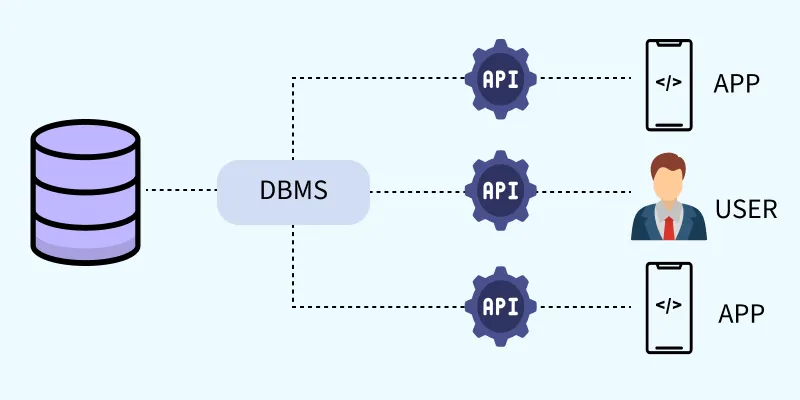

3과목은 데이터베이스 구축 관련한 내용이다. 안그래도 최근 프로젝트하면서 db 세팅하는데 2학년때 배웠던 전공과목이라 개념이 잘 생각이 안났었다..
위 이미지 기준으로 1, 2, 3장에서 많이 출제되니, 이 부분에 집중하자. 4장은 조금 난이도가 있고, 5과목은 아무래도 중요도가 많이 덜한편이다. 정리힘들다..
1. DB 설계 단계
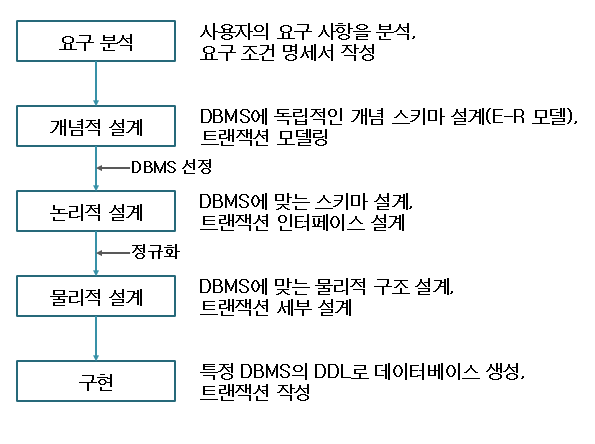
1-1. 개념적 설계(정보 모델링, 개념화)
제일 첫 단계로, 현실 세계의 인식을 추상적인 개념(ER모델 등) 으로 표현하는 과정이다.
중요한 점은, 2과목에서 다뤘던 '개념 스키마' 모델링과 '트랜잭션 모델링'을 병행 수행한다. DB를 만들기 전에 전체 구조를 그림(ERD)으로 그리는 단계라고 생각하면 된다.
1-2. 논리적 설계(데이터 모델링)
개념 모델을 특정 DBMS가 지원하는 논리적 구조로 '변환(mapping)'하는 과정이다.
논리적 자료 구조를 생성하고, 트랜잭션 인터페이스를 설계하는 단계이다. 기존에 만들어뒀던 개념 스키마를 평가 및 정제한다. 쉽게 말하면, 앞 단계에서 그려뒀던 ERD를 테이블 구조로 변환하는 단계이다. 이 단계에서 테이블을 생성하고, 속성 및 정규화, 기본키/외래키를 결정한다.
1-3. 물리적 설계
논리적 구조로 표현된 데이터를 실제 물리적 구조의 데이터로 변환하는 과정이다.
파일 저장 구조 및 접근 경로를 결정하고, 레코드 형식 및 순서, 인덱스를 설계한다. 이 단계에서는 DB를 실제 하드디스크에 어떻게 저장할지를 결정하는 단계인 것이다. 3학년 2학기 Big Data Management에서 배웠던 인덱스, 파티션, 클러스터링 등의 과정이 이 단계이다.
세 단계를 정리하면 아래와 같다.

1-4. 데이터 모델에 표시할 요소
이것도 시험에 출제확률 높으니 잘 알아두자. 다음 세 가지가 데이터 모델에 꼭 들어간다.
- 구조: 개체 및 타입 간의 관계로, 테이블 구조 및 관계 구조를 말한다.
- 연산: 실제 데이터를 처리하는 작업 명세를 말하며, DB 조작 도구다. 예를 들면 SELECT, INSERT, DELETE가 다음과 같다.
- 제약 조건(Constraints): 저장될 수 있는 실제 데이터의 논리적인 제한을 의마한다. 무결성 제약 및 데이터의 정확성을 유지한다. 주로 기본키, 외래키, 도메인에 대한 제약이 있다.
1-5. E-R 다이어그램
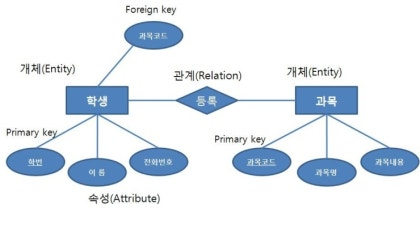
개발전 API 명세서와 더불어 꼭 필요한 문서다. 주요 구성 요소를 알아두자.
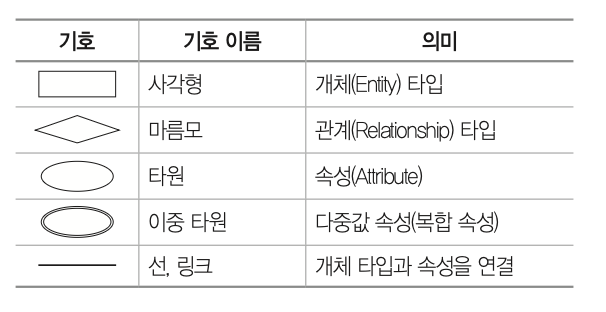
추가로 이것도 알아두자.
