[코드라이언] Python (심화)
요청 메소드(method) - GET, POST, PUT, DELETE
요청 메소드(method)
클라이언트가 서버에 데이터를 요청할 때 CRUD라는 4가지 타입이 있다. 이때 CRUD는 읽기(Read), 쓰기(Create), 수정(Update), 삭제(Delete)를 말한다.
게시판 사이트가 있다고 할 때를 예를 들어보자. 게시판의 모든 게시글 리스트를 가져오거나 특정 게시글에 대한 정보를 가져올 때는 Read이다. 게시글을 추가하면 Create, 게시글을 수정하면 Update, 게시글을 삭제하면 Delete라고 한다. 하지만 클라이언트와 서버는 Read, Create, Update, Delete라고 직접 명시하지 않는다. 이러한 요청을 헤더에 GET, POST, PUT, DELETE의 형태로 메소드를 정의한다.

GET 요청
- GET 요청은 클라이언트가 서버에 데이터를 요청할 때 사용하는 메소드
- 웹 페이지를 요청할 수 있고, 특정 게시글을 요청할 수 있음
- 서버 종류에 따라 다양한 데이터를 요청
예) 영상 서버에는 영상을 요청할 것이고, 도메인 서버에는 IP를 요청할 것
POST 요청
- POST 요청은 특정 데이터를 추가하는 요청
- 데이터를 만들어 내는 것(= 데이터베이스에 데이터를 추가한다는 의미)
- 예) 게시판에 게시글을 추가하는 작업
PUT 요청
- PUT 요청은 특정 데이터에 대해 수정하라는 요청
- 데이터베이스에 존재하는 데이터를 수정
- 예) 회원 정보를 수정하여 데이터를 수정하는 행위
DELETE 요청
- DELETE 요청은 특정 데이터를 삭제하라는 것
- 데이터베이스에 존재하는 데이터를 삭제
- 예) 회원 탈퇴를 하는 행위
크롤링과 스크래핑 그리고 파싱
크롤링(Crawling)
웹 크롤링은 'URL을 탐색해 반복적으로 링크를 찾고 가져오는 과정'이다. '기어 다니다' 라는 뜻의 영어 단어 크롤링(crawling)을 사용한 것에서 알 수 있듯이, 웹 크롤링은 웹 페이지를 찾아다니며 정보를 수집한다.
대표적인 웹 크롤링으로는 검색엔진의 웹 크롤러(web crawler)가 하는 일을 예로 들 수 있다. 웹 크롤러는 URL을 수집하고 웹 페이지를 복사하여, 수집한 웹 페이지에 색인(index)을 부여한다. 분류가 잘 되어있으면 그만큼 검색 속도가 올라갈 테니까.
즉, 쉽게 말해 데이터를 수집하고 분류하는 것을 크롤링(Crawling)이라고 지칭한다.
파싱(Parsing)
웹페이지에서 원하는 데이터를 추출하여 가공하기 쉬운 상태로 바꾸는 것이다.
웹페이지에서 떠다니는 데이터는 리스트, 딕셔너리 같은 자료구조와 달라 사용자 마음대로 접근하고 자르고 추가하는 등의 편집이 쉽지않다. 그렇기 때문에 이런 데이터들을 다루기 쉬운 형태로 바꿔주는 과정이 필요한데, 이 역할을 하는 함수나 프로그램을 파서(parser)라고 하며, 이 과정을 파싱(parsing)이라고 한다.
웹크롤링을 할 때 필연적으로 만나게 되며, python에서는 beautifulsoup 라이브러리를 사용하여 html 문서를 파싱한다.
스크래핑(Scraping)
웹 스크래핑은 '우리가 정한 특정 웹 페이지에서 데이터를 추출하는 것'이다. 우리가 특정 주제의 뉴스만을 가져오거나, 인기 검색어 정보를 가져오는 것, 어떤 상품의 가격을 모니터링하는 것 모두 웹 스크래핑이다. 그래서 웹 스크래핑을 웹 데이터 추출(web data extraction), 웹 하베스팅(web harvesting)이라고도 부른다.
