1. Loging
[1] Logging이란
- 배포 환경에서 동작 상태를 확인하기 위해 로깅이 필요하다. 로깅이란 프로그램 동작시 발생하는 모든 일을 기록하는 행위로, 서비스 동작상태 및 장애를 표현한다.
- I/O 작업 (Http 통신, DB 처리 등), Null Pointer Exception, Application 상태, 로직 에러 등이 있다.
- 로그를 기록하는 시점은 그때그때 다른데, 웬만하면 모두 남기는 것이 좋다. 다만 용도에 따라 level을 구분하여 남긴다.
- 실 서버 구동 같이 디버깅을 할 수 없는 상황에서는 로깅이 최선의 선택이다. 당연히 디버깅을 쓸 수 있다면 디버깅을 최대한 활용하는게 좋다.
- Log Level : Fatal(매우 심각한 에러로, 프로그램이 종료되는 경우) -> Error(프로그램이 종료되지 않지만, 의도치 않은 에러) -> Warn(에러가 될 수 있는 잠재적 가능성이 있으며, 지속적으로 중첩될 경우 문제가 되어 알람과 같이 수신한다.) -> Info(시스템 동작여부와 같이 정보를 확인하기 위해 사용) -> Debug -> Trace로 구성하며 환경(dev, alpha, stage, real)에 따라 로그 레벨을 달리 구성한다.
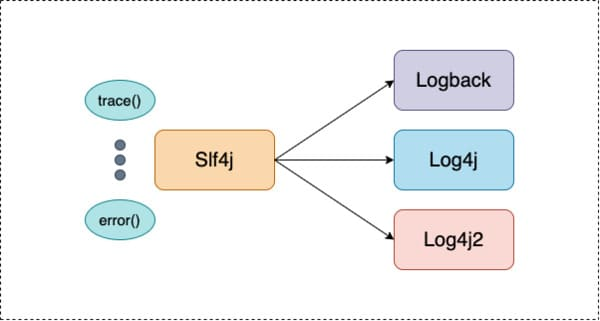
[2] SLF4J
- Simple Logging Facde For Java로 다양한 로깅 프레임 워크에 대한 추상화(인터페이스) 역할을 수행한다. 당연히 인터페이스니 단독으로 사용 불가능하고, 최종 사용자가 배포시 원하는 구현체를 선택해야한다. 구현체는 Logback, Log4J, java.util.logging 등이 있다.
- Client -> SLF4J API <- (Logback, LOG4J 등 다양한 구현체)로 구성
- 클라이언트는 SLF4J만 알면 되므로 구현체 컴포넌트의 변경 및 상세 코드 변경에 대한 파급효과가 없다.
[3] Logback 설정 요소
- local, dev, alpha, stage, real 등 배포 환경에 따라 다르게 설정할 수 있다.
- configuration : 최상위에 위치하며, 구성 파일을 묶어준다.
- logger
- 실제 로깅을 수행하는 구성요소로, 로그 객체를 등록한다.
- name : 이후 LogFactory에서 이 부분에서 설정한 값으로 가져온다.
- level : 로깅할 레벨을 지정한다.
- appender-ref : appender에서 설정한 name을 넣으면 해당 로그 메시지로 write한다.
- additivity : 상위 로거로부터의 상속 여부를 의미하며, default는 true(상속 o)이다.
- root
- loggerd의 네이밍에 맵핑이 안된 얘들은 모두 여길 탄다.
- appender
- 설정해 놓은 위치에 로그 메시지를 write한다. default는 동기적으로 처리한다.
- name : logger에서 호출할 이름
- class : appender 구현한 클래스
- ConsoleAppender : 콘솔에 로그 기록
- FileAppender : 지정된 파일에 로그 기록
- RollingFileAppender : file appender확장판으로, 한 곳에 파일을 지속적으로 write하면 부담이되어 용량, 날짜에 따라 파일을 분리하여 저장하며, 지정 주기로 파일을 삭제하기도 한다.
- SMTPAppender : 로그를 메일로 기록
- DBAppender : 디비에 로그 기록
- encoder pattern : 로그 출력할 패턴
- level : Log Level
- logger
- LogFactory
- logger에서 지정한 로그 객체를 불러온 후 로그를 기록한다. 즉, 로그 객체를 생성한다.
- @SLF4J로 로그를 기록하면 로거와 맵핑될 때 이름은 클래스 명으로 기록된다. 만약 logger에 맵핑되는것이 없다면 root로 기록된다.
2. Filebeat
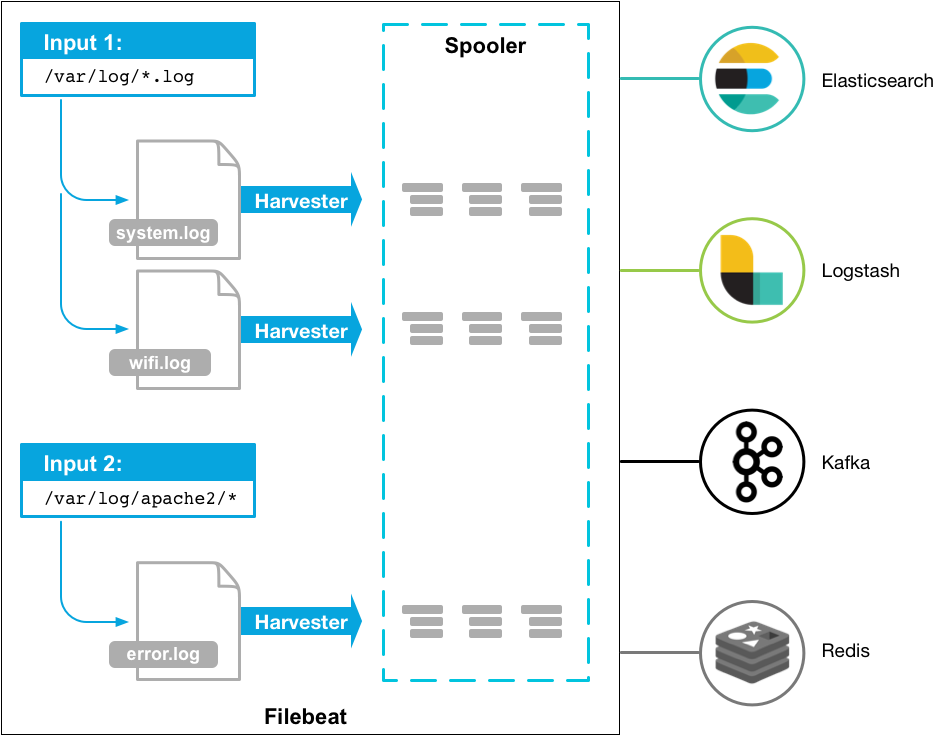
경량화된 로그 파일 수집기로, VM&컨테이너 등 호스트에 상관없이 로그(파일) 데이터를 수집 후 경량화된 방식으로 로그를 타겟서버로 전달하고 중앙 집중화 작업을 편리하게 만들어준다. 참고로 로그 같이 빠른시간내에 적재되는 데이터를 매번 보내는 것보다, 파일비트에 의해 보내는것이 더욱 효율적이다.
