다 (순서가 뒤섞인다던가 등)
3.8 타노스 운영
다수의 프로메테우스를 관리할 경우 유지관리가 어려울 수 있다. 이를 해결하기 위해 타노스가 해결책이 될 수 있다
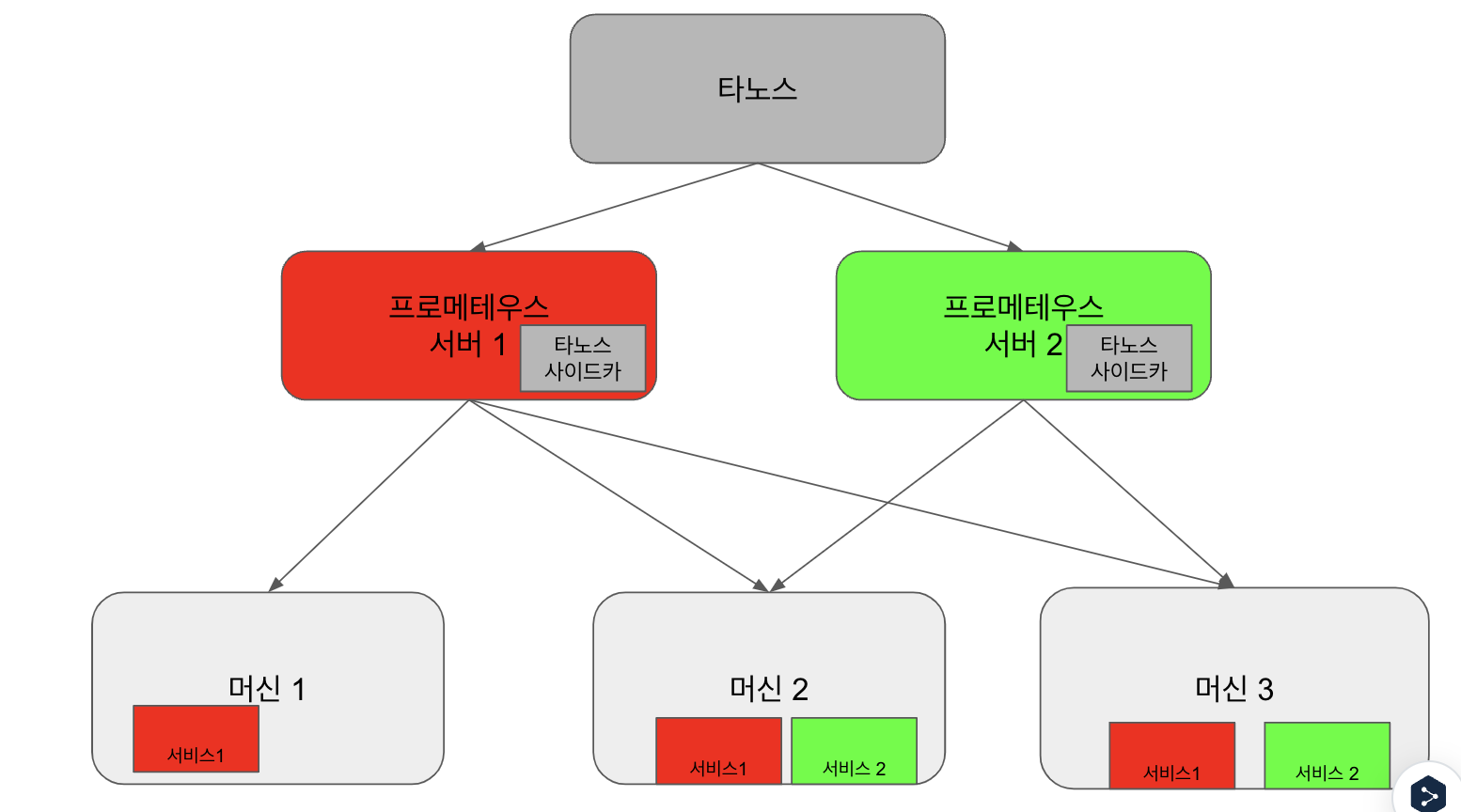
프로메테우스는 클러스터링을 지원하지 않고, 로컬스토리지를 사용하기 때문에 대용향 데이터를 스토리지 확장하기 어렵고 장기관 보관하기에 한계가 있다. 타노스를 도입하면 다음과 같은 장점이 있다.
-글로벌 뷰: 반환된 시계열을 집계하고 중복을 제거하면서 동일한 위치에서 모든 프로메테우스 인스턴스를 쿼리한다
- 다운 샘플링: 장기간 보관된 데이터를 쿼리할 때 전체 해상도로 나오는 샘플을 다운샘플링하여 가져온다
- 규칙: 프로메테우스 샤드의 메트릭을 혼합하는 글로벌 알람 규칙 등을 생성할 수 있다
- 장기 보관: 객체 스토리지를 활용해 스토리지의 내구성 및 확장에 용이하다.
사이드카 아키텍쳐
타노스 아키텍쳐는 사이드카 방식과 리시버 방식이 있지만 '모니터링에 새로운 미래 관측 가능성' 책에서는 사이드카 방식을 주로 설명하고 있다.
