- deep learning
- NLP pytorch
0. NLP(Natural Language Processing) 개요
자연어 처리
인코딩: 컴퓨터가 인지하는 형태로 문자열을 처리하는 방법. 인코딩한다는 의미는 유니코드를 utf-8, euc-kr, ascii 형식의 byte 코드로 변환함을 의미함.
디코딩: byte 코드를 유니코드로 변환하여 문자열로 표시하는 방법.

(인코딩하고자 하는 변수명).encode('형태(utf-8, euc-kr, ascii 등)')
(디코딩하고자 하는 변수명).decode('형태(utf-8, euc-kr, ascii 등)')
그 중 가장 좋은 정규화 방법?
ASCII, Unicode ... etc
utf-8(가변길이 인코딩): 현재 아스키코드가 표현하는 알파벳, 숫자, 특수기호의 한계를 인지하고 uft-8을 사용함. 운영체제, 프록그램, 언어에 관계 없이 문자마다 고유 코드 값 제공하는 의의 있음.
(※ 한글 영어만 추출할 때 데이터가 None이 되는 경우는 아스키 코드가 달라서 발생함 -> 유니코드 정규화 필요)
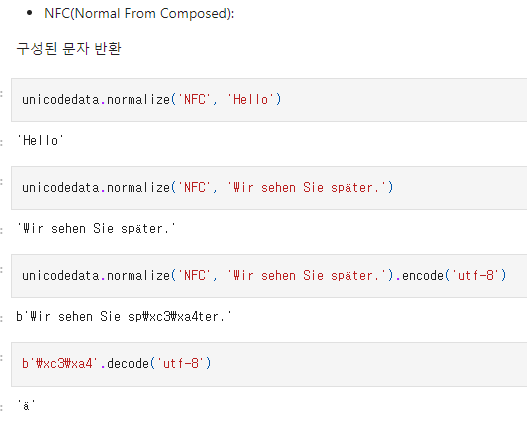
unicodedata 임포트 -> normalize('NFC', '문자열') -> 문자열 반환해서 표시
=> 중요하지만, 한계를 경험하지 못해 아직 필요성을 잘 모르겠음.
CLEANING
처리 대상:
대문자, 소문자 처리 / 출현 횟수 적은 단어 제거 / 노이즈 제거
1)
대문자, 소문자 처리:
US, us 등 대문자 소문자의 뜻이 다른 경우 변경해서는 안됨.
2)
출현 횟수:
출현 횟수 적음에도 중요한 단어는 제거하면 안됨.
3)
노이즈:
관사, 대명사 등 의미 없는 글자 제거
=> 중요. 특히, 대문자, 소문자 처리에 있어 미리 데이터 검토 필요하다는 생각.
(set으로 중복 검사 후 VOCAB 확인하며)
STEMMING
추출 대상:
어간 추출(문법<), 표제어(원형) 추출
1) 어간 추출
ing, s(복수), ness 등 품사를 바꿔주는 접사들을 제거하여
중복성을 낮추고 의미 극대화
2) 표제어 추출
is, are -> be, having -> have 등 품사 정보를 제거
Stopwords 불용어 제거
분석에 도움 되지 않는 단어들 제거
Tokenization 의미 부여 단위
신경망은 훈련 중에 문자 의미와 단어의 문장 형성 과정 이해.
Word level, Char level(문자, 글자 단위) 등 다양한 접근 방식 존재.
token: 텍스트의 원자 조각
Tokenize: 텍스트를 토큰으로 변화하는 과정
Vectorize: 토큰을 신경망 공급 가능한 숫자에 할당
(Vocab: 토큰 어휘 구축해 Vectorize에 이용)
Word Embedding: Vectorize의 과정, 토큰을 공급 가능한 숫자에 할당하는 과정
Vocabulary 어휘집
중복을 제거한 어휘와 index가 정의된 집합. 문자를 숫자로 변환 가능
Encoding 문자 숫자 처리
Encoding의 한계:
1) Out of Vocabulary: 단어장에 없는 경우 손실
2) Order: 순서 정보 손실
Encoding의 방법:
- Integer Encoding
Bag of Words(빈도 값), Count Encoding(단어 토큰 생성, BOW 인코딩 벡터 생성), TF-IDF Encoding(전체 문서의 공통 단어의 가중치 축소) 등 방법들이 있음.
다른 임포트가 없는 경우, 해당 문서 내 공통 정보 축소 이용하는 TF-IDF가 좋아보임.