- 밑줄 친 속성: 기본키
- 이중 사각형: 약한 개체
- 이중 마름모: 식별 관계
2. Relation
2-1. 테이블 구조
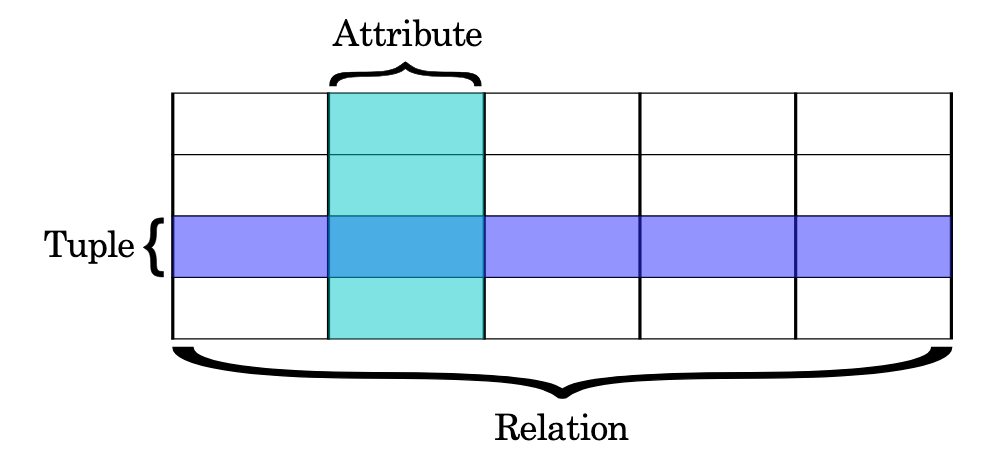
-
튜플
릴레이션을 구성하는 'row'를 말한다. 참고로 '튜플 수 = 카디널리티(Cardinality)'다. -
속성(Attribute)
릴레이션의 '열'로, db를 구성하는 가장 작은 논리적 단위다. '속성의 수 = Degree(차수)'인 것을 외워두자. -
도메인
'하나의 속성이 가질 수 있는 값의 집합'이다. 같은 타입의 원자값(더 이상 쪼갤 수 없는 값)들의 집합이다. 예를 들면, 성별 도메인은 {남, 여}, 학년 도메인은 {1,2,3,4} 이렇게 될 수 있다.
2-2. Relation의 특징
그림으로도 확인할 수 있듯이, relatioin=tabled이다. 테이블의 특징 및 규칙을 외워두자.
- 튜플은 중복 불가하다.(행 중복 불가)
- 튜플 사이에는 순서가 없다.
- 속성의 명칭은 유일해야 한다(같은 이름의 열은 존재할 수 없다)
- 속성의 값은 원자값으로, 더 이상 분해할 수 없어야 한다.
2-3. Key 종류 ★★★
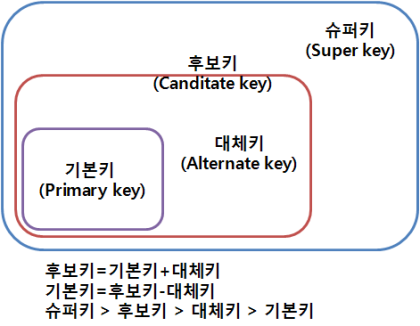
다양한 키 종류를 다 확실히 알고, 헷갈리지 않게 잘 정리해놓자.
-
후보키 (Candidate Key)
튜플을 유일하게 식별할 수 있는 속성의 부분집합으로, 중요한 건 '유일성'과 '최소성'을 만족해야 한다는 점이다. -
기본키 (Primary Key)
후보키 중에서 선택된 main key로, 중복된 값을 가질 수 없으며, NULL값을 가질 수도 없다. -
대체키 (Alternate Key)
후보키 중 기본키로 선택되지 않은 나머지 키들이며, 보조키라고도 한다. -
슈퍼키 (Super Key)
유일성은 만족하지만, '최소성'은 만족하지 않는 키를 말한다. 즉, 후보키에 다른 속성을 추가한 것이다. 예를 들면, 학번이 후보키라고 하면, (학번, 이름)은 슈퍼키가 된다. -
외래키 (Foreign Key)
다른 릴레이션의 기본키를 참조하는 속성 또는 속성들의 부분집합을 의미하며, 중요한 건 동일 도메인이어야 한다.
