1. Index란
인덱스는 임의의 규칙대로 정렬된 인덱스 테이블을 만들고, 이 테이블을 참조하여 빠른 검색을 제공합니다. 특히 NL Join시 후행 테이블에서 효과적입니다.
예를 들어 페이지가 10,000쪽인 책에서 'Transaction' 키워드를 찾는다고 가정해봅니다. 처음부터 끝까지 하나하나 비교하며 (Full Scanning) 키워드를 찾는 것은 너무 오래 걸리고, 이런 작업을 자주 반복한다면 효율은 급격히 감소합니다. 따라서 우리는 키워드를 찾을 때 맨 끝 페이지에 '색인'을 참조하여 원하는 페이지를 찾게됩니다. 이때 색인은 보통 'a', 'b', 'c' 등 일련의 순서대로 표기하고 'T' 이후에 값들은 탐색할 필요도 없습니다. 즉, 어떤 키워드를 찾을 때 색인 페이지를 참조하는데 색인 페이지는 특정 값으로 정렬 되있고 거기서 원하는 페이지를 찾고, 그 페이지에서 원하는 결과를 바로 탐색합니다. 만약 범위 탐색인 경우에도 색인에서 정렬된 값 범위를 벗어날 경우 더 이상 탐색할 필요가 없습니다.
이때 Clustered Index는 알파벳 순으로 책도 정렬된 상태를 말하고, Non-Clustered Index는 알파벳 순이 아닌 원하는 순서대로 책이 뒤죽박죽된 상태를 의미합니다.
DB도 동일합니다. 원하는 컬럼에 인덱스를 설정하면 컬럼 값 기준으로 정렬된 인덱스 테이블이 생성됩니다. 이후 해당 컬럼에 걸린 데이터를 조회할 때(Join이 핵심입니다.) 인덱스 테이블을 참조하여 Random Access 한 후, 빠르게 데이터를 조회할 수 있습니다. 물론 인덱스 테이블은 항상 정렬된 상태를 유지하기 때문에 조회 성능은 좋아졌지만 삽입, 삭제, 수정의 경우 인덱스 테이블 정렬 연산이 추가적으로 필요한 단점이 있습니다. 하지만 Join 연산으로 원하는 값을 추출하는 SQL 특성상 Index의 성능이 중요할 때가 많습니다.
2. Index 사용 기준
[1] Index를 무작정 많이 사용하는것이 좋을까요?
- 인덱스를 사용하면 인덱스 테이블을 추가적으로 생성하기 때문에 공간의 낭비가 발생할 수 있습니다.
- 인덱스 설정 컬럼을 기준으로 인덱스 테이블을 정렬하기 때문에 삽입, 업데이트, 삭제시 데이터가 밀리고 끌어당기는 등의 추가 연산이 발생할 수 있습니다.
- Clustered Index는 인덱스 테이블 뿐만 아니라, 데이터가 담긴 실제 테이블도 인덱스 컬럼 기준으로(PK) 정렬되어 있어 성능이 저하될 수 있습니다.
- 그럼에도 불구하고 Join이 많은 SQL 특성 상 Index는 성능 향상에 필수 조건입니다.
[2] Index 설정 기준
- 무작정 인덱스를 늘리는 것이 아니라 조회 시 자주 사용되고 고유한 값 위주로 설정하는 것이 좋습니다. 이를 위해 Cardinality 값을 이용합니다.
- Cardinality가 높은 컬럼을 인덱스로 잡는 것이 좋습니다. 컬럼 값들의 중복도가 낮으면 Cardinality는 높다고 표현합니다. 즉, 중복된 값이 적은 컬럼을 인덱스로 선정하는것을 권장합니다.