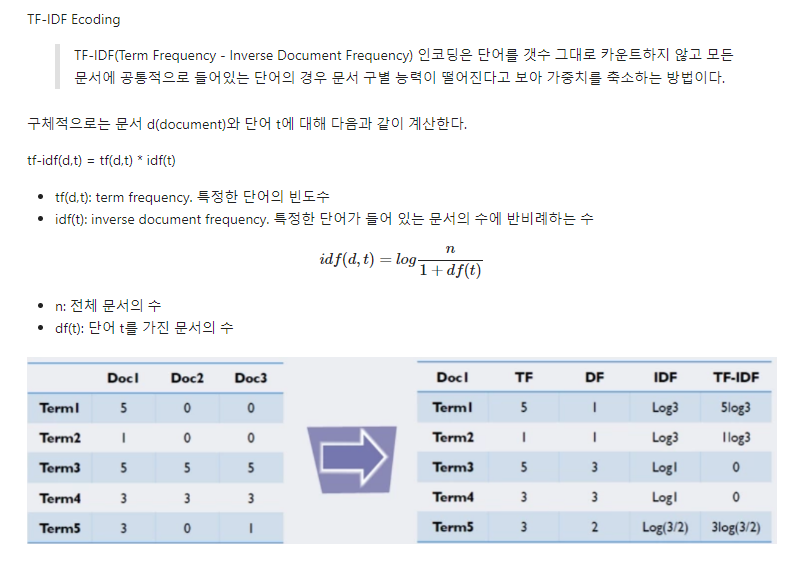
단어 사이의 연관성을 파악하기 어렵다는 단점이 있다.
-One Hot Encoding
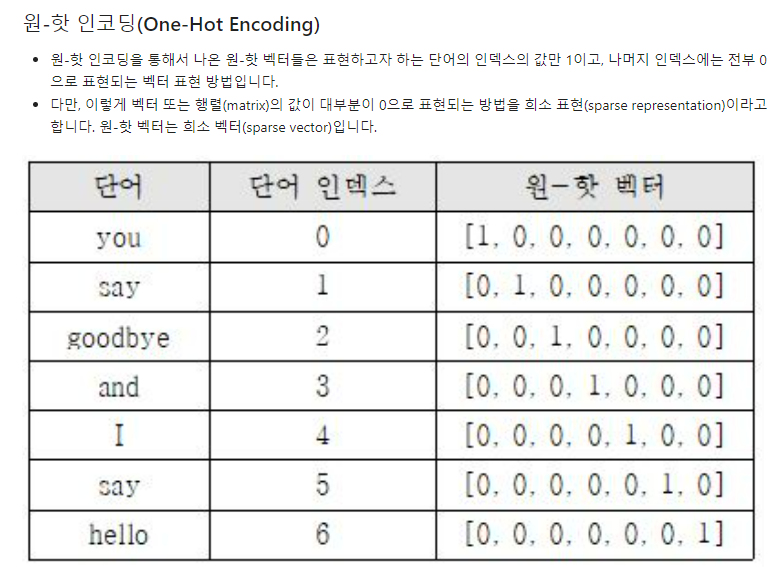
벡터를 단어 개수만큼(index + 1) 만들어 표현하고자 하는 단어의 인덱스를 1, 나머지는 0으로 표시.
다만, 0으로 표시되는 vector가 많아 낭비가 심하다는 sparse vector, 희소 벡터의 단점이 있다.
-Word2vec Encoding
분산 가설, 비슷한 위치의 단어는 비슷한 의미를 가진다-는 가설을 이용하여 비슷한 위치에 존재하는 단어는 단어 간 유사도를 크게 파악.
의미상보다는 문장구조상 특질을 이용
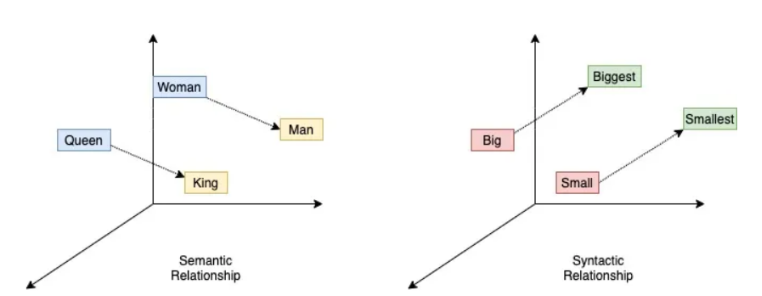
단어의 유사성을 반영할 수 있음.
단어의 모든 의미 구분 못하고, 다른 뜻을 갖는 한 단어에 대한 여러 의미를 묶을 수 있음.
