1. Backend란
[1] Frontend vs Backend
- Frontend : 유저와 시스템의 인터페이스로, 유저의 인풋을 처리하여 적절한 아웃풋을 제공합니다. 보통 화면으로 제공하는데, 플랫폼에 따라 web, android, ios 등이 있습니다.
- Backend : 클라이언트의 요청을 안전하고, 빠르게 응답 해줍니다. 더 나아가 DL/ML에서 필요한 데이터를 관리합니다.
클라이언트의 요청이 적다면 즉, 트래픽이 적다면 복잡한 로직과 아키텍처를 필요로하지 않습니다. 하지만 수많은 사용자의 요청과 데이터 분석을 위해 아래와 같은 복잡한 구조, 효율적인 프로그래밍을 사용합니다.
[2] Backend Response > 데이터 전송
- HTML : 태그를 활용하여 다양한 컨텐츠를 '보여주는' 목적
- XML : HTML과 비슷한 마크업 언어로, 컨텐츠를 '전송'할 목적
- JSON : Key & Value로 이루어지며, 데이터 오브젝트를 '전송'할 목적
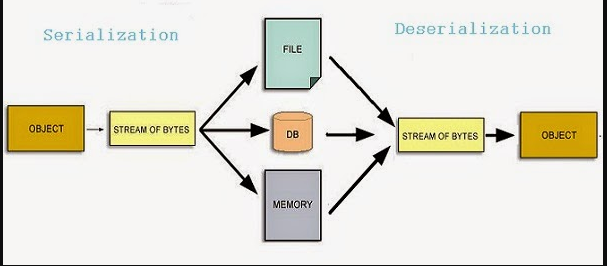
초기에 인터넷은 정보를 보여주는 목적이었고 그래서 HTML이 존재했습니다. 하지만 사용자가 많아지면서 언어와 기종에 상관없이 순수 데이터 전달의 니즈가 발생했습니다. 이 과정에서 XML, JSON이 나왔고 직렬화 & 역질렬화 작업이 필요로합니다. 즉, 언어, 기종에 상관없이 통신 시 Stream Of Bytes를 사용합니다.
- 직렬화 : 자료구조 혹은 오브젝트 상태를 통신 시 사용할 포맷 Stream Of Bytes로 변환해줍니다.
- 역직렬화 : Stream Of Bytes를 원래의 자료구조 혹은 오브젝트 상태로 복원합니다.
2. Web Architecture Summary
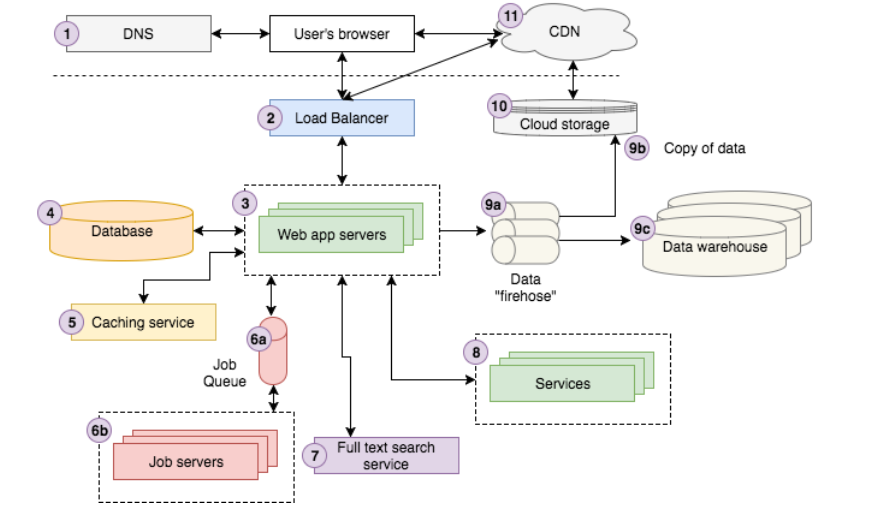
유저가 구글에서 '아름다운 강산'을 검색하면 브라우저에 관련 사진, 사이트들이 나옵니다. 원하는 링크를 클릭하여 사이트를 방문하기도 하고, 다른 결과를 얻기 위해 새롭게 검색하기도 합니다.
