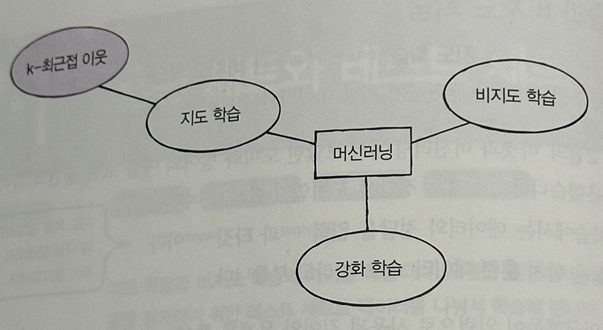
앞서 도미와 빙어를 지도학습에서 훈련을 하고 결과를 보았다. 지도 학습은 정답이 있으나 알고리즘이 정답을 맞히는 것을 학습힌다. 예를들어 도미인지 빙어인지??
반면 비지도 학습 알고리즘은 타깃 없이 입력 데이터만을 이용한다.
훈련 세트와 테스트 세트를 알아 보자.
상식적으로 우리가 학교에서 시험을 볼때 시험문제와 답안지를 보여주고 시험을 친다면 누구나 100점을 맞는다. 아닌가? 머신러닝도 이와 마찬가지이다. 도미와 빙어의 데이터와 타깃을 주고 훈련한 다음, 같은 데이터로 테스트한다면 모두 맞히는 것이 당연하다.(앞 블로그) 연습문제와 시험문제가 달라야 하는 것처럼 훈련 세트와 테스트 세트 역시 달라야 한다.

훈련 데이터와 테스트 데이터를 다르게 두어야한다고 하면 이렇게 두면 과연 맞을까?

아니다! 확률은 0.0
당연히 훈련 데이터는 도미의 데이터이고 테스트 데이터는 빙어의 데이터이다. 0이 안나온게 이상할 정도이다.
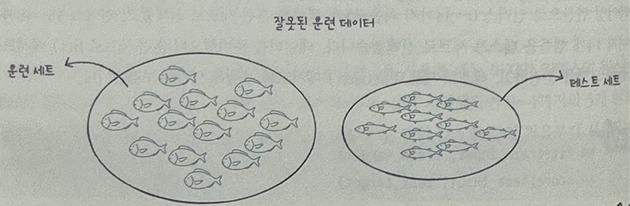
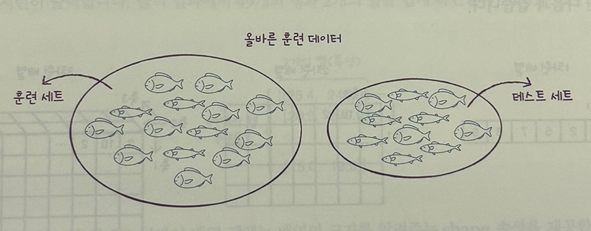
일반적으로 훈련 세트와 테스트 세트에 샘플이 골고루 섞여 있지 않으면 샘플링이 한쪽으로 치우쳤다는 의미로 샘플링 편향이라고 부른다.
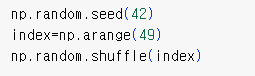
넘파이 arrange()함수를 사용하면 0에서부터 48까지 1씩 증가하는 인덱스를 간단히 만들 수 있다. 그 다음 이 인덱스를 랜덤하게 섞는다.
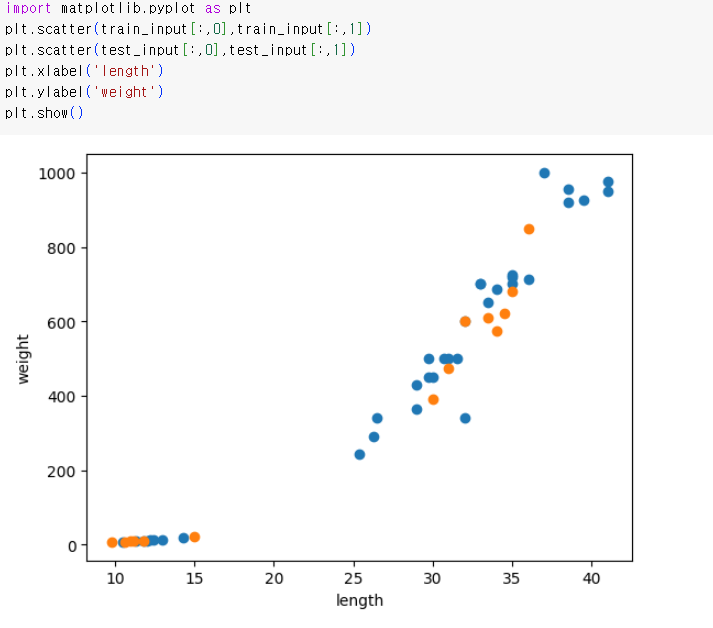
파란색이 훈련 세트이고 주황색이 테스트 세트이다. 양쪽에 도미와 빙어가 모두 섞여 있는 것을 볼 수가 있다.
앞서 만든 훈련 세트와 테스트 세트로 k-최근접 이웃 모델을 훈련시켜 보자.

100% 정확도가 테스트 세트에 있는 모든 생선을 맞혔다. predict()메서드로 테스트 세트의 예측 결과와 실제 타깃을 확인 해 보면,

테스트 세트에 대한예 예측 결과가 정답과 일치하는 것을 볼 수 가 있다.
도미와 빙어를 골고루 섞어 나누기 위해 파이썬의 다차원 배열 라이브러리인 넘파이를 사용해 보았다. 넘파이는 파이썬의 리스트와 비슷하지만 고차원의 큰 배열을 효과적으로 다룰 수 있고 다양한 도구를 많이 제공한다. shffle()함수를 사용해서 배열의 인덱스를 섞었다.ㅁ
