1. Kubernetes가 나온 배경
- 몇 년 전만 해도 애플리케이션은 거대한 모놀리틱 시스템이었다. 업데이트가 자주 되지 않아 릴리스 주기가 느리고, 개발자는 개발 후 패키징 파일을 운영팀에게 넘기면, 운영팀이 이를 배포 후 모니터링 했다. 이후 운영팀은 하드웨어 장애가 발생하면 이를 사용 가능한 다른 서버로 마이그레이션 했다.
- 많은 서비스들이 Micro Service로 전환하면서 독립 개발 환경 구성, 잦은 배포, 수평 확장이 더욱 필요해졌다. 당연히 시스템에 배포 가능한 앱 구성 요소가 많아짐에 따라 시스템 관리자가 모든 구성 요소를 관리하는건 어려워졌다. 반면 잦은 배포가 필요해지면서 개발자는 시스템 관리자의 도움 없이 쉽게 배포도 필요해졌다.
- 즉, 개발자가 운영팀의 도움 없이 자신의 앱을 원하는 만큼 자주 배포하고 싶고, 운영팀은 하드웨어 장애 시 앱을 자동으로 모니터링 하면서 스케줄링을 통해 인프라를 쉽게 제어하고 싶어졌다.
2. Kubernetes가 뭐지?
- 컨테이너를 관리하는 S/W로, 개발자가 쿠버네티스에게 시스템이 의도하는 상태를 선언적으로 알려주고, 쿠버네티스가 실제 현재 상태를 지속적으로 검사해 의도한 상태로 조정한다.
- 클러스터에 노드가 몇개 있든 중요치 않고, 쿠버네티스에 앱을 배포하는 것은 항상 동일하며,(앱마다 상이한 케이스를 줄여줌) 클러스터 노드를 추가하는 것은 단순히 배포된 앱이 사용 가능한 리소스 양(cpu, memory, disk etc)을 추가한다는 의미다. 이때 기본 철학은 애플리케이션들이 어떤 노드에 배치되는지는 중요치 않다.
- 개발자가 원하는 상태를 '선언형'으로 나타내면, 쿠버네티스가 자체적으로 선언한 명령대로 스스로 관리된다. 따라서 개발자는 앱의 실제 기능을 구현하는데 집중하고, 앱을 인프라와 통합하는데 시간을 낭비하지 않는다.
3. Kubernetes의 장점
- 모놀리틱 서비스는 일부만 변경해도 전체 컴포넌트를 배포해야 되는데, 잘개 쪼개진 MSA에선 필요한 부분만 배포하면 된다. 쿠버네티스는 잘게 쪼개진 서비스를 쉽게 관리할 수 있어, 개발자는 쉽게 배포할 수 있다.
- 사용 가능한 리소스에 따라 스케줄링하여 하드웨어 활용도가 높은 노드로 선정하며, 노드 장애시 자동으로 실행 가능한 다른 노드로 대체하여 운영팀은 새벽 근무가 필요 없어진다. 또한 트래픽이 급증했을 때도 auto scaling하여 지속적인 모니터링이 필요없어졌다.
- 새로운 버전으로 업데이트할 때도 유용한다. 이전에는 운영중인 서버를 잠시 다운하고, 새로운 버전의 앱을 키는 과정을 점진 배포로 '수동'으로 했지만 쿠버네티스가 자동으로 컨테이너를 끄고 -> 교체 -> 키는 과정으로 배포 중 다운 없이 처리하게한다. 즉, '수동'이 아닌 '자동'으로 무 중단 업데이트를 제공한다.
- 컨테이너 기반이기 때문에 local, dev, real 등 개발환경 셋팅이 간편하다.