- 각각의 웹 사이트들은 Domain과 IP 주소로 맵핑되기 때문에 브라우저 내부에서는 DNS 서버에 접근하여 웹 사이트 IP 주소를 획득합니다.
- 브라우저의 요청은 로드 밸런서에 도착하고, 알고리즘에 맞게 WAS 중 하나를 선택하여 요청을 처리합니다. (특정 상황에서 CDN에 접근하여 WAS를 거치지 않을 수도 있습니다.)
- WAS는 캐싱 서비스에서 필요한 정보를 가져온 후 더 필요한 정보는 Database 서버에 요청합니다.
- 지금 당장은 필요 없지만 추후 작업을 위해 특정 잡을 잡큐에 보냅니다. 잡 서버는 큐에 추가된것들을 비동기로 처리한 후 DB에 결과를 업데이트합니다.
- 이후에 우리는 full text search 서비스로 새로운 검색을 시도합니다. 사용자 성향을 반영하기 위해 사용자가 구글에 로그인했다면 그의 계정 정보를 계정 서비스에서 가져옵니다. 일련의 작업들이 끝난 후 클라우드 스토리지에 시스템을 기록하고, 그 정보는 분석가들이 비즈니스에 활용하도록 데이터 웨어하우스에 저장합니다.
- 서버는 로드 밸런서를 통해 사용자에게 데이터를 제공합니다. 필요에 따라 CDN에 연결된 우리의 클라우드 스토리지에서 JS, CSS, 이미지와 같은 정적 데이터를 직접 제공하기도합니다.
2. Domain 소개
[1] DNS
- Domain과 IP 주소를 변환시켜줍니다. 이는 '가독성', '라우팅' 기능을 위해 존재합니다.
- 잘못된 URL을 입력했을 때 적절한 URL로 변환시켜줍니다.
- DNS 내부적으로 Load Balancer를 처리할 수도 있습니다. (하기 사진 참조)
[2] Load Balancer
트래픽이 급증하면 성능이 더 좋은 서버를 구축하거나 혹은 같은 성능의 서버를 여러대 구축해야됩니다. 웹 서버는 언제든지 고장날 수 있고, 비용적 측면 때문에 같은 성능의 서버를 여러대 구축합니다.
즉, 클라이언트의 요청을 로드밸런서에 연결하고, 로드 밸런서는 이들 서버에 과부화가 걸리지 않도록 요청을 적절히 분배해줍니다.
- 로드 밸런서가 패킷을 분배할 때 source ip, port, round robin 등 다양한 방식으로 분할합니다.
- 로드밸런서는 public ip를 사용하고 이후 was들은 private ip를 사용기도합니다.
- L4 LB : TCP/UDP 계층에서 패킷 내용은 안보고 ip, port 만으로 패킷을 분할합니다.
- L7 LB : 패킷의 내용을 보고 자세히 분할할 수 있습니다. chrome, edge 등 브라우저로 분할 하거나 /main, /sub 등의 부하가 예층 가능한 것들을 나눠서 처리하기도 합니다.

[3] Web Application Server
Request가 들어오면 핵심 비즈니스 로직을 실행하고, 그 결과를 HTML 혹은 JSON 등으로 전달합니다.
- 비즈니스 로직을 처리하다보면 DB, caching, service server, job server, cloud storage 등 다양한 백엔드 인프라와 데이터를 주고 받습니다.
- 성능을 위해 많은 WAS들을 로드 밸런서에 연결하여 로직을 처리합니다.
- 필요에 따라 WAS 앞에 Web Server를 두어 정적 페이지 요청시 WAS까지 들어갈 필요 없게 만들기도합니다. 또한 Web Server와 WAS를 물리적으로 분리하여 보안을 강화합니다.
