1. Volume이 나온 배경
- 파드는 내부에 프로세스가 실행되고 CPU, RAM, 네트워크 인터페이스 등의 리소스를 공유한다. 하지만 디스크는 공유되지 않는다. 파드 내부의 각 컨테이너는 고유하게 분리된 파일시스템을 가지기 때문이다.
- 새로 시작한 컨테이너는 이전에 실행했던 컨테이너에 쓰여진 파일 시스템의 어떤 것도 볼 수없다. 전체 파일 시스템이 유지될 필요는 없지만 실제 데이터를 가진 데렉터리를 보존하고 싶을 수도 있다.
- 이를 위해 쿠버테티스는 스토리지 볼륨 기능을 제공한다. 볼륨은 파드와 같은 최상위 리소스는 아니지만 파드의 일부분으로 정의되며 파드와 일반적으로는 동일한 라이프 사이클을 가진다.
2. Volume이란
- 쿠버네티스 볼륨은 파드의 구성 요소로 컨테이너와 동일하게 파드 스펙에서 정의된다.
- 볼륨은 독립적인 쿠버네티스 오브젝트가 아니므로 자체적으로 생성, 삭제될 수 없다.
- 접근하려는 컨테이너에서 각각 마운트물리적인 장치(디스크)를 특정한 위치(디렉토리)에 연결시켜 주는 과정되어야 한다.
- 예를 들어, 볼륨 2개를 파드에 추가하고, 3개의 컨테이너 내부에 적절한 경로에 마운트했을 때 아래 사진과 같아진다. 이때, 마운트되지 않은 볼륨이 같은 파드안에 있더라도 접근할 수 없고, 접근하려면 volumeMount를 컨테이너 스펙에 추가해야한다.
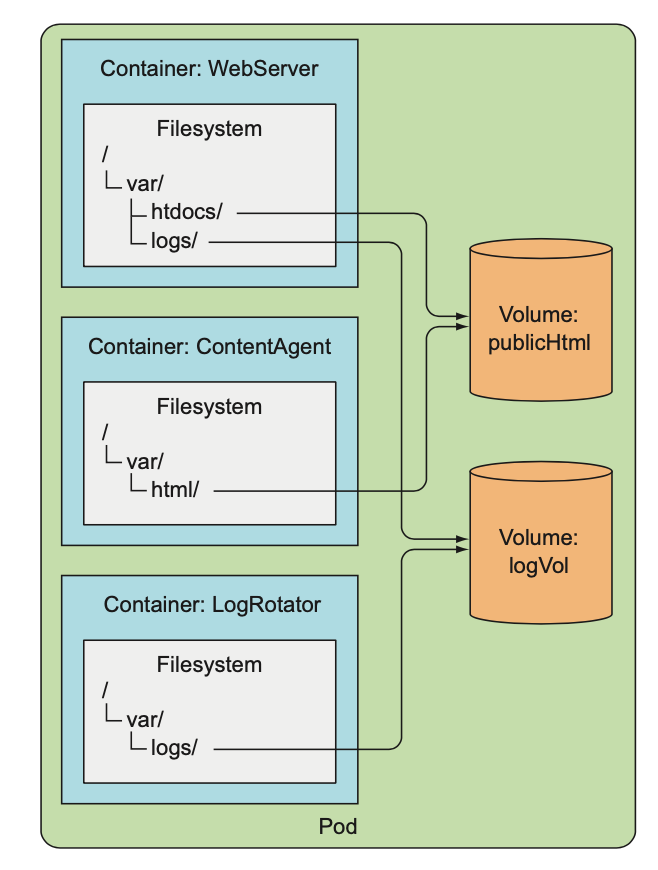
3. 사용 가능한 Volume
- emptyDir : 일시적인 데이터를 저장하는데 사용하는 간단한 빈 디렉토리
- gitRepo : 깃 레포지토리의 컨텐츠를 체크아웃해 초기화한 볼륨
- hostPath : 워커 노드의 파일시스템을 파드의 디렉토리로 마운트
- ntf : NFS 공유를 파드에 마운트
- gcePersistentDisk, awsElasticBlockStore, azureDisk 등 : 클라우드 제공자의 전용 스토리지 마운트
- cinder, cephfs, iscsi, flocker, glusterfs, quobyte, rdb, flexVolume, vsphereVolume, photonPersistentDisk, scaleIO : 다른 유형의 네트워크 스토리지 마운트
- configMap, secret, downwardAPI : 쿠버네티스 리소스나 클러스터 정보를 파드에 노출하는 데 사용되는 특별한 유형의 볼륨
- persistentVolumeClaim : 사전 혹은 동적으로 프로비저닝된 퍼시스턴트 스토리지를 사용하는 방법
[1] EmptyDir
- 빈 디렉토리로 시작되며, 볼륨의 라이프사이클이 파드에 묶여 있으므로 파드가 삭제되면 볼륨의 콘텐츠도 사라진다.