(왜? 의미적 유사성에 관심이 없음)
Word Embedding with neutral network
word Embedding에 신경망을 사용함! -> 벡터화에 학습 사용
LSA, Word2Vec, FastText, Glove 등이 있으나 보편적 Embedding은 단어를 벡터로 변환한 후
가중치를 학습하는 것처럼 단어 벡터를 학습시킴.
단어를 실수 형태 벡터로 표현하고, 신경망에 임베딩 레이어를 추가하여 임베딩 얻음.
Padding
서로 길이가 다른 각 문장, 문서에 대해 길이를 임의로 동일하게 맞춰주는 작업
Similarity 유사도
Euclidean Similarty: 거리 기반 유사도 (L2 distance)
Cosine Similarity: 지향 방향 기반 유사도 (-1 ~ 1 존재)
- deep learning
- NLP pytorch
1-1. Integer Encoding
from torchtext.vocab import build_vocab_from_iterator
1) DictVectorizer - with BOW
from sklearn.feature_extraction import DictVectorizer
vect = DictVectorizer(sparse=False)
data = [{'A': 1, 'B': 2}, {'B': 3, 'C': 1}]
X = vect.fit_transform(data) # 인코딩 수치 벡터로 변환(X)
{'A': 1, 'B': 2} -> [1, 2, 0] {'B': 3, 'C': 1} -> [0, 3, 1]
이때까지 입력받은 값에 대해 빈도 값 부여해 피쳐 값 추출.
또한, 자동으로 단어를 추출.
2) CountVectorizer
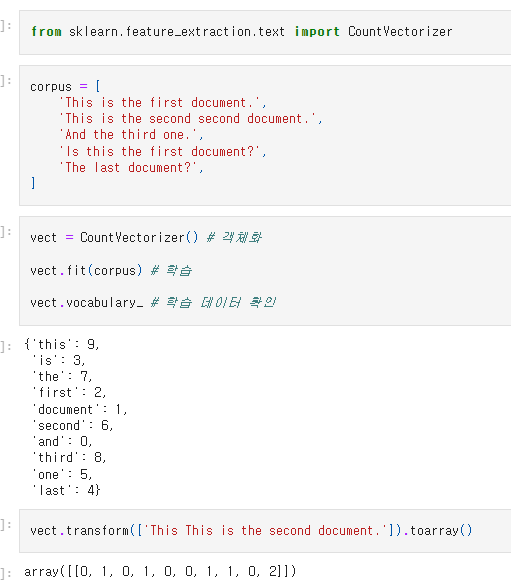
vect.vocabulary_에 vocabulary가 존재하니, 학습 후 확인이 가능함.
객체화, fit 후에 vect.transform('확인하고자 하는 문자열').toarray()을 통해
vocabulary에 대한 빈도 값 확인이 가능함.
0: negative, 1: positive가 아니라 빈도 수를 기반으로 노출
[사용 가능한 메소드]
1
stop_words
vect = CountVectorizer(stopwords=["and", "is", "the", "this"]).fit(corpus)
vect.vocabulary
메소드 stop_words = []를 이용해서 무시할 수 있는 관사, 접속사, 조사 등을 설정 가능함.
2
analyzer, tokenizer
vect = CountVectorizer(analyzer="char").fit(corpus)
vect.vocabulary_
analyzer="char"이면, 글자 단위로
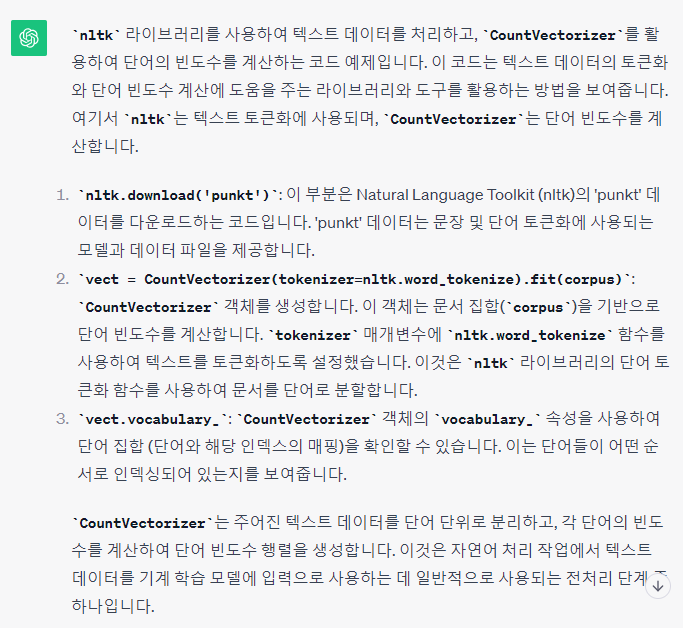
◆ 'punkt' 데이터는 문장 및 단어 토큰화에 사용되는 모델과 데이터 파일을 제공
◆ 이 객체는 문서 집합(corpus)을 기반으로 단어 빈도수를 계산함.
tokenizer 매개변수에 nltk.word_tokenize 함수를 사용하여 텍스트를 토큰화하도록 설정함.
nltk 라이브러리의 단어 토큰화 함수를 사용하여 문서를 단어로 분할함.