- Web Server : 정적 컨텐츠(html, 이미지)를 제공하는 서버로 Apache, Ngingx가 있습니다.
- Web Application Server : 백엔드 인프라와 연동하여 비즈니스 로직을 처리합니다. 동적 컨텐츠를 제공하는 서버로 Tomcat, Jeus가 있습니다.
[4] Database
WAS는 정보를 저장하기 위해 한 개 이상의 DB 서버를 사용합니다. 트래픽 및 효율성을 위해 DB를 분산 처리하거나 SQL 혹은 NoSQL로 DB를 구축하기도 합니다.
- SQL : MySQL, Oracle
- NoSQL : MongoDB, Kasandra, GraphQL
[5] Chching Service
DB 서버에 접근하여 데이터를 가져오는 것은 시간이 많이 걸립니다. 따라서 자주 찾는 정보를 빠르게 찾을 수 있도록 도와주는 캐싱 서비스를 이용합니다. 이는 Key & Value 형태의 데이터 저장소를 제공합니다. 매번 자원이 많이 소모되는 연산의 결과를 다시 계산하지 않고 캐시에서 가져옴으로 효율성을 높입니다. DB 쿼리 결과, 외부 서비스 호출 결과, 정적 리솟 등을 캐시하는데 다음은 몇가지 실무 예시입니다.
- 구글은 'dog', 'cat'과 같은 일반 검색어를 매번 실행하기 보다는 결과를 캐시합니다.
- 페이스북은 로그인할 때 포스트, 친구 목록 등의 데이터를 캐시합니다.
- 이때, 캐싱 서버는 Redis, Memcache 등으로 구현합니다.
[6] Job Queue & Job Server
WAS는 사용자 요청의 응답과는 직접적 관련 없는 작업을 백그라운드에서 비동기적으로 실행합니다. 예를 들어 구글은 검색 결과를 얻기위해 인터넷에서 데이터를 크롤링하고 인덱싱합니다. 이는 유저가 검색할 때마다 실행되지 않으며 구글의 검색 엔진은 비동기적으로 웹을 크롤링합니다.
비동기 작업을 처리하는 여러 아키텍처가 있지만 가장 널리 사용하는 것은 '잡 큐' 아키텍처입니다. 이는 잡이 들어가는 '잡 큐'에서 잡을 꺼내고 '잡 서버'에서 실행합니다. 이 역시 별도의 DB를 보유할 수 있습니다.
[7] Full Text Search Service
현재 많은 어플리케이션은 사용자 검색과 가장 관련있는 결과를 보여주는 기능을제공합니다. 이 기능을 가능하게 하는 것은 full text search service 때문입니다. 이를 위해 inverted index를 활용합니다. 오늘날 인기 있는 전체 텍스트 검색 서비스는 Elasticsearch지만 그 외에도 Sphinx 또는 Apache Solr 같은 선택지도 존재합니다.

[8] Service
앱이 특정 규모에 도달하면 기능별로(?) 별도의 애플리케이션으로 분리해서 운영하는 서비스가 생깁니다. 외부에 노출되지 않지만 WAS, 다른 서비스와 연동됩니다. 아래는 서비스 예시입니다.
- 계정 서비스는 사이트 유저 정보를 저장해서 더 일관적 사용자 경험을 제공합니다.
- 결제 서비스는 고객이 카드로 결제할 수 있는 인터페이스를 제공합니다.
- 컨텐츠 서비스는 우리의 모든 비디오, 오디오, 이미지의 메타데이터를 저장합니다. 또, 컨텐츠 다운로드 인터페이스와 다운로드 이력을 보여줍니다.
[9] Data
오늘날, 기업은 데이터를 어떻게 다루느냐에 따라 성공하거나 실패합니다. 최근 대부분의 앱은 특정 규모에 도달하면 데이터를 제어, 저장, 분석하기 위해 데이터 파이프 라인을 사용합니다. 전형적인 파이프라인은 아래의 3단계를 거칩니다.