- 컨테이너에서 가용한 메모리에 넣기에 큰 데이터 셋의 정렬 작업을 수행하는 것과 같은 임시 데이터를 디스크에 쓰는 목적인 경우 사용할 수 있다.
apiVersion: v1
kind: Pod
metadata:
name: fortune
spec:
containers:
- image: luksa/fortune
name: html-generator # 첫번째 컨테이너 html-generator
volumeMounts: # html이라는 이름의 볼륨을 컨테이너 /var/htdocs에 마운트
- name: html
mountPath: /var/htdocs
- image: nginx:alpine
name: web-server # 두번째 컨테이너 web-server
volumeMounts: # html이라는 이름의 볼륨을 컨테이너 /usr/share/nginx/html에 마운트
- name: html
mountPath: /usr/share/nginx/html
readOnly: true
ports:
- containerPort: 80
protocol: TCP
volumes: # html이라는 단일 emptyDir 볼륨을 위의 컨테이너 2개에 마운트하기 위한 정의
- name: html
emptyDir: {}[2] GitRepo
- gitRepo 볼륨은 emptyDir base이고, 파드가 시작되면 깃 레포를 복제하여 데이터를 채운다.
- 볼륨이 생성된 후에 참조하는 레포지터리와 동기화되지 않는다. 파드가 삭제되고 새 파드가 생성되면 그 파드는 최신 커밋을 포함하게 된다.
- 파드가 삭제되면 볼륨과 콘텐츠는 모두 삭제된다.
[3] Host Path
- hostpath 볼륨은 노드 파일 시스템의 특정 파일이나 디렉토리를 가리킨다. (persistent storage)
- gitrepo, emptyDir 볼륨의 콘텐츠는 파드가 종료되면 삭제되지만, hostpath 볼륨의 콘텐츠는 삭제되지 않는다.
- 이전 파드와 동일한 노드에서 새롭게 스케줄링되는 새로운 파드는 이전 파드가 남긴 모든 항목을 볼 수 있다.
- 노드의 로그 파일이나 kubeconfig(쿠버네티스 구성 파일), CA 인증서를 접근하기 위한 데이터들을 hostpath로 구성되어있다.
[4] GCE PersistentDisk
- 파드에서 실행중인 애플리케이션이 디스크에 데이터를 유지해야 하고 파드가 다른 노드로 재스케줄링된 경우에도 동일한 데이터를 사용해야 하는 경우에 필요하다.
