1. Join이란
RDB는 중복 데이터를 피하기 위해 데이터를 여러 테이블로 나누어 저장합니다. 이렇게 분리된 데이터에서 원하는 결과를 도출하기 위해서는 여러 테이블을 조합해야합니다.
[1] Cross Join (Cartisian Product)
특별한 조건 없이 선행 테이블과 후행 테이블의 모든 행을 조합합니다.
SELECT *
FROM STUDENT, PROFESSOR[2] Inner Join
선행 테이블과 후행 테이블 모두를 조합하는데, 조인 조건문을 충족시키는 레코드만을 반환합니다. 즉, 교차 조인에 동등 비교, 범위 연산 등 조건문을 추가합니다.
SELECT *
FROM STUDENT, PROFESSOR
WHERE STUDENT.SUBJECT = PROFESSOR.SUBJECT[3] Natural Join
선행 테이블과 후행 테이블 모두를 조합하는데, 동일한 이름을 갖는 컬럼에서 같은 값을 같는것들만 반환합니다. 즉, 이너 조인 조건문에 같은 컬럼명의 조건을 추가합니다.
# 만약 STUDENT, PROFESSOR의 공통 컬럼명이 SUBJECT일 경우 위에 예시와 동일합니다.
SELECT *
FROM STUDENT NATRUAL JOIN PROFESSOR[4] Outer Join
내부 조인은 공통 컬럼명 기반으로 결과 집합을 생성했지만, 외부 조인은 조건문에 만족하지 않는 행도 표시해줍니다.
2. Join 동작 원리
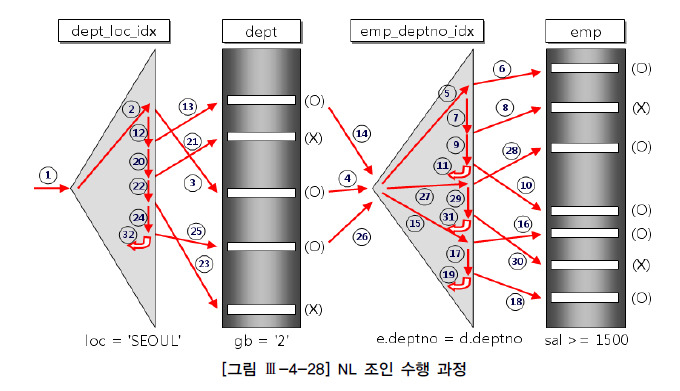
[1] Nested Loop Join
선행 테이블과 후행 테이블의 모든 레코드를 조합하는데, 중첩 루프와 비슷하게 동작합니다. : 선행 테이블 Loop * 후행 테이블 Loop
- 선행 테이블과 후행 테이블의 블록을 메모리로 가져옵니다. 메모리 공간은 한정되있어 블록을 다 사용하면 다음 블록과 SWAP합니다.
- 선행 테이블의 ROW 수만큼 [3]번 동작을 진행합니다.
- 후행 테이블 전체를 순회하며 선행 테이블의 조건절을 비교합니다.
후행 테이블에서 JOIN Key 탐색 과정이 자주 일어나 Index 작업이 없으면 굉장히 비효율적입니다. 또한 선행 테이블 ROW 수만큼 반복되므로 선행 테이블은 ROW 수가 적을수록 효율적입니다.
[2] Sorted Merge Join
- 조인 키를 기준으로 두 테이블을 정렬한 후 결과를 병합해서 데이터를 찾는 방식입니다.
- 만약 대용량 테이블에서 후행 테이블의 인덱스가 없을 때 NL Join은 너무 오래 걸립니다.
- 물론 대량의 조인 작업에서 CPU 작업 위주로 처리하는 Hash 조인이 성능상 유리할 수 있습니다. 하지만 Hash 조인과 달리 범위 조인 작업에서도 성능이 좋은 장점이 있습니다.
[3] Hash Join
해시 함수를 사용하는 조인으로, 동등 조인에서 엄청난 성능을 자랑합니다. 하지만 범위 조인 작업에서는 성능이 떨어지는 단점이 있습니다.
Sorted Merge Join은 추가로 정렬 작업이 있기 때문에 범위 조인일 경우 적합합니다. Hash Join은 인덱스가 없는 테이블에서 조인이 발생할 경우 선택하지만 경우에 따라 인덱스가 있다 하더라도 Hash 조인을 수행하는 경우도 종종 있습니다. 그만큼 대용량 데이터 처리에서 우위를 갖습니다.
