응용 프로그램 목적에 맞는 프로토콜을 결정합니다. 웹 서버 통신을 위한 HTTP, 파일 다운로드를 위한 FTP, 메일 전송을 위한 SMTP 등이 있습니다.
1. Application 계층의 구조
[1] Client - Server 구조
Client
- 서버에 Request 메시지를 보내고 서버로부터 요청 메시지를 브라우저에 보여주는 역할을 수행합니다.
- 정적/동적 IP 모두 보유할 수 있습니다.
- 지속적으로 서버와 연결하는것이 아닌 간헐적으로 연결을 끊었다 연결함을 반복합니다.
Server
- 클라이언트로부터 받은 요청을 알맞게 Response합니다.
- 어떤 상황에서도 패킷을 안전하고 빠르게 전달하는것이 목표입니다. 이를 위해 복잡한 아키텍처 및 로직을 개발합니다.
- 고정 IP 주소를 보유합니다.
웹서버는 HTTP 프로토콜로 통신하며, HTTP 프로토콜은 Client-Sever 구조를 따릅니다.
[2] Peer to Peer 구조
- 별도의 서버 없이 Peer끼리 직접 통신합니다.
- Peer는 연결을 끊었다 연결했다를 반복합니다.
- 각각의 Peer들은 동적 IP를 가지며, request / response를 둘 다 수행한다.
예를 들어 Peer A가 등장하는 시나리오를 생각해봅니다.
- Peer A가 등장하고 Peer 군집 Tracker 서버에게 알립니다. 이때 Tracker 서버는 Peer List에게 A의 등장을 알립니다.
- A는 Peer List들과 Chunk 파일을 교환합니다. 이때 Peer A는 send / receive를 동시에 수행합니다.
- 이때 Peer들은 받기만 해서도 안되고, 그렇다고 주기만 해서도 안되게 적절히 관리해줘야합니다.
Bit Torrent, VOIP(Skype) File Distrivution이 P2P 구조를 이용합니다.
2. HTTP
[1] HTTP이란
HTTP는 신뢰성있게 패킷을 주고 받는것을 지향합니다. 따라서 인터넷에서 하이퍼 텍스트를 Stateless, Connectionless하게 주고 받는 프로토콜입니다. 클라이언트가 서버에게 정보를 리퀘스트하고, 서버는 클라이언트에게 정보를 리스폰스합니다.
- 웹서버와 통신할 때 데이터 무손실이 중요하므로 Transport 계층에서 TCP 프로토콜을 혹은 HTTP/3에서는 UDP 기반의 quic이지만 Application 계층에서 손실 체크를 진행합니다.
- 서버가 유저의 모든 이력을 기억하는것은 과부화가 심해 Stateless합니다. 이에 대비책으로 쿠키와 세션을 활용합니다.
- 커넥션마다 소켓을 생성(TCP를 이용)하는데, 더 많은 클라이언트의 요청을 받아들이기 위해 Connectionless합니다.
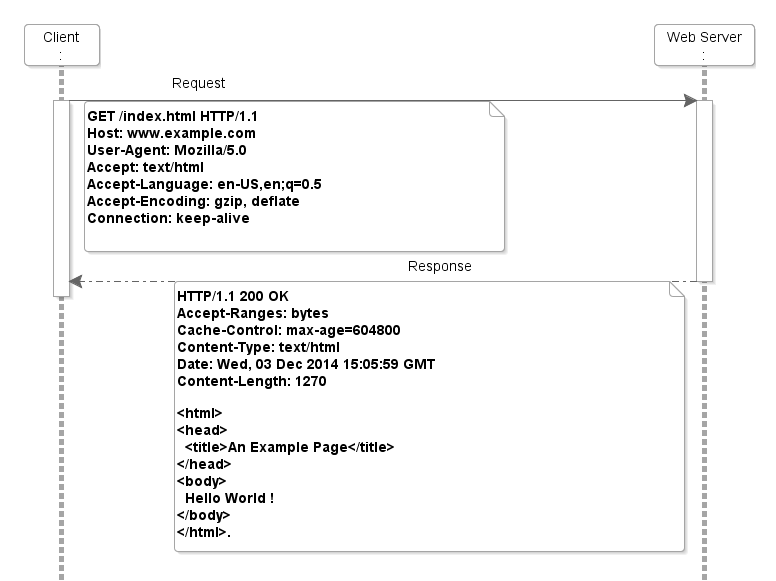
[2] HTTP Message 구조
- Start Line : 패킷이 어떤 메시지인지 설명합니다. Method, File, HTTP 버전, 응답 코드등을 명시합니다.