apiVersion: v1
kind: Pod
metadata:
name: mongodb
spec:
volumes:
- name: mongodb-data
gcePersistentDisk: # 볼륨의 유형은 GCE 퍼시스턴트 디스크 이외에도 awsElasticBlockStore, azureFile, azureDisk, NFS 등 사용
pdName: mongodb
fsType: ext4 # 리눅스 파일시스템 유형
containers:
- image: mongo
name: mongodb
volumeMounts:
- name: mongodb-data
mountPath: /data/db # 컨테이너 내 마운트 되는 path
ports:
- containerPort: 27017
protocol: TCP- 쿠버네티스에 앱을 배포하는 개발자는 어떤 종류의 스토리지 기술이 사용되는지 알 필요 없어야 하고, 동일한 방식으로 파드를 실행하기 위해 어떤 유형의 물리 서버가 사용되는지 알 필요 없어야한다. 즉, 파드의 볼륨이 실제 인프라스트럭처를 참조한다는 것은 쿠버네티스가 추구하는 방식이 아니다.
[5] PV(Persistent Volume) && PVC(Persistent Volume Claim)
- 인프라스트럭처의 세부 사항을 처리하지 않고 앱이 스토리지를 요청할 수 있도록 하기 위한 리소스 유형
- 관리자는 네트워크 스토리지 유형을 정하고, PV 디스크립터를 게시하여 PV를 생성한다.
- 사용자는 PVC를 생성하면, 쿠버네티스가 적당한 크기와 접근모드의 PV를 찾아서 PVC를 PV에 바인딩시킨다.
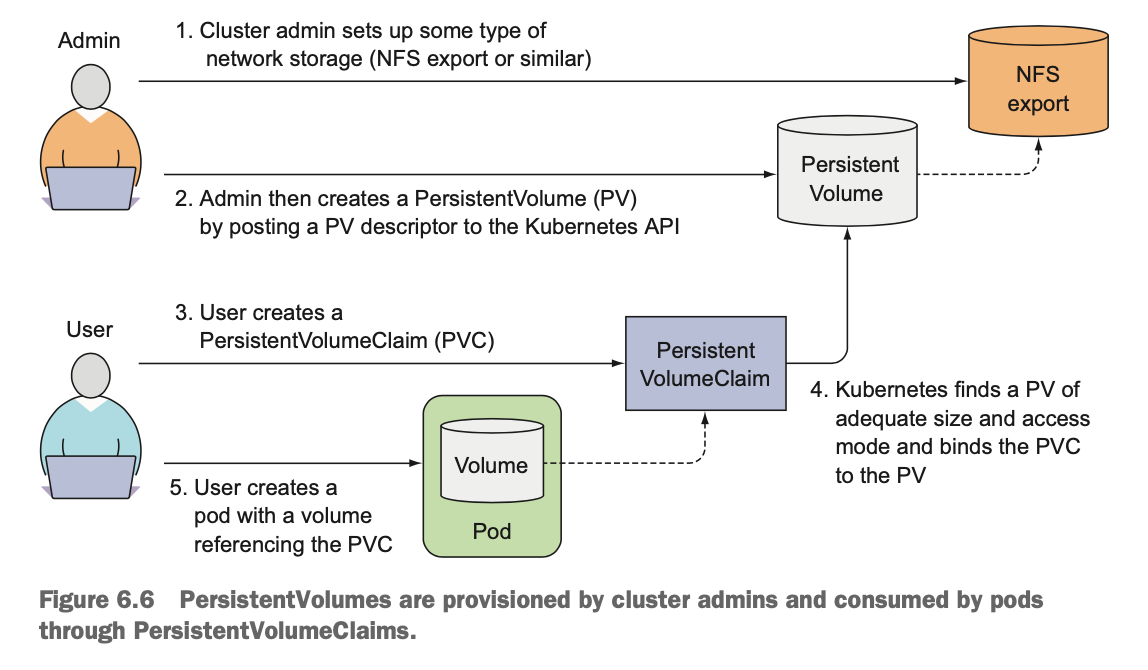
apiVersion: v1
kind: PersistentVolume
metadata:
name: mongodb-pv
spec:
capacity:
storage: 1Gi
accessModes:
- ReadWriteOnce # 단일 클라이언트의 읽기/쓰기용으로 마운트
- ReadOnlyMany # 여러 클라이언트의 읽기 전용으로 마운트
persistentVolumeReclaimPolicy: Retain # 클레임이 해제된 후 퍼시스턴트볼륨을 유지한다. (이 외에도 delete, recycle)
hostPath: # ohstPath 볼륨 (minikube)
path: /tmp/mongodb
# by adminapiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: mongodb-pvc
spec:
resources:
requests: # 1GiB의 스토리지를 요청
storage: 1Gi
accessModes:
- ReadWriteOnce # 단일 클라이언트를 지원하는 읽기/쓰기 스토리지
storageClassName: ""
# by user 1 stepapiVersion: v1
kind: Pod