-> nltk는 이미 있는 토큰화 모델 중 1, 언제나 이용 가능함.
3
N-gram

개수 설정해서, 토큰 크기 결정함. '연결된'
(잘 안 쓸 듯.)
4
Frequency
max_df, min_df인수를 사용하여 문서에서 토큰이 나타난 횟수를 기준으로 단어장을 구성.
토큰의 빈도가 max_df로 지장한 값을 초과 하거나 min_df로 지정한 값보다 작은 경우에는 무시한다.
vect = CountVectorizer(maxdf=4, min_df=2).fit(corpus) # 단어별 빈도수: 최대 4개, 최소 2개
vect.vocabulary, vect.stopwords
({'this': 3, 'is': 2, 'first': 1, 'document': 0}, #index 기반 vocabulary 노출
{'and', 'last', 'one', 'second', 'the', 'third'}) #stop_words을 자동으로 지정
-> stop_words를 frequency 기반으로 미리 지정해두고 쓸 수도 있을 듯.
ex.
a = vect.stopwords
(stop_words = a)
그런데 CountVectorize를 안 쓰는거지.
TfidfVectorizer
CountVectorizer와 비슷하지만 TF-IDF 방식으로 단어의 가중치를 조정한 BOW 인코딩 벡터를 만든다.
from sklearn.feature_extraction.text import TfidfVectorizer
tfidv = TfidfVectorizer().fit(corpus) #객체화 및 학습
tfidv.transform(corpus).toarray() #corpus에 대해 변형시켜 array로 노출
pd.DataFrame(tfidv.transform(corpus).toarray(), columns = tfidv.get_feature_names_out()) #tfidv 객체의 메소드 get_feature_names_out를 이용해서 columns로 지정하여 데이터 프레임 생성, to array 만들기.
- WordCloud(필요하다면)
[만드는 과정 분석]
!pip install wordcloud
from wordcloud import WordCloud
wc = WordCloud(background_color="white",width=500,height=500) #객체화
corpus = 데이터 리스트
vect = CountVectorizer()
tdm = vect.fit_transform(corpus)
#vectorizer를 통해서 인코딩 벡터를 만든다. (겹치지 않도록 단어장 형성, 빈도 세리기)
df_tdm = pd.DataFrame(tdm.toarray(),columns=vect.get_feature_names_out())
#tdm(corpus로 data가 개수를 반영해서 만들어진 리스트)를 array로 변환한 값을 기준, 그 중에서 columns는 feature에 해당되는 열으로 지정.
df_tdm.sum().to_dict()
df_tdm의 합, 그러니 전체 document에 대한 값들을 더해서 dict의 형식으로 만들기.
{}에 피쳐와 개수(빈도)가 함께 담긴다.
변수 = wc(객체화).generate_from_frequencies(df_tdm.sum().to_dict())
변수.to_image()
그 합의 값들에 대해서 we.generate_from_frequencies 함수를 사용하면 담긴다.
그걸 to_image()로 이미지로 표시하기.
그럼 표시하기 전, dictionary 형태로 표시하는 게 필요해보인다.
벡터는 2개로, 하나는 feature(각 단어), 하나는 빈도.
또, array 형태일 필요가 있다.
※ df = pd.DataFrame(data, columns=columns)
pandas의 DataFrame 만드는 메소드 사용을 위해서는 데이터와 columns 지정이 필수적이다.
- deep learning
- NLP pytorch
1-2. 형태소 분석
import nltk
nltk.download("punkt")
nltk.download("averaged_perceptron_tagger")
sentence = """
At eight o'clock on Thursday morning
Arthur didn't feel very good."""