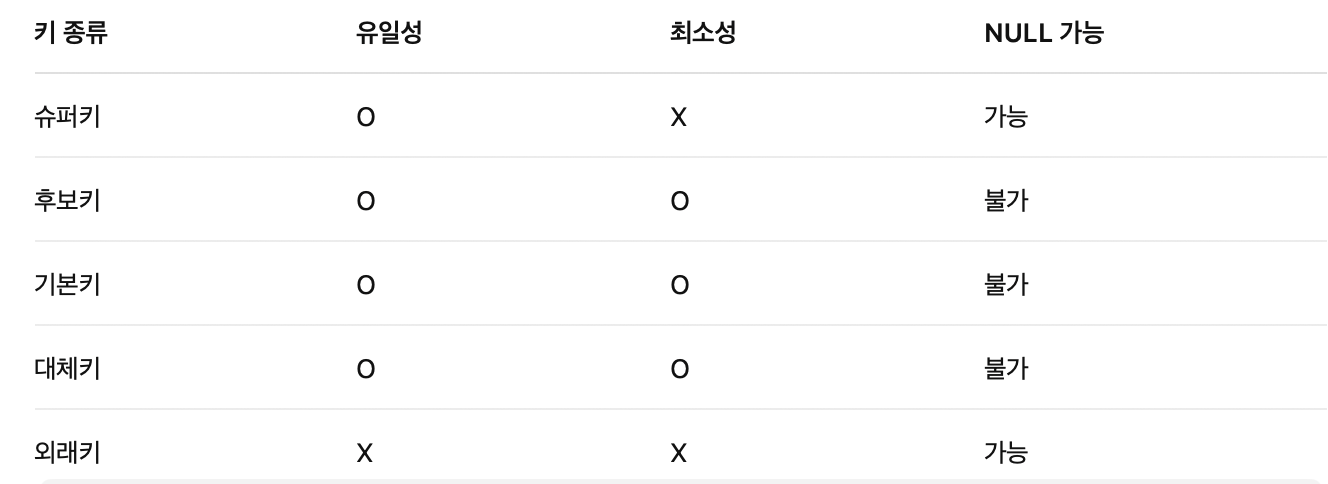
헷갈리니까 다음 아래표도 참고해서 기억하자.
2-3. 무결성(Integrity)
무결성이란, 데이터의 정확성 및 일관성을 의미한다.
-
개체 무결성(Entity Integrity): '기본키'는 반드시 값을 가져야 하며(NULL 불가), 중복이 불가능하다는 개념이다.
-
참조 무결성 (Referential Integrity): 외래키 값은 NULL이거나, 참조 릴레이션의 기본 키 값과 동일해야 한다. 즉, 참조를 할거면 다른 테이블의 기본 키를 참조하거나, 아예 참조를 하지 않게 값을 가지지 말아야 한다는 뜻이다.
-
도메인 무결성: 속성 값은 정의된 도메인(타입·범위) 안에 있어야 한다.
-
사용자 정의 무결성: 업무 규칙에 따라 사용자가 직접 정의한 제약이다.
2-4. 관계 대수
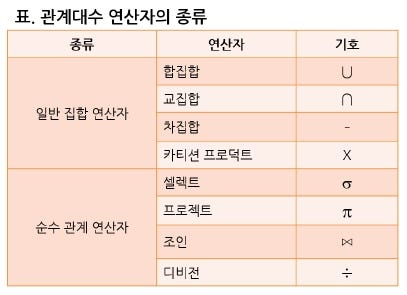
관계 대수란, 원하는 정보를 얻기 위해
어떤 연산을 어떤 순서로 수행할지를 기술하는 절차적 언어이다.
'절차적 언어'라는 것이 포인트며(외워두자 이렇게), 연산 순서를 명시한다. 위 표에서 SELECT, PROJECT, JOIN이 중요하니 기호를 잘 외워야한다.
- 순수 관계 연산자
다음과 같이 4개가 있다.
- SELECT(선택 연산): 기호는 σ, 조건을 만족하는 튜플(행) 만 선택해서 새로운 릴레이션을 만드는 연산이다.
SELECT * FROM Student WHERE 학년=3;
→ σ 학년=3 (Student)- PROJECT(투영 연산): 기호는 π, 지정된 속성(열)만 중복을 제거해서 추출하는 연산이다.
SELECT 이름, 학과 FROM Student;
→ π 이름,학과 (Student)-
JOIN: 기호는 ⋈, 공통 속성을 기준으로 두 릴레이션 결합해 새로운 릴레이션을 만드는 연산이다.
-
DIVISION: 기호는 ÷, 두 개의 릴레이션 R(X)와 S(Y)가 있을 때, R의 속성이 S의 속성값을 모두 가진 튜플에서 S가 가진 속성을 제외한 속성만을 구하는 연산이다.
수강(학생, 과목)
필수과목(과목)
→ 모든 필수과목을 다 수강한 학생 찾기- 일반 집합 연산자
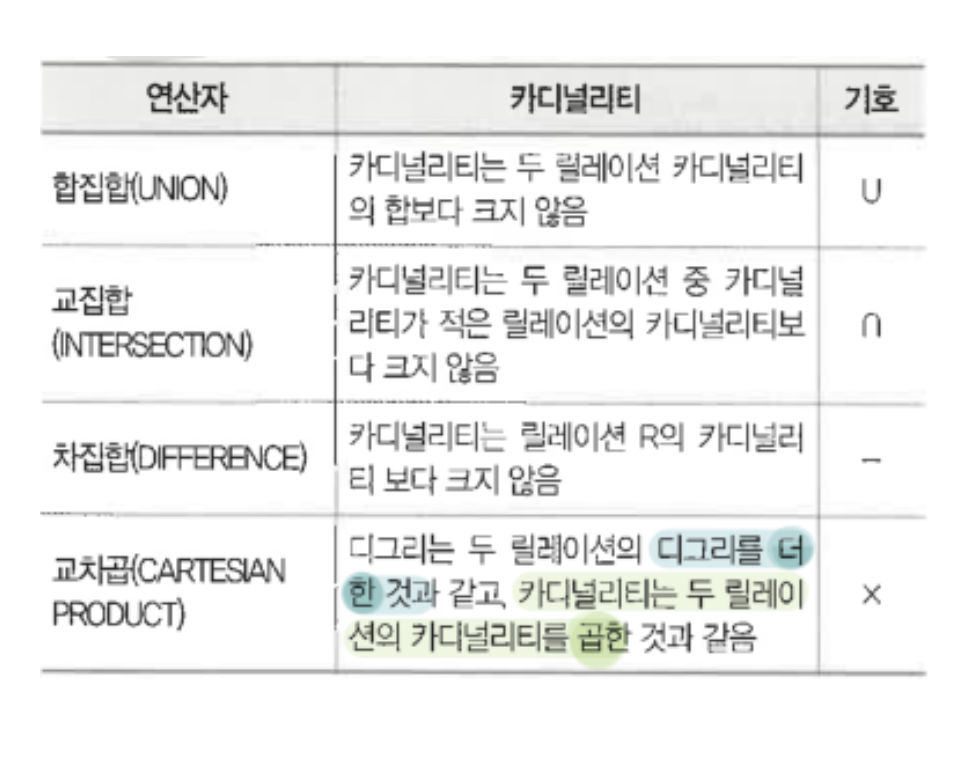
여기서 교차곱(★★)이 중요하니, 살펴보자. 교차곱은 두 릴레이션의 모든 가능한 튜플 조합을 구하는 연산이다.