[1] 예시
- 모니터링하려는 각 시스템에 Filebeat 설치 후, 로그 파일의 위치를 지정한다.
- 이후 로그 데이터를 필드로 파싱하고 target(ES, hadoop 등)으로 전송한다.
- 즉, 설치한 파일비트는 사용자가 지정한 로그 파일이나 위치를 모니터링하고 로그 이벤트를(데이터 발생) 수집하여 인덱싱을 위해 ES, Hadoop 등으로 전달한다.
[2] 로직 상세
- 파일비트를 시작하면 내가 로그 데이터 위치를 들여보도록 등록해놓은 하나 또는 그 이상의 'input'을 시작한다.
- 파일비트가 찾은 각 로그에 대해 harvester를(데이터 수확기) 시작한다.
- 각 harvester는 새 컨텐츠에 대한 로그 '하나를' 읽고 새 로그 데이터를 'libbeat'로 전송하며,
- libbeat는 이벤트를 집계하고 지계된 데이터를 파일비트에 구성해 놓았던 'output'으로 전송한다.
3. Streamset
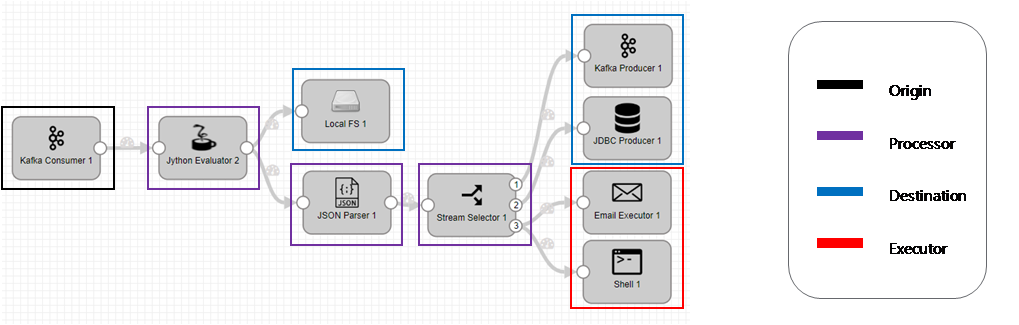
[1] Streamset이란
- 드래그앤드롭 방식으로 데이터 흐름을 관리하며, 파이프라인 생성으로 기능을 제정한다.
- 코드 작성을 최소화하며, 자동으로 인스턴스를 관리한다.
- 파이프라인을 시각화하며, 성능 및 이벤트를 모니터링할 수 있다.
[2] Component
- Origin : 파이프라인 내 시작점을 의미하며, 파이프라인 내 하나만 생성할 수 있다. kafka, redis, tcp 등 data 근원지로 활용가능하다.
- Processor : JSON Parster, Field Masker 등 데이터를 처리/가공하는 기능을 제공한다.
- Destination : 파이프라인 목적지로 Redis, DB, Local File 등에 사용된다.
- Executor : 이벤트를 수신했을 때 동작을 정의하며, Email Executor, Shell Executor 등의 기능을 제공한다.
4. Kafka
분산 이벤트 스트리밍 플랫폼
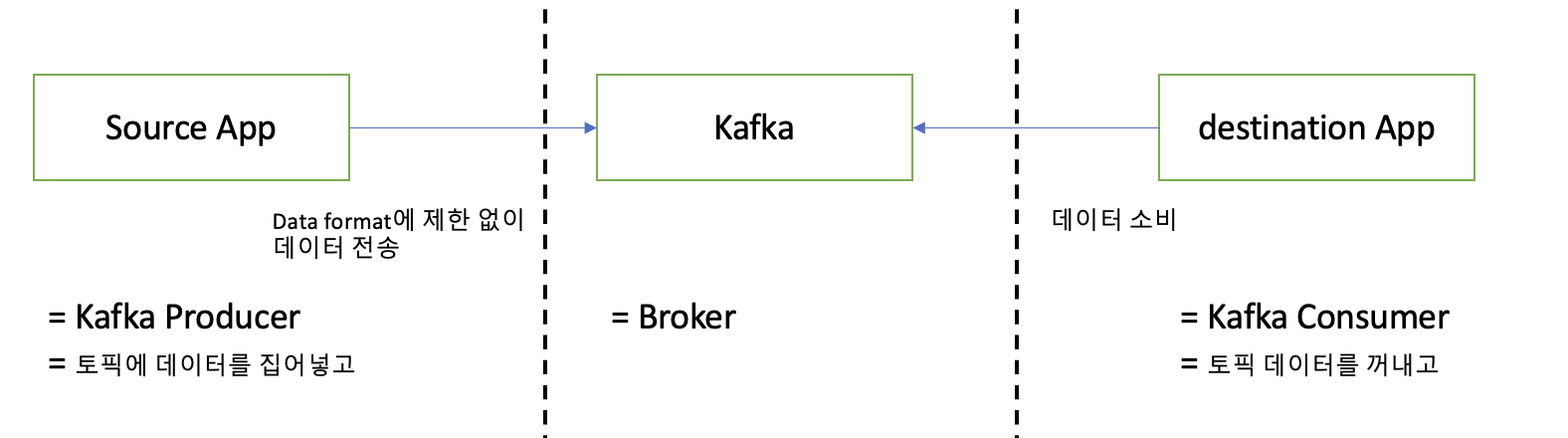
[1] Kafka 배경
- 기존 서비스에선 source -> destination application이 적어 전송라인이 복잡하지 않았다. 하지만 시간이 지나면서 application이 많아졌고, data 전송라인이 많아지면서 배포, 장애 대응이 힘들어졌다.
- 한 앱이 배포시 그와 연계된 서비스가 많아졌고 영향도가 높아지면서 '배포'가 고려할 상황이 늘어났고, 장애 대응시 연계된 서비스가 많아 어느 부분이 장애 포인트인지 파악이 힘들어졌다.
