9. 데이터 파이프라인 구축하기
데이터 파이프라인에서 Apache Kafka의 핵심 역할은 단계 사이에 놓이는 크고 안정적인 버퍼로서, 쓰는 쪽과 읽는 쪽을 느슨하게 결합시키는 데 있다. 이를 통해 하나의 원본 데이터로부터 서로 다른 적시성(timeliness)과 가용성 요구를 가진 여러 대상 시스템으로 안전하게 데이터를 전달할 수 있다. 파이프라인의 양쪽을 분리하면 신뢰성과 보안성, 운영 효율이 함께 높아진다.
9.1 데이터 파이프라인 구축 시 고려 사항
9.1.1 적시성
파이프라인마다 “얼마나 빨리 데이터가 필요하냐”가 다르다. Kafka는 쓰기와 읽기를 시간적으로 분리해, 컨슈머가 자신의 속도에 맞춰 처리한다. 필요하면 프로듀서의 응답을 조절해 백프레셔(속도 조절)도 간단히 적용할 수 있다.
백프레셔란?
컨슈머가 프로듀서의 생산 속도를 따라가지 못해 큐가 가득차는 이슈를 의미한다. 보통 이럴 때는 프로듀서의 생산을 억제하거나 제어한다.
9.1.2 신뢰성
장애가 나도 빨리 자동으로 복구되어야 한다. 그리고 “전달 보장”이 중요합니다.
- 최소 한 번(at-least-once): 원본에서 나온 이벤트가 최소 한 번은 목적지에 도착.
- 정확히 한 번(exactly-once): 중복 없이 딱 한 번만 전달.
Kafka는 기본적으로 최소 한 번을 보장한다. 외부 저장소의 트랜잭션/고유 키와 같이 쓰면 정확히 한 번도 구현할 수 있다. Kafka Connect API는 위와 같이 전달 보장하며 오프셋 관리·외부 시스템 연동을 지원해 커넥터 개발을 쉽게 해준다.
9.1.3 높고 조정 가능한 처리율
처리율 급증에도 적응할 수 있어야 한다. Kafka가 쓰기·읽기 사이에서 버퍼 역할을 하므로, 프로듀서와 컨슈머 처리율을 강제로 맞출 필요가 없다. 프로듀서가 더 빠르면 데이터가 Kafka에 누적되고, 컨슈머가 따라잡으면 된다. 복잡한 백프레셔를 직접 구현할 필요가 없고, 요구에 맞춰 프로듀서나 컨슈머를 독립적으로 확장할 수 있다.
9.1.4 데이터 형식
파이프라인에서는 서로 다른 데이터 형식과 자료형을 적절히 다루는 것이 중요하다. 시스템마다 지원 자료형이 다르다. 예를 들어 Avro 타입을 사용해 XML이나 관계형 데이터를 Kafka에 적재할 수 있다. 엘라스틱서치는 JSON, HDFS는 Parquet, S3는 CSV를 선호한다. Kafka와 Connect API는 형식에 독립적이므로 유연하게 구성 가능하다.
9.1.5 변환
데이터 파이프라인은 ETL과 ELT 두 방식으로 접근할 수 있다.
- ETL(Extract-Transform-Load): 파이프라인에서 변환을 수행해 대상에 저장한다. 변환 후 재저장이 줄어 시간·공간 절약이 가능하지만, 연산·저장 부담이 파이프라인으로 이동한다. 누군가 파이프라인에서 데이터를 삭제하면 하단 사용처에서 활용이 어려워질 수 있다.
- ELT(Extract-Load-Transform): 원본에 최대한 가까운 형태로 최소 변환만 수행한 뒤(예: 자료형 변환), 대상 시스템에서 변환을 맡긴다. 대상 시스템에 더 큰 유연성을 주지만, 변환이 대상의 CPU·자원을 사용한다.
Kafka Connect는 Single Message Transform(SMT)을 제공해 카프카로 옮기거나 카프카에서 내보낼 때 단일 레코드 단위로 변환(토픽 라우팅, 필터링, 자료형 변환, 특정 필드 삭제 등)이 가능하다. Join, Aggregation 같은 복잡한 변환은 Kafka Streams로 처리한다.
9.1.6 보안
고려해야 할 질문:
- 누가 카프카로 수집된 데이터에 접근하는가?
- 파이프라인 내 데이터는 암호화되어 있는가?
- 누가 파이프라인을 변경할 수 있는가?
- 접근 제한된 데이터에 대해 인증을 통과할 수 있는가?
- PII(개인 식별 정보) 저장·접근·사용 시 법·규제를 준수하는가?