- Header : 메타 데이터입니다. 클론을 기준으로 Key : Value 형태를 이룹니다.
- Blank Line : Body에 담길 내용 전 개행문자입니다.
- Body : JSON, XML, HTML 등 데이터를 전달하거나 반환할 때 사용합니다.
[3] Method
- GET : 해당 URI의 리소스를 가져오고, Request Body에 정보를 담지 않습니다.
- POST : Request Body에 데이터를 담아서, URI가 가리키는 리소스에 데이터를 전송합니다.
- PUT : 서버가 갖고있는 리소스 전체를 수정합니다.
- DELETE : 서버가 갖고 있는 일부 리소스를 삭제합니다.
- PATCH : 서버가 갖고 있는 리소스 일부를 수정합니다.
[4] Status Code
- 1xx Informational (100, 101) : 서버가 요청을 받았으며, 서버에 연결된 클라이언트는 작업을 계속 진행하라는 의미입니다.
- 2xx Successful (200 ~ 206) : 성공입니다.
- 3xx Redirection (300 ~ 307) : 다른 곳으로 요청하세요.
- 4xx Client Error (400 ~ 417) : 클라이언트 잘못입니다.
- 5xx Server Error (500 ~ 505) : 서버 잘못입니다.
Example
- 101 : 다른 프로토콜 사용을 권장합니다. Http -> Https
- 200 : 성공을 의마합니다.
- 201 : 새로운 자원을 만듬을 의미합니다. 응답할 때, 새로 생성된 URI를 location header에 추가합니다.
- 202 : 클라이언트 요청이 폭주할 때, 요청 잘 받음을 응답하고 서버단 뒤에서 처리함을 의미합니다.
- 307 : 클라이언트의 요청이 리소스가 다른 URI에 임시적으로 있을 때 redirect함음 전달합니다. 302와 유사하지만 302는 redirect 시 동일 메서드를 보장하지 않습니다.
- 308 : 클라이언트의 요청이 리소스가 다른 URI에 영구적으로 있을 때 redirect함음 전달합니다. 301과 유사하지만 301은 redirect 시 동일 메서드를 보장하지 않습니다. 301, 302는 높은 확률로 GET으로 전달합니다.
- 401 : Unauthorized으로 인증이 필요합니다. 토큰을 재 발급할 때 필요합니다.
- 403 : Forbidden으로 사용자가 해당 리소스의 권한이 없을 때 사용합니다. 401은 인증 실패, 403은 인가 실패라고 볼 수 있습니다.
- 404 : 클라이언트가 요청한 페이지를 찾을 수 없을 때 사용합니다.
- 405 : 잘못된 Method 호출시 사용합니다.
- 504 : 내부 서버 오류시 전달합니다.
[5] Header
- URL 및 Host : 패킷 전달 주소를 지정합니다. URL은 인터넷 상 자원의 위치를 말하고, URI는 인터넷 상 자원의 리소소를 식별하기 위해 사용합니다. (URL <= URI)
- Cache-Control : 캐시 관련 정보를 설정합니다.
- Content-encoding : gzip, defalte, br 등의 메시지를 압축 방식을 지정 합니다.
- Content-type : text/html, application/json 등 보내주는 데이터가 어떤 타입인지, utf8 등 어떤 charset인지를 결정합니다.
- Accept : 수용 가능한 타입들을 열겨합니다. q(쿼터)에 따라 암묵적으로 우선순위대로 움직입니다.
- Accept Language : 사용할 언어가 담겨있으며, 여기서도 쿼터에 따라 어느정도의 우선순의를 선정합니다.