- 예를 들어, 남/녀 2가지로 구분되는 성별은 Cardinality 값이 낮기 때문에 인덱스로 만들어봤자 효율이 적습니다. 하지만 주민번호, 계좌 번호 등은 각각 유일한 값을 가지므로 Cardinality가 높습니다. 따라서 인덱스를 설정할 경우 효율적으로 데이터를 찾을 수 있습니다. 보통 테이블당 3-5개의 인덱스 설정을 진행한다. (clustered index는 테이블당 하나, non clustered index는 여러개를 당연히 가질 수 있습니다.)
3. Index 종류
[1] Clustered Index
클러스터란 여러개를 하나로 묶는다는 의미입니다. 마찬가지로 Clustered Index는 기준 값이 비슷한 레코드끼리 묶어서 저장함을 의미합니다. 즉, 인덱스 테이블도 설정된 컬럼 값 기준으로 정렬되있고 실제 테이블도 설정된 컬럼 값 기준으로 정렬되있습니다.
이러한 특징으로 테이블 당 하나의 Clustered Index가 가능하고 데이터 조회 특히 범위 탐색에서 큰 장점을 가지고있습니다. SQL은 굉장히 많은 Join(특히 Nested Loop Join)연산이 이루어지고 이때 Index의 효과는 굉장히 큽니다. 하지만 데이터 삽입, 삭제, 수정시 데이터가 밀리고 당기는 등의 추가 연산이 발생하는 단점이 있습니다.
예를 들어, 어떤 학생 테이블에서 학번이 '10'으로 시작하는 학생들 찾고싶습니다. 이 테이블은 학번이 PK고, B+Tree로 인덱스가 구현되있습니다. 먼저 B+Tree로 인덱스 테이블에 '10' 시작 블럭을 Random Access를 수행합니다다. 이후에 차례로 데이터를 탐색하면됩니다. 이때 Non-Clustered Index와 달리 실 데이터 역시 PK로 정렬되있어 현재 기준 다음 학번을 탐색하고 싶어도 보통 같은 Block에 있는 경우가 많아 속도가 빠른 장점이 있습니다다. 당연히 I/O 연산 횟수를 줄일 수 있습니다.
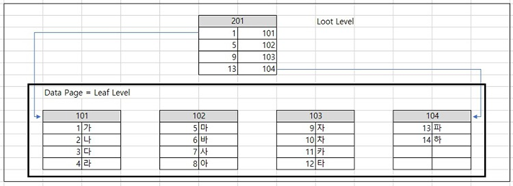
[2] Non Clustered Index
인덱스 테이블은 설정된 인덱스 컬럼 기준으로 정렬 되있지만, 실제 테이블의 레코드는 PK(Clustered Index)순으로 정렬되있지 않습습니다. 따라서 한 테이블에 여러개의 인덱스 설정이 가능하고 Clustered Index보다 범위 검색에 성능이 좋지 않습니다.
예를 들어, 상품 구입 테이블의 가격 컬럼에 Index가 B+ Tree로 구현되있고, Non-Clustered Index로 설정되있다고 가정해봅니다. 만약 10,000원에 해당 하는 상품 품목을 알기 위해 B+ Tree로 탐색을 한 후 접근 해야하는 부분에 Random Access를 수행합니다. 당연히 Index 설정 전과 비교할 때 불 필요한 (Full Scanning) I/O 연산이 줄어들어 빠르게 접근할 수 있습니다. 그런데 10,000원 ~ 20,000원 즉, 범위 검색을 수행한다면 실제 데이터는 뒤죽박죽 섞여 있어 성능이 Clustered Index보다는 느립니다. 왜냐하면 정렬된 상태의 다음 값이 같은 Block에 없는 경우가 많아 다른 Block에서 가져오는 횟수가 증가하기 때문입니다.