4. Kubernetes 구성요소
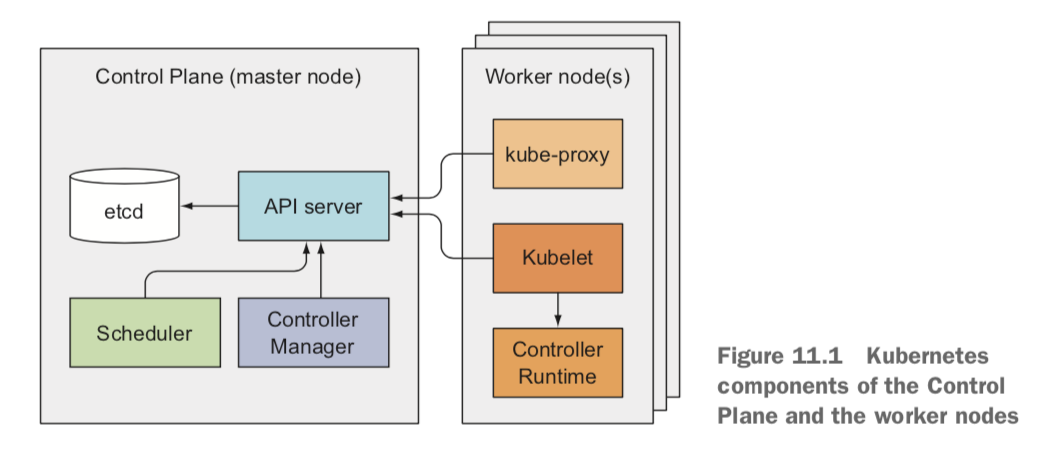
Master Node
- etcd
- scheduler
- api server
- controller manager
Worker Node
- kube-proxy
- kublet
- controller runtime
Master Node, Worker Node
- Master Node는 쿠버네티스 시스템을 관리하는 Controller Plain 역할로, 클러스터 상태를 저장하고 관리하는 요소이다. 이는 컨테이너를 직접 실행하지는 않는다. 반면 Worker Node에서 실제 컨테이너를 실행한다.
ETCD 저장소
- 쿠버네티스 오브젝트는 api 서버가 다시 시작되거나 실패하더라도 유지하기 위해 영구 저장이 필요하다. 이를 위해 쿠버네티스는 클러스터의 상태와 메타 데이터를 저장할 고가용성 구조를 가진 key/value 형태의 etcd 저장소를 사용한다.
API Server
- API 서버는 다른 모든 구성 요소 및 클라이언트와 '직접' 통신한다. worker node의 kubelet을 통해 클러스터로 요청이 오면 '인증' -> '인가' -> '컨트롤 플러그인' -> etcd 저장 및 클라이언트에 반환하는 작업을 처리한다.
- 여기서 말하는 인증이란 요청을 보낸 클라이언트를 인증함을 말하며, 인가는 인증된 사용자가 요청한 작업이 요청한 리소스를 대상으로 수행할 수 있는지 판별한다. 컨트롤 플러그인은 리소스 변경정책을 확인한다. 예를 들어 파드가 배포될 때마다 이미지를 강제로 가져오는 정책이 있다.
- object가 갱신되면 api 서버는 etcd 정보를 (리소스 변경시 etcd 데이터가 업데이트됨) 참조해 클라이언트들에게 갱신된 정보를 전달한다. 즉, api 서버는 리소스 정보를 etcd에 저장하고, 변경 사항을 클라이언트에 통보하는 것 외에 다른 일을 하지 않는다.
Scheduler
- API 서버의 감시 매커니즘(변경 정보를 etcd에 업데이트하고, 쿠버네티스 리소스와 같은 클라이언트에게 이를 알림)을 통해 새로 생성될 파드를 기다리다, 할당된 노드가 없는 새로운 파드를 노드에 할당만하면된다.
- H/W 리소스, 라벨, 볼륨 마운트 등 여러가지를 고려하여 스케줄링한다.
Controller Manage
- 리소스는 클러스터에 어떤 것을 실행해야 하는지 기술하는 반면, 컨트롤러 매니저는 배포된 리소스에 지정한대로 시스템을 원하는 상태로 수렴되도록 다른 '활성' 구성요소이다. replica, deployment, statefulset, service, volumn 등 여러가지 리소스가 있으며, 이를 컨트롤러 매니저가 관리한다.
- 어떤 컨트롤러도 kubelet과 직접 통신하지 않고, api 서버와 통신하며 리소스 정의와 현 상태를 비교하며 object를 제어한다.
Kubelet
- 워커 노드에서 실행하는 모든 것을 담당하는 구성요소이다.
- kubelet이 실행중인 노드를 노드 리소스로 만들어서 api 서버에 등록한다. 이후 api 서버를 지속적으로 모니터링해 해당 노드에 파드가 스케줄링되면, 파드의 컨테이너를 시작한다. 이후 설정된 컨테이너 런타임(docker)에 지정된 컨테이너 이미지로 컨테이너를 실행하도록 지시한다. 이후 실행중인 컨테이너를 계속 모니터링하면서 상태, 이벤트, 리소스 사용량을 api 서버에게 보고한다.