- Apache Kafka는 source와 destination 사이의 coupling(결합도)을 약하게 하기 위해 나왔다.
[2] 구조
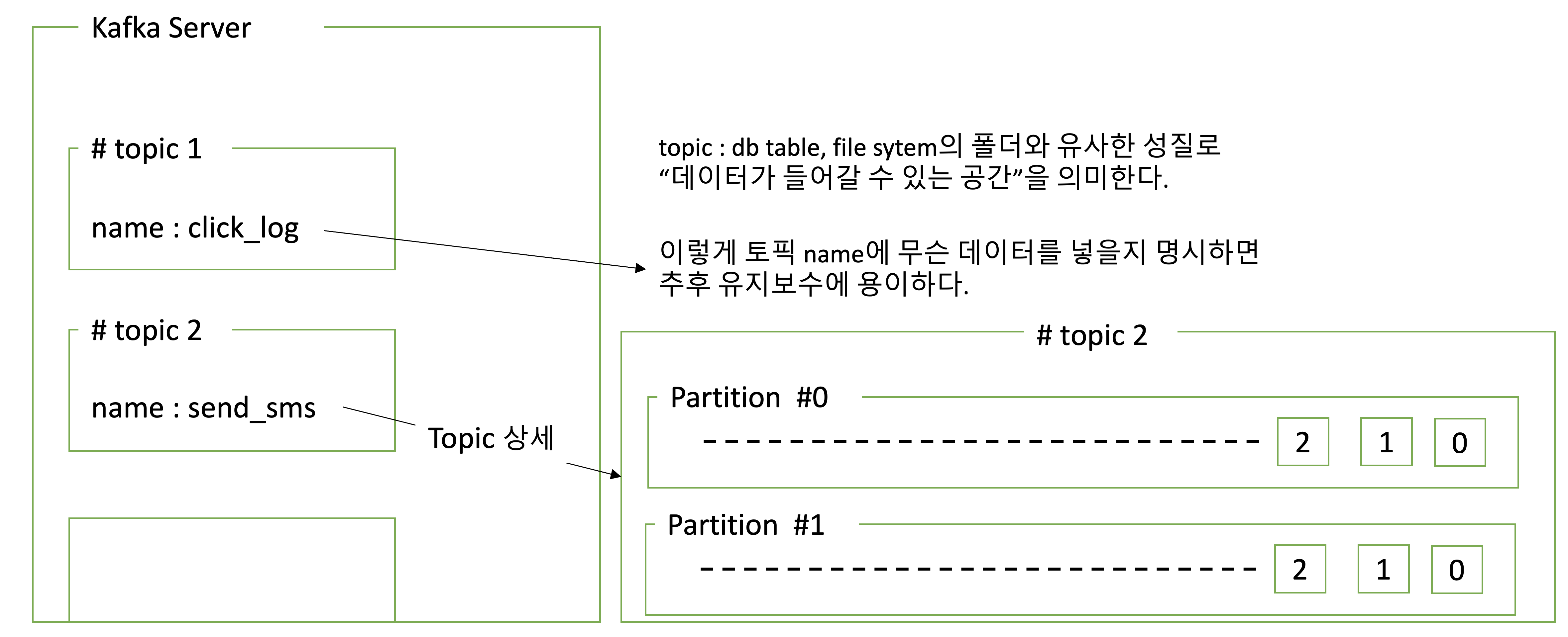
[3] 특징
- 복구가 가능하여 이슈 대응이 쉽고(Foult Tolerant가 용이), Latency 성능이 좋아 지연이 낮으며, Throughput이 좋아 높은 처리량을 갖는다. 즉, 데이터를 처리하기 매우 편리하다.
- 로그를 분석하고, 시각화하기 위해 ES에 저장하기도 하고, 로그를 백업하기 위해 하둡에 저장하기도 한다.
[4] partition
- 하나의 토픽에 여러개의 파티션을 구성할 수 있다.
- 하나의 파티션에 큐와 같이, 파티션 끝에서부터 차곡차곡 채워넣는다.
- consumer는 가장 오래된 순서부터 데이터를 가져간다.
- consumer가 토픽 내부 파티션에서 데이터를 가져가도, 데이터는 삭제되지 않는다. 파티션 안에 데이터는 그대로 남아있어, 동일 데이터를 여러번 처리(소비)할 수 있다. 즉, 복구에 용이하다.
- 새로운 consumer가 오면 다시 파티션 안에 0번 데이터부터 가져갈 수 있다. 단, consumer group이 달라야하며, auto.offset.reset=earliest 셋팅되어야 한다.
- 파티션 안에 데이터가 삭제되는 시기는 레코드가 저장되는 최대시간과 크기로 제어할 수 있다. 단, 파티션은 삭제 안되는데, 파티션 안에 데이터는 지정된 시간이 지나면 삭제된다.
- log.retention.ms : 최대 레코드 보존 시간
- log.retention.byte : 최대 레코드 보존 크기
- 파티션이 여러개면 데이터를 어느 파티션에 넣어야될까?
- key, value로 데이터를 보내는데, key가 null이고 기본 파티셔너를 사용할 경우 round robin(순차적)으로 파티션을 할당한다. 만약 key가 있고, 기본 파티셔너를 사용할 경우 key의 hash 값을 구하고 특정 파티션에 할당한다.
- key는 프로듀서가 메시지를 보내면 토픽의 파티션이 지정될 때 쓰인다.
- 파티션을 늘릴 수 있지만 줄일 수는 없으며, 토픽 안에 파티션을 늘리고 컨슈머 갯수를 늘려서 데이터 처리를 분산시킬 수 있다.
- 토픽에 파티션을 사용 중 중간에 추가하는 경우 해시를 쓰기 때문에 key, partition의 일관성이 깨진다. 따라서 key를 사용할 경우 초기 파티션 갯수 설정 후 추후에 변경하지 않음을 권장한다. -> 이전에 할당되던 파티션이 아닌 다른 파티션에 데이터가 할당 될 수 있다.
Partional
- 프로듀서가 데이터를 보내면 무조건 파티셔너를 통해서 브로커로 데이터가 전송된다. 파티셔너는 데이터를 토픽의 어떤 파티션에 넣을지 결정하는 역할이다. 이떄 레코드에 포함된 메시지 '키' 또는 '값'에 따라서 파티션의 위치가 결정된다.
- Uniformsticky Partitioner : 기본 옵션으로, 메시지 키 유무에 따라 다르게 동작한다.