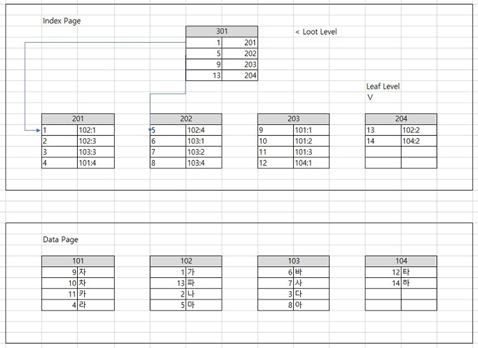
4. Index 구현 방식
[1] B Tree
- 각 노드는 Key와 Data로 구성된 Pair들로 구성되고 노드의 크기는 보통 Block의 크기와 동일합니다.
- 노드 안에 Key값들은 정렬된 상태이며, 자신의 Key 보다 작은것은 왼쪽 혹은 왼쪽 자식에 있고 자신의 Key보다 크면 오른쪽 혹은 오른쪽 자식에 존재합니다.
- 모든 Leaf Node는 동일한 Depth를 갖고 있어 탐색의 성능이 우수합니다.
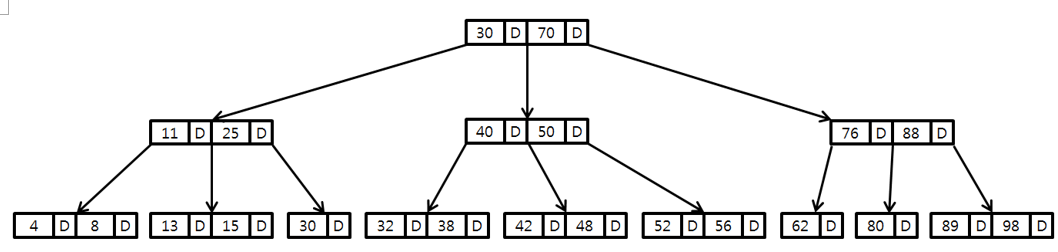
예를 들어, 아래 사진에서 '56' Key를 탐색하는 과정을 살펴봅니다.
- Root부터 차례로 탐색합니다.. '56'은 '30'과 '70' 사이에 존재하여 해당 자식 노드로 이동합니다.
- '56'은 '40', '50'보다 크니 맨 오른쪽의 자식 노드로 이동합니다.
- '52', '56'을 차례로 비교하여 탐색을 종료합니다.
[2] B+ Tree
- B-Tree와 유사하게 노드 안에 Key값들은 정렬된 상태이며, 자신의 Key 보다 작은것은 왼쪽 혹은 왼쪽 자식에 있고 자신의 Key보다 크면 오른쪽 혹은 오른쪽 자식에 존재합니다.
- B-Tree와 유사하게 모든 Leaf 노드는 동인한 Depth를 갖습니다.
- Inner 노드에는 Key만 저장되고, Leaf 노드에 Key와 Data를 함께 저장합니다. 또한 Leaf 노드에만 데이터가 저장되어 Leaf Node들을 포인터로 연결하여 B-Tree보다 쉬운 순회가 가능합니다. 즉, 범위 탐색 성능이 우수합니다.
- Inner 노드에 Key 값만 저장되므로 B-Tree보다 더 많은 Key 값을 담을 수 있어 키 값 탐색시 Disk를 읽어오는 횟수가 줄어듭니다. 즉, 트리의 높이가 낮아집니다.
- 물론, Inner 노드, Leaf 노드의 Key 값 중복의 단점은 존재합니다.
