리눅스 창시자 인터뷰

두 번째 날, 가장 인상깊었던 건 역기 리누스 토발즈 영접이다. 영어를 잘하지 못해서 그의 말을 100% 이해하지 못했지만 그가 생각하는 리눅스 커널의 방향, AI 시대에 대해 얼추 이해할 수 있었다.
- 리눅스 커널에 러스트 적용 👍
- 생성형 AI 은 리눅스 커널에 부정적인 영향을 줌
- 바이브 코딩은 딱히…
- 이메일 답장 안하는 사람
자세한 인터뷰 내용은 요기를 참고하면 좋을 듯 하다.
그리고 첫 번째 날에 비해 다양한 주제로 많은 강연들이 있었다. 나는 리눅스 커널보다는 AI 쪽에 관심이 많았기에 스케쥴을 보면서 'AI' 가 들어간 강연을 위주로 선택하여 보았다.
OpenFGA
ref: https://openfga.dev/
다양한 상황, 기술에 AI 을 접목시켜 사용하고 있는데 과연 보안 측면에서는 괜찮을까? 어떻게 하면 AI 를 사용할 때 내부적인 데이터 등을 보호할 수 있을까 고민이 되었는데 두 번째 날 스케쥴에서 "AI... overprivilege" 라는 단어가 눈에 들어왔다.
해당 강연을 들으면서 앞서 공부했었던 "keycloak" 과 비슷한 느낌이 들었기에 쉽게 이해할 수 있었다.
1. AI 에이전트와 인가(Authorization)의 중요성
AI가 사용자 대신 API를 호출하고, 데이터에 접근하며, 업무를 자동화하는 시대가 오면서 가장 중요한 보안 이슈는 “누가, 무엇을, 언제, 어디까지 할 수 있는가” 이다.
- 인증(Authentication): 사용자가 누구인지 확인하는 단계
- 🔸 인증은 “Who are you?”
- 인가(Authorization): 사용자가 무엇을 할 수 있는지 결정하는 단계
- 🔸 인가는 “Can you do that?”
2. GenAI 보안에서 고려해야 할 네 가지 요구사항
발표에서는 AI 기반 시스템의 4가지 인증·인가 요구사항을 제시한다.
- AI는 사용자가 누구인지 알아야 한다.
- AI는 사용자를 대신해 API를 호출해야 한다.
- AI는 비동기(Async) 상호작용을 처리해야 한다.
- AI의 데이터 접근은 사용자 권한을 반영해야 한다.
즉, AI가 사용자의 권한 범위 내에서만 데이터 접근 및 조작을 해야 한다.
3. 접근 제어의 진화: RBAC → ABAC → ReBAC
| 이름 | 설명 |
|---|---|
| RBAC (Role-Based Access Control) | 사용자의 역할(Role)에 따라 권한을 부여 |
| ABAC (Attribute-Based Access Control) | 속성(Attributes) — 예: 부서, 근무 시간 등 — 기반의 세분화된 접근 |