5. 고가용성 클러스터
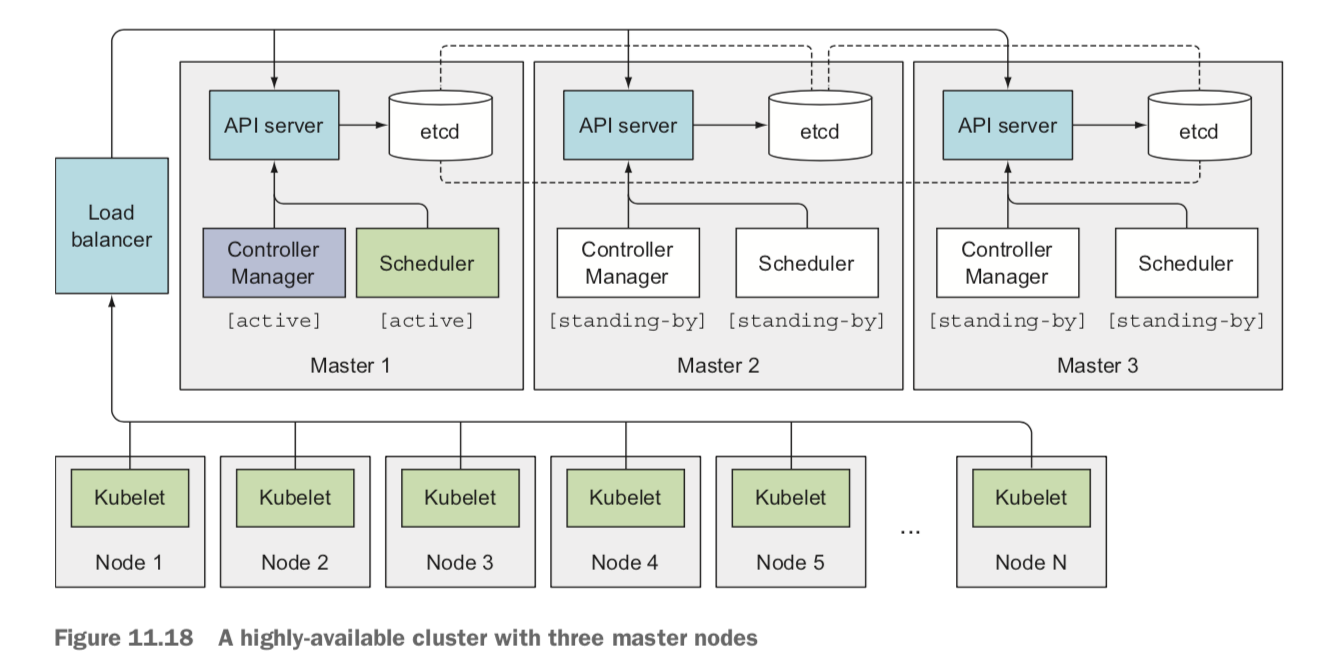
- 애플리케이션의 고가용성을 위해, 디플로이먼트 리소스로 애플리케이션을 실행하고 적절한 수의 레플리카를 설정한다.
- 애플리케이션 수평확장이 힘들더라도, 레플리카 수를 1로 선정해야하는데 이는 문제 발생시 자동으로 재시작하기 때문이다. 하지만 파드 교체시 짧은 중단 시간이 발생하는데 이는 어쩔 수 없다.
- 짧은 중단 시간을 방지하고자 활성/비활성 복제본을 두고 처리하기도 한다. 단 하나만 활성 상태에 두다, 문제시 비활성 복제본을 사용하는 방법도 있다.
6. Kubernetes 애플리케이션 실행
- 앱을 하나 이상의 컨테이너 이미지로 패키징하고, 해당 이미지를 이미지 레지스트리로 푸시한다. 이후 디스크립션 파일에 어떤 이미지를 불러오고, 구성요소(리소스), 구성요소간 통신 방법 등이 담긴 정보를 쿠버네티스 API 서버로 전송한다.
- 먼저 API 서버가 디스크립션 파일을 읽는다. 이후 스케줄러에 의해 각 컨테이너에 필요한 리소스를 계산하고 워커노드에 각각의 컨테이너를 할당한다.
- 지정받은 워커 노드의 kubelet은 컨테이너 런타임에 필요한 이미지를 이미지레지스트리로부터 가져와 컨테이너를 실행하도록 지시한다.
- 앱이 실행되면 쿠버네티스는 애플리케이션의 실행 상태가 사용자가 제공한 디스크립션 내용과 일치하는지 지속적으로 확인한다. 예를 들어, 워커 노드가 중단되거나 특정 컨테이너가 이상이 있을 경우 해당 노드/컨테이너를 재스케줄링한다.
- 애플리케이션이 실행되는 동안 복제본 수를 늘릴지 줄일지를 결정할 수 있고, 이 작업은 쿠버네티스에 맡겨 cpu 부하/메모리 사용량, 초당 요청 수 등을 고려해서(디스크립션에 지정) 자동으로 조정할 수 있다.

성장하는 개발자가 되고싶어요