- 교차곱의 차수(Degree)는 두 릴레이션의 차수를 더한 것과 같다.
- 교차곱의 카디널리티(튜플의 수)는 두 카디널리티를 곱한 것과 같다.
2-5. 관계 해석
코드(Codd)가 제안한 술어해석(Predicate Calculus) 기반
비절차적 언어다.
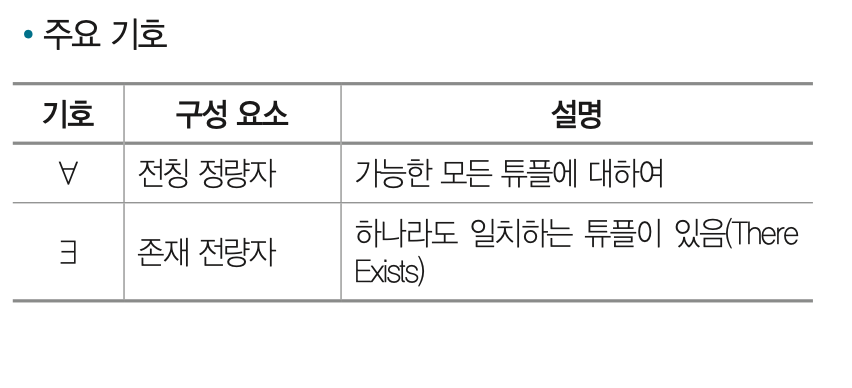
뭔소리냐.. 처음 들어보는 개념이다. 일단 주요 기호부터 외워두자. 관계 대수와 달리 '비절자척'언어이며, 조건만 기술한다는 특징이 있다.

3. 정규화(Normalization)

함수적 종속 이론을 이용하여 잘못 설계된 릴레이션을 더 작은 릴레이션으로 분해하는 과정
정규화는 너무 유명한 만큼 시험에 꼭 나온다. 이 정규화의 정의 또한 그대로 기억해두자.
개념-논리-물리 설계 단계에서 '논리적 설계 단계'에서 이루어지며, 데이터의 중복을 제거해 이상(Anomaly)를 방지하며, 저장 공간을 최소화하는데에 목적이 있다.
3-1. 이상(Anomaly)
정규화를 하지 않으면 발생하는, DB 내에 데이터들의 불필요하게 중복되어 릴레이션 조작시 곤란한 현상이 발생하는 것을 의미한다.
- 삽입 이상: 데이터를 삽입할 때 원하지 않은 값도 함께 삽입되는 현상이다.
- 삭제 이상: 튜플을 삭제할 때 상관없는 값들도 함께 삭제되는 현상이다.
- 갱신 이상: 튜플에 있는 속성값을 갱신할 때 일부 튜플의 정보만 갱신되어 모순 생기는 현상으로, 같은 정보를 여러 군데 수정해야 하는 번거로움이 생긴다.
3-2. 정규화 과정

-
1NF(제 1 정규형): 도메인이 원자값이 되는, 반복 속성을 제거하는 단계다.
-
2NF(제2정규형): 1NF를 만족하는 상황에서, '부분적'으로 함수 종속을 제거한다.
-
3NF(제3정규형): 2NF를 만족하는 상황에서, '이행적 함수 종속을 제거'한다. 이행적 종속 관계란, A → B 이고 B → C 일 때, A → C 를 만족하는 관계를 말한다.
-
BCNF (보이스-코드 정규형): 모든 결정자가 후보키가 된다. 결정자이면서 후보키가 아닌 것을 제거한다. 3과 4 사이에 있는것이 포인트다.
*결정자: 함수적 종속 X → Y 에서 Y를 결정하는 속성 X -
4NF: 다치 종속을 제거한다.
*다치 종속: 하나의 속성 X 값에 대해 여러 개의 Y 값이 독립적으로 존재하는 경우
ex.
A 하나에
B가 여러 개
C도 여러 개
근데 B와 C는 서로 관련 없음 -
5NF: 조인 종속을 제거한다.
3-3. 종속(Dependency)
- 함수적 종속 (Functional Dependency)
어떤 속성 X의 값이 정해지면 다른 속성 Y의 값이 '하나'로 결정되는 관계, 즉 X → Y인 관계다.
예를 들면, '학번 → 이름'의 관계가 있다고 한다면, 학번이 같으면 이름은 반드시 같아진다.

- 이행적 종속(Transitive Dependency)
A → B
B → C
이면
A → C
제거 단계는 '3단계'다.
3-4. 반정규화(Denormalization)
성능 향상을 위해 의도적으로 정규화 원칙을 위반(의도적 중복 허용)하는 것
정규화를 많이 하게 되면, JOIN이 많아진다. 그렇게 되면 속도는 느려지게 되어 일부러 합치는 경우가 반정규화다. 테이블을 통합하거나, 중복 속성을 추가하거나, 중복 테이블을 추가하는 식으로 이루어진다.