| ReBAC (Relationship-Based Access Control) | 객체 간 관계(Relationship) 기반 접근 제어 (예: “팀원이면 해당 문서 접근 가능”) |
4. OpenFGA
AI 에이전트는 호출한 사용자가 누구냐에 따라서 API 호출을 제어해야된다. 예를 들어, CEO 가 아닌 일반 사원이 사내 기밀 문서에 접근하면 안되는 거처럼 말이다.
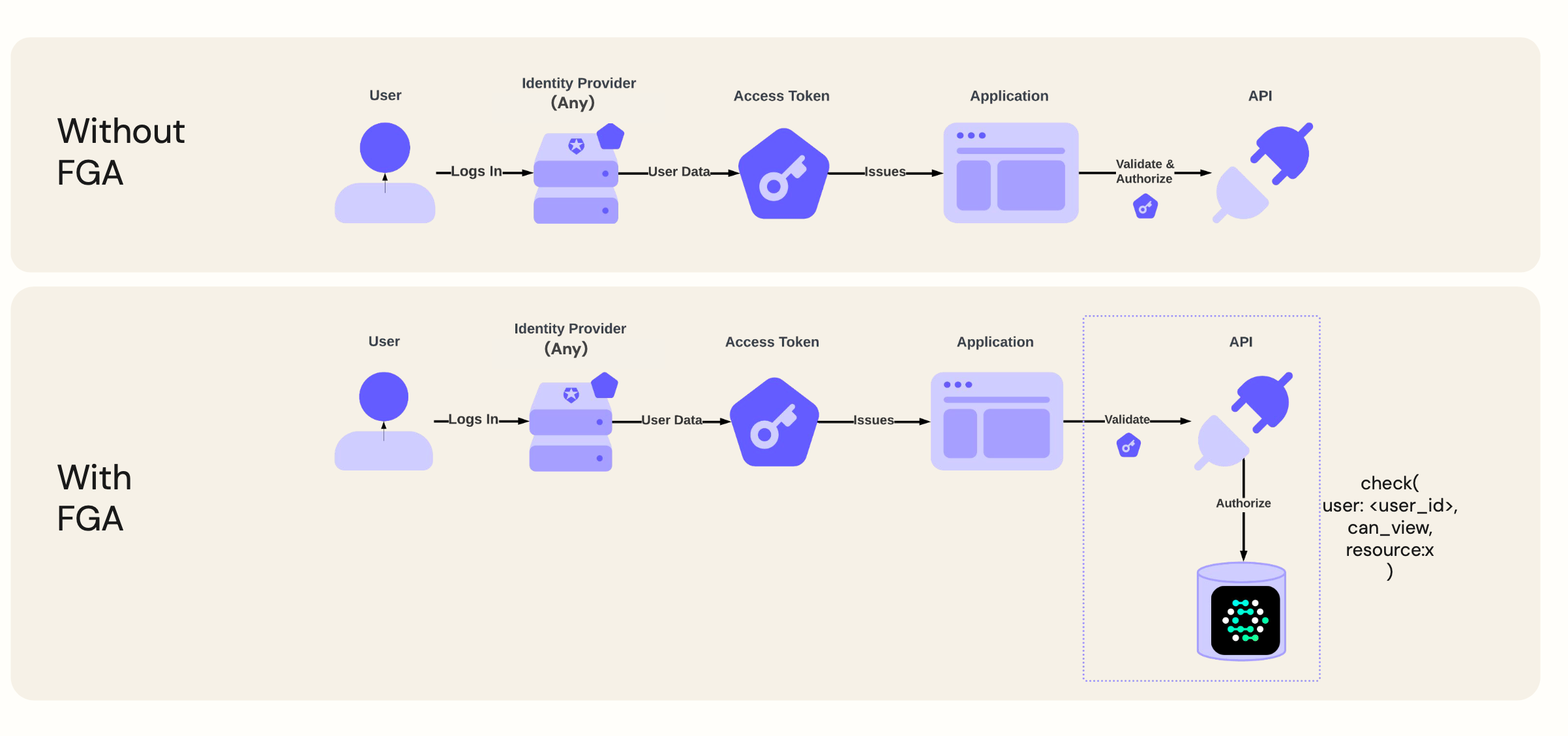
그러나 이렇게 구현하려고 어플리케이션 또는 파이프라인에 검증 뿐만 아니라 인가 관련된 코드까지 직접 작성하면 결합도가 높아지는 문제가 있다. 하지만 openFGA 를 사용하면 별도의 인가만 모아놓은 독립된 서비스로 결합도를 낮출 수 있다.
4-1) openFGA 의 핵심 요소 3가지

-
인가 모델 (Authorization Model)
→ “누가 무엇을 할 수 있는가”를 정의하는 관계 스키마.
-
관계 튜플 (Relationship Tuple)
→ user, relation, object 간의 구체적 관계 매핑.
-
접근 제어 검사 (Access Control Check)
→ 특정 사용자가 리소스에 접근할 수 있는지 확인하는 API 호출.
4-2) openFGA 의 작동 방식
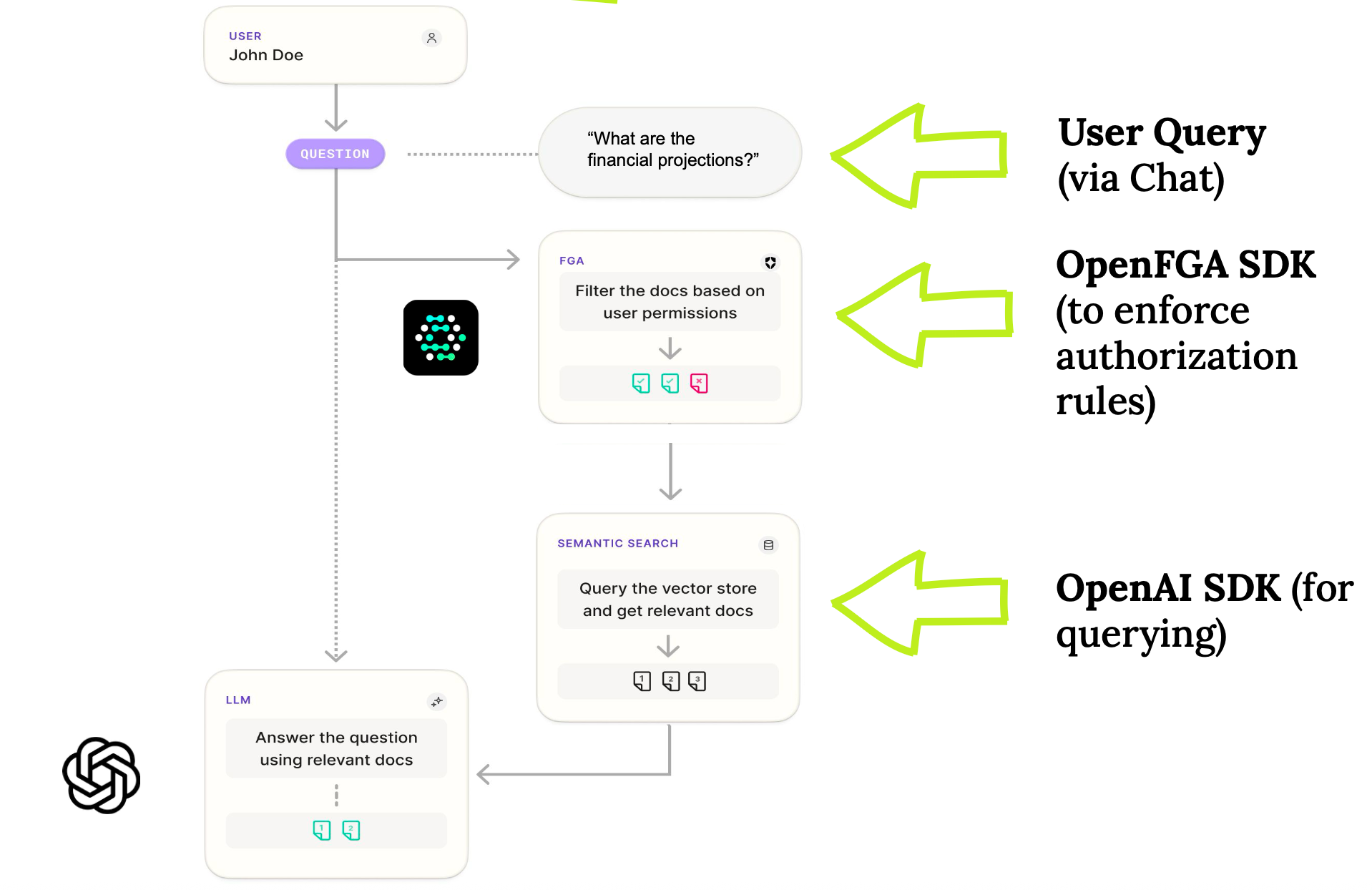
OpenFGA는 RAG(Retrieval-Augmented Generation) 파이프라인에서도 인가 기반 필터링 계층으로 작동한다. (pre, post 로 LLM 호출 전 또는 후에 필터링 계층 추가할 수 있다)
아래 이미지를 보면 openAI llm 에 물어보기 전에 호출한 유저가 document 에 대해 적절한 권한을 갖고있는지 검사하고 llm 에 전달한다.
4-3) openFGA 의 장점(개인적인 생각)
개인적으로 openFGA 의 또 하나 큰 장점은 object 와 accessor 간 접근 권한이 그래프로 쉽게 볼 수 있다는 점!

Backend.ai sokovan 엔진 -> k8s 에 적용
과거 오픈소스 컨트리뷰톤에 참가했을 때 기여했던 프로젝트가 backend.ai 여서 꼭 듣고 싶었던 강연이였다. 이전에 파악했던 backend.ai 아키텍쳐와 비슷했던 거 같은데 내용이 어려워서 그런지 이해하기 힘들었다. 그래서 pdf 파일 보면서 다시 복기하며 정리를 해보았다.
1. AI, HPC 의 특징
AI, HPC 의 특징은 다음과 같다
| 구분 | 설명 |
|---|---|
