1. Kubernetes 리소스 구조
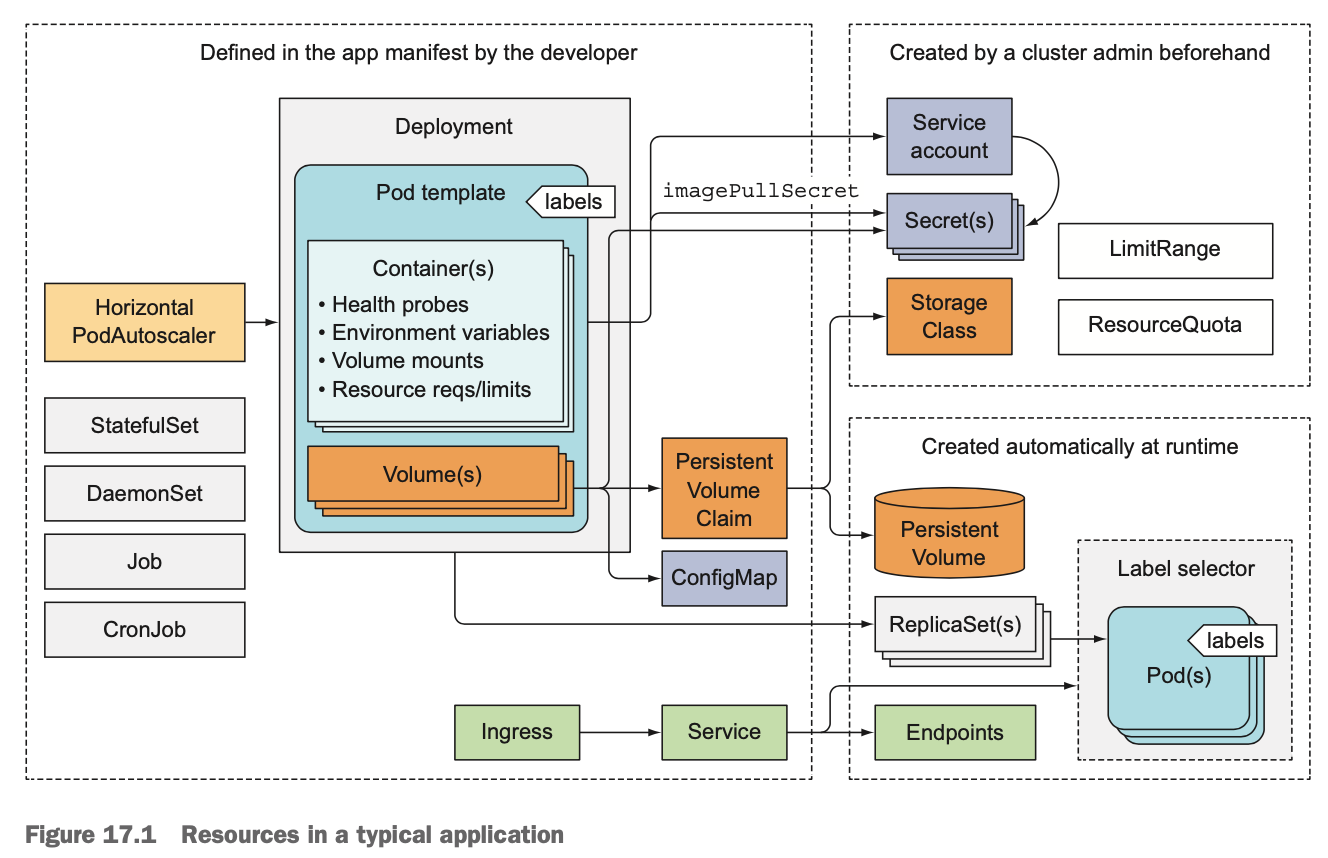
- Horizontal PodAutoScaler에 의해 트래픽이 늘어나거나, 시스템 리소스 사용량이 증가하면 유동적으로 파드를 늘린다. 이후 사용량이 줄어들면 파드 일부를 제거하기도한다.
- Deployment를 통해 무중단 배포가 가능하며, 이 과정에서 ReplicaSet을 활용한다.
- Pod Template에서 readness probe를 통해 health-check를 수행한다. 이를 통해 준비되지 않은 파드가 요청을 처리하는 불상사를 방지한다.
- confingmap 및 secret을 통해 환경변수 및 보안 요소를 처리한다.
- PVC, PV를 통해 디스크에 데이터를 유지하기도 한다.
- stateless한 파드, stateful한 파드를 구별하여 이전 상태를 유지하기 위해 statefulset 리소스를 활용하기도한다.
- Daemonset, Job, CronJob을 통해 주기적으로 실행해야되는 Job들을 처리한다.
- ResourceQuota, LimitRange를 활용하여 cpu, memory, 요청 수에 따라 파드를 늘리거나/ 줄이는 등 사용량을 제어할 수 있다.
- 외부 요청을 처리하기 위해 Ingress, Service 리소스를 활용한다. 파드는 지속적으로 ip 주소가 변경되는데, 외부에 변경되지 않는 public ip 주소를 노출한다.
- 쿠버네티스 내의 리소스를 체계적으로 유지하기 위해 하나 이상의 레이블을 지정하기도 한다.
2. Pod Lifecycle
- 파드에서 실행 중인 애플리케이션은 언제든지 종료될 수 있기 때문에 이를 고려해야 한다.
- OOMKiller와 같은 크래시 등 다양한 이유로 컨테이너가 재시작될 수 있다. 이 경우 파드는 동일하지만 컨테이너 자체는 완전히 새로운 것이 된다. 컨테이너를 다시 사용하더라도 데이터를 보존하기 위해 최소한 파드 범위 이상의 볼륨을 사용하길 권장한다.