3-5. 시스템 카탈로그
DBMS가 데이터베이스의 구조 정보를 저장하는 시스템 테이블
메타데이터를 저장하며, 테이블 정보, 속성 정보, 사용자 정보 인덱스 정보가 포함된다. 시스템 그 자체에 관련이 있는 다양한 객체에 관한 정보를 포함하는 시스템 DB이다.
중요한건 사용자가 이 내용을 검색할 수는 있어도, 갱신하진 못한다.
4. Transaction
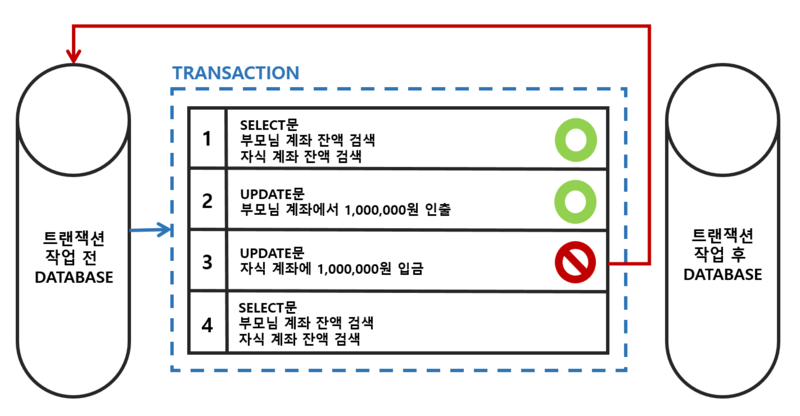
트랜잭션이란, 데이터베이스의 상태를 변화시키는 하나의 논리적 기능 수행을 위한 '작업 단위' 또는 '한 번에 모두 수행되어야 할 일련의 연산'다.
그림과 같이, 중간에 끊기면 안되는 '한 번에 이루어져야 하는 실행 단위'이다. '모두 수행'하거나 아니면 '전혀 수행되지 않아야 한다.'
실제로 작성자가 최근에 DBeaver로 프로젝트 DB 스키마를 지속적으로 수정하면서 트랜잭션을 rollback 하라는 오류가 제일 많이 떴었는데, 바로 이 트랜잭션의 중요한 원리 때문이다.
4-1. 트랜잭션의 상태
- 활동(Active): 트랜잭션이 실행중인 상태
- 실패(Failed): 실행에 오류가 발생하여 중단된 상태
- 철회(Aborted): 비정상적으로 종료되어 롤백 연산 수행한 상태
- ★부분완료(Partially Committed): 모두 성공적으로 실행한 후 커밋 연산이 실행되기 직전 상태
- 완료(Committed): 모두 성공적으로 실행한 후 커밋 연산 실행 후의 상태
이렇게 5가지 상태가 있다. 상태 흐름은 다음 2가지가 있다.

4-2. 트랜잭션 특성 (ACID) ★★★
시험 100% 출제다.
-
원자성(Atomicity): 트랜잭션의 연산은 DB에 모두 반영이 되도록 완료(Commit)하거나 전혀 반영되지 않도록 복구(Rollback) 되어야 한다.
-
일관성(Consistency): 트랜잭션이 정상적으로 성공하면 일관성 있는 데이터베이스 상태로 변환한다.
-
독립성(Isolation): 둘 이상의 트랜잭션이 동시에 병행 실행중에 다른 트랜잭션 연산이 끼어들 수 없음
-
영속성(Durability): 성공적으로 완료된 트랜잭션 결과는 시스템이 고장나더라도 영구적으로 반영되어야 한다.
TCL 명령어들도 기억해두자.
COMMIT; -- 트랜잭션 확정
ROLLBACK; -- 트랜잭션 취소 (전체 또는 SAVEPOINT까지)
SAVEPOINT sp1; -- 중간 저장점 설정
ROLLBACK TO sp1; -- sp1 이후만 취소5. Index & View
5-1. Index
데이터 레코드를 빠르게 접근하기 위한 <키 값, 포인터> 쌍으로 구성된 자료 구조
쉽게 말하면 책의 '목차'같이 빠르게 찾기 위한 구조로, DDL(데이터 정의어)로 생성/변경/삭제가 가능하다.
5-2. View ★★
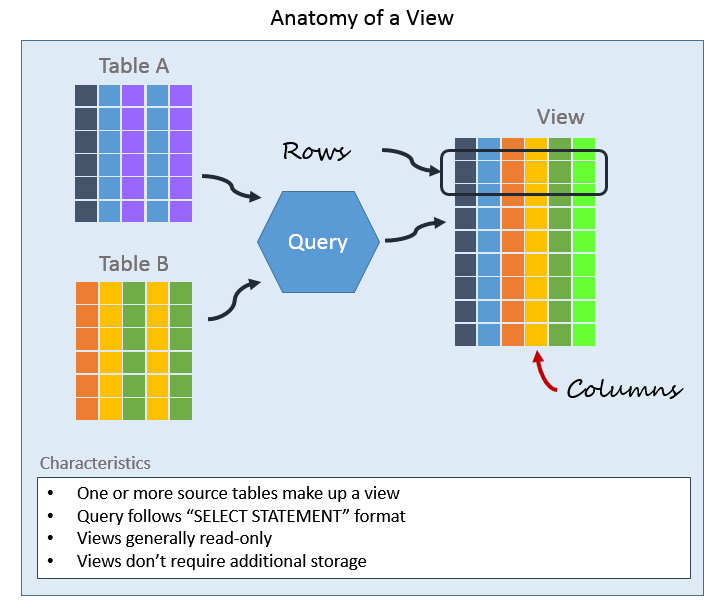
기본 테이블로부터 유도된 가상 테이블
실제로 데이터를 저장하지 않고, 이름만 존재하며, 물리적으로 존재하지 않는다. 사용하는 이유는 보안(특정 열만 보여줄 수 있음)적인 이유도 있고, 복잡한 쿼리를 단순화할 수 있고, 사용자에게도 맞춤 제공이 가능하다.