| 전체 자원 독점 가정 | 대부분의 AI/HPC 작업은 “하나의 작업이 가시적인 모든 리소스를 사용할 수 있다” 는 전제를 가짐. 예를 들어, 대규모 모델 학습 시 GPU 전부를 점유. |
| 멀티노드 확장(Multi-node scaling) | 하나의 작업(Job)을 여러 노드에 걸쳐 확장해야 하며, 노드 간 고속 네트워크 통신이 필수.→ 이를 위해 RDMA (Remote Direct Memory Access), GPUDirect Storage 같은 고성능 인터커넥트 필요. |
| 배치 지향적(Batch-oriented), 상태 유지(Stateful) | AI 학습·HPC 작업은 반복적(batch)으로 수행되며, 중간 상태(state)가 중요함.→ 재시작이나 재배치(restart/relocation)는 비용이 크고 시간 소모가 큼. |
2. 쿠버네티스의 한계
그러나 쿠버네티스는 마이크로서비스에 적합하지 배치 잡에는 적합하지 않는다.
(https://medium.com/better-programming/kubernetes-was-never-designed-for-batch-jobs-f59be376a338 요기 참고하면 좋음)
2-1) 불완전한 격리 (Leaky Sandbox)
- 컨테이너는 호스트 정보를 다수 노출하는 누수형 샌드박스이며,CPU/메모리 제약은 리눅스 커널(cgroup)에 의해 강제 적용된다
2-2) 가속기(Accelerator) 의존성 문제
- 가속기 자원은 벤더 전용 플러그인(nvidia-container-runtime)을 통해만 제어 가능.
2-3) 멀티노드 확장(Multi-node scaling)의 어려움
- Kubernetes의 기본 단위인 Pod는 한 호스트(Node) 내에서만 동작함.
- 여러 노드를 아우르는 대규모 학습/추론(Job)을 실행하려면
- 사전에 Pod를 여러 노드에 배치하고,
- 각 Pod 간의 통신·동기화를 담당할 별도의 조정 계층(coordination layer) 이 필요함.
=> 개인적으로 요게 큰 문제였던거 같음!
3. backend.ai 의 sokovan 을 k8s 에 적용!
backend.ai 에서는 쿠버네티스 환경에서도 AI 워크로드를 효율적으로 실행할 수 있도록 sokovan 엔진을 개발함(HPC workloads → AI 로 확장하여 개발)
-
투명성과 관찰 가능성 (Transparency & Observability)
- 기존 사용자가 사용하던 관리 도구들이 Backend.AI가 관리하는 컨테이너를 그대로 관찰할 수 있어야 함.
- 이를 위해 Sokovan은 Kubernetes 네임스페이스 및 접근 제어를 활용해 GPU 노드 및 컨테이너에 대한 완전한 제어권을 유지함.
