1. Network Layer란?
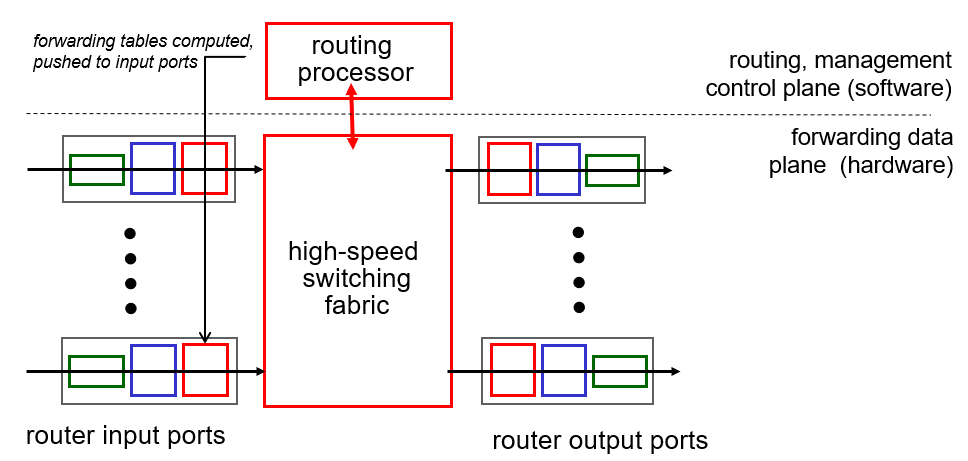
네트워크 계층의 핵심 기능은 출발지부터 목적지까지 길을 찾아주는것입니다. 경로를 계산하고, 경로에 맞게 패킷을 알맞은 라우터로 전송합니다. 이를 위해 Routing과 Forwarding 기능을 제공합니다.
Routing
Routing Processor에서 Routing Algorithm으로 나온 결과 값(출발지부터 목적지까지의 최적 경로)을 Forwarding Table에 저장합니다. 예를 들어, A 목적지로 가려면 알파 포트로, B 목적지로 가려면 베타 포트로 보내는것과 유사하게 테이블에 맵핑됩니다. 즉, 포워딩 테이블에는 목적지 IP와 포트 번호가 저장됩니다.
Forwarding
Data Plane 영역에서 입력으로 들어온 패킷 헤더 IP와 포워딩 테이블을 참조하여 적절한 포트로 패킷을 보냅니다. 이때 인풋, 아웃풋 포트 패킷 속도 차이 때문에 queueing delay or loss가 발생할 수 있어 queue buffer가 필요합니다.
네트워크 계층 신뢰성
- 비신뢰성 : 전송을 보장하지 않습니다. 전송이 되지 않을 수도, 순서가 다를수도, 심지어 중복된 패킷을 전송할 수도 있습니다.
- 비연결성 : 전송을 위한 전제로 연결을 성맆하지 않습니다. 일단 패킷을 전송하고 봅니다.
2. IP Address
[1] IP
IP 주소는 호스트 혹은 라우터 인터페이스를 식별하는 32bit 식별자입니다. 편의상 십진수로 0 ~ 255로 4자리로 표현합니다.
Example) 127.0.0.1
IP주소는 Network Part와 Host Part로 이루어집니다. 네트워크 파트는 네트워크들을 구분해주는 영역이며 호스트 파트는 한 네트워크 안에서 여러 장비를 구별해주는 역할을 담당합니다. 네트워크 파트가 같은것은 하나의 브로드캐스트 영역이란 말 동시에 라우터를 거치지 않고 통신이 가능한 영역입니다.
32비트 주소는 IPv4 기준입니다. 기존 주소를 약 99% 사용중이며 IPv4 신규 주소 할당은 이미 중지 되었습니다. 따라서 주소 고갈 문제를 어떻게 해결하는지에 대해 다양한 노력이 있습니다.