Kafka는 전송 암호화, SASL 기반 인증·인가, 접근 로그(감사) 지원, 외부 비밀 관리(예: HashiCorp Vault)와의 통합을 제공한다.
9.1.7 장애 처리
모든 데이터가 항상 완벽하다고 가정하는 것은 위험하다. Kafka를 장기간 보존하도록 설정하면, 필요 시 과거 시점으로 되돌아가 에러를 복구할 수 있다.
9.1.8 결합(Coupling)과 민첩성(Agility)
원본과 대상을 분리하는 설계가 중요하다. 의도치 않은 결합은 다음에서 발생한다.
- 임기응변(Ad-hoc) 파이프라인: 매번 커스텀으로 연결하면 데이터 파이프라인이 특정 엔드포인트에 강하게 결합되어 설치·운영·모니터링 비용이 커진다. 또한 새로운 기술을 적용시키기에도 어려운 환경이 되어버린다.
- 메타데이터 유실: 만약 데이터 파이프라인이 스키마 메타데이터를 보존·진화시키지 않으면 양쪽 시스템이 소스 데이터를 파싱하는 방법을 알아야되고 이로 인해 소스·싱크가 강결합된다. 따라서 파이프라인에서 스키마 진화를 지원한다면 양쪽 시스템은 유연하게 적용이 가능하고 결합도 약해진다.
- 과도한 처리: 파이프라인에서 처리를 과도하게 하면 하단 시스템이 보존 필드, 집적 방식 등 선택지가 줄고, 요구 변경 시 파이프라인을 자주 수정해야 한다. 가능하면 가공되지 않은(raw) 데이터를 하단 애플리케이션으로 내려보내고(Kafka Streams 포함), 처리·집적 방식은 각 애플리케이션이 결정하도록 하여 유연성을 확보한다.
9.2 Kafka Connect vs. 프로듀서/컨슈머
카프카에 데이터를 쓰거나 읽을 때는 클라이언트(프로듀서·컨슈머) 코드를 직접 작성하는 방법과 Connect API/커넥터를 사용하는 방법이 있다. 보통 프로듀서/컨슈머는 어플리케이션이 카프카와 데이터를 주고받을 때 사용하며, Kafka Connect는 코드나 API를 바꿀 수 없는 외부 데이터 저장소와 카프카를 연결할 때 적합하다. 사용자는 주로 설정 파일만 작성하면 된다. 연결하려는 저장소용 커넥터가 없다면, 카프카 클라이언트 또는 Connect API를 사용해 애플리케이션을 직접 작성할 수 있다. Connect API를 쓰면 표준화된 관리 기능(배포·확장·모니터링 등)을 활용할 수 있어 운영이 편리하다.
9.3 카프카 커넥트
카프카 커넥트는 아파치 카프카의 일부로서, 카프카와 다른 데이터 저장소 사이에 확장성과 신뢰성을 가지면서 데이터를 주고받을 수 있는 수단을 제공한다. 커넥트는 커넥터 플러그인을 개발하고 실행하기 위한 API 와 런타임을 제공한다. 커넥터 플러그인은 카프카 커넥트가 실행시키는 라이브러리로 데이터를 이동시키는 것을 담당한다. 커넥터는 여러 워커 프로세스들의 클러스터 형태로 실행된다. 사용자는 워커에 커넥터 플러그인을 설치한 뒤 REST API를 사용해서 커넥터별 설정을 잡아 주거나 관리해주면 된다. 대량의 데이터 이동을 병렬화해서 처리하고 워커의 유휴 자원을 더 효율적으로 활용하기 위해 테스크를 추가로 실행한다. 소스 커넥터 테스크는 원본 시스템으로부터 데이터를 읽어 와서 커넥트 자료 객체의 형태로 워커 프로세스에 전달한다. 싱크 커넥트 테스크는 워커로부터 커넥트 자료 객체를 받아서 대상 시스템에 쓰는 작업을 담당한다.
9.3.1 카프카 커넥트 실행하기
카프카 커넥트는 아파치 카프카에 포함되어 배포되므로 별도로 설치할 필요가 없다. 그리고 카프카 커넥트 워커 실행방법은 브로커 실행방법과 매우 유사하다. 참고로 카프카 커넥트를 프로덕션 환경에서 사용할 경우, 카프카 브로커와는 별도의 서버에서 커넥트를 실행시켜야 한다.
bin/connect-distributed.sh config/connect-distibuted.properties커넥트 워커 핵심 설정은 다음과 같다.