metadata:
name: mongodb
spec:
containers:
- image: mongo
name: mongodb
volumeMounts:
- name: mongodb-data
mountPath: /data/db
ports:
- containerPort: 27017
protocol: TCP
volumes:
- name: mongodb-data # 파드 볼륨에서 이름으로 퍼시스턴트볼륨클레임을 참조
persistentVolumeClaim:
claimName: mongodb-pvc
# by user 2 stepPVC의 장점
- 개발자가 직접 인프라스트럭처에서 스토리지를 가져오는 방식보다는 PV + PVC를 통해 직간접적으로 가져오는 방식이 더 간단하다. (개발자가 인프라스트럭처 상세 내용을 몰라도 됨)
- 동일한 파드와 PVC 메니페스트는 인프라스트럭처와는 관련된 어떤 것도 참조하지 않으므로 (PV만 참조), 다른 쿠버네티스 클러스터에서도 그대로 사용할 수 있다.
- PVC는 x만큼의 스토리지가 필요하고, 한 번에 하나의 클라이언트에서 읽기와 쓰기만 할 수 있어라고만 명시하면된다.
PV의 재사용
- persistentVolumeClaimPolicy를 Retain으로 설정하면 PVC가 해제되더라도 데이터가 남아있으면 상태가 Avaliable로 풀리지 않는다.
- 다른 리클레임 정책인 Recycle과 Delete가 있는데 Recycle은 볼륨의 콘텐츠를 삭제하고 다시 클레임될수 있도록 만드는 옵션이다.
- Delete 정책은 쿠버네티스에서 퍼시스턴트볼륨 오브젝트와 외부 인프라(예: AWS EBS, GCE PD, Azure Disk 또는 Cinder 볼륨)의 관련 스토리지 자산을 모두 삭제한다.
- Recycle과 Delete의 차이는 pvc가 삭제될때 pv까지 삭제하느냐 안하느냐에 대한 차이가 있음(Delete는 pvc를 삭제하면 pv까지 삭제함)
[6] PV의 동적 프로비저닝
- 클레임을 생성하면 fast(사용자 정의) 스토리지 클래스 리소스에 참조된 프로비저너가 PV를 생성한다.
- PVC에서 존재하지 않는 스토리지 클래스를 참조하면 PV 프로비저닝은 실패한다.
- 이렇게 생성된 PV는 리클레임 정책 delete를 가지며, PVC가 삭제되면 PV도 삭제된다.
- 스토리지 클래스의 장점은 클레임이 클래스 이름으로 참조한다는 사실이다. 그래서 다른 클러스터에서 스토리지 클래스 이름을 동일하게 사용한다면 PVC정의를 다른 클러스터로 이식도 가능하다.
- storageClassName 속성을 빈 문자열로 지정하지 않으면 미리 프로비저닝된 퍼시스턴트볼륨이 있다고 할지라도 동적 볼륨 프로비저너는 새로운 퍼시스턴트볼륨을 프로비저닝한다.
- 미리 프로비저닝된 PV에 바인딩하기 위해서는 (미리 만들어둔 PV에 바인딩하려면) 명시적으로 storageClassName을 ""로 지정해야한다.