Example) CIDR, DHCP, NAT, IPv6
[2] CIDR
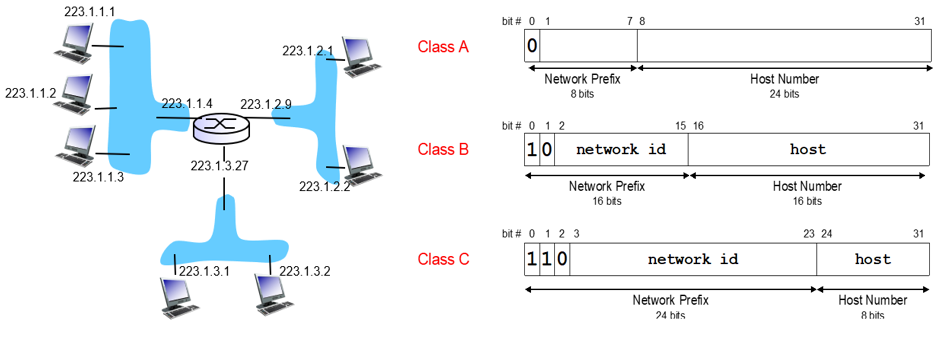
IPv4 주소 체계
IPv4에서 네트워크, 호스트 파트의 영역 크기를 Class로 구별합니다. A ~ E 클래스가 존재합니다. 우리나라에 아마 A Class는 없고 SKT/KT 정도가 B Class를 가지고 하위 조직에게 주소를 할당시켜줍니다.
또한 호스트 파트가 모두 0인것은 네트워크 자체를 의미하고, 모두 1인것은 브로드캐스트를 나타냅니다.
- A Class : Network(8) + Host(24)
- B Class : Network(16) + Host(16)
- C Class : Network(24) + Host(8)
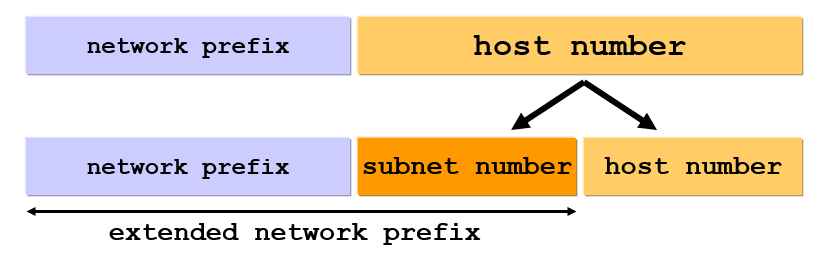
Subnet
네트워크 파트가 많이 필요하거나 혹은 호스트가 별로 필요 없을 경우 Class A, Class B는 적절치 않습니다. 브로드캐스트시 필요 이상의 오버헤드가 발생할 수 있고, IP를 무분별하게 사용할 수 있습니다. 따라서 기존의 Host Part에서 다시 Network Part + Host Part로 분할하는 작업을 subneting이라하며, 이떄 나누어진 네트워크를 Subnet이라고 합니다. 서브넷 간의 통신은 라우터를 거치며, 서브넷이 다른것은 네트워크가 다름을 의미합니다. 이때 서브넷으로 나누는 방법은 기존 IP 주소에게 Subnet Mask를 씌우면 됩니다.
Example
- IP Address : 153.070.100.0000 0010 (Class B)
- Subnet Mask : 255.255.255.1100 0000
- Subnet : 153.070.100.0000 0000 (밑줄은 나뉘진 네트워크로 밑줄 이후는 호스트 부분입니다.)
Example
주어진 네트워크가 201.222.5.0 (Class C)이고 호스트 수가 5개 이상, 서브넷 수가 20개 이상이 되도록합니다.
- 201.222.5.0 -> 11001001. 11011110. 00000101. 00000000 (Class C)
- 255.255.255.0 -> 11111111. 11111111. 11111111. 00000000 (Subnet Mask를 적용해야하는 부분)
- 20개 이상의 서브넷 : 2^5개
- 5개 이상의 호스트 : 2^3 –2개 (호스트 파트 전부 0인 경우 네트워크 주소, 전부 1인 경우 브로드캐스트 주소이므로 사용 못합니다.)
- Subnet Mask=>255.255.255.11111(Subnet)000(Host)
즉 CIDR은 기존 IP 주소의 클래스 체계를 쓰는것보다 더욱 능동적으로 IP 주소를 사용하는 방식입니다. 이를 위해 Subnet Mask를 활용합니다.