- key 존재 o : 키가 같다면 동일한 해시 값을 만들기 때문에 항상 동일한 파티션에 들어가므로 '순서'를 보장한다.
- key 존재 x : 라운드 로빈으로 동작하며, 프로듀서에서 배치로 모을 수 있는 최대한의 레코드를 모아서 파티션으로 데이터를 전송한다. 파티션에 적절히 데이터를 분배한다.
- Partitional Interface를 사용해서 커스텀 파티셔너 클래스를 만들면 메시지 키 또는 값 또는 토픽 이름에 따라서 레코드를 어떤 파티션에 보낼지 결정할 수 있다. 예를 들어 VIP 고객의 데이터를 좀 더 빨리 처리하고 싶다면 '파티셔너'를 통해 처리량을 늘릴 수 있다. 기본적으로 10개의 파티션이 있다고 가정할 때 우리가 커스텀 파티셔너를 만들어서 8개의 파티션에는 VIP 고객의 데이터를 그리고 2개의 파티션에는 일반 고객의 데이터를 넣어 처리량을 제어할 수 있다.
[5] Kafka Producer
- 데이터를 카프카에 보내는(토픽 파티션에 데이터 생성) 역할로, 예를 들어 많은 양의 클릭 로그들을 대량으로 카프카에 적재할 때 사용한다.
- kafka broker로 데이터를 전송할 때 전송 성공 여부를 알 수 있고 실패할 경우 재시도한다.
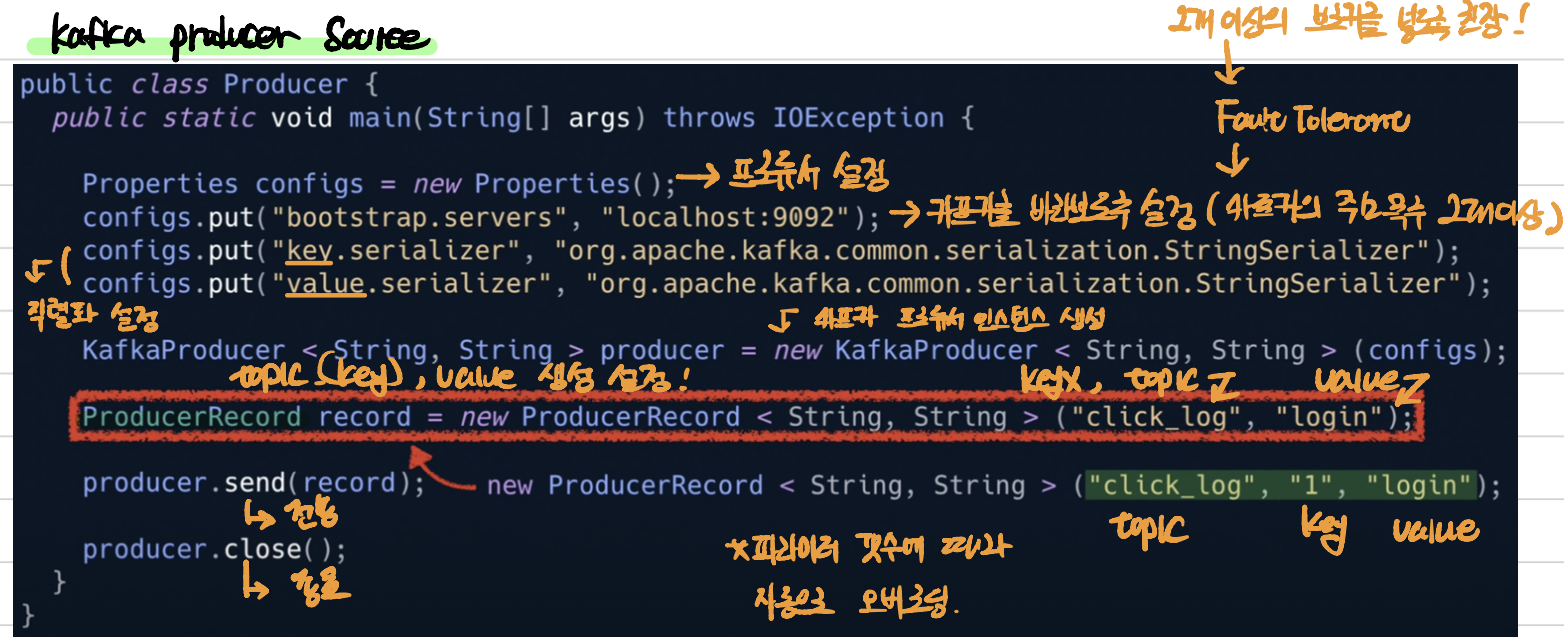
[6] 데이터 유실을 막기 위한 노력
- 용어
- Kafka Broker : 카프카가 설치되어 있는 서버 단위로, 보통 3개 이상의 브로커 사용을 권장한다.
- Replication : 파티션의 복제를 뜻하며, 브로커 갯수보다 작아야한다. 예를 들어 partition이 1, replication이 3이라면 partition은 원본 1개와(leader partition) 복제본 2개(follower partition)로 구성된다.
- 왜 replication을 쓸까?
- 갑자기 브로커가 어떠한 이유로 사용 불가하다면 복제본이 없다면 파티션 안에 적재된 데이터를 복제할 수 없다. 즉, follow partition이 leader partition 역할을 승계하여 '복구'할 수 있다. 여기서 리더 파티션은 프로듀서가 토픽의 파티션에 데이터를 전달할 때 전달받는 주체다.
- replication 갯수가 많아지면 그만큼 브로커 리소스 사용량도 늘어난다. 당연히 하나의 토픽에 저장된느 파티션이 많아지기 때문이다. 따라서 카프카에 들어오는 데이터 양과 retention date(저장시간)를 고려해서 지정하자. 보통 broker가 3개 이상일 때 replication은 3으로 설정을 권장한다.
- partition의 replication과 관련있는 'ACK' 옵션
- ACK 0 : 프로듀서가 리더 파티션에 데이터를 전송하고 응답값을 받지 않는다. 속도는 빠르지만 데이터 유실 가능성이 있다.
- ACK 1 : 프로듀서가 리더 파티션에 데이터를 전송하고 응답값을 받는다. 0보단 아니지만 약간의 데이터 유실 가능성이 존재한다.
- ACK 2 : 프로듀서가 리더 파티션에 데이터를 전송하고, 팔로워 파티션에 복제가 잘 이루어졌는지까지 응답을 받는다. 즉, 리더 파티션에 데이터를 보낸 후 나머지 팔로워 파티션에도 데이터가 저장되는 것을 확인한다. 다만, '0', '1'에 비해 체크하는게 많아 속도가 현저히 느리다.