- Content-Length : 메시지 전체 길이로, 반대쪽에서 해석할 때 사용합니다. 서버 응답시 필수 정보입니다.
- Connection : 패킷 연결 지속 여부를 결정합니다. keep-alive 할지 close 할지 환경에 맞게 선택합니다. 대규모 트래픽에서 close 한다면 더 많은 클라이언트를 수용할 수 있지만 웹 페이지에서 HTML, CSS 구조는 보이는데 리소스는 안보이는 등의 문제가 발생할 수 있습니다. 왜냐하면 연결을 끊었다 연결했다를 반복하여 딜레이가 발생했기 때문입니다.
[6] Cache of Header
Conditional GET
클라이언트는 이전에 한번 요청해서 돌려받은 리소스를 재 요청 할 때 불필요한 트래픽을 줄이기 위해 해당 리소스가 변경된 경우에만 다시 보내달라고 요청할 수 있습니다. 이때, last-modified(서버 생성 권한)와 if-modified since 헤더를(클라이언트가 보내는) 참조합니다.
- 클라이언트는 서버에게 리소스를 요청하고, 서버로부터 리소스와 last-modified 응답 헤더를 받습니다.
- 이후, 서버에게 해당 리소스를 보낼 때 last-modified 값이 담긴 if-modified-since 헤더를 함께 전송합니다.
- 서버에서 if-modified-since 헤더를 보고 변경 일시가 다른 경우, 최근 변경 일시 값을 last-modified에 담음 정보와 변경된 리소스 데이터를 바디에 담아 전송합니다.
- 서버에서 if-modified-since 헤더를 보고 변경 일시가 같은 경우, 최신 정보임을 클라이언트에게 전송합니다.
ETag
Conditional GET의 목표와 같습니다. 즉, 중복된 불필요한 트래픽을 줄이기 위해 사용합니다. 생성 권한은 서버가 갖고 있으며, 리소스가 바뀌면 ETag 값이 변경됩니다.
- 클라이언트가 리소스를 요청하고, 서버가 응답헤더에 ETag 값을 전송합니다.
- 클라이언트는 이후, if-non match 헤더 값에 ETag 값을 담아 전송합니다.
- 서버에서 if-non match 값을 비교하여 값이 같다면, 다른 곳을 봐라. 즉, 캐시를 보라는 의미로 300번대 304 Not Modified 응답코드를 전송합니다.
- 만약 ETag 값이 클라이언트가 알고 있는 값과 다른 경우, 200 OK 응답과 함께 변경된 ETag와 body를 전송합니다.
If-modified와 ETag 모두 같은 기능을 하지만 둘 다 사용함을 권장합니다. 하나만 남기면 ETag가 강력하지만 둘 중 하나라도 다르면 캐시를 이용하지 않고 무조건 새로 받습니다.
Cache
conditional get, ETag를 사용해도 일단 클라이언트는 서버로부터 변경 여부를 판단하기 위해 RTT의 비용이 반드시 필요로 합니다. 이를 보완하기 위해 Cache-Control과 Expire 헤더를 사용합니다. 이 헤더들은 컨텐츠가 얼마나 오랫동안 신선한 상태인지를 알려줍니다. 캐시가 만료된 경우를 stale cache, 만료되지 않은 경우를 fresh한 상태로 부릅니다.
보통 html은 캐싱을 덜하고, 리소스는 적극적으로 갱신합니다. 사실 캐싱 때문에 다양한 에러가 발생하기 때문에 동기화 고려는 반드시 필요합니다.
tag value
Http는 문서가 완료되기 전까지 얼마나 올랫동안 캐시될 수 있게 할것인지 서버가 설정하는 여러 방법을 제공합니다. 위에서 말한 expire 태그는 절대 유효 기간을 명시하며 아래는 cache control tag 값들을 설명합니다. expires 헤더가 없는 경우, 캐시는 알아서 적당히 Freshness Lifetime을 계산합니다.
- no-cache : 진짜 이 캐시를 사용해도 되는지 여부를 체크합니다.
- no-store : 캐시가 응답의 사본을 만듬을 금지합니다.