#토큰화 원하는 document
tokens = nltk.word_tokenize(sentence)
tokens
#형태소 단위로 분석, (개수 안 세리고) 리스트로 만듦
nltk pos_tag: 품사 적용
tagged = nltk.pos_tag(tokens)
tagged
(튜플 형태 구성)
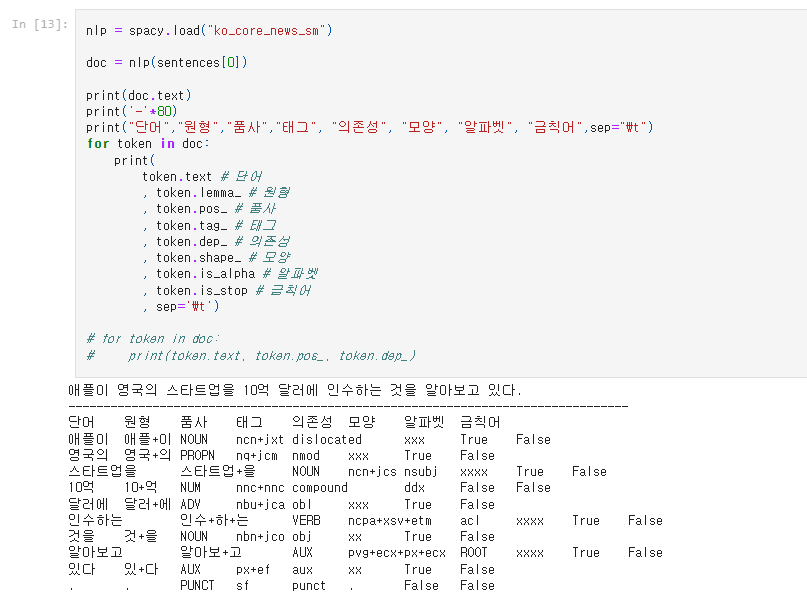
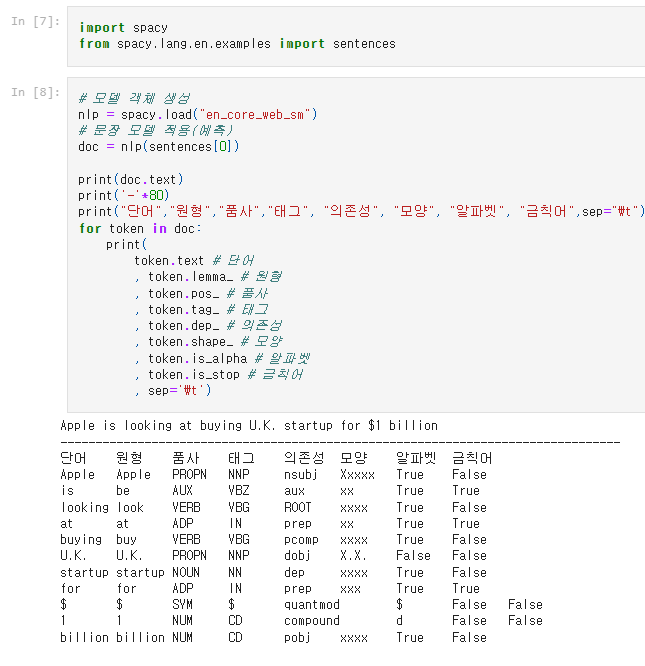
spacy
영어:
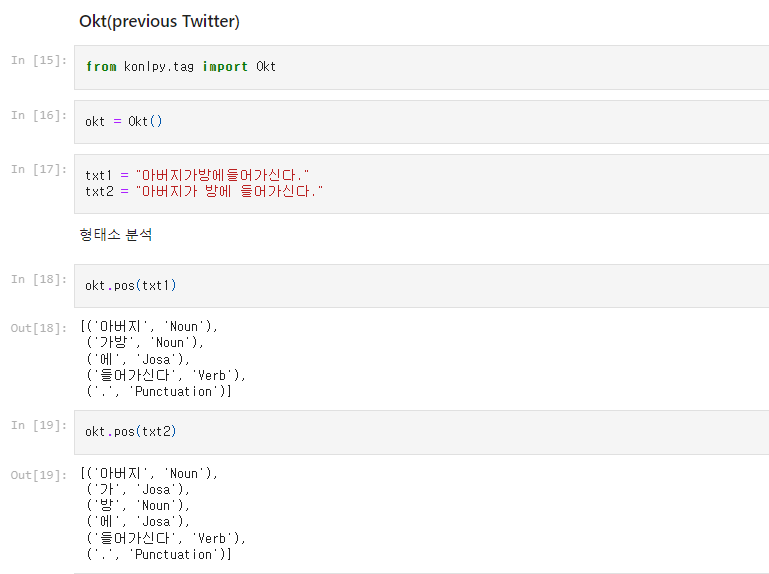
한국어:
Okt 형태소 분석
띄어쓰기 유무에 따라 정확도의 차이가 있지만,
띄어쓰기가 없는 경우에도 형태소 단위로 분석할 수 있음.
(Okt를 사용하되 word_min, max를 위처럼 설정해놓으면 좋을 것 같음.)