| 설정 | 목적 | 예시 값 |
|---|---|---|
| bootstrap.servers | 커넥트 워커가 데이터를 주고받기 위해 연결하는 카프카 브로커 주소 | host1:9092,host2:9092 |
| group.id | 동일한 그룹 ID를 갖는 모든 워커들은 같은 커넥트 클러스터를 구성 | connect-cluster-prod |
| plugin.path | 커넥터, SMT, 컨버터 플러그인을 로드할 파일시스템 경로 | /usr/share/java,/opt/connect-plugins |
| key.converter, value.converter | 커넥트 내부 포맷과 카프카 토픽의 키/값 포맷 간 변환 | org.apache.kafka.connect.json.JsonConverter; org.apache.kafka.connect.storage.StringConverter; io.confluent.connect.avro.AvroConverter |
| rest.host.name, rest.port | 커넥트 REST API 바인드 주소와 포트(커넥터 생성/관리, 상태 조회) | rest.host.name=0.0.0.0; rest.port=8083 |
9.3.2 커넥트 예제: 파일 소스와 파일 싱크
AI 를 이용해서 작성한 예제 코드입니다.
커넥터 설정 파일
bootstrap.servers=localhost:9092
group.id=connect-cluster-demo
plugin.path=/usr/local/share/kafka/plugins,/usr/share/filestream-connectors
rest.host.name=0.0.0.0
rest.port=8083
key.converter=org.apache.kafka.connect.storage.StringConverter
value.converter=org.apache.kafka.connect.storage.StringConverter커넥트 실행 및 데이터 적재
set -euo pipefail
CONNECT_URL="http://localhost:8083"
INPUT_FILE="/tmp/test.txt"
OUTPUT_FILE="/tmp/test.sink.txt"
TOPIC="connect-test"
# 1) 입력 파일 초기 내용 작성
echo "hello kafka connect" > "$INPUT_FILE"
echo "second line" >> "$INPUT_FILE"
# 2) 소스 커넥터 생성
echo "Creating source connector..."
curl -s -X POST "${CONNECT_URL}/connectors" \
-H "Content-Type: application/json" \
-d "$(cat <<JSON
{
"name": "local-file-source",
"config": {
"connector.class": "FileStreamSource",
"tasks.max": "1",
"file": "${INPUT_FILE}",
"topic": "${TOPIC}"
}
}
JSON
)"
# 출력 예시:
# {"name":"local-file-source","config":{"connector.class":"FileStreamSource","tasks.max":"1","file":"/tmp/test.txt","topic":"connect-test"},"tasks":[],"type":"source"}
# 3) 싱크 커넥터 생성
echo "Creating sink connector..."
curl -s -X POST "${CONNECT_URL}/connectors" \
-H "Content-Type: application/json" \
-d "$(cat <<JSON
{
"name": "local-file-sink",
"config": {
"connector.class": "FileStreamSink",
"tasks.max": "1",
"file": "${OUTPUT_FILE}",
"topics": "${TOPIC}"
}
}
JSON
)"
# 출력 예시:
# {"name":"local-file-sink","config":{"connector.class":"FileStreamSink","tasks.max":"1","file":"/tmp/test.sink.txt","topics":"connect-test"},"tasks":[],"type":"sink"}
# 4) 커넥터 상태 확인
echo "Checking connector status..."
curl -s "${CONNECT_URL}/connectors/local-file-source/status"
# 출력 예시:
# {"name":"local-file-source","connector":{"state":"RUNNING","worker_id":"localhost:8083"},"tasks":[{"id":0,"state":"RUNNING","worker_id":"localhost:8083"}],"type":"source"}
curl -s "${CONNECT_URL}/connectors/local-file-sink/status"
# 출력 예시:
# {"name":"local-file-sink","connector":{"state":"RUNNING","worker_id":"localhost:8083"},"tasks":[{"id":0,"state":"RUNNING","worker_id":"localhost:8083"}],"type":"sink"}
# 5) 현재 출력 파일 내용 확인 (초기 두 줄이 써져 있어야 함)
echo "Reading current sink output..."
nl -ba "${OUTPUT_FILE}"
# 출력 예시:
# 1 hello kafka connect
# 2 second line
# 6) 추가 라인 스트리밍 테스트
echo "third line" >> "${INPUT_FILE}"
sleep 2다이어그램
[입력 파일 /tmp/test.txt]
| (추가된 라인 감시: FileStreamSource)
v
+--------------------+
| Kafka Topic | connect-test
+--------------------+
|
v (소비: FileStreamSink)
[출력 파일 /tmp/test.sink.txt]커넥터 예제: MySQL 에서 Elasticsearch 로 데이터 보내기
AI 를 이용해서 작성한 예제 코드입니다.