즉, 스크래핑(Scraping)이란 크롤링(Crawling)한 데이터를 파싱(Parshing)하여 Web에서 필요한 데이터를 추출하는 것이라 할 수 있다.
패키지 (beautifulsoup / request)
import requests
from bs4 import BeautifulSoup
url = "http://www.daum.net/"
response = requests.get(url)
print(response.text)request
Requests란 Python용 HTTP 라이브러리이다.
Python에서 특정 웹사이트에 HTTP 요청을 보내는 모듈이라고 생각하면 될 것 같다.
좀 더 쉽게 말해서 특정 웹사이트에 HTTP 요청을 보내 HTML 문서를 받아올 수 있는 라이브러리이다.
근데 정확히 말하면 얘가 가져오는 HTML 문서는 문서가 아닌 그냥 단순한 String이고,
뒤에서 배우는 BeautifulSoup에 의해 살아있는 HTML 문서로 바뀌게 된다.

Beautiful Soup / lxml
BeautifulSoup이란 스크래핑을 하기위해 사용하는 패키지이고, lxml은 구문을 분석하기 위한 파서이다.
즉, BeautifulSoup은 response.text를 통해 가져온 HTML 문서를 탐색해서 원하는 부분을 뽑아내는 그런 역할을 하는 라이브러리이다.
또한, response.text로 가져온 HTML문서는 단순히 String에 지나지 않으니, lxml을 통하여 의미있는 HTML문서로 변환하는 것이다.
결론적으로, response.text로 가져온 String은 lxml이라는 모듈의 해석에 의하여 의미있는 HTML 문서로 변환되고, 이렇게 변환된 HTML문서는 BeautifulSoup에 의해서 원하는 부분을 탐색할 수 있게 된다.

예제) 실시간 검색어 확인하기
참고자료
https://ponyozzang.tistory.com/626 (.starftime 함수)
https://wikidocs.net/26 (open 함수)
- 다음(Daum) 실시간검색어
from bs4 import BeautifulSoup
import requests
from datetime import datetime
headers = {'User-Agent':'Mozilla/5.0 (Windows NT 6.3; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Safari/537.36'}
url = "http://www.daum.net/"
response = requests.get(url, headers=headers)
soup = BeautifulSoup(response.text, 'html.parser')
rank = 1
results = soup.findAll('a','link_favorsch')
search_rank_file = open("rankresult.txt","w")
print(datetime.today().strftime("%Y년 %m월 %d일의 실시간 검색어 순위입니다.\n"))
for result in results:
search_rank_file.write(str(rank)+"위:"+result.get_text()+"\n")
print(rank,"위 : ",result.get_text(),"\n")
rank += 1- 네이버(Naver) 실시간검색어
from bs4 import BeautifulSoup
import requests
from datetime import datetime
headers = {'User-Agent':'Mozilla/5.0 (Windows NT 6.3; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Safari/537.36'}
url = "https://datalab.naver.com/keyword/realtimeList.naver?age=20s"
response = requests.get(url,headers=headers)
soup = BeautifulSoup(response.text, 'html.parser')
rank = 1
# span - item_title
results = soup.findAll('span','item_title')
print(response.text)
search_rank_file = open("rankresult.txt","a")
print(datetime.today().strftime("%Y년 %m월 %d일의 실시간 검색어 순위입니다.\n"))
for result in results:
search_rank_file.write(str(rank)+"위:"+result.get_text()+"\n")
print(rank,"위 : ",result.get_text(),"\n")
rank += 1API
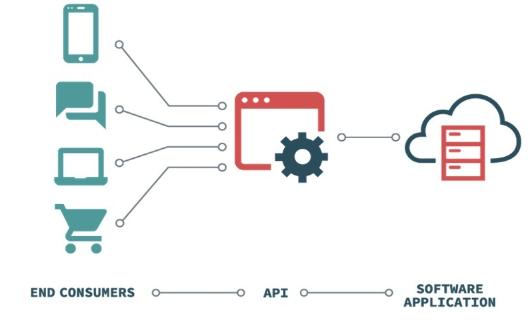
API(Application Programming Interface)는 응용 프로그램에서 사용할 수 있도록 운영체제나 프로그래밍 언어가 제공하는 기능을 제어할 수 있게 만든 인터페이스를 뜻합니다. 주로 파일 제어, 창 제어, 화상 처리, 문자 제어 등을 위한 인터페이스를 제공합니다.
