1. Sync, Async, Blocking, Non-Blocking
[1] Sync vs Async
- 동기와 비동기의 차이는 호출되는 함수의 작업 완료 여부(리턴값)를 신경쓰는지의 여부의 차이다.
- 동기는 함수 A가 함수 B를 호출한 뒤, 함수 B의 리턴 값을 계속 확인하면서 신경쓰는 것이다.
- 비동기는 함수 A가 함수 B를 호출할 때 콜백 함수를 함께 전달해서, 함수 B의 작업이 완료되면 함께 보낸 콜백 함수를 실행한다. 즉, 함수 A는 함수 B를 호출한 후로 함수 B의 작업 완료 여부에는 신경쓰지 않는다.
[2] Blocking vs Non-Blocking
- 제어권은 자신(함수)의 코드를 실행할 권리 같은 것이다. 제어권을 가진 함수는 자신의 코드를 끝까지 실행한 후, 자신을 호출한 함수에게 돌려준다.
- Blocking은 A 함수가 B 함수를 호출하면 제어권을 A가 호출한 B 함수에게 넘겨준다.
- Non-Blocking은 A 함수가 B 함수를 호출해도, 제어권은 그대로 자신이 가지고 있는다.

[3] 4가지 케이스
Sync && Blocking
- 함수 A는 함수 B의 리턴 값을 필요로한다.(sync) 그래서 제어권을 B에게 넘겨주고, 함수 B가 실행을 완료하여 제어권을 돌려줄때까지 함수A는 기다린다.(blocking)
Sync && Non-Blocking
- 함수 A는 함수 B를 호출한다. 이때 A 함수는 B 함수에게 제어권을 넘기지 않고, 자신의 코드를 계속 실행한다.(non-blocking) 그런데 A 함수는 B 함수의 리턴값이 필요하기 때문에, 중간중간 B 함수에게 실행이 완료되었는지 물어본다.(sync)
Async && Non-Blocking
- 함수 A가 함수 B를 호출할 때, 제어권을 넘기지 않고 자신이 계속 가지고있다.(Non-Blocking) 따라서 B 함수를 호출하더라도, 멈추지 않고 자신의 코드를 계속 실행한다.
- 또한, B 함수를 호출할 때 콜백함수를 넘겨준다.(A는 B의 작업여부를 신경쓰지 않는다.) B 함수는 자신의 작업이 끝나면 A 함수가 준 콜백함수를 실행한다.(Async)
Async && Blocking
- 잘 마주치지 않는데, A 함수는 B 함수의 리턴값에 신경쓰지 않고, 콜백함수를 넘긴다.(Async) 그런데, B 함수의 작업에 관심이 없음에도 불구하고 A 함수는 제어권을 넘긴다. 따라서 A 함수는 자신과 관련 없는 B 함수의 작업이 끝날때까지 대기한다.
2. RestTemplate
[1] RestTemplate이란?
- spring에서 지원하는 객체로, 간편하게 REST방식의 API를 호출할 수 있는 스프링 내장 클래스다.
- spring 3.0부터 지원되었고, REST API를 호출 후 json, xml의 응답을 모두 받을 수있다.
- HTTP 프로토콜의 메소드(ex. GET, POST, DELETE, PUT)들에 적합한 여러 메소드를 제공하며, Header, Content-Tpye등을 설정하여 외부 API 호출할 수 있다.
- Blocking I/O 기반의 동기 방식을 활용한 통신방식이다.
[2] RestTemplate 동작원리
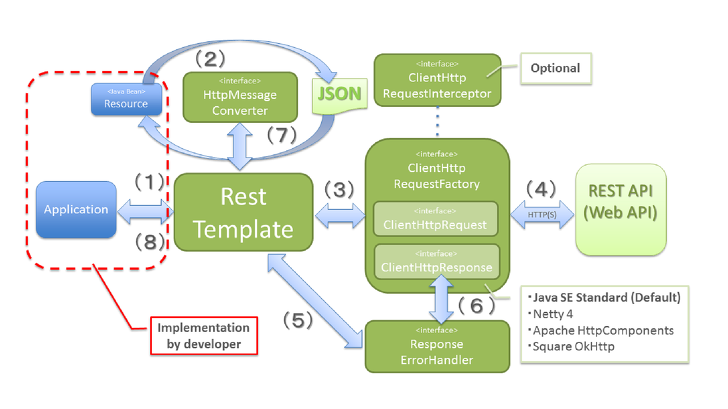
- 애플리케이션 내부에서 REST API에 요청하기 위해 RestTemplate의 메서드를 호출한다.