즉, 빈 문자열을 스토리지 클래스 이름으로 지정하면 PVC가 새로운 PV를 동적 프로비저닝하지 않고 미리 프로비저닝된 PV에 바인딩된다.
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: mongodb-pvc
spec:
storageClassName: fast # PVC는 사용자 정의 스토리지 클래스를 요청. 만약, 이름을 지정하지 않고(이 항목 존재 x) PVC 생성시 구글 쿠버네티스 엔진에서는 pd-standard 유형의 퍼시스턴트 디스크가 프로비저닝된다.
resources:
requests:
storage: 100Mi
accessModes:
- ReadWriteOncePV 동적 프로비저닝 플로우
- 클러스터 관리자는 퍼시스턴트볼륨 프로비저너를 설정하고, 하나 이상의 스토리지 클래스를 생성하고 기본값 정의
- 사용자는 스토리지클래스 중 하나를 참조해 PVC를 생성
- PVC는 스토리지클래스와 거기서 참조된 프로비저너를 보고 PVC로 요청된 접근모드, 스토리지 크기, 파라미터를 기반으로 새 PV를 프로비저닝하도록 요청
- 프로비저너는 스토리지를 프로비저닝하고 PV를 생성한 후 PVC에 바인딩한다.
- 사용자는 PVC를 이름으로 참조하는 볼륨과 파드를 생성
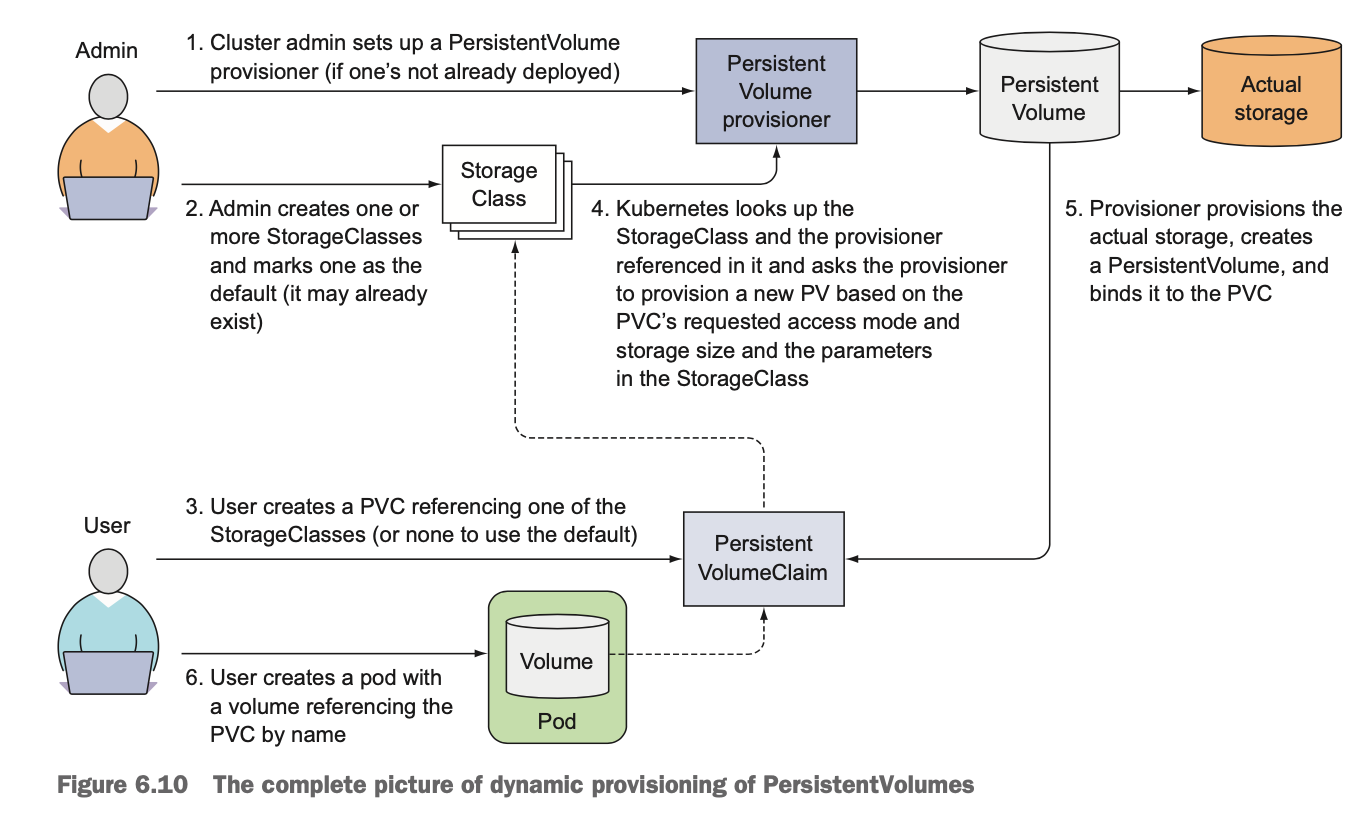
4. Config Map & Secret
- 빌드된 애플리케이션 자체에 포함되지 말아야 하는 설정[배포된 인스턴스별로(dev, stage, real) 다른 셋팅, 외부 시스템 엑세스를 위한 자격증명 등]이 필요하다. 쿠버네티스는 이런 앱을 실행할 때 설정 옵션을 전달할 수 있는 방법을 제공한다.