[7] Kafka Consumer
- 카프카에서는 컨슈머가 데이터를 가져가더라도 데이터가 사라지지 않는다.
- 토픽의 파티션으로부터 데이터를 polling해서 가져간다.
- 데이터를 읽을 때 파티션의 offset 위치를 기록한다.
- offset : topic > partition > data의 고유 번호로, offset은 토픽별, 파티션 별로 별개로 지정된다.
- 즉, consumer가 데이터를 어느 지점까지 읽었는지 확인하는 용도로 사용된다.
- 파티션 갯수에 따라 컨슈머를 여러 개 만들면 병렬처리가 가능하기 때문에 빠른 속도로 데이터를 처리할 수 있다.
- 컨슈머가 파티션에서 데이터를 읽을때마다 offset을 commit하게 되는데, 이는 _consumer_offset 토픽에 저장된다.
- 만약 불의의 사고로 컨슈머가 실행이 중지되어도 offset 정보를 토픽에 기록해있어, 중지된 위치부터 다시 데이터를 읽을 수 있다.
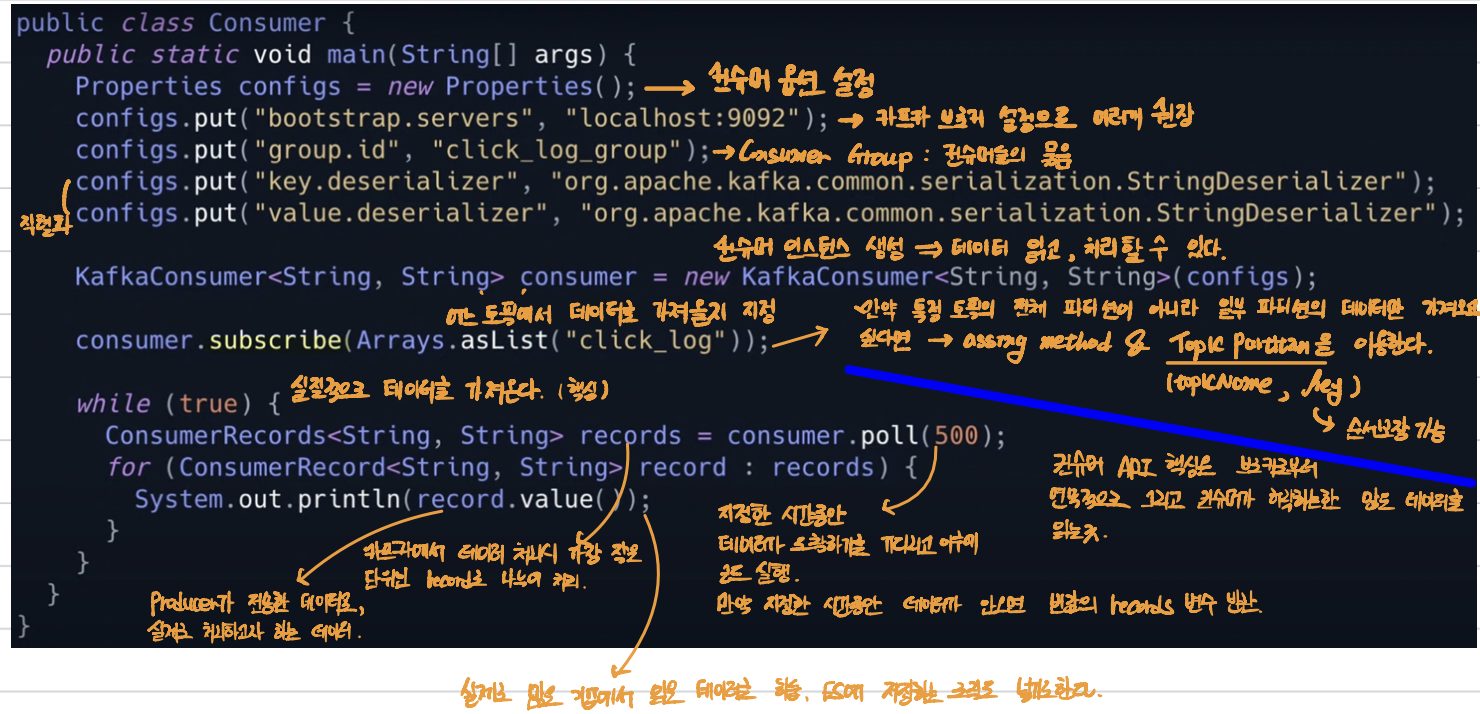
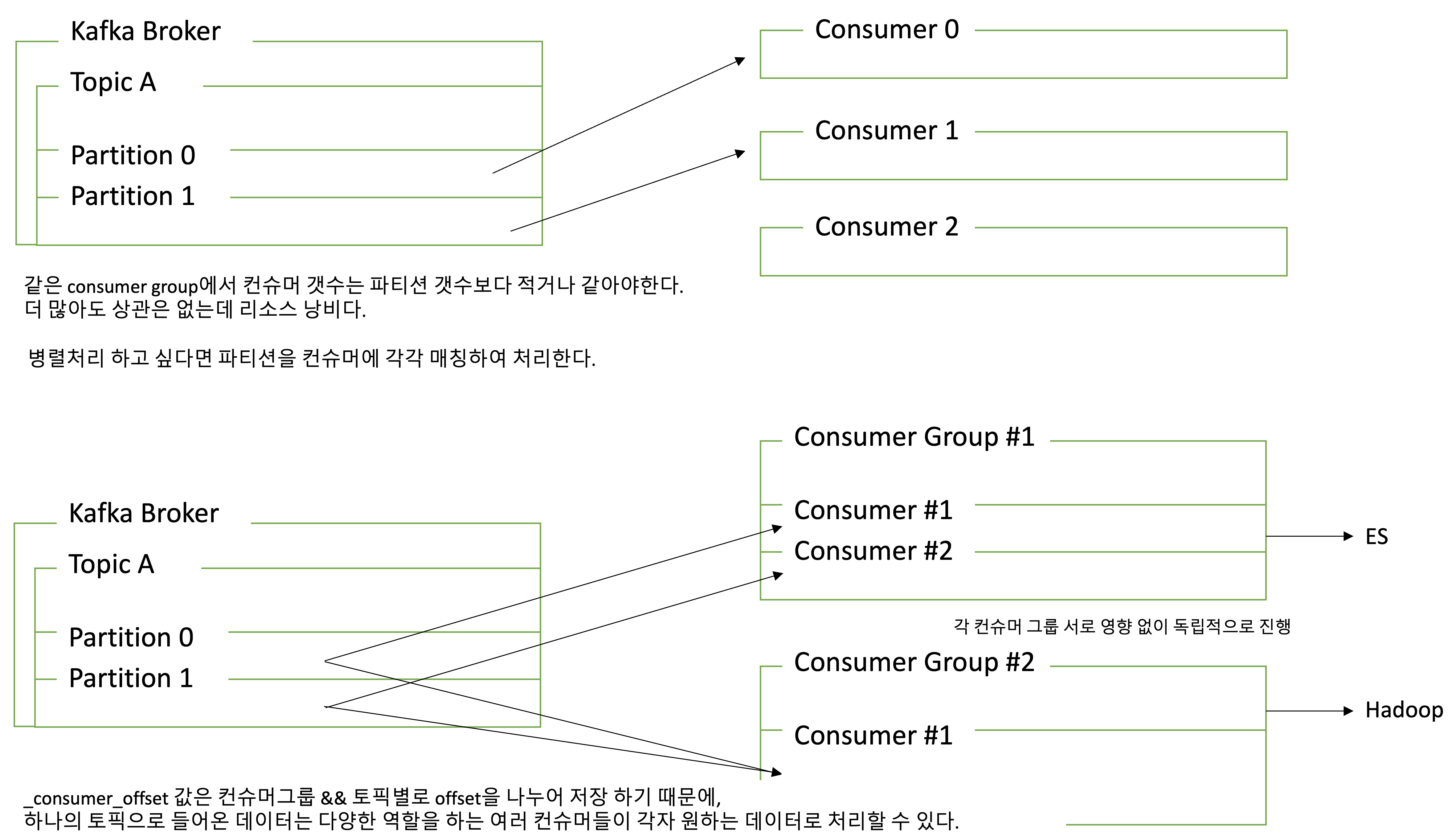
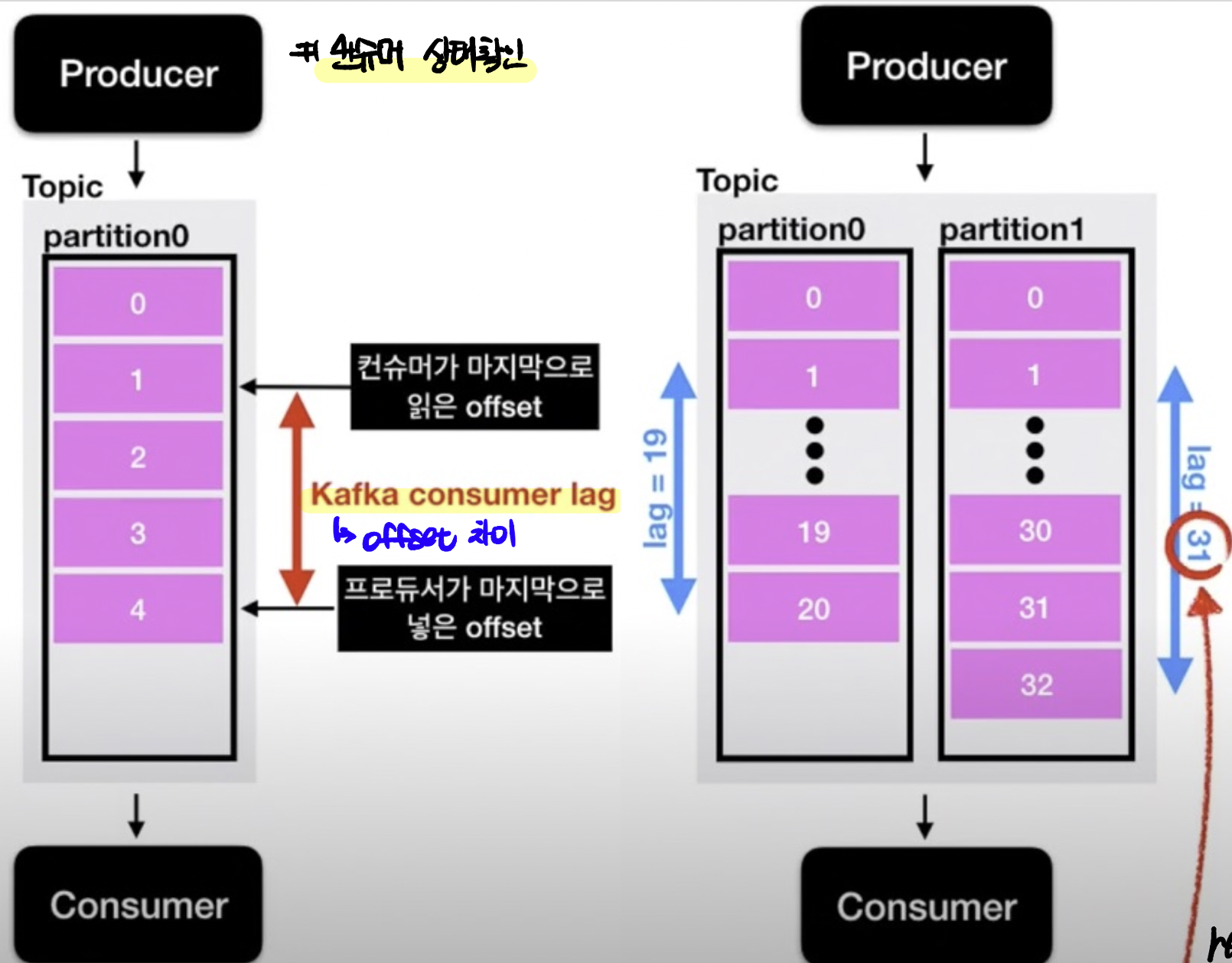
[8] Lag
- lag는 프로듀서의 오프셋과 컨슈머의 오프셋간의 차이다. 컨슈머가 성능이 안나오거나 비정상적으로 동작하면 lag가 필연적으로 발생하여 모니터링시 주의깊게 살펴봐야한다.
- 프로듀서가 데이터를 넣는 속도보다 컨슈머가 데이터를 가져가는 속도가 느리다면, 2개의 오프셋간의 차이가 발생한다. lag의 숫자를 통해 현재 해당 토픽에 대해 파이프라인으로 연계되있는 프로듀서와 컨슈머의 상태에 대한 유추가 가능하다.
- 토픽에 여러 파티션이 존재할 경우 lag가 여러개 존재할 수 있다.