- RestTemplate은 MessageConverter를 이용해 java object를 request body에 담을 message(JSON etc.)로 변환한다.
- ClientHttpRequestFactory에서 ClientHttpRequest을 받아와 요청을 전달한다.
- 실질적으로 ClientHttpRequest가 HTTP 통신으로 요청을 수행한다.
5/6. ResponseHandler에 의해 에러핸들링을 한다. - MessageConverter를 이용해 response body의 message를 java object로 변환한다.
- 결과를 애플리케이션에 돌려준다.
[3] 사용 예시
RestTemplate restTemplate = new RestTemplate();
HttpHeaders headers = new HttpHeaders();
MediaType mediaType = new MediaType("application", "json", Charset.forName("UTF-8"));
headers.setContentType(mediaType);
HttpEntity<String> entity = new HttpEntity<>(jsonData, headers);
String response = restTemplate.postForObject(url, entity, String.class); // restTemplate 함수가 완료된 후에 아래코드가 실행된다. block-I/O 방식이기 때문. 비동기로 처리하고 싶다면? 별도의 쓰레드에서 처리가 필요한데 그 부분은 다음 절에서 설명.
...
3. 비동기 통신
[1] 배경
- 여러 API를 호출 후, 이 데이터를 합치는 기능을 만든다고 해보자. 각각의 외부 API를 호출할 때 순차적으로 호출하면 좋을까 아니면 병렬로 호출하면 좋을까? 물론 상황마다 다르다. 만약 1번 API를 호출한 값이 2번 API를 호출할 때 필요하다면 순차적으로 호출하는게 당연하다. 이런 경우가 아니라면 즉, 특정 API의 결과값이 다른 API를 호출할 때 상관 없다면 빠르게 다른 API를 호출하는게 성능적으로 매우 유리하다.
- 즉, 우리는 API를 호출 할 때 결과값을 기다리지 않고 처리하는 비동기 통신을 사용하고 싶다.
[2] @Async
@SpringBootApplication에@EnableAsync를 설정 후, 비동기 메소드에@Async을 달면 끝이다.- 스프링의
@Async는 AOP에 의해 동작하는데,@Async으로 선언된 메서드는 비동기 메서드로 동작한다. AOP 내부로직을 보면 반환 메서드의 리턴 타입에 따라 상이하게 구현된다.- CompletableFuture
- ListenableFuture
- Future
- Return이 없는 케이스
- 비동기 메서드는 별도의 쓰레드를 생성 후 작업한다. 결과값은
@Async메서드를 호출한쪽에서 blocking하거나 혹은 콜백 메서드를 통해 처리할 수 있다. - 멀티스레드와 Blocking 방식을 사용하기 때문에, Request는 먼저 Queue에 쌓이고, 가용한 스레드에 할당되어 처리한다. 즉, 1개의 요청 당 하나의 스레드를 할당한다.
- 따라서 요청을 처리할 쓰레드가 없다면 요청은 큐에서 대기하게된다. 따라서 외부서버와의 커넥션이 많고, 오래 걸릴 경우 가용한 스레드 수가 줄어들어 전체 서비스가 느려질 수 있다.
Future
- 메서드의 결과를 전달받아야 한다면 Future를 사용한다.
- 스프링에서 제공하는
AsyncResult는 Future의 구현체며, future의get메서드는 메서드의 결과를 조회할 때까지 계속 기다린다. 예를 들어, A 함수에서 Future를 리턴하는 함수를 호출한다면, A함수는 호출한 함수의get()을 마주치기 전까지 non-blocking으로 실행되다get을 마주치면 blocking된다.
public Future<UserInfo> getUserInfo(String id) {
UserInfo userInfo = getUserInfo(id); // userInfo APi Call by RestTemplate
return new AsyncResult<>(userInfo);
}
...