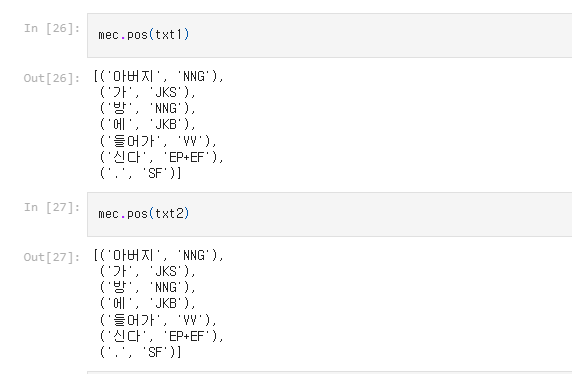
Mecab
(chatgpt: 따라서 선택지는 사용하려는 언어 및 목적에 따라 다릅니다. MeCab는 일본어에 최적화되어 있고, Okt는 한국어 자연어 처리를 간편하게 수행할 수 있는 좋은 선택입니다.)
어쨌든 둘 다 형태소 분석 툴킷 및 라이브러리임.
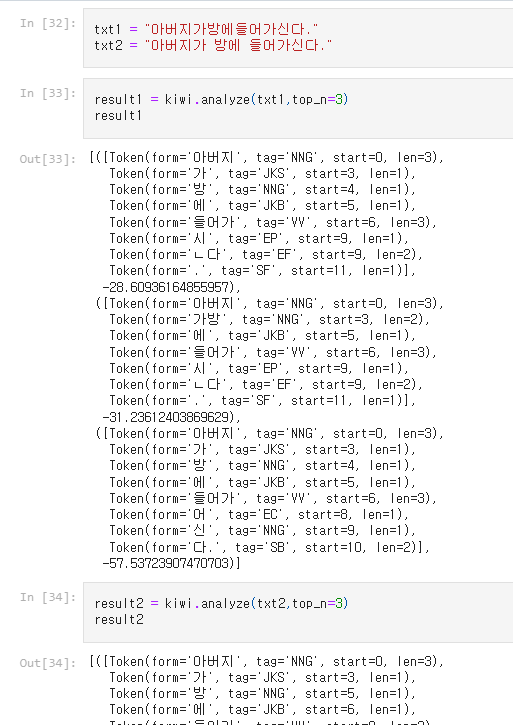
KIWI (추천!)
from kiwipiepy import Kiwi
kiwi = Kiwi() #객체화
result = kiwi.analyze('텍스트',top_n=3) #kiwi의 analyze 메소드 사용, 분석하는 문장과 몇개의 가능한 선택지 제공할 것인지 선택하는 변수 top_n 지정

가능한 여러 개의 가능성들을 열어두고 제시함.
(chat GPT: -27, -31.23612403869629, -57.53723907470703와 같은 숫자는 해당 형태소 분석 결과의 신뢰도나 가중치를 나타내며, 이를 기반으로 최적의 형태소 분석 결과를 선택)
[ token.form for token in result1[0][0]]
우리가 선택할 수도 있지만, [0] 이렇게 가장 신뢰도 높은 걸 선택할 수도 있지.
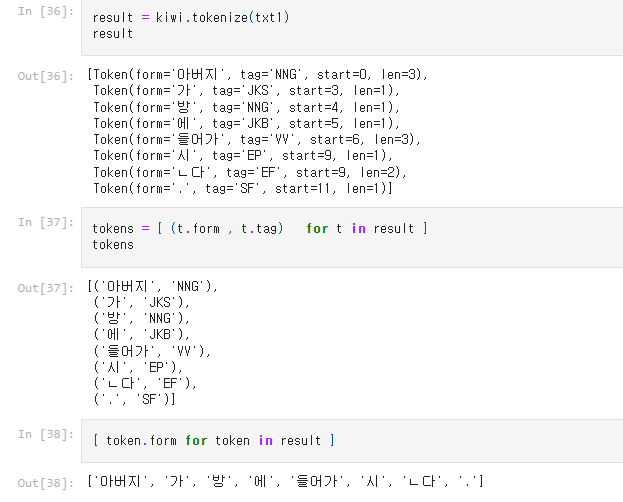
kiwi.tokenize() 메소드를 사용하면, Token(form=, tag=, start=, len=)의 형태로 나온다.
result의 각 개체들을 변수에 저장하고, 변수.form, 변수.tag, 변수.start, 변수.len 등으로
따로 나누는 것도 가능하다.