- 파드의 컨테이너가 계속해서 크래시 되면 kubelet은 최대 5분까지 파드를 재시작한다. 파드는 계속 CrashLoopBackOff 상태가 표시되고, 레플리카수와 레플리카가 일치하기 때문에 컨트롤러는 별도의 조치를 하지 않는다. 즉, 요청을 처리하지 않는 파드가 계속 띄어져 있다. 그러면 어떻게 해야할까? CrashLoopBackOff 관련 알람을 설정하고, 알람이 왔을 때 조치를 취하거나 예를 들어 재시작하거나 혹은 로그를 보고 문제있는 부분을 수정하면된다. 근데 로그를 따로 보관하지 않고 컨테이너단의 로그를 저장하면 아마 컨테이너 재시작시 해당 로그는 사라질 것이다. ㅠ
3. Init Conatainer
- 파드의 주 컨테이너를 구동시키기 전에 초기화하는 것을 목적으로 사용한다.
- 파드는 여러 개의 초기화 컨테이너를 가질 수 있고, 이는 순차적으로 실행되며 마지막 컨테이너가 완료된 후에 주 컨테이너가 시작된다. 이를 통해 파드A와 파드B가 있을때 파드B의 초기화 컨테이너에서 A의 구동을 기다리도록 한다면 파드 A,B의 구동 순서를 보장할 수 있다. 예를 들어, A -> B 파드 순으로 실행해야된다면, A 파드 주 컨테이너 구동 전 init-container로 B 파드에게 curl을 날려 응답이 정상일 때 까지 기다리는 방법도 있다.
- 물론 애플리케이션이 시작되기 전 준비 상태가 되기 위해 의존해야 할 서비스를 필요로 하지 않도록 애플리케이션을 만드는 것이 가장 좋다. 하지만 애플리케이션 의존성이 있다면 이를 위해 레디니스 프로브를 통해 의존성이 완료되어 정상 응답을 줄수 있을때 서비스에 투입되도록 하는것이 바람직하다.
4. 모든 클라이언트 요청의 적절한 처리 보장
- 파드의 스케일업과 스케일다운 과정 중에 모든 클라이언트 요청이 올바르게 처리되어야 할 것이다. 이를 위해서는 연결이 끊어지지 않도록 애플리케이션에서 몇 가지 규칙을 잘 따라야 한다.
- 파드 스펙에 레디니스 프로브를 지정하지 않으면 곧바로 파드는 항상 준비된 것으로 간주되기 떄문에 이를 필수적으로 지정해야 한다. 레디니스 프로브에서는 요청을 올바르게 처리할 준비가 됐을 때에만 레디니스 프로브가 성공을 반환하도록 해야 한다.
- 파드 제거가 필요할 경우 pod를 stop하고 kube-proxy에서 삭제할려는 pod ip를 iptables에서 제거한다. 하지만 파드에 종료 신호를 보낸 후에도 클라이언트의 요청을 받을 수 있어 (iptables에서 아직 삭제되지 않거나 혹은 캐시 정책도 있을 수 있고), Connection Refused 에러가 발생할 수 있다. 따라서 파드 종료 요청을 보낸 후, iptables에서 제거 시간을 고려하여 파드 종료 요청 후 5~10초 후에 파드를 종료한다. (아마 자체적으로 처리되있을 것이다.)
5. 애플리케이션을 쉽게 실행하고 관리
- 이미지를 만들때 OS 배포판의 모든 파일을 다 넣을 필요는 없다. 다 넣을 경우 파드가 노드에 처음 스케줄링할 때 필요 이상으로 대기해야 하는 경우가 생길 수 있다. (컨테이너 레지스트리에서 이미지 다운로드 시간이 증가할 수 있기 때문) 따라서 불필요한 것이 없는 작은 이미지로 만드는 것이 중요하다.
- 하지만 최소한의 이미지로는 디버깅이 어렵기 때문에 컨테이너 내에 ping,dig, curl 또는 이와 유사한 도구 등은 이미지에 포함시켜주는 것이 좋다.
- 파드 매니페스트에서 latest 태그를 참조하면 개별 파드 레플리카가 실행중인 이미지 버전을 알 수 없기 떄문에 이를 사용해서는 안된다. 그렇다고 imagePullPolicy가 always일 때는 새 파드가 배포될 떄마다 커네이너 런타임이 이미지 레지스트리에 접속해서 이미지를 가져와야 해서 파드 시작 속도가 약간 느려질 수 있다. 그리고 혹시 레지스트리에 연결할 수 없는 상황에서는 파드를 시작할 수 없게 된다. 결론은 상황에 맞게 잘 판단하자.(?)
- 최소한 리소스에는 리소스를 설명하는 어노테이션과 담당자 연락처 정보가 포함된 어노테이션을 포함시켜주는 것이 좋다.
- 컨테이너가 왜 종료되었는지를 추적하는 일은 무언가 해놓지 않았다면 굉장히 추적이 어렵다. 그렇기 때문에 로그 파일에 필요한 모든 디버그 정보를 포함시켜두는 것이 좋다. pod > yaml -> terminationMessagePath
- 파드로 각각 분리되있기 때문에 이를 합칠 방법이 필요하다. ELK 스택을 활용한다. ElasticSearch, LogStash, Kibana로 구성된 ELK 스택 또는 EFK 스택(ElasticSearch, FluentD, Kibana)을 통해 중앙 집중식 로깅을 활용하자.
끝

성장하는 개발자가 되고싶어요