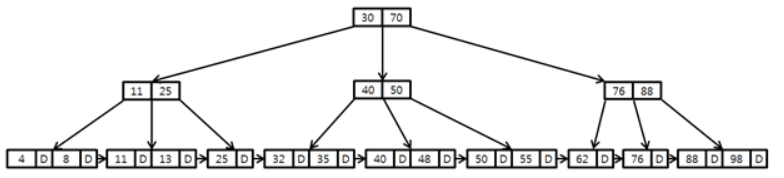
예를 들어 키 값이 '48'부터'62'까지 탐색한다고 가정해봅니다. B-Tree와 유사하게 루트부터 차근차근 비교합니다. '48'은 '30'과 '70' 키 사이에 존재하여 다음 자식으로 넘어가고 '48'은 '40'과 '50' 사이에 존재하여 다음 노드로 넘어 간후 '48'의 키 값을 찾습니다. 이후 키 값 '62'가 넘어가지 않도록 Leaf 노드에서 차례로 순회합니다. (Leaf 노드는 끝에서 링크드 리스트로 연결되어 있기 때문)
| 구분 | B- Tree | B+ Tree |
|---|---|---|
| 데이터 저장 | 리프 노드, 이너 노드 모두 데이터 저장 가능 | 오직 리프 노드에만 데이터 저장 가능 |
| 트리의 높이 | 높음 | 낮음 (한 노드 당 키를 많이 담을 수 있음) |
| 풀 스캔시 검색 속도 | 모든 노드 탐색 | 리프 노드에서 선형 탐색 |
| 키 중복 | 없음 | 있음 |
| 검색 | 자주 엑세스되는 노드를 루트 노드 가까이에 배치하면 빠르게 데이터 접근이 가능합니다. | 리프 노드까지 갈 경우 느릴 수 있지만 높이가 더 낮아 일반적으로 데이터 접근이 더 빠릅니다. |
| 링크드리스트 | 없음 | 있음 |
[3] Hashing Index
해싱이란 가변 크기의 인풋에서 가공 및 고정된 크기의 제한된 출력 값으로 변환하는 기법입니다. 해시 인덱스는 동등 비교 검색에서 상당히 좋은 이점을 갖고있습니다. B-Tree, B+Tree는 트리를 순회하며 I/O에 대한 연산이 많지만 해싱 인덱스는 Disk의 할일을 CPU에서 처리하여 보다 빠른 특징을 가지고 있습니다. 검색하고자 하는 값을 주면 Hash Function을 거쳐서 찾고자 하는 키 값이 포함된 버킷을 찾고, 버킷을 통해 해당 레코드의 주소를 알아냅니다.
하지만 특정 문자로 시작하는 값의 검색, 범위 검색, 정렬된 경과를 가져오는 등 '범위 검색'에서 성능이 급격히 안좋아 현재 DBMS는 인덱스 구현 방식을 B+Tree를 사용하고있습니다.
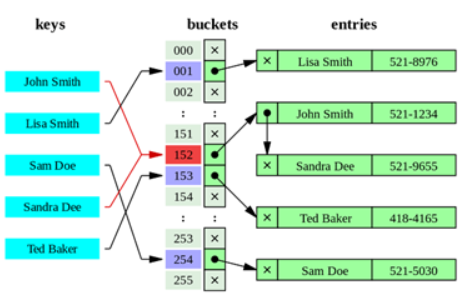
※ 인덱스 사용시 왜 B+Tree를 사용할까?
hash index는 SELECT의 조건에서 등호[=]연산에는 적합하지만 부등호 연산 [<, >]에서 성능이 좋지 않기 때문입니다.
5. 요약
예를 들어 배달의 민족같은 서비스는 주로 사용자가 지역별 배달 음식점을 조회하고 검색하는 기능이 메인이기 때문에 인덱스 기능을 잘 사용한다면 DB의 성능을 최적화시킬 수 있습니다. 반면에 페이스북같은 소셜 미디어는 새로운 게시글들이 사용자들에 의해 끊임없이 생성하기 때문에 인덱스 기능을 사용하는 것이 오히려 성능 저하에 원인이 될수도 있습니다. 하지만 대부분의 경우 인덱스의 성능은 엄청납니다.
결론적으로 인덱스는 '검색'에 최적화된 기능이기 때문에 삽입, 삭제, 수정이 자주 일어나는 비즈니스 로직 혹은 테이블 사용 용도에 따라 신중히 고민합니다.