Future<UserInfo> userInfoFuture = userService.getUserInfo(id);
// non-blocking
System.out.println("UserInfo : " + userInfoFuture.get());
// blockingListenableFuture
future.addCallback메서드는 비동기 메서드의 내부 로직이 완료되면 수행되는 콜백 기능이다. Future를 사용했을 때는future.get을 사용하여 메서드가 처리될 때까지 호출한 함수쪽에서 blocking 현상이 발생했지만, 콜백 메서드를 사용한다면 결과를 얻을때까지 무작정 기다릴 필요가 없다.- 개인적으로 결과론적으로 본다면 future, ListenableFuture에 큰차이는 없다고 생각한다.(get 메서드의 위치가 잘 있다면) 다만, future의 get의 순서를 잘못 지정한다면 성능은 크게 떨어질 것이다. 하지만 콜백으로 처리하는 ListenableFuture의 경우 이러한 실수를 사전에 방지할 수 있다.
ListenableFuture<UserInfo> userInfoFuture = userService.getUserInfo(id);
userInfoFuture.addCallback( ...callback 처리);CompletableFuture
Future+@Async를 합친다면 비동기로 외부 서버와 통신할 수 있다.CompletableFuture는@Async를 추가할 필요 없이 자체적으로 별도의 쓰레드를 생성하여 API를 통신한다. 뿐만 아니라 콜백 등록, Future 조합, 예외 처리 등 다양한 기능을 제공한다.- 개인적으로 비동기 통신할 때 람다형식으로 편하게 읽기 쉽게 외부 API와 통신할 수 있다.
- 비동기 작업 실행
- runAsync : 반환값이 없는 경우, 비동기로 작업 실행
- sypplyAsync : 반환 값이 있는 경우, 비동기로 작업 실행
- 작업 콜백
- thenApply : 반환 값을 받아서 다른 값을 반환함
- thenAccpet : 반환 값을 받아 처리하고 값을 반환하지 않음
- thenRun : 반환 값을 받지 않고 다른 작업을 실행함
- 작업 조합
- thenCompose : 두 작업이 이어서 실행하도록 조합하며, 앞선 작업의 결과를 받아서 사용할 수 있음
- thenCombine : 두 작업을 독립적으로 실행하고, 둘 다 완료되었을 때 콜백을 실행함
- allOf : 여러 작업들을 동시에 실행하고, 모든 작업 결과에 콜백을 실행함
- 예외 처리
- exeptionally : 발생한 에러를 받아서 예외를 처리함
- handle, handleAsync : (결과값, 에러)를 반환받아 에러가 발생한 경우와 아닌 경우 모두를 처리할 수 있음
ThreadPoolTaskExecutor executor;
CompletableFuture<Bank1> back1Info = getBack1(param1);
CompletableFuture<Bank2> back2Info = getBack2(param2);
CompletableFuture<Bank3> back3Info = getBack3(param3);
CompletableFuture.allOf(bank1Info, back2Info, back3Info)
.thenRun( () ->
bankTotalInfo.builder()
.bank1Info(bank1Info.join())
.bank2Info(bank2Info.join())
.bank3Info(bank3Info.join())
.build()
).join();
...
private CompletableFuture<Bank1> getBank1(BankParam param) {
return CompletableFuture.supplyAsync(() -> bankService.getBank(param, executor))
.exceptionally(e -> new Bank1());
}
...
4. WebClient
- Spring WebClient는 웹으로 API를 호출하기 위해 사용되는 Http Client 모듈 중 하나로, RestTemplate와 동일하게 'HttpClient' 모듈이다. 차이점은 통신방법이 RestTemplate은 Blocking방식이고, WebClient는 Non-Blocking방식이다.
- Spring WebClient가 필요한 이유는, 다시 말하면 Non-blocking방식이 필요한 이유는 네트워킹의 병목현상을 줄이고 성능을 향상시키기 위함이다.
[1] 기존 RestTemplate의 Blocking 방식의 문제점
- 위에서 언급한 것처럼 RestTemplate은 Multi-Thread와 Blocking방식이다. 'Thread Pool'에 가용할 Thread를 미리 만들어놓고, Request가 오면 먼저 Queue에 쌓이고 가용한 스레드가 있으면 그 스레드에 할당되어 처리된다. 즉, 1 요청 당 1 스레드가 할당된다. 이때 각 스레드에서는 Blocking방식으로 처리되어 응답이 처리될때 까지 그 스레드는 다른 요청에 할당될 수 없다.
