1. Nomalization
정규화란 메모리 낭비, 업데이트시 발생하는 이상현상을 해결하고자 테이블을 나누는 기법을 말합니다.
하나의 테이블이 중복된 데이터를 가지고 있다면 레코드 중 일부가 중복되게 저장되고, 업데이트시 하나의 레코드만이 아닌 테이블 안에 중복 데이터 모두를 변경해줘야합니다. 이를 위해 테이블을 나누는것이 정규화인데, 데이터 일관성을 더욱 제공하지만 Join 연산 비용이 증가하는 단점이 있습니다.
정규화는 1차, 2차, 3차 정규화, BCNF, 4차, 5차 정규화로 나눌 수 있는데, 실무적으로 4차, 5차 정규화까지 하는 경우는 드뭅니다.
- Redundancy : 중복된 불필요한 데이터를 제거합니다. 메모리 낭비를 막고 Full Scanning, Index 테이블 이득을 볼 수 있습니다.
- Integrity : 업데이트 시 발생 할 수 있는 각종 이상현상들을 방지합니다.
2. Nomalization 종류
[1] 1차
필드는 Atomic Value를 가집니다. 즉 한 개의 값만 가집니다. 만약 여러 값을 가지면 Integrity check, Index, Join 에서 문제가 발생합니다.
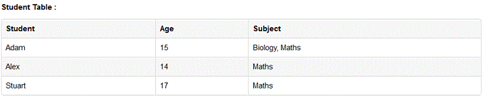
[2] 2차
기본키 이외에 컬럼이 기본키 중 한개의 컬럼에만 의존적일 경우 발생합니다. 당연히 기본키가 한 개면 무조건 2차 정규화는 만족합니다.
아래 그림은 PK가 StudentID, Subject인 테이블입니다. 이때 Age는 Student ID에만 종속적인 일반 컬럼입니다. 만약 아래 테이블에서 12345 학번을 가진 학생의 나이를 잘못 입력해 24으로 바꿔야한다면 Math, English 과목을 가진 레코드 모두 바꿔줘야됩니다. 만약 사용자 실수 혹은 쿼리 오류가 발생했는데 하나의 레코드만 변경한다면 데이터의 일관성이 깨지는 문제가 발생합니다. 따라서 하나의 컬럼에 종속적인 테이블을 따로 분리합니다.

[3] 3차
기본키 이외에 다른 컬럼이 그 외 다른 컬럼을 결정질때 발생합니다. 테이블을 분리하여 해결합니다.
STUDENT_ID가 기본키이고, ZIP 컬럼은 STREET, CITY, STATE 컬럼을 결정합니다. PK가 한개이므로 2차정규화를 만족합니다.
만약 도로명 주소 변경건 때문에 특정 Zip 컬럼의 STREET, STATE 값이 바껴야합니다.만약 하나의 데이터만 변경하면 데이터 일관성이 깨집니다. 따라서 3차 정규화 역시 아래와 같이 두 개의 테이블로 나눔으로 문제를 해결합니다.
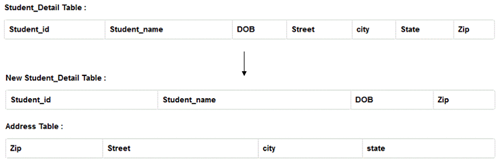
[4] BCNF
일반 컬럼이 PK를 결정하는 경우 BCNF를 위반합니다.
아래 테이블은 학생, 과목 컬럼이 PK이며 교수 컬럼이 과목 컬럼을 결정합니다. 여기서 교수 컬럼은 빈번하게 업데이트하여 PK 성질에 맞지 않습니다. 따라서 교수 컬럼 대신 과목 컬럼을 PK로 설정했습니다.
이 경우 교수가 가르치는 과목이 바뀌면 해당하는 모든 레코드를 갱신해야하고, 그 중 일부만 바꿀 경우 데이터 일관성이 깨집니다. 따라서 아래 사진과 같이 테이블을 분리합니다.

3. 반정규화
- 정규화는 데이터의 일관성을 제공하지만 테이블을 분리해 Join 비용이 증가합니다.
- 반정규화란 시스템 운영 및 편의성을 위해 의도적으로 정규화를 위배합니다. 즉, 중복 데이터를 용인하여 Join 비용을 줄어들게합니다.
- 갱신이 별로 없거나 해당 컬럼에 조회가 많을 경우 일부러 반정규화를 사용하는 경우도 있습니다. 하지만 데이터 무결성이 깨질 수 있으니 주의해서 사용해야합니다.
| - | 장점 | 단점 |
|---|---|---|
| 정규화 | 중복 데이터를 줄여 메모리, I/O 연산이 효과적입니다. 데이터 변경시 이상 현상을 줄입니다. | 테이블을 분리해 조인 비용이 증가합니다. |
| 반정규화 | 조인 비용이 줄어들어 빠르게 데이터를 조회합니다. | 데이터 갱신 비용이 높고 데이터의 일관성이 깨질 수 있습니다. |