5. Hadoop
[1] 철학
- 한 대의 고가 장비보다 여러 대의 장비가 낫다고 생각하여 데이터를 분산하여 저장한다.
- 시스템(H/W)은 언제든지 죽을 수 있다고 생각하여, 장애가 자동화되어야하며 && 시스템 확장이 쉬워야한다고 생각한다.
- 따라서 다음과 같은 구성을 따른다.
- 수천대 리눅스 기반 범용 서버로 구성된 Cluster로 구성한다.
- Master-Slave 구조를 따른다.
- File을 block 단위로 저장한다.
- 하둡 자체적으로 기본적으로 3개의 복제본을 구성한다. 즉, block data 복제본을 유지한다.
- data 처리시 최대한 지역성을(비슷한 데이터는 물리적으로 근처에 위치한다.) 보장할려고 노력한다.
[2] Hadoop 기본 개념
- 하둡은 비정형 데이터를 포함한 빅데이터를 다루기 위한 가장 적합한 플랫폼으로 저렴한 비용으로 많은 비정형 데이터를 저장하며, 분석에 용이하다. RDBMS는 정형 데이터만을 다룬다.
- '빅 데이터'의 '저장'과 '분석'을 위한 '분산' 컴퓨팅 솔루션
- 빅데이터 : 한 대의 컴퓨터로 저장/연산하기 어려운 거대 데이터
- 저장 : 데이터 크기, 복구 관점에서 큰 규모의 데이터를 저장해야한다.
- 분석 : 쪼개진 데이터를 분석하고 그 결과를 합친다.
- 분산 : 여러대의 컴퓨터로 나눠서 작업을 처리한다.
- 구성
- 네임 노드 : 데이터를 쪼개고 위치를 기억한다.
- 데이터 노드 : 실 데이터를 저장한다.
- 연계 컴포넌트
- hadoop : 대용량 데이터 접근을 위한 분산형 파일 시스템으로, 데이터를 블록 단위로 분할하여 여러 서버에 복제하여 저장하기 때문에 안전, 신뢰할 수 있게 저장하는 디비다. hadoop 안에 GFS라는 기능이 있으며, 이 기능 덕분에 파일을 '분산형'으로 저장한다.
- yarn : 작업 일정 관리, 클러스터 자원 관리 툴
- MapReduce : 분산 파일 시스템으로 저장된걸 병렬 처리한다.
- Spark : 빅 데이터 처리를 위한 고속 엔진
- hive : SQL을 활용하여 MapReduce를 실행할 수 있는 구조로, 파일 정보의 물리적 구조를 테이블 형태의 논리적 구조로 설명한다.
6. Redis
Not Disk, In Memory Data Structure
[1] 캐시란
- 캐시란 나중에 요청 올 결과를 미리 저장하고 빠르게 서비스 해준다. 보통 많은 양의 데이터를 디비에 저장하고 이를 서비스해주는데, 사실 1000개 데이터가 있으면 그 중 20개의 데이터만 자주 사용한다고 알려져 있다.
- 읽기 작업이 빈번한 경우 디스크가 아닌 메모리 캐시를 이용하면 더 빠른 속도로 서비스를 제공할 수 있다.
- DB에 삽입 쿼리 1번을 500번 날리는 것보다, 삽입 쿼리 500번을 1번에 날리는게 더 빠르다. 물론 캐시 장애시 동기화 안된 데이터가 다 날라가는 문제가 있지만, write 작업이 빈번한 경우(ex-log 적재) write-back 방식이 사용된다.

[2] Redis 사용처
- remote data structure : A, B, C 서버에서 데이터를 공유하고 싶을 때
- 한 대의 서버에서는 전역변수가 괜찮지 않을까? 물론 맞는데, 레디스는 싱글 스레드라 자동으로 아토믹하게 지원
- 인증 토큰(Strings, Hash), 랭킹보드(Sorted, Set), 유저 API Limit, Job Queue(List), 자주 사용되는 값, 배치로 돌린 값 저장 등 다양한 곳에서 사용된다.
[3] Collection이란
- 미리 잘 만들어 놓은 자료구조를 사용하여, 개발의 편이성이 증가한다. 즉, 컬렉션을 왜 사용할까에 대한 질문은 외부 요인은 신경 안쓰고 비지니스 로직에만 집중할 수 있기 때문이다.
- 랭킹 시스템 구현시 디비의 정렬로 구현한다면 속도가 현저히 느려진다. 따라서 in-memory 기반의 레디스를 활용한다. 또한, Atomic하지 않게 처리하다보면 특정 상황에서 race condition 상태가 발생하는데, redis collection은 이런 atomic 처리를 구성한다.
- 이러한 이유로 레디스에서 제공하는 컨렉션을 사용하며, 잘못 선택하면 서비스의 속도가 굉장히 느려져서 Collections을 잘 선택해야한다.
- 하나의 컬렉션에 너무 많은 아이템을 담으면 안된다. 10,000개 이하 몇천개 수준으로 유지하는게 좋으며, Expire Time은 Collection의 아이템 개별로 걸리지 않고 전체 컬렉션에 대해서만 걸린다.
Collection 종류
- Strings : key, value 형태로 set(key, value), get(key), mset(multi set)으로 데이터를 저장 / 읽기 할 수 있다. 또한 키에 따라 데이터가 분산되기 때문에 어떻게 키를 잡을지 고민이 필요하다.
- List : 중간에 값을 넣을 때 비효율적이며, 잡큐와 같이 데이터를 집어넣고, 하나씩 앞에서부터 가져올 때 사용된다. LPush, RPush, LPop, RPop 명령어를 이용한다.
- Set : 데이터가 있는지 없는지만 체크하는 용도로 중복되지 않은 키를 넣을 때 사용한다. SADD, SMEMBERS, SISMEMBER 명령어를 사용하며, 친구 리스트와 같이 특정 유저를 팔로우 하는 목록을 저장할 때 사용한다.
- Sorted Sets : 랭킹에(score 값) 따라 순서가 바껴서 set 형태로 저장한다. score는 double type이므로 부정확할 수 있으나, 유저 랭킹 보드로 사용한다. key, socre, value로 구성된다.
- Hash : key 밑에 sub key가 존재하며, Hmset key subkey1 value1 subkey2 value2 등 명령어로 값을 삽입 및 Hgetall key, Hget key subkey1 등으로 조회할 수 있다.
