스파르타 코딩클럽 엑셀보다 쉬운 SQL 강의를 듣고 작성하였습니다.
🍩 SQL(Structured Query Language)
DataBase를 구축하고 접근할 수 있게 사용되는 언어이다. 미국 국립 표준 협회가 SQL을 표준으로 재정하여 SQL이 가장 많이 사용된다.
SQL의 종류
SQL은 영어 문장과 유사해서 초보자들도 비교적 쉽게 사용가능하다.
크게 정의언어 DDL, 데이터 조작언어 DML로 나뉜다.
| 분류 | 내용 |
|---|---|
| 데이터 정의 언어 (DDL, Data Definition Language) | 릴레이션 생성, 삭제, 변경 |
| 데이터 조작 언어 (DML, Data Manipulation Language) | 검색, 삽입, 삭제, 갱신 |
✔ Query
Query란 질문이라는 뜻으로, 질의(inquiry)와 같은 뜻으로 사용된다.
파일의 내용을 알기 위해 code나 key를 기초로 질의하는 것을 가리킨다. DB에 존재하는 자료를 사용자가 원하는 조건을 통해 검색하고, 검색된 결과를 자유로이 조회할 수 있는 기능들을 지원한다. 이러한 질의어들이 구조적으로 체계화된 것을 SQL이라고 한다!
🍪 SQL Query문 (Select & Where)
1. SELECT QUERY
Select 쿼리문은 어떤 테이블에서 어떤 필드의 데이터를 가져올지로 구성된다.
Select 쿼리문을 통해 'orders 테이블의 created_at, course_title, payment_method, email 필드를 가져와줘!'라고 명령을 내릴 수 있다.
select * from orders; select created_at, course_title, payment_method, email from orders;
2. Where 절
Where 절은 Select 쿼리문으로 가져올 데이터에 조건을 걸어주는 것을 의미한다.
select * from Orders where payment method = 'kakaopay';
SQL문은 줄을 잘 맞춰주는 것이 중요하다. 나중에 양이 방대해지면 길어지고 헷갈리기 때문이다.
select * from point_users where point >= 5000
select * from Orders where course_title = '앱개발 종합반' and payment_method = 'card' where course_title = '앱개발 종합반' or payment_method = 'card'
이상일 때 >=, 초과일 때 > 이렇게 표현하고, and나 or을 사용하여 조건을 추가할 수 있다.
3. Where 절과 같이 쓰이는 문법
1) != : 같지 않음
2) = : 같음
3) between and : ~사이에 있는 정보를 보고 싶을 때 (범위조건)
4) in(a,b,c,•••) : a또는 b또는 C •••인 데이터를 보고 싶을 때 (포함조건)
5) like + % : 패턴 규칙 (문자열 규칙) 'how to use like in sql' 구글링
select * from users where email like '%daum.net';
4. 이외 유용한 문법
1) Limit : 일부 데이터만 가져올 때
select * from orders where payment_method = "kakaopay" limit 5;
2) Distinct : 중복데이터 제거
select distinct(payment_method) from orders;
3) Count : 몇 개인지 숫자를 세어볼 때
select count(*) from orders
4) Distinct와 Count 한번에 작성해 보기
select distinct(name) from users;
🍋 SQL Query문 (Group by & Order by)
1. Group by
select name, count(*) from users group by name;
1) from users: users 테이블에서 데이터를 불러온다
2) group by name: name이라는 필드에서 동일한 값을 갖는 데이터를 하나로 합쳐준다
3) select name, count(*) : 이름과 count(*)를 출력해 주는데, 여기서 count(*)는 group by로 합쳐진 데이터의 개수를 세어주는 것이다.
2. Group by 기능
1) count
select 범주별로 세어주고 싶은 필드명, count(*) from 테이블명
group by 범주별로 세어주고 싶은 필드명;2) min
select 범주가 담긴 필드명, min(최솟값을 알고 싶은 필드명) from 테이블명
group by 범주가 담긴 필드명;3) max
select 범주가 담긴 필드명, max(최댓값을 알고 싶은 필드명) from 테이블명
group by 범주가 담긴 필드명;4) avg
select 범주가 담긴 필드명, avg(평균값을 알고 싶은 필드명) from 테이블명
group by 범주가 담긴 필드명;avg의 경우 소수점이 길게 나오는 것을 해결하기 위하여 round(avg(필드명),n)) 이런 식으로 avg를 감싸고 n개까지의 소수점 자리가 나오게 한다.
5) sum
select 범주가 담긴 필드명, sum(합계를 알고 싶은 필드명) from 테이블명
group by 범주가 담긴 필드명;3. Order by
문자열 기준으로 정렬, 시간순 기준으로 정렬, 값의 크기 기준으로 정렬, 한글로 정렬 •••
다 가능하다!
select * from 테이블명
order by 정렬의 기준이 될 필드명;desc : descending (내림차순)
asc : ascending (오름차순)
SQL 쿼리가 실행되는 순서를 알아야 에러 없이 쿼리를 작성할 수 있다.
select name, count() from users
group by name
order by count();
위 쿼리가 실행되는 순서: from → group by → select → order by
4. Alias
테이블의 수도 많아지고, 데이터의 양도 많아져서 쿼리가 점점 길어지게 되면 헷갈리는 일이 발생하는 때가 생긴다. 그래서 SQL은 Alias(알리아스)라는 별칭 기능을 지원한다.
select * from orders o where o.course_title = '짱윤서'
select payment_method, count(*) as cnt from orders o where o.course_title = '짱윤서' group by payment_method
🍯 Table Join
아래의 사진들 출처 : cloudstudying.kr
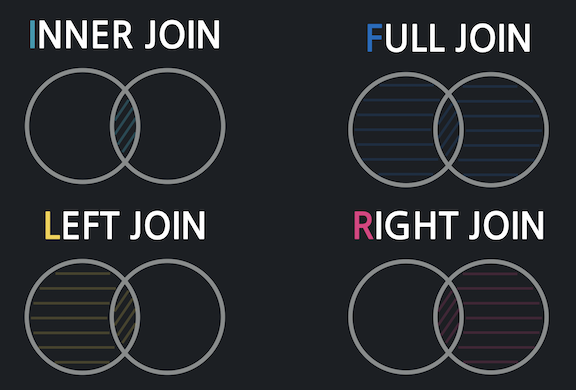