- max-age : 문서 최대 기간을 설정합니다.
정리
ETag, Last-Modified 헤더를 통해서 문서의 마지막 수정일을 알 수 있습니다. If-Modifieed-Since와 If-Non-Match를 요청 헤더에 담아 보내면, 서버는 요청을 해석하여 리소스 수정 여부를 판단하고 그에 맞는 응답을 전송합니다. 이러한 과정은 실서버에 한번 왔다 갔다 해야하는 RTT의 비용을 추가로 요구합니다.
이러한 네트워크 비용을 줄이기 위해 Cache-Control, Expire 헤더를 사용합니다. 리소스의 신선도를 체크하여 fresh 하다면 해당 데이터를 사용하고, 만약 stale한 상태면 실 서버에 If-Modified-Since, If-None-Match 헤더를 담아 전송합니다. 값이 변경 될 경우, ETag, Last-Modified, 변경 데이터를 받습니다.
3. Cookie & Session
HTTP는 Stateless하고 Connectionless하기 때문에 이전 정보를 기억하지 못합니다. 정보가 유지되지 않으면 매번 페이지를 이동할 때마다 로그인을 하거나, 상품을 선택했는데 구매 페이지에서 다시 상품을 선택해야하는 경우도 발생합니다. 그렇다고 서버가 클라이언트 상태 정보를 모두 기억하는 것은 부하가 심하고, 연결을 계속 유지한다면 서버는 한정된 클라이언트만 수용할 수 있습니다. 따라서 Cookie와 Session 개념이 도입됐습니다.
Cookie
- 클라이언트에 저장되는 정보입니다.
- 패킷의 유저를 식별할 때 사용합니다.
- 방문했던 사이트를 다시 방문하지 않을 때, 혹은 ID / PW 자동 입력시 사용합니다.
- 팝업창을 통해 "오늘 이 창을 다시 보지 않기"를 체크할 때 사용합니다.
Session
- 서버에 저장되는 정보입니다.
- 유저를 식별하는 토큰을 저장합니다. Aceess Token, Refresh Token 중 자주 바뀌는 Access Token을 저장하기도합니다.
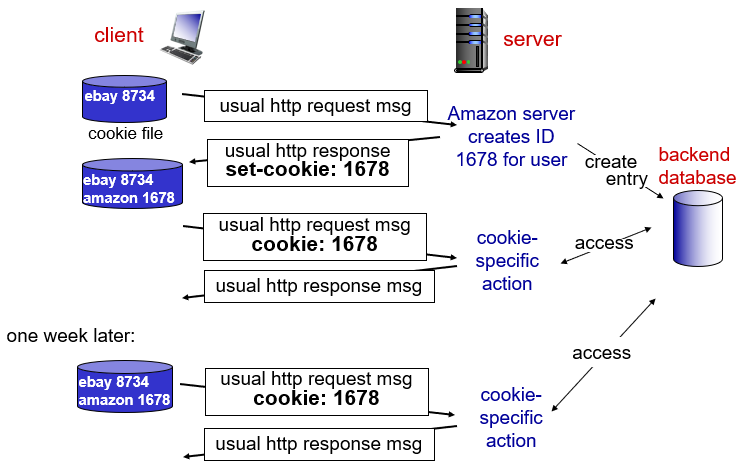
예를 들어 로그인한 상태에서 클라이언트와 서버 사이의 패킷을 주고 받는 상황을 가정합니다.
서버에서 Set-Cookie 응답헤더를 통해 토큰을 클라이언트에게 보내면 클라이언트는 쿠키를 보관하고 있습니다. 이후 패킷 전달시 Cookie 헤더로 토큰을 서버에 전송합니다. 서버는 토큰을 비교하여 패킷이 어떤 유저를 지칭하는지 알게됩니다. 요즘 추세는 쿠키에 많은 정보를 안 담는 추세입니다. 즉, 세션에 맵핑될 특정 사람을 추상화(토큰 같은 것)할 정보만을 쿠키에 담습니다.