- 요청을 처리할 스레드가 있으면 아무런 문제가 없지만, 스레드가 다 차는 경우 이후의 요청은 Queue에 대기하게 된다. 대부분의 문제는 네트워킹이나 DB와의 통신에서 생기는데 이런 문제가 여러 스레드에서 발생하면 가용한 스레드수가 현저하게 줄어들게 되고, 결국 전체 서비스는 매우 느려지게 된다.
[2] WebClient 동작원리
Spring WebClient는 Single Thread와 Non-Blocking방식을 사용한다. 즉, Core 당 1개의 Thread를 이용한다.
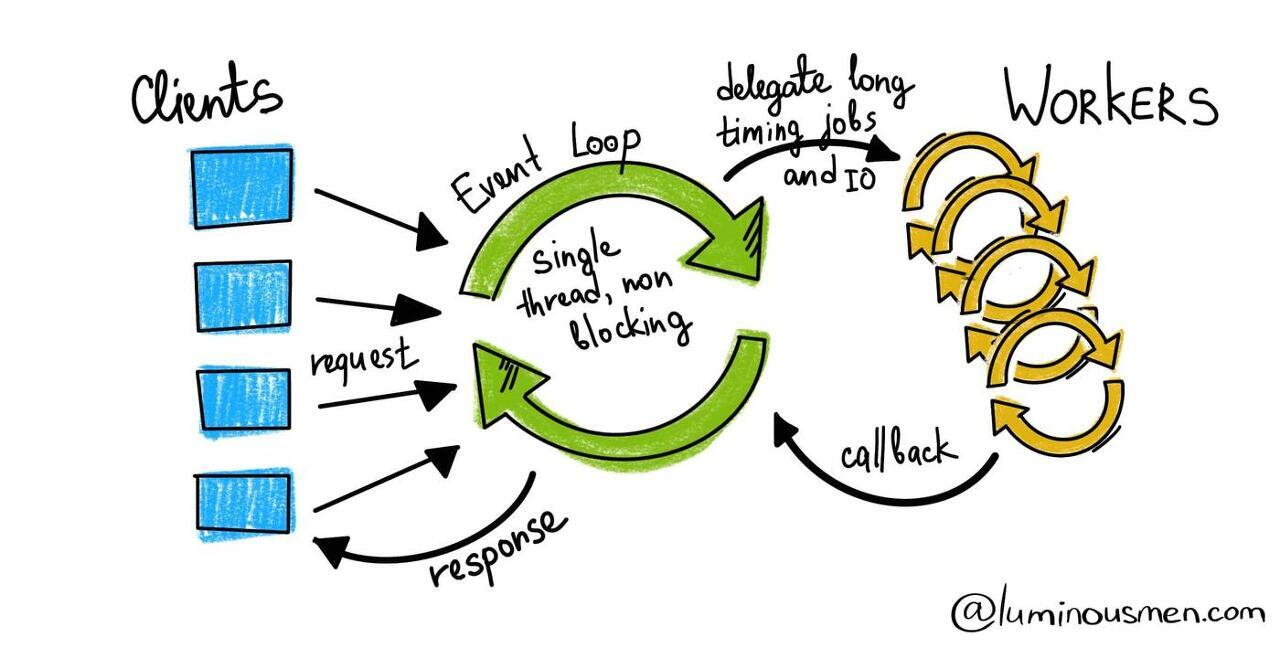
이미지 출처 : https://luminousmen.com/post/asynchronous-programming-blocking-and-non-blocking
- 각 요청은 'Event Loop' 내의 Job으로 등록된다.
- 'Event Loop'는 각 Job을 'Worker'에게 요청한 후, 결과를 기다리지 않고 다른 Job을 처리한다.
- 'Event Loop'는 Worker로부터 Callback으로 응답이 오면 그 결과를 요청자에게 제공한다. 이렇게 WebClient는 이벤트에 반응형으로 동작하도록 설계되었다.