- 앱은 보통 사용자 상호작용으로 발생한 데이터를 'firehose'라 불리는 곳으로 전달합니다.firehorse는 데이터를 받아들이고 처리할 수 있는 인터페이스를 제공하며, 가공되지 않은 원시 데이터, 가공된 데이터 모두 처리합니다. AWS Kinesis와 Kafka는 이러한 작업을 위한 대표적 기술입니다.
- 원시 데이터와 최종 데이터는 모두 클라우드 스토리지에 저장됩니다. AWS Kinesis의 클라우드 스토리지(S3)를 사용하기도 합니다.
- 변형/추가된 데이터는 종종 분석을 위해 데이터 웨어하우스에서 로드됩니다. AWS Redshift, Oracle등을 사용합니다. 만약 데이터가 충분히 축적되었다면 Hadoop 같은 NoSQL MapReduce 기술이 분석을 위해 필요하게 될 것입니다.
[10] Cloud Storage
클라우드 스토리지는 인터넷을 통해 데이터를 저장, 접근할 수 있는 단순한 방법입니다. 클라이언트에서 RESTful API를 사용해서 클라우드에 저장하고 접근할 수 있습니다. 대표적으로 파이어베이스 스토리지, 아마존의 S3가 있습니다. 사진, 비디오, 데이터, CSS, JS, 사용자 데이터 등을 저장합니다.
[11] Content Deliver Network
CDN은 HTML, CSS, JS, 이미지 같은 정적 데이터를 원본 서버에서 가져오는것보다 더 빠르게 제공하기 위한 기술입니다. 이는 컨텐츠를 전 세계의 엣지 서버에 분산시킴으로 동작합니다. 예를 들어, 스페인에 있는 사용자가 뉴옥에 있는 원본 서버의 웹 페이지에 접근하면 정적인 데이터는 대서양을 가로지르는 매우느린 HTTP 요청을 하는 대신에 영구에 있는 CDN 엣지 서버에서 빠르게 가져오게 하는 것입니다.
- 가장 가까운 곳에서 요청자에게 솔루션을 제공하는 서비스로, bandwidth, latency를 동시에 해결합니다.
- 사용자와 가까운 곳에서 패킷을 전달하여 latency 문제 해결합니다.
- 한 곳에 데이터가 몰릴 경우가 드물게 바뀌어 bandwidth 문제 해결합니다.
* Cache Server
클라이언트와 본 서버 사이에 캐시서버를 두어, 클라이언트가 보낸 패킷 메시지가 본 서버로 바로 가는 것이 아니라 일단 캐시 서버로 가서 데이터가 있으면 바로 반환하는 방식입니다. 당연히 패킷 latency도 줄고, 웹 서버의 트래픽도 줄일 수 있습니다. 실 서버로 가기 전 캐시 서버를 거치는 오버헤드는 크지 않기 때문에 웹 서버로 가기 전 일단 캐시서버를 거칩니다.
- html, 이미지 등의 정적 리소스를 캐시 서버로 두어 패킷 latency를 급격히 오르게합니다.
- 실 서버의 트래픽을 분산시켜줍니다.
- 많은 대학, 회사에서 Internet Edge쪽에 캐시 서버를 두어 Access Network 사용량을 줄입니다. 이로 인해 비용을 줄이는 효과를 이끕니다.
하지만 캐시 서버와 실 서버와의 동기화 문제가 있습니다. 따라서 패킷의 expire 태그 헤더를 통해 캐시의 유효기간을 체크합니다.
- 패킷이 캐시 유효 기간에 포함될 경우 실 서버를 거치지 않고 반환합니다. 만약 캐시 유효 기간을 넘어설 경우 실 서버를 거친 후 리스폰스합니다. 정보가 바꼈다면 변경 정보를 캐시 서버에도 반영합니다.
- 혹은 일정 주기마다 캐시 정보를 업데이트하는 방법도 있습니다.