- 설정 데이터를 최상위 레벨의 쿠버네티스 오브젝트에 저장하고, 이를 기타 다른 리소스 정의와 마찬가지로 깃 저장소 혹은 파일 스토리지에 저장할 수 있다.
- 대부분의 설정 옵션에서는 민감한 정보가 포함돼있지 않지만 자격증명, 암호화키, 보안을 유지해야 하는 유사 데이터들도 있다. 이를 위한 시크릿이라는 또다른 유형의 오브젝트도 제공한다.
- 애플리케이션에 설정을 전달하는 방법에는 명령줄 인자로 전달하거나, 환경변수 설정(.yaml)으로 전달할 수 있다.
하드코딩된 환경변수의 단점
- 하드코딩된 값을 가져오는게 효율적일 수 있지만, 프로덕션과 개발환경의 파드를 별도로 정의해야할 수 있다.
- 즉, 여러 환경에서 동일한 파드 정의를 재사용하려면 파드 정의에서 '설정'을 분리하는 것이 좋다.
[2] 컨피그맵으로 설정 분리
- 환경에(local, alpha, real …) 따라 다르거나 자주 변경되는 설정 옵션을 애플리케이션 소스 코드와 별도로 유지하는 것
- 쿠버네티스에서는 설정 옵션을 컨피그맵이라 부르는 별도 오브젝트로 분리할 수 있다.
- 짧은 문자열에서 전체 설정 파일에 이르는 값을 가지는 키/값 쌍으로 구성된 맵이다.
- 파드는 컨피그맵 이름을 참조하여, 모든 환경에서 동일한 파드 정의를 사용하되 각 환경에서 서로 다른 설정을 사용할 수 있다.
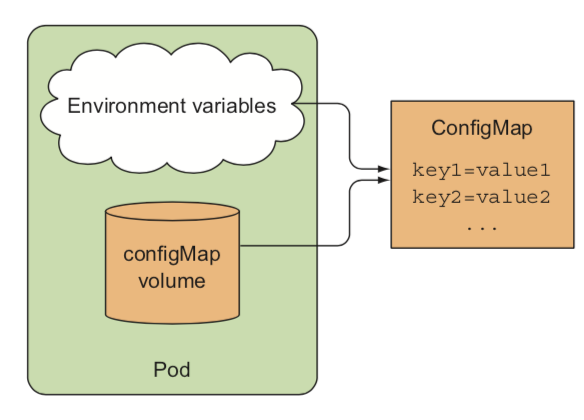
5. Statefulset
[1] 각각의 파드가 다른 PV와 맵핑하고 싶다면 어떻게 해야될까?