커넥터 설정 파일
bootstrap.servers=localhost:9092
group.id=connect-cluster-mysql-es
# 플러그인 경로: Debezium MySQL, Elasticsearch Sink 커넥터가 설치된 디렉토리들을 포함
# 예) Confluent Hub 설치 또는 수동 배치
plugin.path=/usr/local/share/kafka/plugins,/usr/share/debezium-plugins,/usr/share/elasticsearch-plugins
rest.host.name=0.0.0.0
rest.port=8083
key.converter=org.apache.kafka.connect.json.JsonConverter
key.converter.schemas.enable=true
value.converter=org.apache.kafka.connect.json.JsonConverter
value.converter.schemas.enable=true커넥트 실행 및 데이터 적재
set -euo pipefail
CONNECT_URL="http://localhost:8083"
MYSQL_HOST="localhost"
MYSQL_PORT="3306"
MYSQL_USER="debezium"
MYSQL_PASSWORD="debezium"
MYSQL_SERVER_ID="184054" # MySQL 서버 내 고유 ID (복제용)
MYSQL_SERVER_NAME="mysql01" # Debezium의 논리적 서버명 (토픽 prefix)
MYSQL_DB_INCLUDE="inventory" # 캡처할 DB (예시)
TABLE_INCLUDE="inventory.customers" # 캡처할 테이블 (예시)
ES_URL="http://localhost:9200"
# 0) MySQL 설정 가이드 (참고용)
cat <<'MYSQL_GUIDE'
-- my.cnf 주요 설정 (MySQL 5.7+ / 8.0)
[mysqld]
server-id=1
log_bin=mysql-bin
binlog_format=row
binlog_row_image=full
gtid_mode=ON
enforce_gtid_consistency=ON
-- 사용자 권한
CREATE USER 'debezium'@'%' IDENTIFIED BY 'debezium';
GRANT REPLICATION SLAVE, REPLICATION CLIENT ON *.* TO 'debezium'@'%';
GRANT SELECT ON inventory.* TO 'debezium'@'%';
FLUSH PRIVILEGES;
MYSQL_GUIDE
# 1) Debezium MySQL Source 커넥터 생성
echo "Creating Debezium MySQL source connector..."
curl -s -X POST "${CONNECT_URL}/connectors" \
-H "Content-Type: application/json" \
-d "$(cat <<JSON
{
"name": "debezium-mysql-source",
"config": {
"connector.class": "io.debezium.connector.mysql.MySqlConnector",
"tasks.max": "1",
"database.hostname": "${MYSQL_HOST}",
"database.port": "${MYSQL_PORT}",
"database.user": "${MYSQL_USER}",
"database.password": "${MYSQL_PASSWORD}",
"database.server.id": "${MYSQL_SERVER_ID}",
"database.server.name": "${MYSQL_SERVER_NAME}",
"database.include.list": "${MYSQL_DB_INCLUDE}",
"table.include.list": "${TABLE_INCLUDE}",
"include.schema.changes": "false",
"snapshot.mode": "initial", // 최초에 테이블 전체 스냅샷 후 binlog 추적
"decimal.handling.mode": "string",
"time.precision.mode": "adaptive_time_microseconds",
"tombstones.on.delete": "false", // delete 시 tombstone 억제 (필요 시 true)
"transforms": "unwrap,route",
"transforms.unwrap.type": "io.debezium.transforms.ExtractNewRecordState",
"transforms.unwrap.drop.tombstones": "true",
"transforms.unwrap.delete.handling.mode": "rewrite",
"transforms.route.type": "org.apache.kafka.connect.transforms.RegexRouter",
"transforms.route.regex": "(${MYSQL_SERVER_NAME})\\.(.*)\\.(.*)",
"transforms.route.replacement": "\$2-\$3" // 토픽명: inventory-customers 형태
}
}
JSON
)"
echo
# 예상 출력 예시:
# {"name":"debezium-mysql-source","config":{...},"tasks":[],"type":"source"}
# 2) Elasticsearch Sink 커넥터 생성
# - 토픽 inventory-customers 를 인덱스 inventory-customers 로 매핑
# - key.ignore=true 로 문서 id는 Connect가 자동 생성 (또는 PK 기반으로 key 사용하려면 false)
echo "Creating Elasticsearch sink connector..."