[3] 사용법
fun getWebClient(webClientBuilder: WebClient.Builder, url: String): WebClient {
return webClientBuilder.baseUrl(url) // webclient base url
.defaultHeaders { it.contentType = MediaType.APPLICATION_JSON }
.clientConnector(ReactorClientHttpConnector(getHttpClient())) // HTTP CLIENT 설정
.build()
} // webclient 생성
fun getHttpClient(): HttpClient {
val httpClient = ConnectionProvider.builder("connection-pool")
.maxConnections(MAX_CONNECTIONS) // 유지할 Connection Pool 의 수
.pendingAcquireMaxCount(MAX_PENDING_ACQUIRE_COUNT) // Connection 을 얻기 위해 대기하는 최대 수
.pendingAcquireTimeout(Duration.ofMillis(PENDING_ACQUIRE_TIMEOUT)) // Connection 모두 사용중일때 Connection 을 얻기 위해 대기하는 시간
.maxIdleTime(Duration.ofSeconds(MAX_IDLE_TIME)) // 사용하지 않는 상태의 Connection 이 유지되는 시간
.maxLifeTime(Duration.ofSeconds(MAX_LIFE_TIME)) // Connection Pool 에서의 최대 수명 시간
.build()
return HttpClient.create(apiConnectionProvider)
.option(ChannelOption.CONNECT_TIMEOUT_MILLIS, CONNECT_TIMEOUT_MS)
.responseTimeout(Duration.ofMillis(RESPONSE_TIME_OUT_MS)) // Default RESPONSE TIMEOUT
.resolver(DefaultAddressResolverGroup.INSTANCE)
} // webclient 생성 시 필요한 Http Client
fun userCall() {
client // 위에서 언급한 getWebClient 사용
.get() // get or post etc.. method 설정
.uri { it.path(path).queryParams(parameters).build() } // baseurl + path, parameters 설정
.header("header", header) // cookie, header .. 설정
.accept(MediaType.APPLICATION_JSON) // accept type 설정
.httpResponseTimeout(Duration.of(timeout)) // default timeout이 아닌, 변경된 timeout 설정 가능.
.retrieve() // body를 받아 디코딩하는 메서드로, exchange보다 memory leak의 단점 보안
.bodyToMono<UserInfoResponse>() // 해당 클래스로 맵핑
.doOnError { // 에러 수신시 처리 방식
throw WebClientException()
}
.map { UserInfo(it) } // 최종 반환 클래스
.awaitSingle() // 뒤이어 나올 코루틴과 관련된 내용
// 많은 API를 연동하다보면 중복된 코드가 많이 발생할 수 있는데 코틀린에서 제공하는 '확장함수'를 이용하면 코드 중복을 최소화할 수 있다.
}[4] timeout 관련 정리
- CONNECT_TIMEOUT_MILLIS : http client level이며, 서버와 커넥션 맺는데 기다리는 시간이다.
- ReadTimeoutHandler/WriteTimeoutHandler : TCP Level에 적용되므로 TLS handshake 동안에도 적용된다. 따라서, HTTP 응답에 대해 원하는 것보다 timeout을 높게 설정해야한다. 심지어 HTTP request가 진행되지 않는 경우에도 ReadTimeoutHandler/WriteTimeoutHandler 핸들러가 작동된다. 예를 들어, 1000ms이라고 잡아도 실제로 TLS 등의 이유로 1000ms에 읽는/쓰는 시간 뿐만 아니라 다른 작업도 포함된다.
- Reactive Stream의 timeout : 클라이언트가 응답을 받는 시간 뿐만 아니라, 커넥션 풀로부터 커넥션을 얻고 새로운 연결을 생성하는 것과 같은 것들을 수행한다. TLS의 handshake도 포함
- response timeout : responseTimeout 은 순수 http 요청/응답 시간에 대한 timeout 이다.