-
성능 및 하드웨어 가속 유지 (Performance & Hardware Acceleration)
- Sokovan의 본래 엔진 성능(네이티브 가속기 활용 성능)을 Kubernetes 상에서도 동일하게 유지해야 함.
-
엔터티 매핑 (Entity Mapping)
Sokovan의 개념을 Kubernetes 리소스와 일대일로 매핑
Sokovan 개념 Kubernetes 대응 개체 설명 Resource Group Node Pool 동일한 ACL을 공유하는 컴퓨트 노드 그룹 Kernel Pod 개별 컴퓨트 노드에서 실행되는 컨테이너 Session Pod 그룹(Group of Pods) 하나의 연산 잡(Job)을 구성하는 여러 컨테이너 묶음
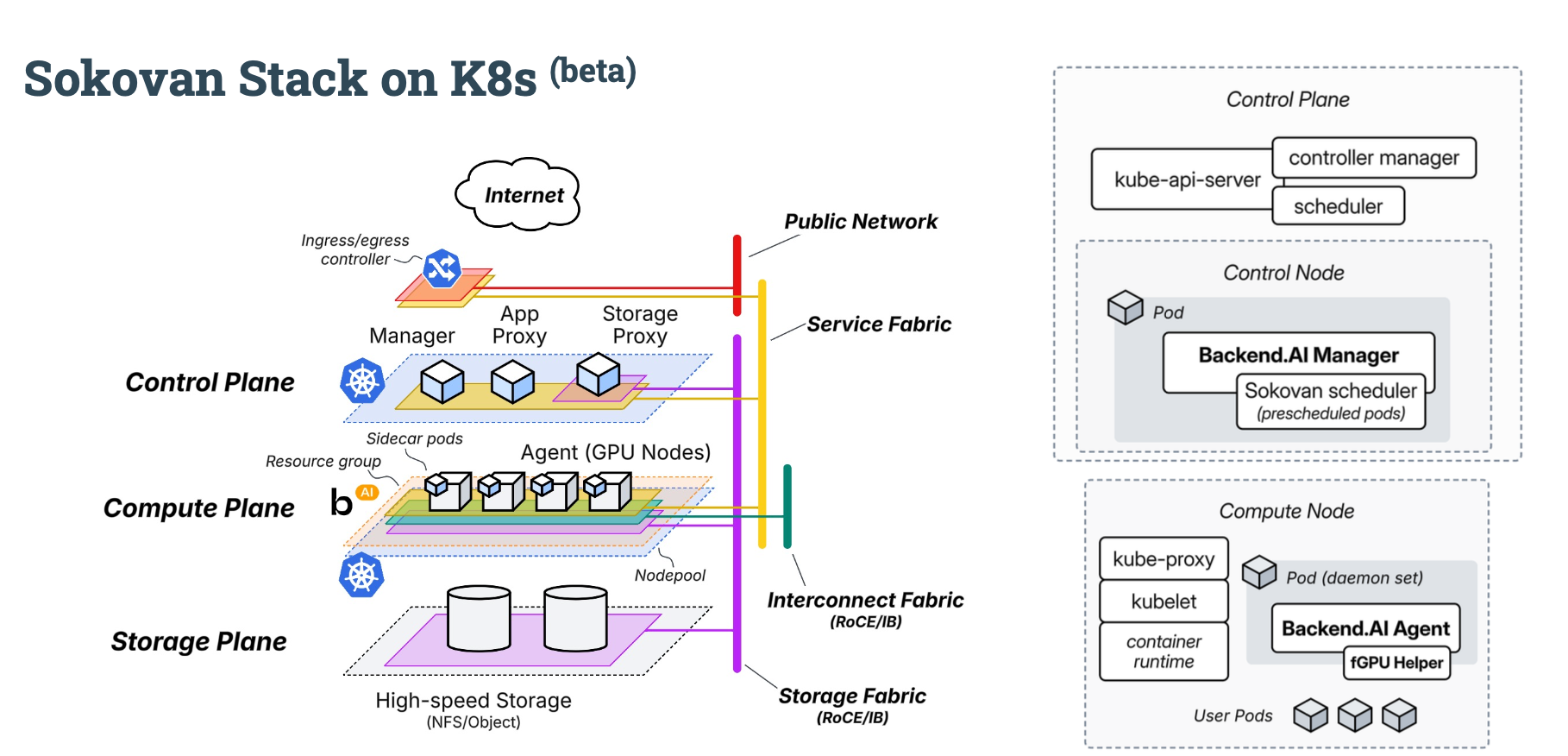
control plane
- Manager 가 적절히 agent 를 스케쥴링한다
compute plane
- agent 가 각 gpu 노드에 데몬셋 형태로 배포되어 컨테이너 실행과 gpu 리소스 관리를 담당함
⇒ 과거 카펜터에서 미리 노드를 띄워주는 기능이 존재하지 않아 별도로 데몬셋(한 노드에 하나만 존재 가능)을 추가했었던 작업을 했는데 그거랑 비슷한듯!
오픈텔레메트리를 이용한 프로파일링
'모니터링의 새로운 미래 관측 가능성'에 대해서 공부했던터라 쉽게 이해할 수 있었던 내용이였다. 해당 강연을 보면서 '오픈텔레메트리'가 곧 표준이 되겠구나(어쩌면 이미 된걸지도) 싶었다.