참고자료
https://ittrue.tistory.com/31 (API)
https://www.daleseo.com/python-f-strings/ (f-string)
JSON
JSON (JavaScript Object Notation)
- JavaScript Object Notation라는 의미의 축약어로 데이터를 저장하거나 전송할 때 많이 사용되는 경량의 DATA 교환 형식
- Javascript에서 객체를 만들 때 사용하는 표현식을 의미한다.
- JSON 표현식은 사람과 기계 모두 이해하기 쉬우며 용량이 작아서, 최근에는 - JSON이 XML을 대체해서 데이터 전송 등에 많이 사용한다.
- JSON은 데이터 포맷일 뿐이며 어떠한 통신 방법도, 프로그래밍 문법도 아닌 단순히 데이터를 표시하는 표현 방법일 뿐이다.
참고자료
https://velog.io/@surim014/JSON%EC%9D%B4%EB%9E%80-%EB%AC%B4%EC%97%87%EC%9D%B8%EA%B0%80
예제) 날씨정보 받아오기 (open API)
import requests
import json
city = "Seoul"
apikey = "################################"
lang = "kr"
# units - metric
api = f"""http://api.openweathermap.org/data/2.5/\
weather?q={city}&appid={apikey}&lang={lang}&units=metric"""
result = requests.get(api)
# print(result.text)
data = json.loads(result.text)
# 지역 : name
print(data["name"],"의 날씨입니다.")
# 자세한 날씨 : weather - description
print("날씨는 ",data["weather"][0]["description"],"입니다.")
# 현재 온도 : main - temp
print("현재 온도는 ",data["main"]["temp"],"입니다.")
# 체감 온도 : main - feels_like
print("하지만 체감 온도는 ",data["main"]["feels_like"],"입니다.")
# 최저 기온 : main - temp_min
print("최저 기온은 ",data["main"]["temp_min"],"입니다.")
# 최고 기온 : main - temp_max
print("최고 기온은 ",data["main"]["temp_max"],"입니다.")
# 습도 : main - humidity
print("습도는 ",data["main"]["humidity"],"입니다.")
# 기압 : main - pressure
print("기압은 ",data["main"]["pressure"],"입니다.")
# 풍향 : wind - deg
print("풍향은 ",data["wind"]["deg"],"입니다.")
# 풍속 : wind - speed
print("풍속은 ",data["wind"]["speed"],"입니다.")참고자료 (파라미터)
https://velog.io/@pm1100tm/python-%ED%95%A8%EC%88%98%EC%99%80-%ED%8C%8C%EB%9D%BC%EB%AF%B8%ED%84%B0
GoogleTrans 라이브러리
예제) 번역하기
from googletrans import Translator
translator = Translator()
# sentence = "안녕하세요 코드라이언입니다."
sentence = input("번역을 원하는 문장을 입력해주세요 : ")
dest = input("어떤 언어로 번역을 원하시나요?")
result = translator.translate(sentence,dest)
detected = translator.detect(sentence)
print("===========출 력 결 과===========")
print(detected.lang,":",sentence)
print(result.dest,":",result.text)
print("=================================")SMTP 와 IMAP
- SMTP는 Simple Mail Transfer Protocol 의 줄임말로서 이메일을 보내는데 있어서 업계표준 프로토콜이다. SMTP의 간단한 예를 보면 Microsoft Outlook 등에서 메일 Client가 메시지를 email server로 보낼때 사용하는 프로토콜로 볼 수 있다.
