
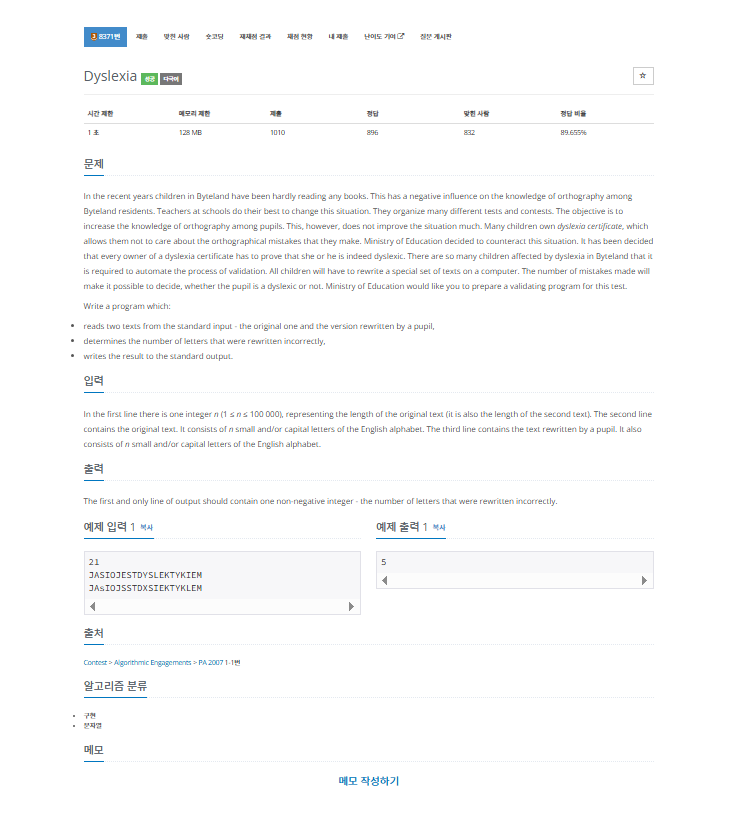
문제
내가 생각했을때 문제에서 원하는부분
In the first line there is one integer n (1 ≤ n ≤ 100 000), representing the length of the original text (it is also the length of the second text).
The second line contains the original text.
It consists of n small and/or capital letters of the English alphabet.
The third line contains the text rewritten by a pupil.
It also consists of n small and/or capital letters of the English alphabet.
The first and only line of output should contain one non-negative integer - the number of letters that were rewritten incorrectly.내가 이 문제를 보고 생각해본 부분
BufferedReader로 입력을 빠르게 받는다.
첫 줄에서 문자열 길이 n을 정수로 받고, 두 줄을 String으로 받는다.
for문으로 0부터 n-1까지 모든 위치를 비교한다.
각 위치의 문자 original.charAt(i)와 rewritten.charAt(i)가 다르면 errors를 1씩 증가시킨다.
반복 후에 errors를 출력한다.
마지막에 리소스 누수를 막기 위해 br.close()로 스트림을 닫는다.코드로 구현
package baekjoon.baekjoon_32;
import java.io.BufferedReader;
import java.io.IOException;
import java.io.InputStreamReader;
// 백준 8371번 문제
public class Main1299 {
public static void main(String[] args) throws IOException {
BufferedReader br = new BufferedReader(new InputStreamReader(System.in));
int n = Integer.parseInt(br.readLine()); // 문자열 길이 입력
String original = br.readLine(); // 원본 문자열 입력
String rewritten = br.readLine(); // 학생이 쓴 문자열 입력
int errors = 0;
for (int i = 0; i < n; i++) {
if (original.charAt(i) != rewritten.charAt(i)) {
errors++; // 문자가 다르면 오류 개수 증가
}
}
System.out.println(errors); // 최종 오류 개수 출력
br.close();
}
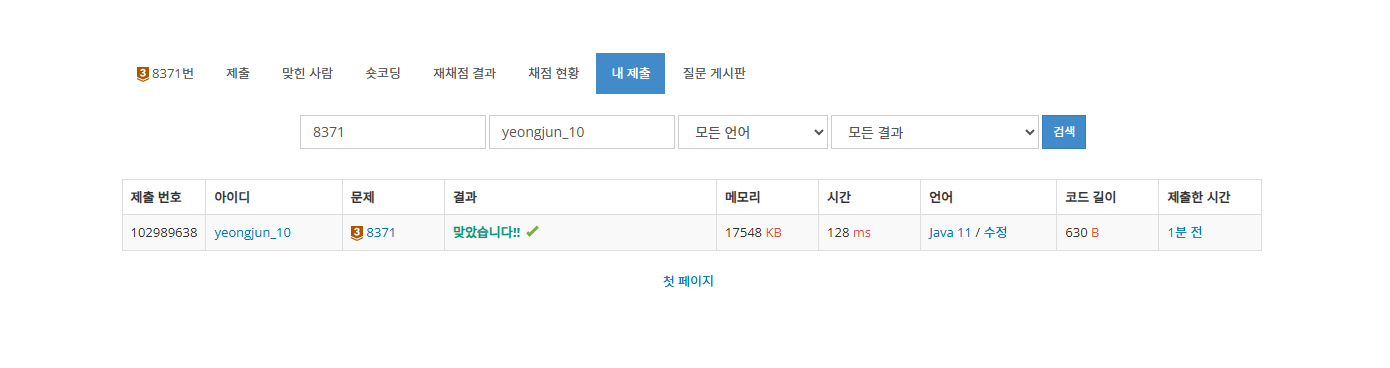
}
마무리
코드와 설명이 부족할수 있습니다. 코드를 보시고 문제가 있거나 코드 개선이 필요한 부분이 있다면 댓글로 말해주시면 감사한 마음으로 참고해 코드를 수정 하겠습니다.

Junior backend developer