다시 한번 오픈텔레메트리의 강력함을 확인할 수 있었던 내용이였다.
1. LLM 시스템의 주요 문제점
대규모 언어 모델(LLM)은 막대한 연산 자원을 요구하므로, 다음과 같은 운영상 이슈가 발생함
| 문제 영역 | 설명 |
|---|---|
| 비용(Cost) | GPU/CPU 자원 점유가 높고, 모델 실행 시간에 따라 비용 급등. |
| 모델 관리(Management) | 여러 버전의 모델을 관리·배포하는 과정에서 추적성 부족. |
| 지연(Latency) | 응답 지연이 크며, 내부 파이프라인 병목 구간 확인이 어려움. |
| 자원 점유(Resource Utilization) | 특정 코드나 모듈이 불균형하게 GPU/CPU/메모리를 사용. |
2. 오픈텔레메트리란?
오픈소스 Observability 프레임워크로, 애플리케이션과 인프라 전반의 Trace / Metrics / Logs 를 수집·통합한다. 그리고 모니터링 벤더(예: Grafana, Datadog, New Relic, Prometheus 등)와 연동 가능하여 사용할 수 있다.
내부적으로 Otel Collector가, 각 서비스의 관측 데이터를 수집(receive) → 전송(export) 한다.
[App / Infra] → [OpenTelemetry SDK] → [Otel Collector] → [DBs / Monitoring System]3. 프로파일링
프로파일링은 코드 실행 중 어떤 부분이 자원을 많이 소모하거나 지연을 일으키는지 분석하는 과정이다. 내부적으로 어느 트랜잭션에서 CPU, GPU, Memory, I/O 등 자원 사용량을 함수 단위 혹은 호출 스택 단위로 추적 가능하다.
OpenTelemetry 기반 프로파일링을 통해서
- OpenTelemetry의 Trace 데이터를 기반으로 코드의 실행 흐름을 시각화.