- SMTP는 이메일을 보내는 것이라고 했을 때 IMAP는 이메일을 받은 서버로부터 이메일 메시지를 관리하고 이메일을 꺼내서 가져오는데 사용되는 프로토콜이라고 볼 수 있다. IMAP는 Internet Access Message Protocol의 줄임말이다.
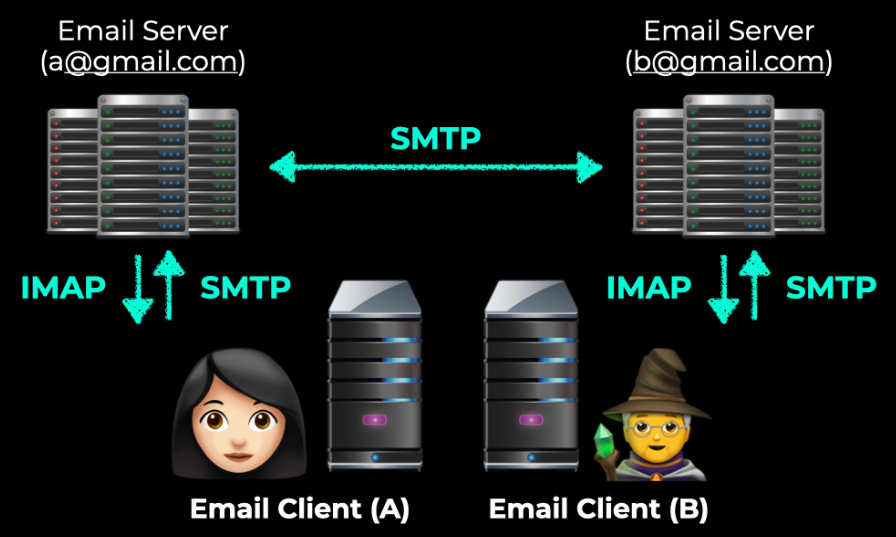
1) 이메일을 만들고 보내게 되면 Gmail, Outlook 등의 Client가 SMTP를 이용해서 메시지를 Email 서버로 보내게 된다.
2) Email Server는 SMTP를 이용해서 송신자의 이메일 서버에 메일을 보내게 된다.
3) SMTP 통신을 통해서 메일을 받게 되면 수신자의 이메일 Client는 IMAP를 이용해서 메시지를 가져오고 Inbox에 메일을 가져오게 된다.
smtplib 라이브러리
MIME
Multipurpose Internet Mail Extensions의 약자로 간단히 말하면 파일 변환을 의미한다.현재는 웹을 통해 여러 형태의 파일을 전달하는데 사용하고 있지만 이 용어가 생길 땐 이메일과 함께 동봉할 파일을 텍스트 문자로 전환해서 이메일 시스템을 통해 전달하기 위해 개발되어 Internet Mail Extensions라고 불리기 시작했다고 한다.
MIME 사용이유
예전에는 텍스트 파일을 주고 받는데에 ASCII로 공통된 표준에 따르기만 하면 문제가 없었으나 네트워크를 통해 ASCII가 아닌 바이너리 파일을 보내는 경우가 생기게 되었다. 음악파일, 무비파일, 워드파일 등등 ASCII만으로는 전송이 안되기 때문에 기존 시스템에서 문제 없이 전달하기 위해서는 텍스트로의 변환이 필요했다.
텍스트 파일로 변환하는 것을 인코딩(Encoding), 텍스트 파일을 바이너리 파일로 변환하는 것을 디코딩(Decoding)이라고 한다.