[4] Redis 운영
메모리 관리를 잘하자
- 레디스가 빠른 이유는 디스크가 아닌 In Memory Data Structure 때문인데, Physical Memory 이상을 사용하면, 메모리 -> Disk Swap이 발생하며 속도가 현저히 느려진다.
- 데이터 삽입시 해당 데이터만큼만 메모리에 할당하는 것이 아닌 'Page' 단위로 데이터를 넣기 때문에 실제 사용 데이터보다 더 크게 메모리에 잡히는 경우가 존재한다. 따라서 모니터링은(실제 할당) 필수다.
- 큰 메모리를 쓰는 인스턴스 하나보다는 적은 메모리를 사용하는 인스턴스 여러개가 더 '안전'하다. 이유는 read는 괜찮은데 write시 현재 메모리의 fork 작업으로 2배를 사용하는 경우가 존재하기 때문이다. 따라서 관리는 귀찮지만 운영면에서는 더욱 안전하다. (24 gb instance (최대 48gb) 보다 8gb x 3개가(최대 32gb) 더 안전하다.)
- 따라서 다양한 데이터를 가지는 경우보다 유사한 크기의 데이터를 가지는것이 메모리 파편화가 덜 일어나 더 유리하다.
- 메모리가 부족하다면 좀 더 많은 메모리를 보유한 장비로 migration 해야 하는데, 메모리가 빡빡하다면 migration시 문제가 발생할 수 있다. 사용량 70~80%시 고민이 필요하며, 필요없는 victime 할 것을 지워줘야한다.
O(n) 명령어는 주의하자.
- Redis는 Single Thread로 동시에 '하나의' 명령어만 처리할 수 있다.
- TCP로 쪼개진 패킷이 들어오고, 쪼개진 패킷을 조합하여 차례로 명령어를 실행할 것이다. 단순 get, set 명령어는 금방 처리되지만 긴 시간을 소요하는 명령어를 수행하면 뒤이어 오는 명령들은 오랫동안 대기하여 전체가 대기하는 문제가 발생한다.
- KEYS(모든 키 조회), FLUSH/DELETE Collections (삭제), Get All Collections 와 같이 뭔가 '모든' key, value를 조회하는 명령어를 주의하자.
- Key가 백만개 이상인데 확인을 위해 Keys 명령어를 사용할 경우 문제가 발생하며, scan & cursor 명령어를 활용하여 하나의 긴 명령어를 짧은 여러 명령어로 분할하여 사용하자.
- 아이템이 많은 상황에서 모든 데이터를 조회하는 것보다, collection의 일부만 가져오거나, 큰 컬렉션들을 여러개의 컬렉션으로 나누어 저장하여 오랜 연산비용을 줄이자.
[5] Redis Replication
- 레디스에서 데이터 안전을 위해 특정 서버로 데이터를 복제한다. 즉, A 서버(master) 데이터의 모든 변화를 B 서버에(slave) 반영하는데, 이때 'Replication Lag'가(잠시 동안 데이터의 불일치) 발생한다.
- replication 과정에서 fork가 일어나므로 메모리 부족 현상이 발생할 수 있다. 또한, 많은 대수의 레디스 서버가 레플리카를 두면 네트워크 이슈가 발생할 수도 있다. (network bandwith보다 크게 데이터 전송시 문제가발생하여, 1대씩 migration 하도록 하기도한다.)
- redis.conf 권장 설정 tip
- MaxClient 설정을 50,000으로 높이고
- RDB, AOF (Memory -> DB 저장) 설정을 off하고, master replica는 끄고 secondary replica만 켜서 레플리카에 의한 속도 이슈를 제어한다.
- 전체 장애의 90% 이상이 keys, save 설정(예를 들어 1분에 500개의 데이터 변경시 memory dump default 설정으로 disk, memory 사용량 부하)에 의하여 발생하므로 특정 명령어를 disable한다. (ex keys command)
데이터 분산 설정
- Consistent Hashing by Appcation단
- 일반 해싱은 중간에 서버가 죽거나 증설되면 모든 데이터가 rearange하는 작업이 필요하다. consistent는 key의 일관된 해시 값을 주는 특성을 이용하여 모든 서버 해시 값에 근접한 값으로 이동하여, rearange해도 1/n 만큼의 변화가 일어난다.
- Sharding by Application단
- 특정 range를 정의하고, 해당 range에 속하면 해당 키값에 데이터를 저장하는데, 상황에 따라 놀고있는 서버가 존재할 수 있다. 하지만 서버 확장이 용이하고, key를 쉽게 찾을 수 있다.
- 참고로 modulus로 처리하는건 서버 확장/감소시 안 좋지만 데이터를 '균등히' 분배할 수 있어 데이터 삽입/조회에 용이하다.
- Redis Cluster
- primray 서버, secondary 서버로 구성하며, primary가 죽으면 secondary가 승격한다.
- 해시 기반으로 slot 16,834로 구분한다.
- 일부 언어에서 라이브러리로 구현되있어, 사용이 편리하다. ex) 잘못된 slot으로 갈 때 처리 등
Redis Failover
- redis cluster의 경우 primary & secondary로 구성되어 서버 장애시 자동 승격이 이루어진다.
- Coordinate 방식
- API Server가 레디스에 접근 시 Coordinate를 통해 어떤 레디스가 Primary인지 알려준다.
- Health Check가 Primary 서버가 죽으면 Redis가 죽으면 Coordinate 서버에게 어떤 서버가 Primary인지 알려준다.
- VIP 방식
- Api Server가 레디스 접근시 VIP로 접근하며, 레디스가 죽으면 Health Check가 VIP를 바꾼다.(Secondary 승격)
[6] Redis Monitoring
- infra(cpu, memory, disk)는 당연히 고려해야하며, 실제 데이터 사용량보다 메모리 사용량이 더 클 수도 있다.
- Disk 기반의 DB보다 Memory 기반의 레디스는 좋은 툴이다. 하지만 메모리를 빡빡하게 쓰면 관리가 어렵다. 예를 들어, 32gb 장비에서 24gb 이상 사용하면 장비 증설을 고려해야한다. 당연히 write 작업이 heavy할 경우 migration을 주의하자.
- 캐시로 레디스를 사용할 경우 redis가 문제 있어도 db가 대체하여 괜찮지만, persistent storage 혹은 단독으로 사용할 경우 무조건 Primary/Secondary로 구성하자. 뿐만 아니라 주기적으로 secondary로 migration하여 fork가 주기적으로 일어나 메모리 사용을 여유롭게 구성하자.
- RDB, AOF 작업은 Secondary에서 처리하도록 구성하자.

성장하는 개발자가 되고싶어요