- Trace → Profiling 확장으로, CPU/GPU 사용률, Memory 누수, I/O 병목 등을 정밀 분석 가능.
- 예를 들어, LLM 실행 중 Transformer 모듈의 특정 Attention 연산에서 자원 집중 현상을 추적 가능.
4. 최적화 및 비용 절감 방향
- 개발 단계에서 프로파일링을 수행하여 자원 낭비를 조기 발견
- 스택 트레이스(Stack Trace) 기반으로 CPU 사용률이 높은 부분 파악
- Memory leak 발생 지점을 추적하여 코드 수정
kepler, 그린생태계 유지
ref: https://github.com/sustainable-computing-io/kepler
강연 제목은 "Achieving Cloud Native Sustainability With MCP Integration" 로서 '와 MCP 얘기인가?" 하고 들었는데 내가 생각한 내용과 전혀 다른 내용이였다. (개요좀 미리 살펴볼 걸...)
Kepler 를 사용해서 자원 사용량을 파악하고 이를 프로메테우스 등에서 수집하여 시각화한 내용이였는데, 과거 그라파나 LGTM 공부하면서 프로메테우스 공부했던게 많은 도움이 되었다.
1. 기술 발달 ⇒ 지구 온난화
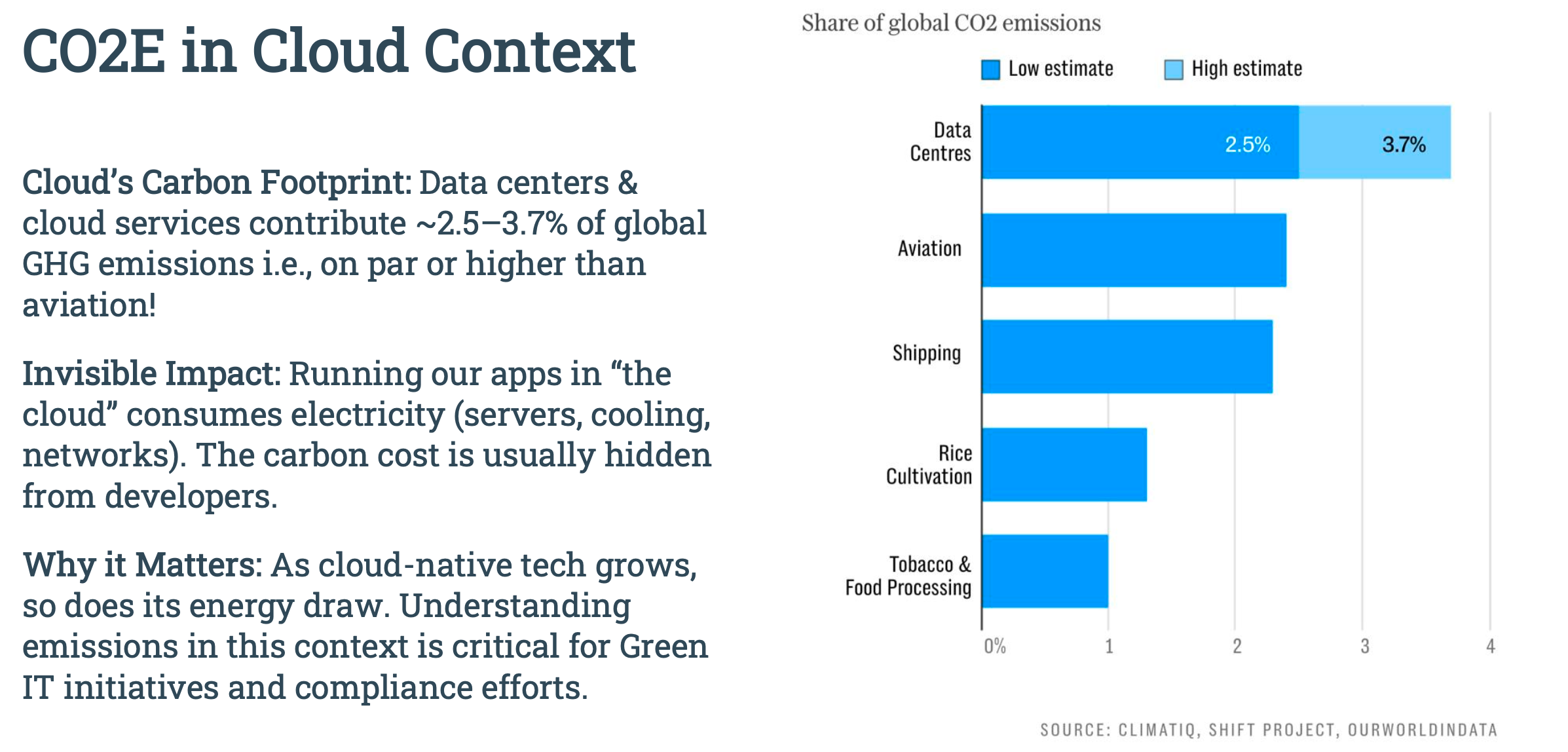
클라우드 네이티브 기술이 성장하면서 에너지 사용량도 증가. CO2 방출량의 일정 부분을 차지할만큼 환경적으로 인지해야될 필요가 있다.
2. Kepler란 무엇인가?
Kepler(Kubernetes-based Efficient Power Level Exporter) 는 컴퓨팅 자원 사용에 따른 에너지 데이터를 수집하고 노출하는 오픈소스 관찰 도구이다.
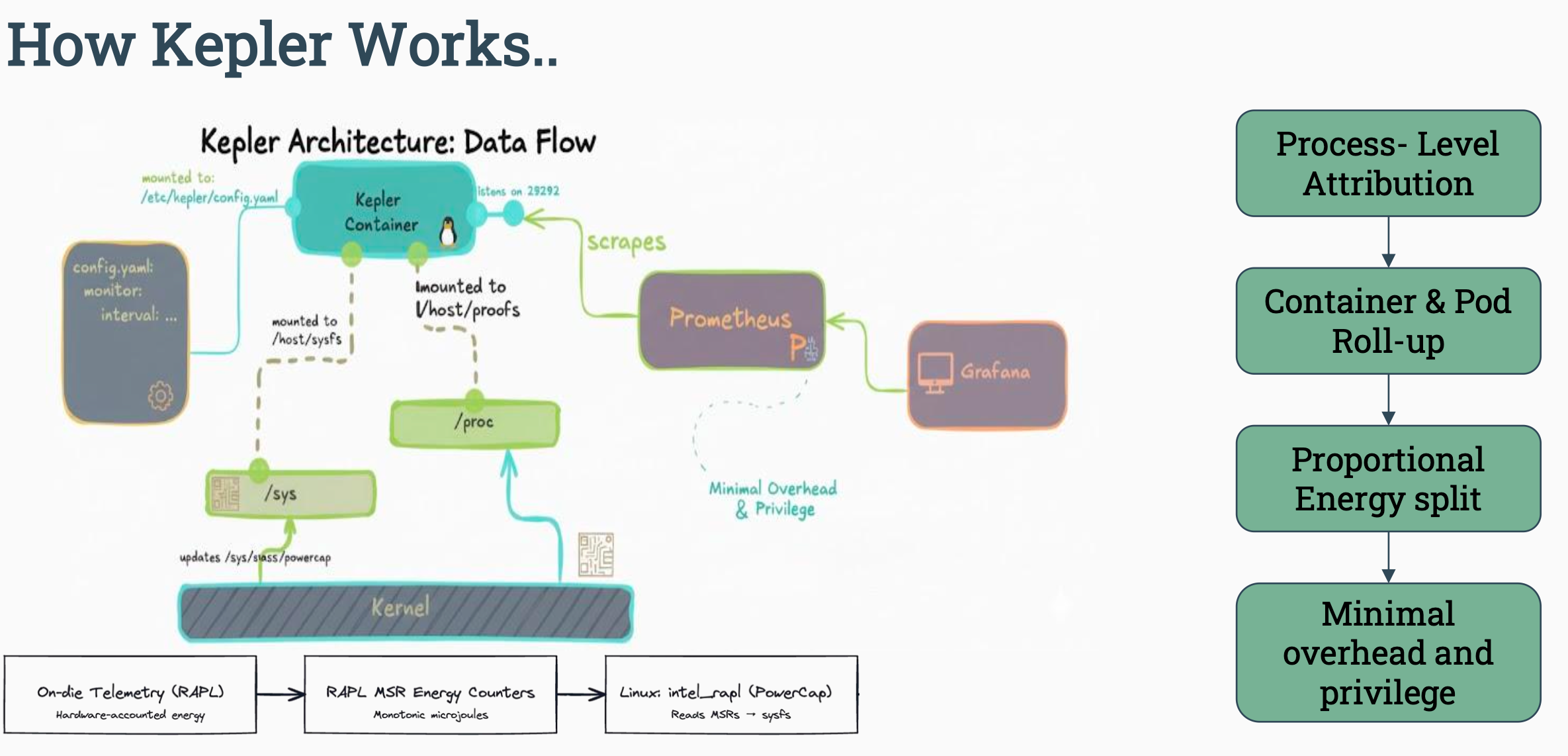
케플러는 커널 단계에서 리소스 사용률을 수집하면, 프로메테우스 측에서 스크래핑하여 시각화한다.