4. DNS
[1] Domain Name System이란
- 웹 서버 주소를 IP로 기억하는것은 가독성이 너무 떨어지고, 도메인 이름으로 통신하는것은 실행효율이 떨어집니다. 따라서 DNS 서버는 IP주소와 도메인 이름을 맵핑한 테이블을 저장하여 IP <-> 도메인을 변환하는 기능을 제공합니다.
- 잘못된 URL을 검색해도 의미있는 URL로 변환시켜 주기도 합니다.
- DNS 서버에서 웹서버의 IP 주소를 알려줄 때 로드를 분산시켜 항상 같은 주소의 IP 주소를 알려주는 것이 아닌 상황에 맞게 같은 기능을 수행하는 다른 웹 서버의 IP 주소를 알려 주기도 합니다.
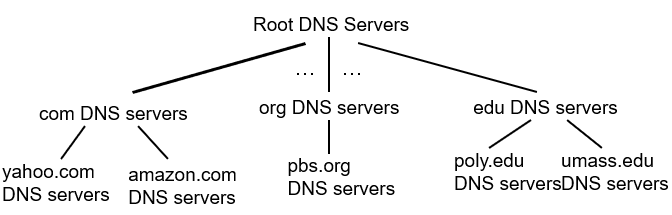
[2] 계층 구조
DNS는 계층 구조로 관리되는데 Root & TLD & Authoritative + Local DNS로 이루어집니다.
- Root DNS는 전 세계에 약 9개? 정도 보유하며 그 밑에 com, org와 같은 큰 규모 회사들의 IP를 보유합니다.
- Top Level Domain은 각 기관별 naver.com, google.com 등의 IP 주소를 보유합니다.
- Authoritative DNS는 이제 해당 IP와 관련된 정보를 보유합니다. 즉, host와 ip를 맵핑한 테이블을 보유합니다.
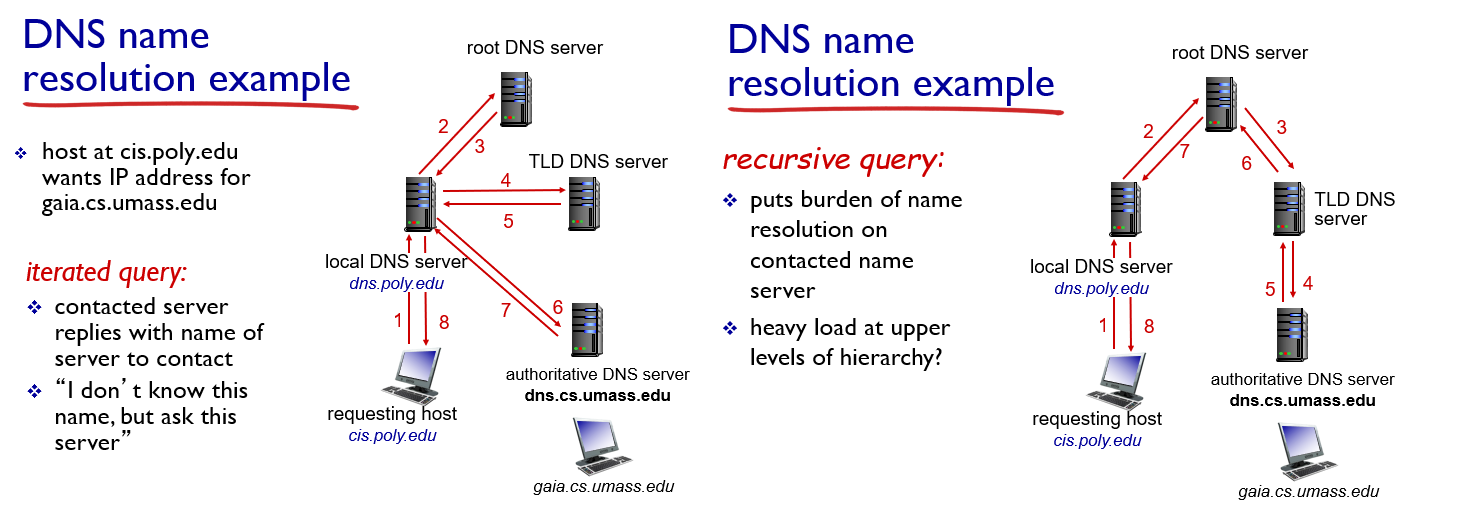
Local DNS Server
계층구조가 아닌 DNS 캐시 서버의 개념입니다. 즉, Domain, IP Mapping된 캐싱 정보 테이블을 유지합니다. 당연히 동기화 문제도 있지만 성능적으로 굉장히 효과적입니다. Host에서 Mapping IP를 조회할 때, 일단 Local DNS Server에 패킷을 보내 정보 유무를 판단하며, 정보가 있다면 해당 IP를 받아 오고, 없다면 Root DNS Server로 전송합니다.