- stopwords 불용어 메소드
from kiwipiepy.utils import Stopwords
stopwords = Stopwords() #stopwords 인스턴스화.
result = kiwi.tokenize(txt_list, stopwords=stopwords) # 토큰화 & 불용어
for tokens in result:
print(tokens)
tokenize로 txt_list를 토큰화하는 것도, stopword를 지정하는 것도 가능하다.
stopwords.add("NLP")
stopwords.stopwords
#이런 식으로 stopwords.add() 함수를 추가할 수도 있다.
stopwords.remove(["NLP"])
stopwords.stopwords
#이런 식으로 stopwords.remove() 제거할 수도 있다.
(단, 추가할 때에는 단어만 추가해도 됐지만 튜플 형태로 되어있기에... 제거할 때에는 [] 리스트 형태로 표시해야 함)
- deep learning
- NLP pytorch
1. Word2Vec
word embedding을 위한 방법 중 하나, 단어의 유사성을 문장 구조 상 위치로 봄
같은 문장의 인접 단어 간 의미 유사도를 전제함.
다음에 단어가 나올 확률을 계산함.
[이용 과정]
tokenizing -> vocabulary
sliding window size(한 단어의 영향력 범위 설정) -> 입출력 쌍 구성

행렬연산 및 유사성 파악
One-hot encoder를 했을 때 차원 수 = 단어 수 == 5
input layer, output layer node 개수 5
Softmax W1, W2, x를 곱한 결과에 softmax 취해 0과 1 사이 확률로 나타내기
y값과 차이 구해 loss를 줄이기
Bag of Words 방식으로 벡터화하는 것은 유사도, 순서를 나타낼 수 없다.
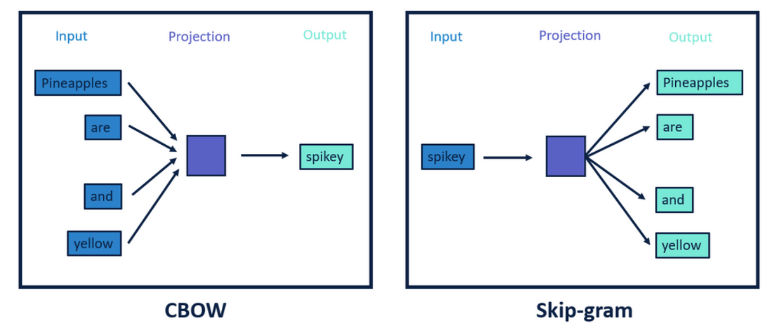
따라서 CBOW나 skip-gram을 사용한다.
CBOW: 한 단어를 주변 단어의 문맥을 이용해 예측
SKIP-GRAM: 어떤 단어를 이용해 주변 단어를 예측
(상관없을 듯? 어쨌든 단어의 주변 환경 고려한 의미를 받아들이기에
사전적 의미[0] 사용보다는 맥락 중심이라 좋을 듯.)
[학습 방법]
import nltk
nltk.download("punkt")
nltk.download("averaged_perceptron_tagger")
#품사 태깅 모델 제공
from tqdm import tqdm
#DICT 비워두기
tokenized_data = []
#DF의 REVIEW열의 각 값들을 SENTENCE라고 치고,
for sentence in tqdm(df['review']):
sentence = sentence.lower() # 대문자를 소문자로 변환
sentence = sentence.replace('
', '') # 필요없는 문자 제거
tokenized_sentence = nltk.word_tokenize(sentence) # 토큰화
tokenized_data.append(tokenized_sentence)
점점 비워둔 'TOKENIZED_DATA'에 추가해나감. 그럼 '단어' 형태의 리스트로 저장이 됨.
소문자화, REPLACE 이후 TOKENIZE 실행
자체 데이터만 가지고 단어 맥락 예측하는 건 일반화 가능!
-> Pre-trained Word2Vec을 사용하는 것은 어떨까여.
word2vec_model = gensim.models.KeyedVectors.load_word2vec_format(dataframe)
#.similarity 메소드 존재 : 단어를 입력하면 유사도 노출해줌.