SQL에서의 Join은 두 집합 사이의 관계와 같다.
1. Left Join
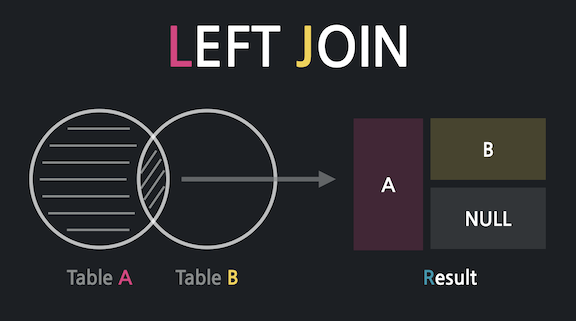
위 그림에서 A와 B는 각각의 테이블을 의미한다. Left Join은 두 테이블의 공통결과 뿐만 아니라, 좌측 테이블의 모든 결과도 가져오는 것이다.
“모든 좌측 테이블을 가져오는데, 조인 가능한 것은 붙이고, 조인 불가능한 것은 NULL로 채운다!”
left join은 어디에 → 뭐를 붙일 건지 순서가 중요하다.
2. Right Join
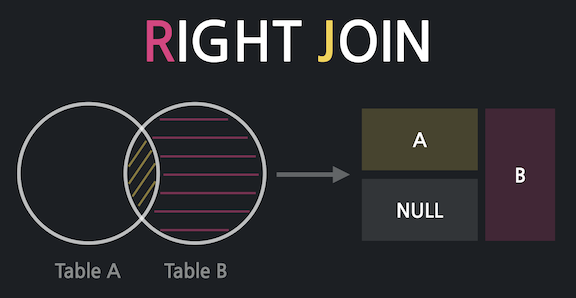
우측 테이블의 모든 결과도 가져오는 것이다.
3. Full Join

조인 가능한 데이터 뿐만 아닌 조인 불가능한 데이터도 가져와서 쓴다.
4. Inner Join
FROM 절의 데이터와 JOIN 절의 데이터를 JOIN 조건을 기준으로 서로 연결하는 것이다. (두 테이블의 교집합이다)
5. SQL 쿼리가 실행되는 순서
select u.name, count(u.name) as count_name from orders o
inner join users u
on o.user_id = u.user_id
where u.email like '%naver.com'
group by u.name위 쿼리가 실행되는 순서: from → join → where → group by → select
select c1.title, c2.week, count(*) as cnt from courses c1
inner join checkins c2 on c1.course_id = c2.course_id
inner join orders o on c2.user_id = o.user_id
where o.created_at >= '2020-08-01'
group by c1.title, c2.week
order by c1.title, c2.weekinner join을 여러 개 연결할 수 있다.
group by, order by 또한 콤마를 이용해서 더 그룹핑하거나 정렬할 수 있다.
count는 NULL값을 자동으로 제외하고 갯수를 세어준다.
🧅 Union
필드가 다 똑같은데, 하나는 7월달 거 하나는 8월달 거.. 붙여서 한 번에 보고 싶을 때? union all
(
select '7월' as month, c.title, c2.week, count(*) as cnt from checkins c2
inner join courses c on c2.course_id = c.course_id
inner join orders o on o.user_id = c2.user_id
where o.created_at < '2020-08-01'
group by c2.course_id, c2.week
order by c2.course_id, c2.week -> 적용 안됨
)
union all
(
select '8월' as month, c.title, c2.week, count(*) as cnt from checkins c2
inner join courses c on c2.course_id = c.course_id
inner join orders o on o.user_id = c2.user_id
where o.created_at > '2020-08-01'
group by c2.course_id, c2.week
order by c2.course_id, c2.week -> 적용 안됨
)union 안에서는 order by가 적용되지 않는다. 이 것은 sub query로 해결할 수 있다.
🍑 쿼리 작성법
1) show tables로 어떤 테이블이 있는지 살펴보기
2) 제일 원하는 정보가 있을 것 같은 테이블에 select * from 테이블명 limit 10 쿼리 날려보기
3) 원하는 정보가 없으면 다른 테이블에도 2)를 해보기
4) 테이블을 찾았다! 범주를 나눠서 보고싶은 필드를 찾기
5) 범주별로 통계를 보고싶은 필드를 찾기
6) SQL 쿼리 작성하기!
🍒 Reference
SQL
Query
cloudstudying.kr
[Table Join - INNER JOIN / 실습]|작성자 지모
스파르타 코딩클럽 엑셀보다 쉬운 SQL 강의

튜터님! TIL보고 배우겠습니다.