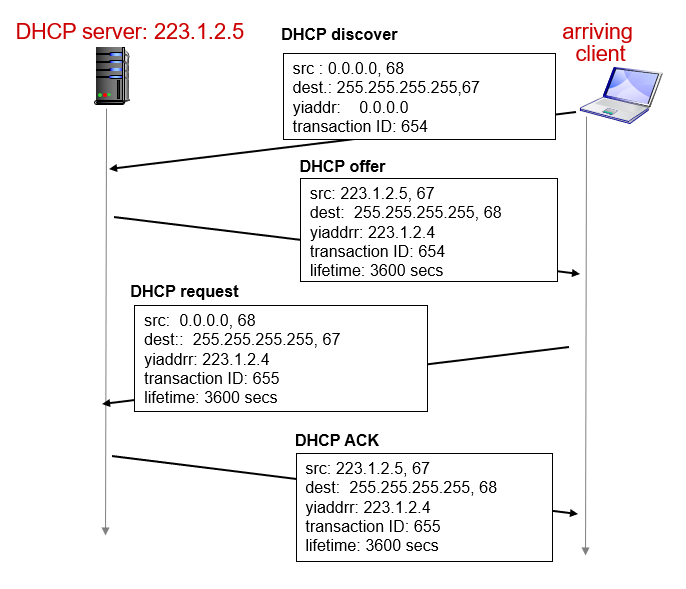
[3] DHCP
- DHCP란 호스트가 IP를 필요로할때마다 서버로부터 IP를 할당/해제 받는 방식입니다. 즉, 호스트가 네트워크에 접속할 때 서버로부터 IP를 할당 받고 필요시 다시 IP를 해제하는 방식입니다.
- IP를 할당 받는 방식은 서버처럼 고정 IP를 할당 받을 수도 있지만, 카페에서 노트북을 와이파이에 연결하는 경우 동적 IP를 할당받기도합니다. 이때 DHCP가 효과적입니다.
- DHCP로부터 자신의 IP, Subnet Mask, First Hoop Router, DNS IP 등의 정보를 얻을 수 있습니다. 따라서 카페나 무선 와이파이에 연결했을 때 처음에 DHCP에 접근하여 이러한 정보를 얻습니다.
- IP 주소를 재활용하여 효율적이고 모바일처럼 네트워크 접속 / 해제가 많은 경우 효과적입니다.
[4] Network Address Translation
내부의 모든 호스트들에게 부여 할 공인 주소는 한정되있고 인터넷을 모두 사용할 경우가 있습니다. 이때 내부에서는 비공인 IP 주소를 사용하다가 외부로 나갈 때만 공인 IP 주소를 부여 받아 사용합니다. 이때 각 호스트들을 포트로 구별합니다. 이렇게 된다면 다수의 비공인 IP 주소 사용자가 한정된 공인 주소를 활용하여 인터넷을 사용할 수 있습니다.
공인 IP 주소를 아낄 수 있지만 포트번호로 호스트를 구별하는 단점이 있습니다. 포트 번호는 프로세스를 구별해야 사용하는데 말이죠. 또한 서버는 먼저 리퀘스트를 보내지 않지만 NAT 라우터는 리퀘스트를 먼저 받아야 해당 LAN의 IP 주소와 Port를 맵핑 시킬 수 있습니다. 따라서 NAT 안에 서버를 두는것은 적절치 않습니다.

[5] IPv6
- 128 bit 주소 체계로 잡아 주소 부족의 문제점을 해결합니다.
- 헤더의 길이가 고정된 40 byte입니다. 헤더의 길이가 고정되 라우팅시 HW로 빠르게 헤더 정보를 체크할 수 있습니다.
- IPv4와 IPv6는 공존하며 사용하는데, 이중스택, 터널링 등 다양한 방식으로 상이한 주소 체계를 해결합니다.
3. Routing Protocol
Routing Algorithm으로 최적의 경로를 계산합니다. 그래프 자료구조를 활용하는데 라우터 및 호스트는 각 노드를 가리키며 링크의 bandwidth, 비용 등을 고려하여 edge를 표현합니다.
[1] Link State Algorithm
- 모든 경로 상태 정보(bandwidth, reliable, cost etc)를 Topological DB에 저장합니다.
- Topological DB를 이용하여 자신을 Root로 하는 Shortest Path First Tree를 구하는데 이때 다익스트라 알고리즘을 활용합니다. 이후 결과 값을 Forwarding Table에 저장합니다.