통신에서 사용되는 모든 시간을 통합한 response timeout 추천
[5] 성능비교
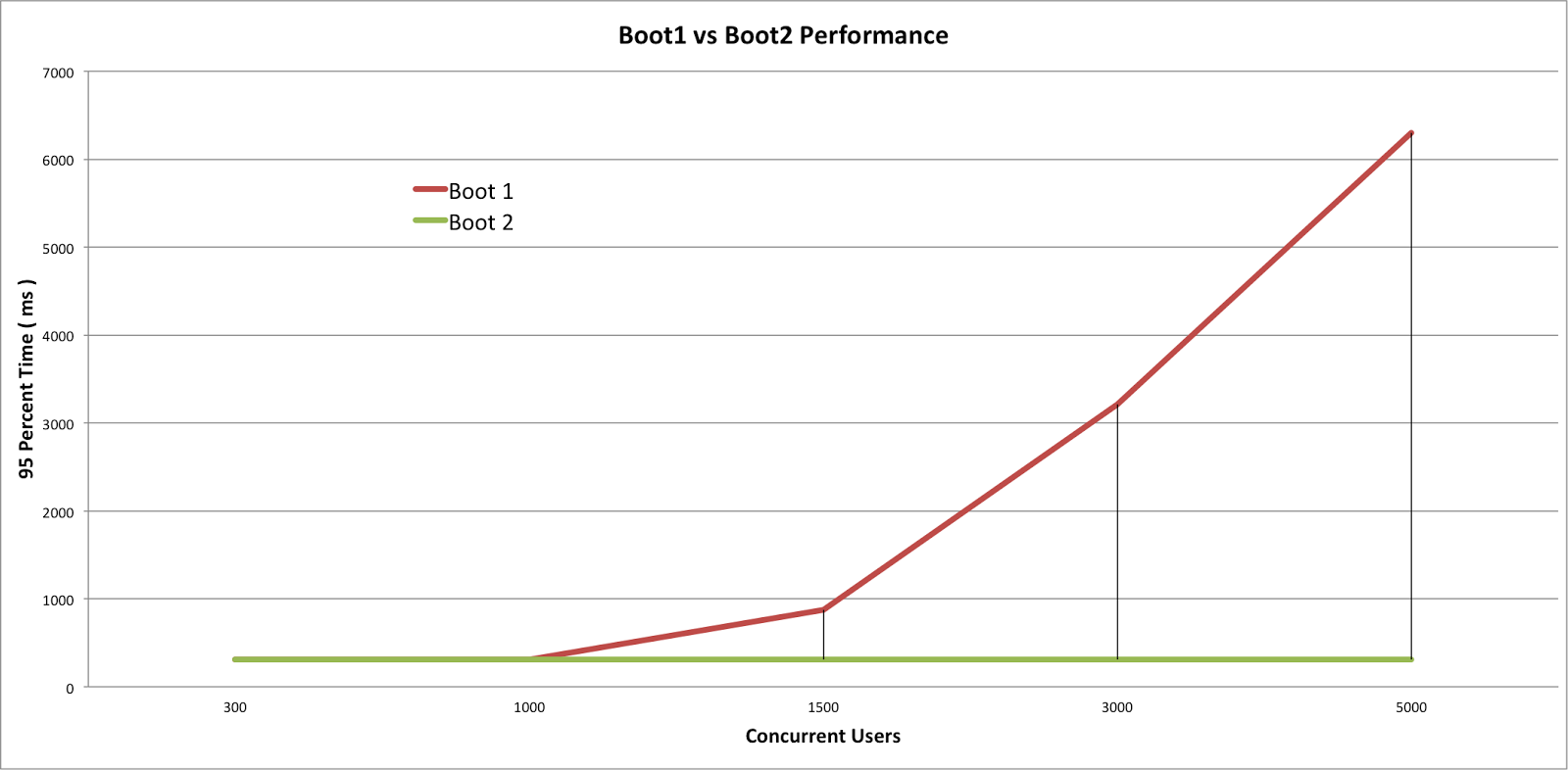
이미지 출처: https://alwayspr.tistory.com/44
- 1,000명까지는 비슷하지만 동시 사용자가 늘수록 RestTemplate은 급격하게 느려지는것을 볼 수 있다.
- Spring 커뮤니티에서는 RestTemplate을 이미 Depreciated시키고 WebClient를 사용할것을 강력히 권고하고 있다.
- RestTemplate보다 훨씬 적은 Thread를 사용하며, Thread가 부족하여 요청이 대기해야하는 상황을 방지하여 더 많은 요청을 처리할 수 있다고 생각한다.
5. Webflux
[1] Spring MVC vs WebFlux
Spring MVC
Spring MVC는 기본적으로 Blocking && Sync방식을 사용한다.
- 하나의 요청에 대해 하나의 스레드가 사용된다(thread-per-request). 그렇기에 다수의 요청을 대비하여 미리 스레드 풀을 생성해놓으며, 각 요청마다 스레드를 할당하여 처리한다. 따라서 Spring MVC 같은 경우 요청이 들어오면 그 요청을 Queue에 쌓고 순서에 따라서 Thread를 하나 점유해 요청을 처리한다. 동시 다발적으로 스레드 수를 초과하는 요청이 발생한다면 계속해서 큐에 대기하게 되는 Thread Pool Hell 현상이 발생할 수 있다.