curl -s -X POST "${CONNECT_URL}/connectors" \
-H "Content-Type: application/json" \
-d "$(cat <<JSON
{
"name": "elasticsearch-sink",
"config": {
"connector.class": "io.confluent.connect.elasticsearch.ElasticsearchSinkConnector",
"tasks.max": "1",
"topics": "inventory-customers",
"connection.url": "${ES_URL}",
"type.name": "_doc", // ES7+에서 무시되지만 호환 위해 지정 가능
"key.ignore": "true",
"schema.ignore": "true", // ES에 스키마 없이 기록(동적 매핑)
"behavior.on.null.values": "delete", // null 값 레코드 시 삭제 동작
"max.in.flight.requests": "1", // 정확히-한-번 근사에 도움 (idempotence 유사)
"write.method": "upsert", // upsert 로 갱신
"batch.size": "2000",
"flush.timeout.ms": "60000",
"max.buffered.records": "20000",
"transforms": "rename",
"transforms.rename.type": "org.apache.kafka.connect.transforms.HoistField$Value",
"transforms.rename.field": "payload" // 이미 Debezium unwrap을 적용했으면 불필요; 예시용
}
}
JSON
)"
echo
# 예상 출력 예시:
# {"name":"elasticsearch-sink","config":{...},"tasks":[],"type":"sink"}
# 3) 상태 확인
echo "Checking connector status..."
curl -s "${CONNECT_URL}/connectors/debezium-mysql-source/status"
echo
# 출력 예시:
# {"name":"debezium-mysql-source","connector":{"state":"RUNNING",...},"tasks":[{"id":0,"state":"RUNNING",...}],"type":"source"}
curl -s "${CONNECT_URL}/connectors/elasticsearch-sink/status"
echo
# 출력 예시:
# {"name":"elasticsearch-sink","connector":{"state":"RUNNING",...},"tasks":[{"id":0,"state":"RUNNING",...}],"type":"sink"}
# 4) 테스트 안내: MySQL 데이터 변경 → ES 문서 확인
cat <<'TEST'
예시 테스트:
MySQL에서 레코드 삽입/수정/삭제:
INSERT INTO inventory.customers(id, first_name, last_name, email) VALUES (1001, 'Ada', 'Lovelace', 'ada@example.com');
UPDATE inventory.customers SET email='ada.l@ex.com' WHERE id=1001;
DELETE FROM inventory.customers WHERE id=1001;
Elasticsearch 확인:
curl -s "http://localhost:9200/inventory-customers/_search?pretty"
TEST다이어그램
[MySQL DB (binlog 활성화)]
| (CDC 캡처: Debezium MySQL Connector)
v
+---------------------------+
| Kafka Topic(s) | 예: inventory-customers
+---------------------------+
|
v (소비 및 색인: Elasticsearch Sink)
[Elasticsearch Index] inventory-customersTMI) Debezium 이란?
Debezium은 database에서 발생하는 변경사항을 추적할 수 있는 일종의 Apache Kafka Connect의 source connector 다. 각각의 connector은 해당 데이터베이스의 CDC(change data capture)와 관련된 기능을 활용해서 변경된 데이터에 대한 정보를 가져온다. 성공적으로 commit이 발생한 데이터에 대해서만 변경사항이 전파되기 때문에 실패한 트랜잭션은 고려할 필요가 없다고 한다.
기존 JDBC 커넥터의 경우 타임스탬프 필드와 자동으로 증가하는 primary key 를 이용하여 새로운 데이터인지 확인한다. 그러나 이러한 방법은 때론 부정확하고 비효율적이다. 대부분 DB 에서는 트랜잭션 로그를 남기는데 Debezium 은 이러한 로그를 살피고 변경을 탐지한다. 그렇기 때문에 기존 JDBC 보다 더 효율적이고 정확하다.
위 코드를 살펴보면 "connector.class": "io.debezium.connector.mysql.MySqlConnector" 와 같이 설정하여 Debezium 소스 커넥터를 사용한 것을 확인할 수 있다.
TMI) 카카오 클라우드 Kafka 기반 실시간 데이터 파이프라인
카프카 커넥트 관련해서 구글링해보니 다음과 같은 튜토리얼 문서도 발견할 수 있었다.