3. 데모
데모하는거 보여줬는데 거기에 리전을 바꿔서 에너지 사용률을 줄일 수 있다고 추천해줌. (사진 찍은 줄 알았는데 없네)
Vibe computing (cloud-barista)
바이브 코딩인 줄 알았다가 자세히 보니 "vibe computing" 이여서 눈길을 끌던 강연이였다. 스케쥴 상세페이지에서 개요를 살펴보지 않았던터라 강연에서 내용을 알게되었는데 뭔가 내가 생각했던 바이브 컴퓨팅?이 아닌 느낌이였다.
그러나 해당 강연에서 소개한 오픈소스 cloud-barista 를 보면서 "와 엄청 편하게 클라우드에 서버 띄우네. 저거 이용해서 뭔가 빠르게 프로토타입 형태도 보여줄 수도 있겠다" 생각이 들었다.
1. 멀티 클라우드의 필요성과 문제점
- 멀티 클라우드(Multi-Cloud) 는 서비스 안정성과 비용 효율성을 위해 필요하지만, 각 클라우드 서비스마다 서로 다른 용어, API, 관리 방식 때문에 통합 관리가 매우 어렵다.
- 또한, VM 성능·가격·네트워크 지연(latency) 이 클라우드와 리전마다 다르기 때문에, 단일 환경에서 최적의 인프라를 구성하기 어렵다
2. Cloud-Barista 란?
- Cloud-Barista 는 멀티 클라우드 인프라 통합 관리 오픈소스 프로젝트로, 여러 클라우드의 자원을 하나의 통합된 인터페이스로 관리할 수 있도록 설계되었다
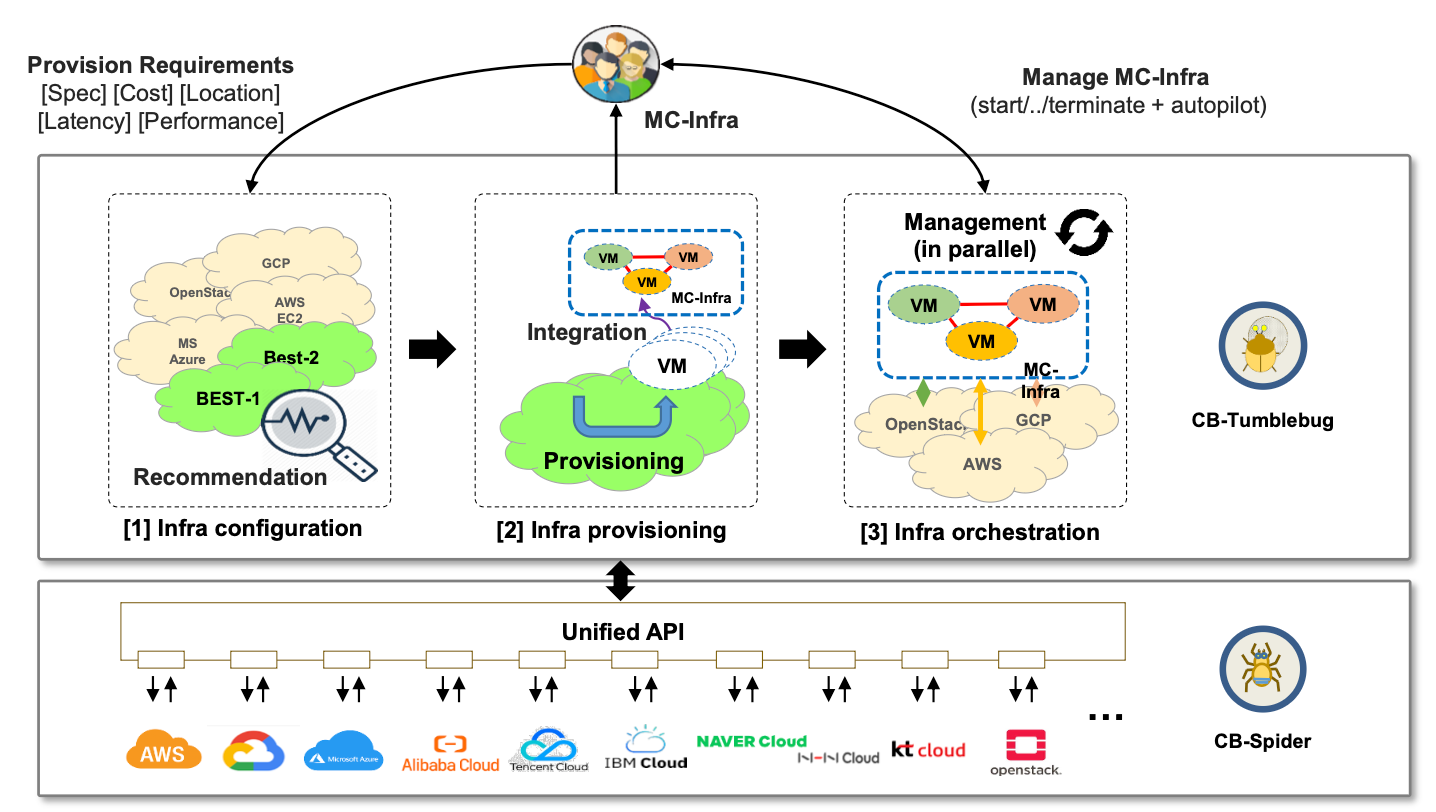
내부적으로 CB-Spider 가 여러 클라우드 서비스 API 를 통합된 API 로서 제공하고 CB-Tumblebug 는 인프라 리전 추천, 프로비저닝, 오케스트레이션을 기능을 담당한다.