- 동작중인 스레드가 블로킹 상태가 되면 다른 스레드에서 CPU 사용을 위해 문맥 교환(context switch)이 일어나게 된다. 만약 서버의 대부분의 연산이 이러한 블로킹 콜(blocking call)로 구성되어 있다면, 특히 MSA 환경은 API 호출 또는 db connection으로 대부분의 비즈니스 로직이 구성되어 있으니 잦은 문맥 교환이 일어나게 된다. 내부 블로킹 콜이 차지하는 비중만큼 문맥 교환의 오버헤드가 있는 것이다.
- 요청량이 증가한다면 스레드 수도 이에 비례하여 증가한다. 64비트 JVM은 기본적으로 스레드 스택 메모리를 1MB 예약 할당하는데 스레드 수가 증가한다면 서버가 감당해내지 못할 만큼의 메모리를 먹을 수 있다. 1만개 요청이면 9.76GB, 100만 개면 976GB 메모리를 점유한다.
Spring WebFlux
Spring Webflux는 Non-Blocking && Async 방식을 사용한다.
- Spring Webflux는 Spring5에 새롭게 추가되었으며, Non-Blocking && Reactive Stream을 지원한다.
- 기존 Spring MVC의 Servlet API는 v3.1부터 Non-Blocking I/O를 위한 API를 제공했다. 하지만 Filter, Servlet과 같이 동기적으로 처리하는 모듈 및 Blocking 방식의 API들이 있기에 완벽한 Non-Blocking 환경의 개발을 할 수는 없었다. 또한, Async && Non-Blocking 환경의 서버로 Netty가 부상하고 있으며 이 Netty와의 연동을 위해 Spring의 새로운 프레임워크가 필요했다. 이게 Webflux다.
- 서버는 스레드 한 개로 운영하며, 디폴트로 CPU 코어 수 개수의 스레드를 가진 워커 풀을 생성하여 해당 워커 풀 내의 스레드로 모든 요청을 처리한다. 제약이 있다면 논블로킹으로 동작하여야만 하며, 블로킹 라이브러리가 필수적으로 사용되어야 한다면, 워커 스레드가 아닌 외부 별도의 스레드로 요청을 처리해야한다(Thread 갯수가 제한되있기 때문).
- Event-Loop가 돌면서 요청이 발생할 경우 그것에 맞는 핸들러에게 처리를 위임하고 처리가 완료되면 Callback 메서드를 통해 응답을 반환한다.
- 요청이 처리될 때까지 기다리지 않기 때문에 Spring MVC에 비해 사용자의 요청을 대량으로 받아낼 수 있다는 장점이 있으며 상대적으로 cpu, memory, thread에 자원을 낭비하지 않는다. (context-switching이 적고 && Blocking하지 않으며, 더 적은 쓰레드를 사용하기 때문) 이렇게 적은 양의 스레드와 최소한의 하드웨어 자원으로 동시성을 핸들링하는 장점이 있다.
- 함수형 스타일 지원 (이 부분은 좀 더 확인 필요)
[2] Spring MVC -> WebFlux 전환 주의점
내부 작업 유형
- 내부 hard한 연산들이 로직의 주를 이룰 경우 Spring MVC보다 성능적인 향상을 내지 못한다고 한다. 따라서 전환을 고려한다면 내부 로직들이 어떤 연산으로 이루어져 있는지 고려해야한다. 예를 들어, 기존 로직들이 내부 연산보다는 외부에 Blocking Call이 많다면 전환시 성능적 개선을 가져올 수 있다. 반면 내부 연산이 많다면 오히려 Thread가 많은 Spring MVC가 더 성능적 우위를 가져올 수 있다.
Reactive Library 유무
- 사용하는 라이브러리들이 블로킹이라면 이는 쉽게 논블로킹으로 전환하기 어려울 수 있다. 워커풀이 아닌 별도의 외부 스레드풀을 생성하여 논블로킹으로 처리할 수 있겠지만, 스프링 가이드는 최대한 이러한 방법도 피하는 것을 권장한다.