MIME으로 인코딩한 파일은 Content-type정보를 앞부분에 담게되며 Content-type은 여러가지 타입이 있다.
웹 브라우저에서 서버에 접속하여 html 문서를 요청하면서 html문서에 있는 이미지 파일의 경로를 불러올 수 있다. 이러한 과정에서 이미지의 경로에 있는 파일이 웹브라우저에서 지원되는 MIME-Type이라면 웹브라우저를 이용하여 열어볼 수 있다.
바이너리파일(음악 파일, 무비 파일, 워드 파일 등) 또한 마찬가지 이다. 주로 쓰고 있는 대부분의 포맷인 .gif .jpg .mov 등등의 파일들은 웹 브라우저에서 무리없이 열리게 되는데 브라우저에서 지원하지 못하는 유형은 따로 지정해줘야 한다.
참고자료 (MIME)
https://velog.io/@aerirang647/MIME-type%EC%9D%B4%EB%9E%80
import smtplib
from email.message import EmailMessage
import imghdr
SMTP_SERVER = "smtp.gmail.com"
SMTP_PORT = 465
message = EmailMessage()
message.set_content("코드라이언 수업중입니다.")
message["Subject"] = "이것은 제목입니다."
message["From"] = "###@gmail.com"
message["To"] = "###@gmail.com"
with open("codelion.png","rb") as image:
image_file = image.read()
image_type = imghdr.what('codelion',image_file)
message.add_attachment(image_file,maintype='image',subtype=image_type)
smtp = smtplib.SMTP_SSL(SMTP_SERVER,SMTP_PORT)
smtp.login("###@gmail.com","######")
smtp.send_message(message)
smtp.quit()유효성검사
이메일을 보낼 때, 그 이메일 주소가 존재하는지 정확히 확인하기 위해서 유효성 검사가 필요
이메일 정규표현식
- 시작 =
^ - 끝 =
$ [a-zA-Z0-9.+_-]+: a부터 z까지 A부터Z까지, 0부터 9까지, . , +, _ , - 이 중에서 하나 가져오라는 것- 뒤에 붙은 +의 갯수 따라서 달라짐, 여기선 + 가 하나 붙었으니깐
a부터 z까지 A부터Z까지, 0부터 9까지, . , +, - , -
여기에 속하는 거 하나 고르고, 또 한번 더 하라는 것임 - (EX) codelion.example 라는 아이가 있다고 하면, a-z 하나, . 하나를 골라와서 총 두번 선택한 것 따라서 ㅇㅋ
\.=> 점 필수라는 것![a-zA-Z]{2,3}=> a부터 z까지, A부터 Z까지가 최소 2회, 최대 3번 반복
import smtplib
from email.message import EmailMessage
import imghdr
import re
SMTP_SERVER = "smtp.gmail.com"
SMTP_PORT = 465
def sendEmail(addr):
reg = "^[a-zA-Z0-9.+_-]+@[a-zA-Z0-9]+\.[a-zA-Z]{2,3}$"
if bool(re.match(reg,addr)):
smtp.send_message(message)
print("정상적으로 메일이 발송되었습니다.")
else:
print("유효한 이메일 주소가 아닙니다.")
message = EmailMessage()
message.set_content("코드라이언 수업중입니다.")
message["Subject"] = "이것은 제목입니다."
message["From"] = "###@gmail.com"
message["To"] = "###@gmail.com"
with open("codelion.png","rb") as image:
image_file = image.read()
image_type = imghdr.what('codelion',image_file)
message.add_attachment(image_file,maintype='image',subtype=image_type)
smtp = smtplib.SMTP_SSL(SMTP_SERVER,SMTP_PORT)
smtp.login("###@gmail.com","######")
# 메일을 보내는 sendEmail 함수를 호출해서 실행해보기
sendEmail("###gmailcom")
smtp.quit()