IP 주소를 가져오는 방식
Recursive query의 방식은 "물어보면 책임지고 구해서 알려준다"입니다. 하지만 root에 들락날락하는 정보가 더 많아져서 Load가 더 심해지는 단점이 있습니다.
5. HTTP Version
[1] HTTP/0.9
- 단순히 HTML 파일만 전송하는 프로토콜
- 상태 코드를 HTML에 포함하여 회신
- 사용 가능 메서드는 GET
- HTTP Header가 존재하지 않음
Request
GET /mypage.html
Response
<HTML>
Simple Page
</HTML>[2] HTTP/1.0
- 몇가지 헤더 추가
- Content Type이 추가되어 html이 아닌 다른 형태의 문서도 전송
- HTTP 버전 송신 & 상태 코드 회신
Request
GET /mypage.html HTTP/1.0
User-Agent: NCSA_Mosaic/2.0 (Windows 3.1)
Response
200 OK
Date: Tue, 15 Nov 1994 08:12:31 GMT
Content-Type: text/html
<HTML>
A page with an image
<IMG SRC="/myimage.gif">
</HTML>[3] HTTP/1.1
- 커넥션을 재사용하여 3 hand shake 과정 비효율을 감소
- 파이프라인을 추가합니다. 즉 첫번째 응답이 오기 전 두번째 요청을 전송합니다.
Head Of Line Blocking (HOL)
파이프라인을 사용하여 클라이언트에서 1번 패킷과 2번 패킷 등을 연속해서 보냅니다. 그런데 1번 패킷이 완료되는데 오래 걸리면 2번 패킷은 작업이 완료됨에도 불구하고 대기합니다. 이는, HTTP 특성상 요청 순서대로 패킷을 수신해야 되기 때문입니다. 이렇게 자신의 작업이 완료됨에도 불구하고 앞의 패킷 때문에 대기하는 문제를 HOL이라고 합니다.
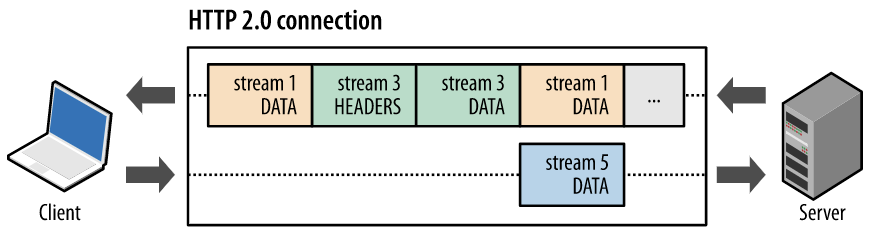
[4] HTTP/2.0
HOL 문제를 해결하기 위해 노력합니다.
Multiplexing
- 하나의 커넥션 안에 스트림이라 불리는 가상 쌍방향 시퀸스를 만들어 문제를 극복합니다.
- 단일 연결 안에서 여러개의 데이터가 섞이지 않게 보내는데, 약 6개의 커넥션을 병렬 처리합니다.
- 커넥션 안에 스트림을 나눠 요청과 응답의 순서에 구애를 덜 받습니다.
[5] HTTP/3.0
HOL, 통신하는데의 latency 등 이런 근본적 문제는 TCP를 사용하면서 발생했습니다. 이전에는 좋지 않은 인프라 때문에 여러가지를 체크 해야 햇지만, 현재는 인프라가 많이 좋아진 상태입니다. 즉 과도한 체크로 인한 오버헤드를 줄인 UDP에 근거한 QUIC 프로토콜을 도입했습니다.