word2vec_model.similarity('', '')
#.most_similar('') 메소드 존재: 단어를 입력하면 의미적 유사한 단어 노출해줌
- deep learning
- NLP pytorch
2. CNN 1D
1
결측치 데이터 확인, 데이터 제거
2
Text Preprocessing
Cleaning
앞뒤 공백 제거, 불필요 부분 없애기
with
df_ko['document'] = df_ko['document'].map(lambda x: x.strip())
df_ko['document'] = df_ko['document'].map(lambda x: x.replace("..", " "))
3
Tokenization (유의미한 단위로 자르기)
1)
with Mecab
from konlpy.tag import Mecab
mecab = Mecab() #인스턴스화
result = mecab.pos(text) #.pos() 메소드에 텍스트 넣어 결과 추출
2)
with Kiwi(권장)
from kiwipiepy import Kiwi
from kiwipiepy.utils import Stopwords
stopwords = Stopwords() # 불용어
kiwi = Kiwi() # 형태소 분석기 객체화
text = df_ko["document"]
result = kiwi.tokenize(text, stopwords=stopwords)
4
Stemming / Stopword
tokenizer를 통해 나눈 곳에서 의미있는 어간 등으로 추출하기
Stopword를 통해 !, ~ 등 제거
(같은 의미인데 품사가 달라 달리 카운트되면 비효율적임)
def tokenizer(text):
tokens = kiwi.tokenize(text, stopwords=stopwords) # 토큰화
return [ t.form for t in tokens if t.tag[0] in "NJMV" ]
애초에 tokenizer를 정의할 때, tokenize 과정에서 token의 form, tag도 확인이 가능함.
특정 단어를 Stopword로 지정할 수도 있지만,
form, tag의 원하는 종류에 해당하는 token만 선정해 뽑을 수 있음.
return(#우리한테 보이게 해라) t.form for t in tokens (token의 내용들을 t로 선정하고, 그것의 t.form을 노출해라) if t.tag in "NJMV" (만약 그 t.tag가 NJMV 중 있으면.)
tokenizer def 하는 코드에서 사용 가능~!
def yield_tokens(data, tokenizer):
for text in tqdm(data):
yield tokenizer(text)
얘는 yield_tokens(data, tokenizer)를 정의하는 것.
넣으면 tokenizer(text)를 산출함.
결국! yield_tokens를 산출해서 데이터셋을 만들기 위해서는
yield_tokens를 정의해야하고, 정제 과정에서의 tokenizer도 정의해야하고
tokenizer는 kiwi.tokenize의 툴에 불용어와 허용 품사를 정해 넣을 것임.
5
vocabulary
그래서. 지금 정리해서 의미 있는 단어들만 추출했음!
그 단어들을 담아 이 dataframe의 단어들과 index를 노출하는 단어집을 만들겠음.
(패딩): 0
(정의되지 않은 문자): 1
gen = yield_tokens(df_ko["document"],tokenizer) # 토큰화
역시 yield_tokens에 데이터와 tokenizer를 넣는군. 실제로 data 값을 넣는 작업을 시작함.
(앞엔 인스턴스와 변수를 정의한 것일 뿐이져~)
vocab = build_vocab_from_iterator(gen, specials=["",""]) # 어휘집
(gen은 데이터구요, build_vocab_from_iterator(data, specials = [지정]))
그럼 data를 기반으로 specials = []를 지정해서 special + 정제된 데이터 토큰화된 것을 이용해
vocabulary를 만들어내고, 그것을 vocab에 담는다.
vocab.set_default_index(vocab[""])
unk가 vocab에 있잖앙. 그걸 default로 지정한다 => vocab에 없는 단어들은 unknown으로 지정
어 근데 data를 그대로 이용해서 vocab을 만들었잖아용?? 근데 왜 단어가 없을 수 있죵?
왜냐면 NJMV에 해당하는 유의미한 어간들만 냈자나여!
의미 없는 것들이 unk에 저장됐을 거에엽.
그럼 이제 어휘집에서
1) len 전체 길이를 산출해낼 수 있다.
2) lookup_tokens : index를 NLP로 바꿈
3) vocab(['', '']) : NLP를 index로 바꿈
features = [ vocab(tokenizer(text)) for text in tqdm(df_ko["document"].tolist()) ]
features = [vocab(tokenizer(text)) for text in df_ko["document"].tolist()]
features는 text를 tokenizer한 것을 vocab에 담음.
#1. 토큰화가된 결과 데이터를 담을 변수 선언
#2. 데이터 프레임에서 for문으로 돌린다.
#3. tokenizer()함수를 이용해서 데이터를 토큰화(글자)
#4. vocab()함수를 이용해서 토큰화(글자)를 토큰화(숫자) 변환
#5. 변수에 해당 결과(토큰화(숫자))를 담음
6
Padding
max_len = max(len(lst) for lst in features)
max_len
**features = [ lst + [0] * (max_len - len(lst)) if len(lst) < max_len for lst in tqdm(features) ]**
features = np.array(features)
features.shape # 10000.48
max_len == len(features[0])
7
Dataset
6- padding을 통해 feature를 형성한 다음, dataset을 만들어보자.
target = df_ko["label"].to_numpy()target.shape
지금은 (10000,)이니까 (10000,1)로 변형시키기 위해
target = target.reshape(-1,1)
target.shape