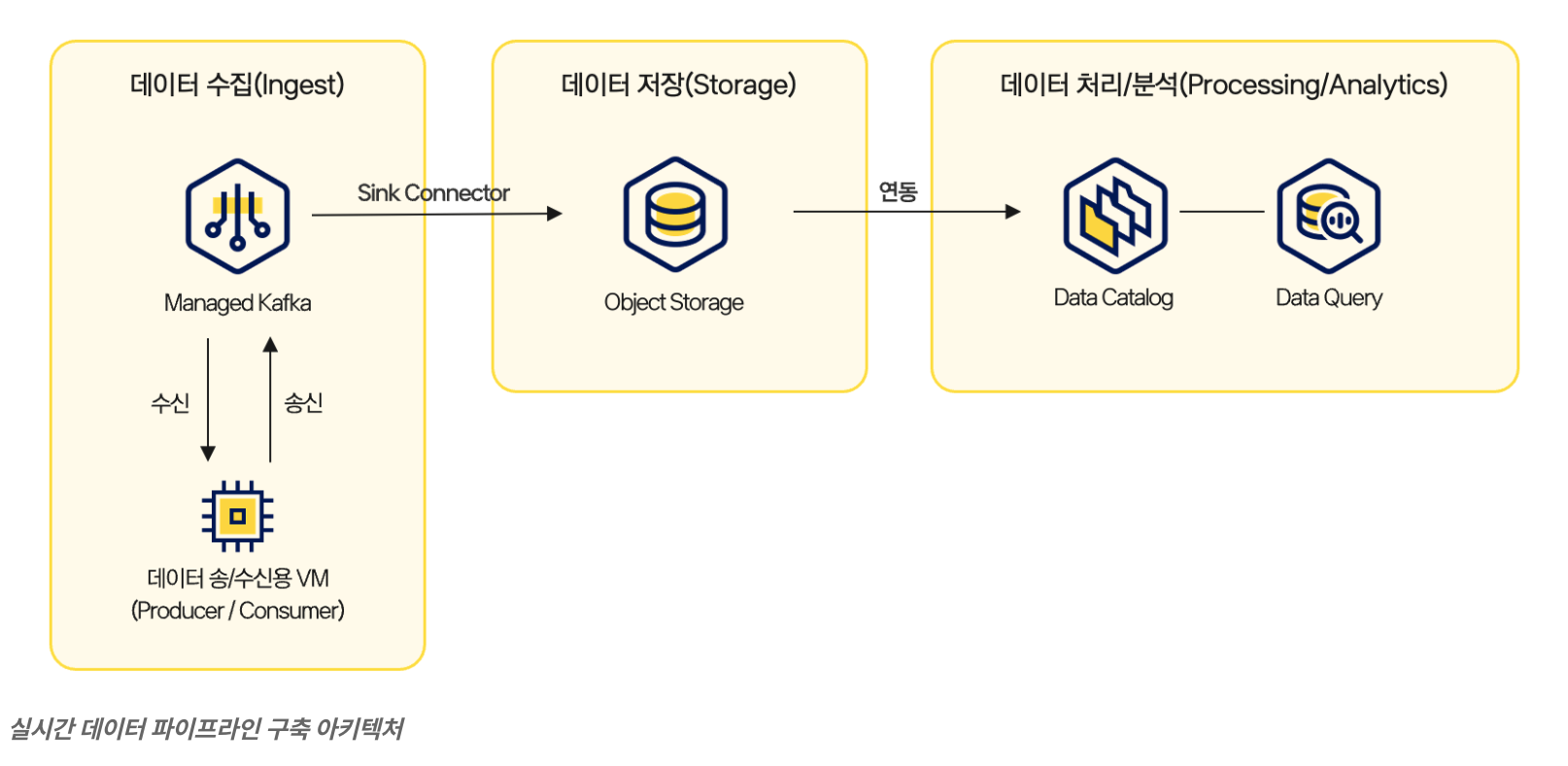
ref: https://docs.kakaocloud.com/blog/2025-09-25-kafka-streaming-tutorial
프로듀서와 컨슈머가 메시지를 송/수신하는 과정에서 실시간으로 S3 객체 스토리지에 데이터를 적재하는 튜토리얼도 소개되어있다.
9.3.4 개별 메시지 변환
데이터를 단순 복사하는 것만으로도 유용하지만, 대부분의 ETL 파이프라인에는 “변환” 단계가 포함된다. Kafka Connect에서는 상태 없는(stateless) 단일 레코드 변환을 스트림 처리의 상태 있는(stateful) 연산과 구분해 SMT(Single Message Transformation)라고 부른다. SMT는 특정 커넥터에 국한되지 않고 아무 커넥터와 사용할 수 있다. SMT 는 보통 설정만으로 적용 가능하며, 반면 Join·Aggregation처럼 상태가 필요한 복잡한 변환은 Kafka Streams를 사용해야 한다.