- 라우터가 모든 경로 정보를 알고 있어 좀 더 정확한 길찾기를 수행하고, 변경에 필요한 부분만 라우터간 교환하므로 Convergence Time이 짧습니다.
- Convergency Time : 라우팅 테이블에 변화가 생길 경우 이 변화를 모든 라우터가 알 때까지 걸리는 시간
- 하지만 모든 라우팅 정보를 알아야하므로 메모리를 많이 사용하고 SPF 계산의 많은 CPU 처리가 필요합니다.
- 주로 대규모 네트워크에 적합하며 OSPF 라우팅 프로토콜에서 사용합니다.
[2] Distance Vector Algorithm
- 라우터는 Hoop Counter(목적지까지 몇개의 라우터를 거치는지)와 그 목적지까지 가려면 어떤 인접 라우터를 거쳐야하는지 방향을 저장합니다. 즉, Link State Algorithm처럼 모든 경로 정보를 저장하는것이 아닙니다.
- 인접 라우터들과 주기적으로 라우터 정보를 교환해서 자신의 정보가 변했는지를 확인해야합니다. 이때 Bellman Ford Equation을 이용합니다.
- 라우팅 테이블을 줄여 메모리가 절약되고 구성 자체가 간단합니다. 하지만 인접 라우터들과 주기적으로 라우팅 테이블을 교환해서 자신의 정보에 변화가 생긴지를 확인해야합니다. 즉 트래픽을 쓸데 없이 낭비하고 Convergency Time이 너무 느립니다.
- 주로 소규모 네트워크에 적합하며 RIP 라우팅 프로토콜에서 사용합니다.
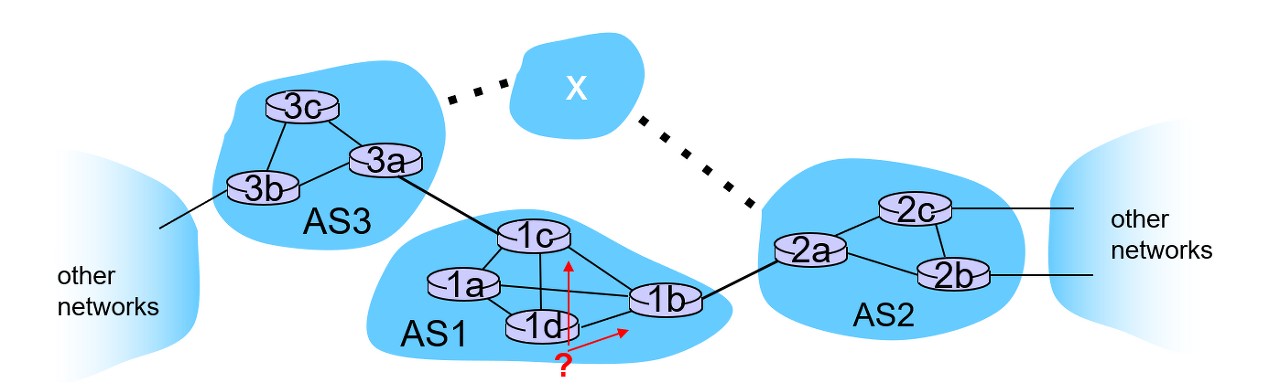
[3] Autonomous System [AS]
- 어떤 라우팅 프로토콜을 사용하든 네트워크 규모가 커지면 성능 및 보안상의 문제가 발생합니다. 이러한 물제를 해결하고자 AS 개념이 도입됐습니다.
- Autonomous System이란 한 기관에 속한 라우터들의 집합입니다. 이제 네트워크의 영역을 구별하여 라우팅 프로토콜을 적용할 수 있습니다. 네트워크 영역 안에 있는 라우터들만 관리하므로 성능 및 비용의 이점을 얻을 수 있습니다.
- 목적지가 같은 AS 내부에 있을 경우 Intra AS Routing, 목적지가 AS 외부에 있을 경우 Inter AS & Intra AS Routing 알고리즘을 협력하여 사용합니다.
- Intra AS Routing은 얼마나 길을 빨리 찾는지가 중요한 반면 Inter AS Routing은 출입국 심사와 같이 필터링에 초점을 맞춥니다.