인덱스와 달리 삽입, 삭제, 갱신에 제약이 있고, 독립적인 인덱스 생성 불가하다. 생성은 CREAE, 삭제는 DROP으로 한다.

6. Partition & 분산 DB
6-1. Partition
테이블을 여러 조각으로 나누는 것
목적은 데이터의 규모가 커졌을 경우에 대용량 처리를 효율적으로 하기 위함과 동시에 이를 통해 성능을 향상시키는데 목적이 있다. 이거 프로젝트 PTSD..
파티션 종류는 다음과 같다.
-
범위 분할 (Range Partitioning)
지정한 열의 값 기준 분할 방식이다. Ex. 날짜별로 1~3월/ 4~6월 분할 -
해시 분할 (Hash Partitioning)
해시 함수 결과값에 따라 데이터를 분할한다. -
조합 분할 (Composite Partitioning)
범위 분할 후 해시 분할을 적용한 방식이다. -
목록 분할 (List Partitioning)
특정 값을 저장한 목록을 기준으로 한 분할 방식이다. Ex. 지역= 서울/부산/대구 -
라운드 로빈 분할 (Round Robin)
순차적으로 균등하게 분배하는 방식이다.
6-2. 분산 DB
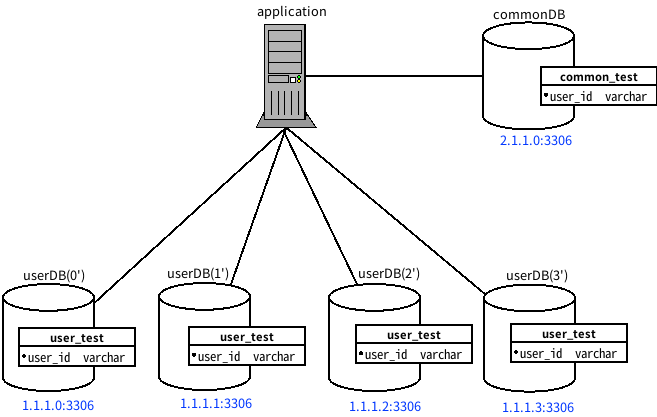
논리적으로는 하나지만, 물리적으로는 네트워크를 통해 연결된 여러 개의 사이트에 분산되어 있는 DB를 말한다.
분산되어 있기에 설계 및 개발이 어려우며, 분산 처리기, 분산 DB, 중요한 통신 네트워크가 구성 요소다.
분산 DB의 목표는 다음 4가지다. 거의 시험에 그대로 나온다.
- 위치 투명성: Access하려는 DB의 실제 위치를 몰라도, 명칭만으로 접근이 가능하다.
- 중복 투명성: 데이터가 중복되어 여러 군데 분산되어 있어도, 사용자는 하나처럼 사용한다.
- 병행 투명성: 동시에 다수의 트랜잭션이 발생해도 해당 트랜잭션의 결과에는 영향을 받지 않는다.
- 장애 투명성: 여러 장애에도 트랜잭션을 정확히 처리할 수 있게 된다.
7. DB 보안
7-1. 암호화 & 복호화
- 암호화 (Encryption): 정보 보호를 목적으로 평문 → 암호문이 이루어지는 과정이다.
- 복호화 (Decryption): 암호문을 원래의 평문으로 바꾸는 과정이다.
7-2. 접근 통제 기술
- DAC(임의 접근통제): 데이터에 접근하는 사용자의 신원 기준에 따라 권한을 부여하는 방식
- MAC(강제 접근통제): 주체와 객체의 등급을 비교해 접근 권한을 부여하는 방식으로, 군대 기밀 등급 같은 느낌이다.
- RBAC(역할 기반 접근통제): 사용자 역할 기준으로, 권한을 역할에 부여하는 방식이다.
*벨-라파둘라 모델 (Bell-LaPadula Model)
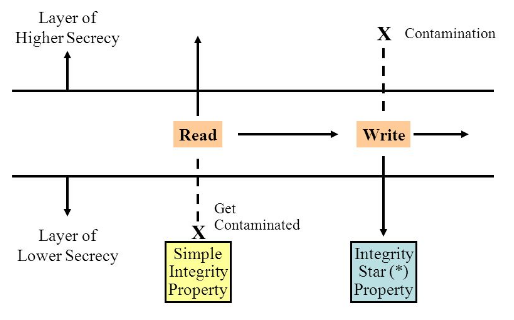
군대의 보안 레벨처럼 정보의 '기밀성'에 따라 상하 관계가 구분된 정보를 보호하기 위해 사용하는 접근제어 모델로, 보안 취급자의 등급을 기준으로 Read와 Write 권한이 제한된다.
핵심 규칙은 다음과 같다.