Webflux 는 Asynchronous Non-blocking I/O 을 방식을 활용하여 성능을 끌어 올릴 수 있는 장점이 있다. 그런데 이 말은 즉, Non Blocking 기반으로 코드를 작성해야 한다. 만약 Blocking 코드가 있다면 Webflux를 사용하는 의미가 떨어지게 된다. 얼마 전까지는 Java 진영에 Non Blocking 을 지원하는 DB Driver가 없었지만, 최근에 R2DBC 가 릴리즈되어 이제는 Java 에서도 Non Blocking 으로 DB 를 접근할 수 있게 되었다.
[3] Netty
- Netty는 NIO(Non-Blocking Input/Output) 서버 프레임워크다. 즉, TCP/UDP 소켓 서버와 같은 네트워크 프로그래밍을 Non-Blocking 방식으로 쉽게 개발할 수 있다.
- Netty는 NIO 방식으로 이벤트를 처리하기 때문에 자원이 스레드를 계속 점유하며 Block 상태를 유지 하지 않는다. 따라서 톰캣보다 더 많은 커넥션을 처리할 수 있는 장점이 있다.
- Netty는 이벤트 기반 방식으로 동작하기 때문에 톰캣과달리 스레드Pool의 스레드 개수는 머신의 Core 개수의 두배다. 즉, 스레드수가 적어 스레드 경합이 잘 일어나지 않는다.
- 새부 내용은 하나의 EVENT Loop(single thread)에서 들어오는 incoming request에 대한 I/O를 담당하고, 해당 작업에 대한 처리는 worker thread에서 수행한다. Event Loop는 Non-Blocking이며 Worker Thread에서 작업 완료시 이벤트(콜백)로 받아 요청을 처리한다. 만약 Blocking 호출이 많다면 Worker Thread에서 해당 쓰레드를 점유해야되는데, 이를 방지하고자 별도의 스레드를 만들어서 처리하기도 한다.(비권장)
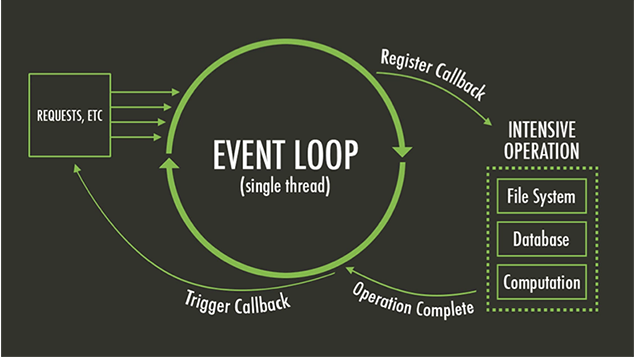
[4] Reactive Programming?
- Reactive Programming이란 결국 Data Stream을 이용하여 전달하고, 데이터의 변경 시점을 이벤트로 하여(callback), 수신자와 송신자 사이에 데이터를 전달시키는 비동기 프로그래밍이다. 이로써 간결해진 Thread를 사용하며, 간단하게 비동기 연산을 처리할 수 있다. 또한 콜백 연산이 훨씬 자유로운 장점도 있다.
- Spring Webflux에서 사용하는 reactive library가 Reactor이고 Reactor가 Reactive Streams의 구현체다. Flux와 Mono는 Reactor 객체이며, 차이점은 발행하는 데이터 갯수다.
[1] Mono vs Flux
- Flux vs Mono
- Flux : 0 ~ N 개의 데이터 전달
- Mono : 0 ~ 1 개의 데이터 전달
- 보통 여러 스트림을 하나의 결과를 모아줄 때 Mono를, 각각의 Mono를 합쳐서 하나의 여러 개의 값을 여러개의 값을 처리할 떄 Flux를 사용한다.
- 그런데 Flux도 0~1개의 데이터 전달이 가능한데, 굳이 한개까지만 데이터를 처리할 수 있는 Mono라는 타입이 필요할까? 데이터 설계를 할때 결과가 없거나 하나의 결과값만 받는 것이 명백한 경우, List나 배열을 사용하지 않는 것처럼, Multi Result가 아닌 하나의 결과셋만 받게 될 경우에는 불필요하게 Flux를 사용하지 않고 Mono를 사용하는게 좋을 것이다.

성장하는 개발자가 되고싶어요