- 하나의 Replicaset에 묶인 각각의 파드는 host 이름, ip가 다른 stateless하게 구성된다. 이때 각각의 파드는 모두 같은 PVC에 맵핑되며 하나의 PV를 공유하게 된다. 이때, 각각의 파드는 어떻게하면 PV를 다르게 맵핑할 수 있을까?
- 하나의 replicaset이 아닌 여러개의 Replicaset으로 구성하는 방식이 있다. 이는 별도의 PV를 맵핑할 수 있지만 의도한 Replicaset 수를 변경할 수 없으며 사실 Replicaset을 사용한 이유가 없다.
- 모든 파드가 동일 PV를 사용하지만 볼륨 내부에서 파일 디렉토리를 분리하는 방법도 있다. 인스턴스 생성 시점에 다른 인스턴스가 사용하지 않는 디렉토리를 선정해야하는데, 인스턴스간 조정이 필요하고 올바르게 수행되지 않을 수도 있다.(동기화 이슈/ 병목현상)
[2] Replicaset vs Statefulset
Replicaset
- Stateless한 애플리케이션의 인스턴스는 이름을 정확히 알고 있을 필요가 없고 몇개가 있는지만 중요하다. 언제든 완전히 새로운 파드로 교체되어도 된다.
Statefulset
- 각 인스턴스에 이름을 부여하고 개별적으로 관리한다.
- Stateful한 파드가 종료되면 새로운 파드 인스턴스는 교체되는 파드와 동일한 이름, 네트워크 아이덴티티, 상태 그대로 다른 노드에서 되살아나야 한다. 또한, 각 파드는 다른 파드와 구별되는 자체 볼륨셋을 가진다.(PV)
- 새로운 파드 교체시 완전히 무작위가 아닌 예측가능한 아이덴티티를 가진다.
[3] Replicaset이란?
statefulset은 애플리케이션의 인스턴스가 각각 안정적인 이름과 상태를 가지며 개별적으로 취급해야하는 애플리케이션에 알맞게 만들어졌다.
- 스테이트풀셋으로 생성된 파드는 서수인덱스(0부터시작해서 N-1까지 할당)가 할당되고 파드 이름, 호스트 이름, ip, 안정적인 스토리지를 붙인다. 즉, 각각의 파드가 누구인지 알며(인덱스 덕분) 스케이 업/다운시 예측 가능한 파드가 제거된다.
- 스테이트풀셋은 레플리카셋이 하는 것과 비슷하게 새로운 인스턴스로 교체되도록 한다. 하지만 교체되더라도 이전에 사라진 파드와 동일한 호스트 이름을 갖는다. 그렇기 떄문에 파드가 다른 노드로 재스케줄링되더라도 같은 클러스터 내에서 이전과 동일한 호스트 이름으로 접근이 가능하다.
- 스테이트풀셋의 스케일 다운의 좋은 점은 항상 어떤 파드가 제거될지 알수 있다는 점이다. 이때 스테이트풀셋의 스케일 다운은 항상 가장 높은 서수 인덱스의 파드를 먼저 제거한다.
- Statefulset 파드들은 각각 별도의 PVC/PV가 맵핑되며 스토리지는 영구적으로 저장된다. 이는 DB와 같은 구조에서 사용될 수 있다. 스케일 다운시 파드는 삭제되지만 PVC 클레임은 남겨둔다. 클레임이 삭제된 후 바인딩됐던 PV를 재활용되거나 콘텐츠를 쉽게 복구할 수 있기 때문이다.

성장하는 개발자가 되고싶어요