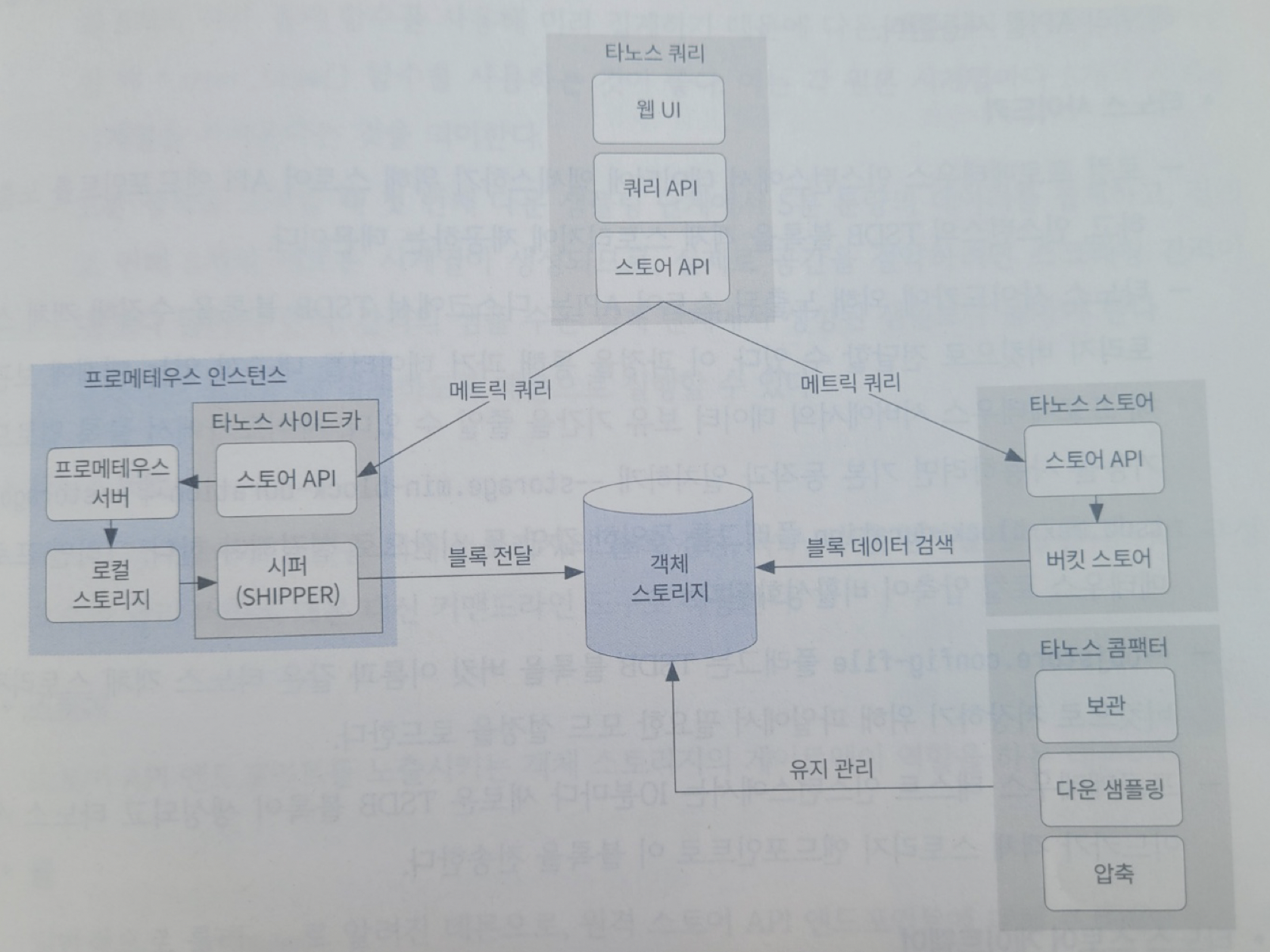
ref: 모니터링에 새로운 미래 관측 가능성 p179
타노스 사이드카 아키텍쳐에서는 원격 읽기 방식(pull 방식)을 사용하며, 스토어 API 를 통해 메트릭을 쿼리한다.
- 쓰기
1. 타노스 쿼리에서 스토어 API 를 통해 메트릭 쿼리를 날린다.- 프로메테우스 인스턴스 내 타노스 사이드카에서 프로메테우스 서버 로컬 스토리지에 있는 데이터를 시퍼(shipper)를 통해 객체 스토리지에 보낸다
- 읽기
1. 타노스 쿼리에서 스토어 API 를 통해 메트릭 쿼리를 날린다.- 타노스 스토어의 버킷 스토어를 통해 객체 스토리지에 접근하여 데이터 블록 검증, 복구, 나열, 검사한다.
- 타노스 콤팩터
1. 보관, 다운 샘플링, 압축을 통해 장기관 데이터를 효율적으로 관리한다.
리시버 아키텍쳐
원격 읽기 방식은 pull 방식을 사용하고 있는데 이러한 방식은 방화벽 등 보안 이슈가 발생하고, 사이드카를 주입해야 하다보니 확장할 때 추가적인 리소스 비용이 발생한다. 이를 해결하기 위해 현재 타노스 아키텍쳐는 원격 쓰기 방식(push 방식)을 사용하는 리시버 방식을 채택했다고 한다.