- No Read Up (상위 읽기 금지): 자기 보다 높은 등급 정보 읽기 불가
- No Write Down (하위 쓰기 금지): 자기 보다 낮은 등급에 쓰기 불가
8. Storage
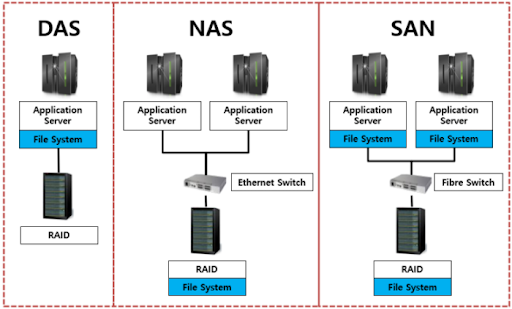
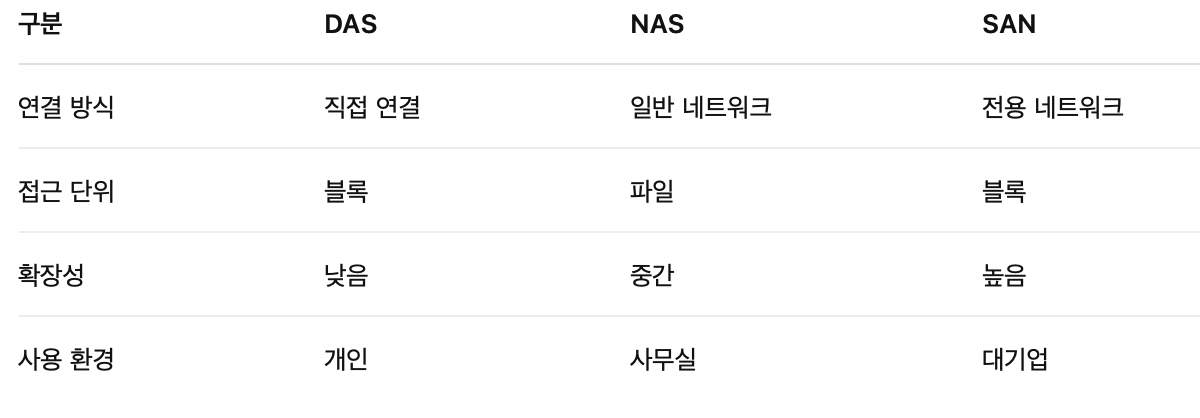
8-1. DAS(Direct Attached Storage)
서버와 저장장치를 전용 케이블로 직접 연결하는 것으로, 말 그대로 컴퓨터를 외장하드에 직접 연결하는 방식이다.
네트워크를 사용하지 않고, 설치도 간단하며 비용도 저렴한 편이지만 확장성은 당연히 떨어진다.
8-2. SAN(Storage Area Network)
서버와 저장장치를 연결하는 전용 네트워크를 구성하는 방식이다.
고속으로 데이터 처리가 가능하며, 확장성도 좋다. 주로 기업용 대규모 환경에서 사용된다.
8-3. NAS(Network Attached Storage)
네트워크를 통해 여러 사용자가 파일 단위로 접근하는 저장 장치
공유 폴더 전용 저장장치라고 생각하면 편하다.
9. SQL
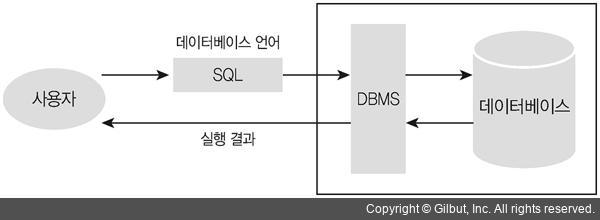
9-1. DDL (Data Definition Language)
데이터베이스 구조를 정의, 변경, 삭제하는 언어
스키마, 테이블, 뷰, 인덱스, 도메인 모두 생성, 변경, 삭제를 하는 언어다. 다음 세 가지가 주를 이룬다.
'구조'를 변경하며, 자동으로 COMMIT이 발생해, ROLLBACK이 불가하다.

ALTER은 '정의'를 변경하는 명령어다. DML이랑 혼동을 주의하도록 하자.
- CREATE TABLE: 테이블 생성
CREATE TABLE 테이블명 (
속성명 데이터타입 [DEFAULT 기본값] [NOT NULL],
...
PRIMARY KEY (속성명),
UNIQUE (속성명),
FOREIGN KEY (속성명)
REFERENCES 참조테이블(속성명)
ON DELETE 옵션
ON UPDATE 옵션,
CONSTRAINT 제약조건명 CHECK (조건식)
);기본키는 중복, NULL 다 안된다는 사실을 또또 기억하자(개체 무결성). UNIQUE는 중복만 안되고 NULL은 가능하다.
- ALTER TABLE: 테이블 구조 변경
ALTER TABLE 테이블명 ADD 속성명 데이터타입; //열 추가
ALTER TABLE 테이블명 ALTER 속성명 SET DEFAULT 값; //열 수정
ALTER TABLE 테이블명 DROP COLUMN 속성명; // 열 삭제- DROP TABLE: 테이블 삭제
DROP TABLE 테이블명 [CASCADE | RESTRICT];
위의 두 가지는 실제로도 자주 쓰는 명령어다.
9-2. DML (Data Manipulation Language)
저장된 데이터를 조회, 삽입, 수정, 삭제하는 언어
즉, 질의어를 통해 저장된 데이터를 실질적으로 처리하는 데 사용되는 언어다.

위의 4가지 다 '튜플'을 검색하고, 삽입하고, 변경하고, 삭제하는 것이다. 트랜잭션의 영향을 받는다.
- INSERT: 테이블에 새로운 튜플(행) 추가
INSERT INTO 테이블명 (속성1, 속성2, ...)
VALUES (값1, 값2, ...);VALUES는 필수이며, 속성 생략 시 테이블 정의 순서대로 입력한다. 속성 생략 시 테이블 정의 순서대로 입력한다.
- DELETE: 조건에 맞는 행 삭제
DELETE FROM 테이블명
WHERE 조건;WHERE을 생략하면 전체가 삭제된다.
- UPDATE: 기존 데이터 수정
UPDATE 테이블명
SET 속성 = 값
WHERE 조건;UPDATE, SET, WHERE 순서다.