주요 SMT 유형
| 변환 | 설명 | 대표 사용 사례 |
|---|---|---|
| Cast | 특정 필드의 데이터 타입을 다른 타입으로 변환 | 문자열 숫자를 정수/실수로 캐스팅, 타임스탬프 형식 맞추기 |
| MaskField | 민감한 필드 값을 null 또는 마스킹 값으로 치환 | PII 제거, 로그/분석 파이프라인에서 개인정보 보호 |
| Filter | 조건에 따라 메시지를 포함/제외 | 오류 레코드 제외, 특정 상태(status)만 통과 |
| Flatten | 중첩 구조를 평탄화하여 단일 레코드로 변환 | JSON 중첩 필드 펼치기, 컬럼형 스토리지 적재 전 전처리 |
| HeaderFrom | 특정 필드를 메시지 헤더로 이동/복사 | 라우팅 메타데이터를 헤더로 분리, 다운스트림 필터링 |
| InsertHeader | 정적 값을 메시지 헤더에 추가 | 환경/버전 태그 부여, 파이프라인 출처 표시 |
| InsertField | 새 필드를 추가(오프셋 등 메타데이터 또는 정적 값) | 수집 시각, 소스 토픽/파티션/오프셋 주입 |
| RegexRouter | 정규식 치환으로 목적지 토픽 이름 변경 | db.table → db-table 패턴 정규화, 멀티 테이블 라우팅 |
| ReplaceField | 특정 필드 삭제 또는 이름 변경 | 불필요 필드 제거, 스키마 호환을 위한 리네임 |
| TimestampConverter | 시간 필드 형식 변환(epoch ↔ ISO-8601 등) | 시계열 DB/검색 엔진 요구 형식 맞춤 |
| TimestampRouter | 타임스탬프 기준으로 토픽을 라우팅 | 날짜별 토픽/파티션으로 분배, 싱크 커넥터에서 날짜 기반 테이블 적재 |
추가로 SMT 와 비슷하게 아무 데이터 싱크 커넥터에 사용가능한 error.tolerance 설정이 있다. 요 설정을 이용하여 에러가 발생할 때 무시하거나 데드 레터 큐 토픽으로 보내는 등 설정할 수 있다.
예제 코드
CONNECT_URL="http://localhost:8083"
curl -s -X POST "${CONNECT_URL}/connectors" \
-H "Content-Type: application/json" \
-d '{
"name": "mysql-login-connector",
"config": {
"connector.class": "JdbcSourceConnector",
...
# 어느 SMT 를 사용할건지 정의한다.
"transforms": "InsertHeader",
"transforms.InsertHeader.type": ...
}
}'9.3.5 카프카 커넥트: 좀 더 자세히 알아보기
카프카 커넥트가 어떻게 작동하는지 이해하려면 기본적으로 다음 3개의 기본적인 개념과 이들이 어떻게 상호작용하는지 알아볼 필요가 있다.
1. 커넥터와 태스크
커넥터는 다음 세가지 작업을 수행한다
- 얼마나 테스크가 필요한지? (필요한 테스크 수와 tasks.max 와 비교하여 결정)
- 데이터 복사 작업을 각 테스크에 어떻게 분할할지?
- 워커로부터 테스크 설정을 받아 테스크에게 전달
테스크는 카프카에 데이터를 카프카에 넣거나 가져오는 작업을 담당한다. 모든 테스크는 워커로부터 컨텍스트를 받아서 초기화 된다.
- 소스 컨텍스트에는 테스크가 소스 레코드의 오프셋을 저장할 수 있게 해주는 객체를 포함한다. 예를 들어, 파일 커넥터의 경우 오프셋은 파일 내 위치가 되고, 만약 JDBC 커넥터라면 오프셋은 테이블의 타임스탬프 열 값이 된다.
- 싱크 컨텍스트는 커넥터가 카프카로부터 받는 레코드를 제어할 수 있게 해주는 메서드들이 있다. 이를 이용해서 백프레셔를 적용하거나, 재시도를 하거나, '정확히 한 번' 전달을 위해 오프셋을 외부에 저장하거나 할 때 사용한다.
2. 워커
워커는 커넥터·태스크를 실행하는 컨테이너 프로세스다. 워커는 REST API 요청 처리(커넥터 정의·설정), 내부 토픽에 설정 저장, 커넥터/태스크 실행과 재할당(크래시·스케일링 시) 등을 담당한다. 앞서 커넥터와 테스크는 데이터 이동 역할을 맡는다면 워커는 REST API, 설정관리, 신뢰성, 고가용성, 규모 확장성, 부하 분산 등을 담당한다.
3. 컨버터 및 커넥트 데이터 모델
소스 커넥터는 데이터 API 를 이용하여 원본 데이터 소스를 데이터 객체로 변환하지만 그 객체를 그대로 카프카에 전달할 수는 없다. 따라서 중간에 컨버터를 넣어서 최종 데이터를 변환해준 다음 카프카에 전달한다.