3. 활용 사례
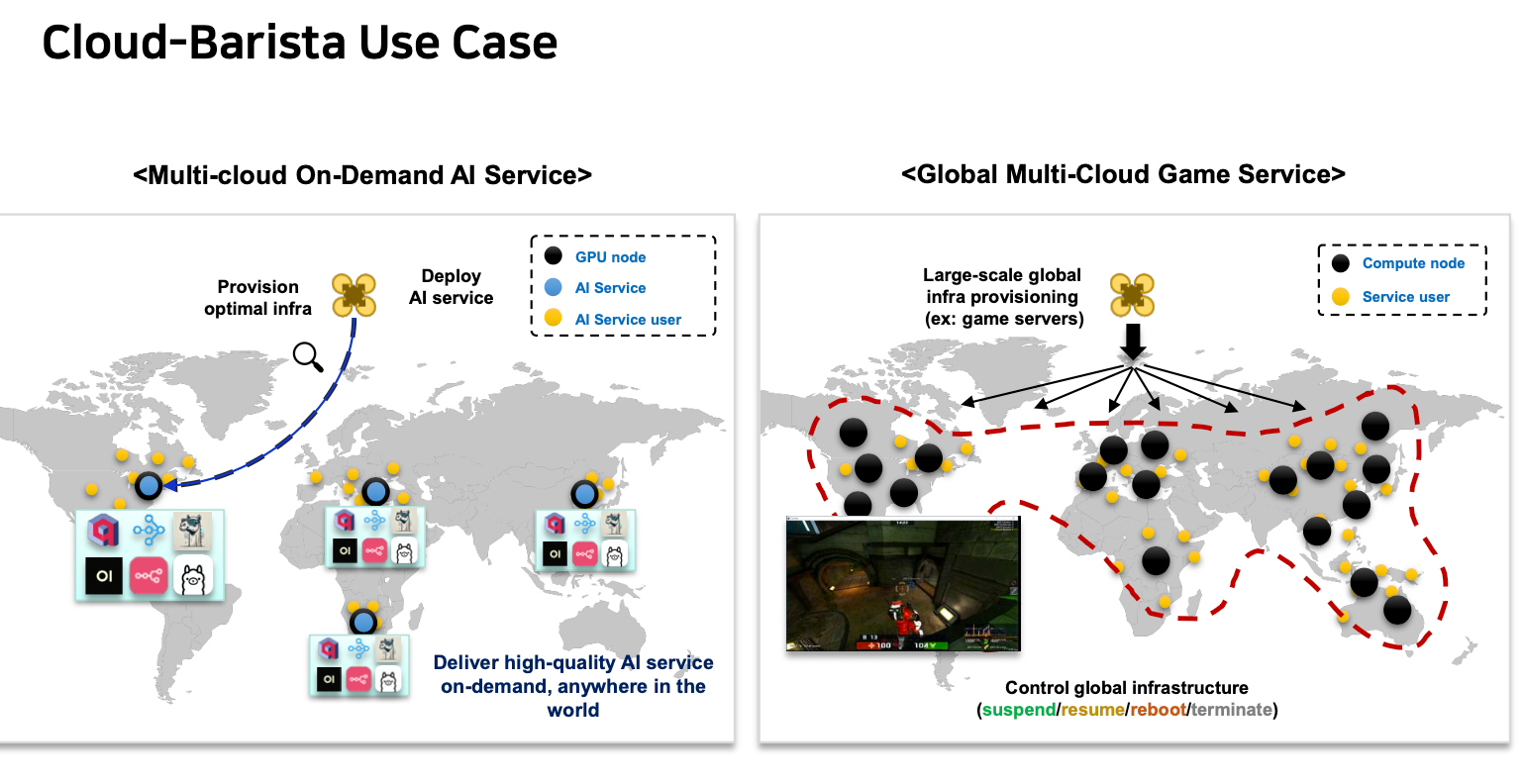
여러 리전에 온디맨드 AI 서비스를 배포할 수도 있고, 게임 서버도 여러 리전에 구축하여 게임하는 등 여러 데모를 보여줬다. 그 중 AI llm 을 배포해서 사용한 데모가 인상적이였다.