- SELECT: 특정 조건을 가진 열을 조회
SELECT [DISTINCT] 속성명
FROM 테이블명
WHERE 조건
GROUP BY 속성명
HAVING 조건
ORDER BY 속성명 [ASC | DESC];이 순서 그대로 외워두도록 하자. DISTINCT는 중복을 제거하는 문(중복된 튜플 중 첫 번째만 검색)이고, GROUP BY는 그룹화할 속성을 지정한다. HAVING은 그룹화의 조건을 의미하고, ORDERED BY는 정렬(ASC;오름차순 DESC;내림차순)이다.
DML(데이터 조작문) 4가지는 정리하면 다음과 같다.

9-3. DCL (Data Control Language)
데이터의 보안, 무결성, 권한 제어에 사용하는 언어
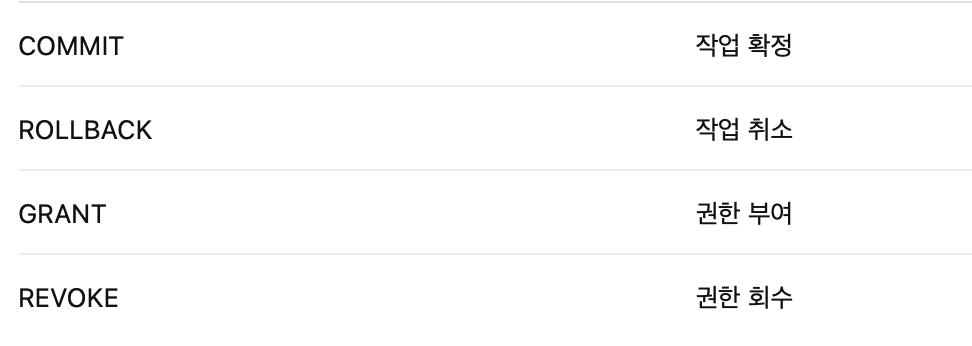
사용 예시는 아래와 같다.
-- 권한 부여
GRANT SELECT, INSERT ON 학생 TO 홍길동;
GRANT ALL PRIVILEGES ON 학생 TO 홍길동 WITH GRANT OPTION;
-- WITH GRANT OPTION: 홍길동이 다른 사용자에게 재부여 가능
-- 권한 회수
REVOKE SELECT ON 학생 FROM 홍길동;
REVOKE SELECT ON 학생 FROM 홍길동 CASCADE;
-- CASCADE: 홍길동이 부여한 권한까지 연쇄 회수9-4. 조건 연산자 및 이외의 연산자들
- 조건 연산자 LIKE: '문자'의 패턴을 검색한다.
WHERE 이름 LIKE '김%'; //김으로 시작
WHERE 이름 LIKE '_철수'; //한글자 + 철수
- BETWEEN: 두 값 사이 범위 검색
WHERE 속성 BETWEEN 값1 AND 값2;- 그룹 함수 (집계 함수): GROUP BY 절에서 그룹별로 속성의 값을 집계할 때 사용한다. 종류는 다음과 같다.
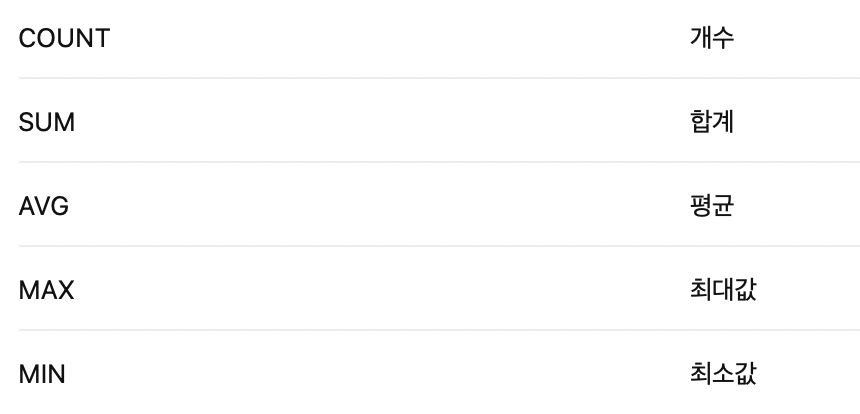
COUNT(*)는 NULL 포함, COUNT(컬럼)은 NULL 제외이다.
- 집합 연산자
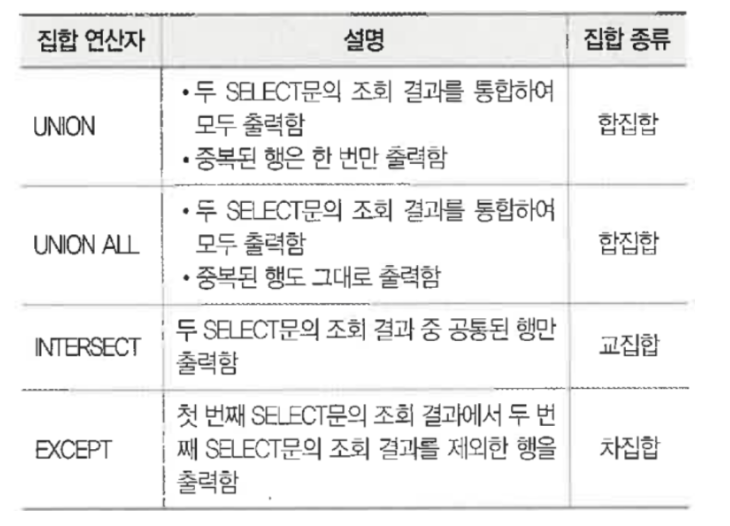
*Trigger
INSERT, UPDATE, DELETE 이벤트 발생 시 자동 실행되는 절차형 SQL
'자동 실행'되며 '이벤트 기반'이다.