6. HTTPS
[1] HTTPS란
HTTPS는 HTTP + TLS(이전에는 SSL로 사용) 프로토콜로, 대칭키와 공개키를 혼합한 방식입니다. 즉 대칭키를 주고 받을 때는 공개키를 사용하고, 이후 대칭키를 사용하여 패킷을 전달합니다.
HTTP는 서버와 클라이언트 사이에 HyperText를 주고받는 프로토콜입니다. 텍스트를 주고 받기 때문에 패킷을 중간에 인터셉트하면 데이터 유출이 발생합니다. 따라서 HTTPS는 데이터를 주고 받는 과정에서 보안요소인 SSL Protocol을 추가한 프로토콜입니다.
- 클라이언트는 자신이 위조된 서버가 아닌 진짜 서버와 통신함을 알 수있습니다. 왜냐하면 서버로부터 받은 인증서가 신뢰할만한 CA 인증서이기 때문입니다.
- 클라이언트와 서버는 패킷의 인터셉터 즉, 도청에 대한 걱정 없이 통신할 수 있습니다.
[2] 대칭키와 공개키
Symmetric Key
암호화, 복호화에 같은 암호키(대칭키)를 사용하는 방식입니다. 동일한 키로 암호화/복호화 하기 때문에 간단하지만 초기에 대칭키 전달 과정에서 해킹 위험에 노출됩니다.
Public Key
서로 다른 두 개의 키가 존재하고 비밀키로 암호화하면 공개키로, 공개키로 암호화하면 비밀키로 복호화 할 수 있습니다. 공개키는 누구나 얻을 수 있고 개인키는 서버 자신만 갖고 있습니다.
대칭키보다 해킹에 위험에 덜 노출되지만 구조가 복잡한 단점이있습니다.
※ 개인키로 암호화한 패킷은 누구나 해석 가능하지만 해당 패킷이 본 서버에서 온 응답임을 확신할 수 있습니다.
통신 과정
- A가 웹 상에 공개된 B의 공개키로 암호화하여 B에게 보냅니다.
- B는 자신의 비밀키로 복호화 하고 평문을 확인합니다. 이후 A의 공개키로 암호화하여 A에게 보냅니다.
- A는 자신의 비밀키로 암호화된 응답문을 복호화합니다.
SSL 통신 방식
- A가 앞으로 사용할 대칭키를 B의 공개키로 암호화 한 후 전송합니다.
- B는 암호문을 받고 자신의 비밀키로 복호화합니다.
- B는 A로부터 얻은 대칭키를 적당히 수정하여 대칭키를 암호화 한 후 전송합니다.
- A는 자신의 개인키로 복호환 후 앞으로 디 대칭키를 암호화하여 통신합니다.
즉, 대칭키를 주고 받을 때만 공개키 암호화 방식을 사용하고 이후에는 대칭키 암호화 방식으로 통신합니다.
[3] HTTPS 통신 흐름
- 알파 서비스가 HTTPS 사용을 위해 CA 기업에게 "우리 공개키 관리해줘"와 함께 일정 금액을 지불합니다.
- CA 기업이 승인하면 CA 기업 이름, A의 공개키, 암호 방식 등이 담긴 인증서를 줍니다. 이 인증서는 CA 기업의 개인키로 암호화 돼있습니다. CA 개인키로 암호화된 인증서이기 때문에 알파 서비스가 신뢰성을 획득합니다.
- 이제 외부 클라이언트에서 알파 서비스에 패킷을 보내는데, 아무런 암호화된 정보가 없다면 알파 서비스는 CA기업으로부터 받은 인증서를 클라이언트에게 전송합니다.
- 브라우저에는 대부분의 유명 CA 기업 공개키들이 존재하기 때문에 클라이언트는 인증서를 복호화하여 알파 서비스의 공개키를 획득합니다.
- 이후 SSL 인증 방식으로 알파 서비스와 클라이언트가 대칭키를 주고 받아 통신을 진행합니다.