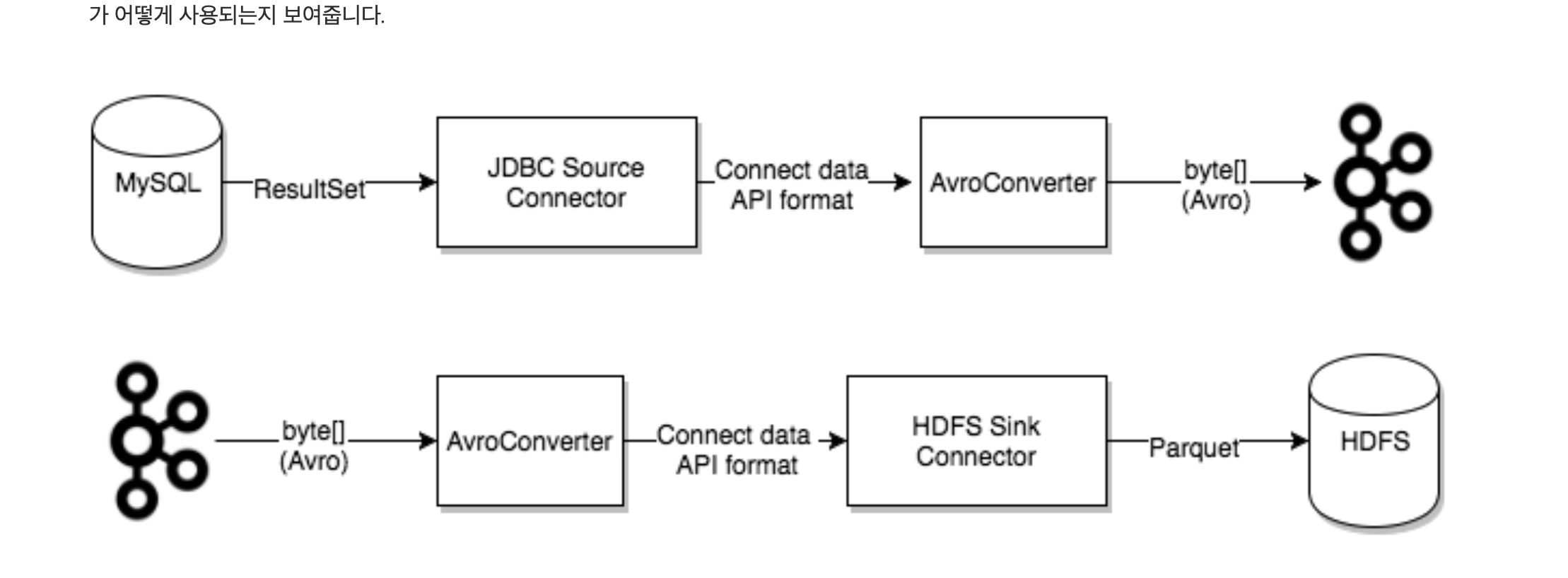
ref: https://dytis.tistory.com/74
싱크 커넥터는 소스 커넥터와 반대로 위치해있다.
컨버터는 커넥터와 분리되어 있어 커넥터 간 재사용도 가능하다.
4. 오프셋 관리
오프셋 관리는 워커 프로세스가 커넥터에 제공하는 편리한 기능 중 하나이다.
소스 커넥터는 원본 기준의 논리 파티션·오프셋을 붙여 레코드를 반환한다(예: 파일=파티션, 줄/바이트=오프셋; JDBC는 테이블=파티션, ID/타임스탬프=오프셋). 워커가 레코드를 카프카에 성공적으로 쓴 뒤에야 그 오프셋을 저장하므로, 장애나 재시작 후에도 마지막 저장 지점부터 안전하게 이어 처리할 수 있다. 오프셋은 내부 토픽 또는 외부 저장소에 보관할 수 있으며, 싱크 커넥터도 반대 흐름으로 동일한 방식으로 진행한다.
소스 커넥터를 개발할 때 가장 중요한 것 중 하나는 원본 데이터를 어떻게 분할하고 오프셋을 정의하느냐이다. 이것은 병렬성과 전달 의미(최소 한 번, 정확히 한 번)에 직접 영향을 준다.
9.4 카프카 커넥트의 대안
하둡의 경우 플룸, 엘라스틱서치의 경우 로그스태시, fluentd 가 와 같이 자체적인 데이터 수집 툴이 갖춰져 있다. 카프카를 중심으로 쓰고있다면 kafka connect를 쓰는것이 좋지만, 엘라스틱서치를 중점적으로 쓰고있다면 로그스태시 쓰는게 좋다
