플레이데이터 데이터 엔지니어링 28기 2월 3주차 회고록 /ᐠ。ꞈ。ᐟ↘
안녕안녕
(●'◡'●)
ADsP 공부와 Final Project, AWS 자격증을 위한 공부를 병행하고 있는 요즘입니다.
잠깐 팀 파이널 프로젝트에 대해 설명하자면,
🎆 팀 README
https://github.com/PlaydataFinal/Final_project/blob/main/README.md
저는 팀에서 파생변수 생성과 함께 모델링을 맡아 진행하고 있고,
OCR 모델 구성, 추천모델 파생변수 생성을 위한 모델, 챗봇 모델을 만들고 있습니다.
준비하며 적었던 개인 메모와 회고록을 공유합니다.
일별 메모
🎈
2/14
- FINAL PROJECT
- 챗봇 GEMINI 파인튜~닝
- EDA
- 재무회계에서 머신러닝 / 딥러닝 사용 공부
- AWS 공부
Alpaca나 gpt 다양한 챗봇 api에 접근을 해 봤는데
역량 문제인지 ... 일단 alpaca는 기본적으로, 주지 않은 정보에 대해서 알고 있지 않았었고 gpt는 과금이었기 때문에 ^^
구글의 Gemini를 사용해보기로 했는데요.

저희가 이용할 챗봇은 제주도 관광지에 대한 네이버(타사) 정보들을 알고 있어야 했기 때문에, 파인튜닝이 꼭 필요한 상황이었습니다.
완전 공짜는 아니지만, 저는 상윤님의 api key를 사용했기 때문에
질문을 막 했답니다.
사실 어느 수준까지는 공짜랩니다.
코드 리뷰를 잠깐 해보겠습니다.
#설치
%pip install -U --quiet langchain-google-genai
#임포트
from langchain_google_genai import ChatGoogleGenerativeAI
#인스턴스화
llm = ChatGoogleGenerativeAI(model="gemini-pro")
result = llm.invoke("헬로키티아일랜드의 장소가 어디야?")
Markdown(result.content)
질문을 해 봤는데요.
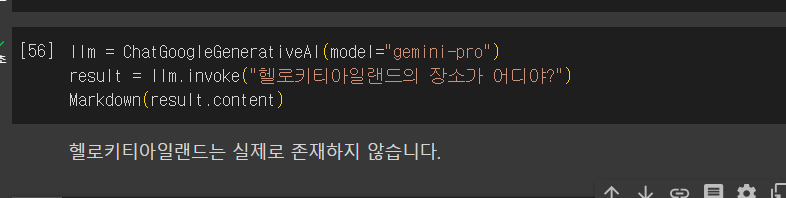
넹?
아주 멀쩡히. 운영중인 헬로키티 아일랜드를 없애다닛.
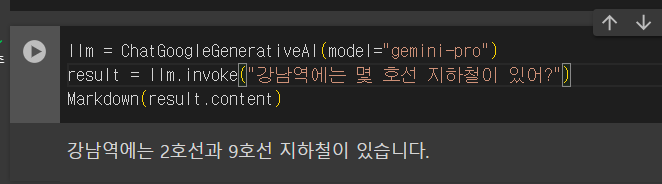
(참고: 강남역은 2호선과 신분당선이 지나갑니다.)
이렇게 AI가 아는 것처럼 이야기하는 것을 '환각현상'이라고 하죠.
https://www.donga.com/news/Opinion/article/all/20230319/118420844/1
그래서 예전 경진대회에서 챗봇을 학습시킬 때에도,
엄격한 프롬프팅을 진행해서 경고를 해 줬답니다.
강의 내용에 없는 건 없다고 햇! 이렇게.
프롬프팅에 관해서는 내일 알아보겠습니다.
프롬프팅 전에, 저희가 가진 정보들로 학습을 시켜야겠죠.
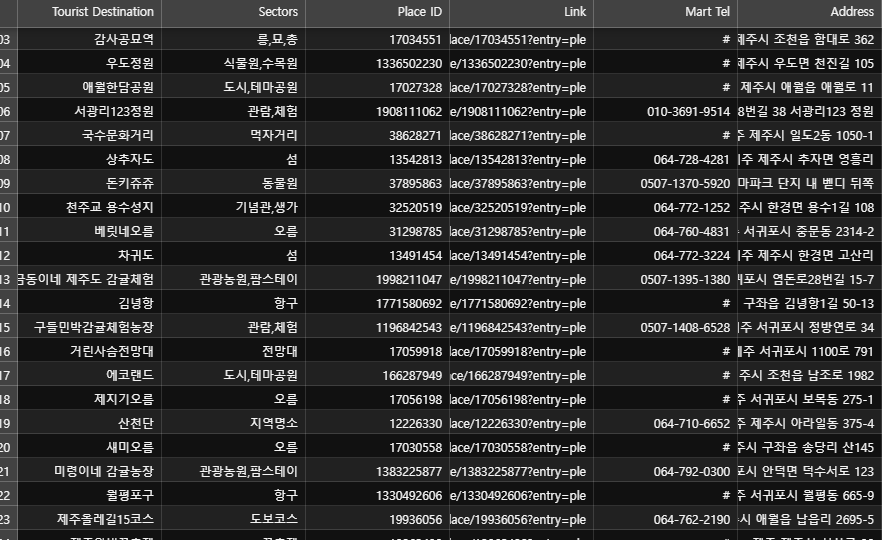
우선 우리가 가진 파일은 csv 파일입니다.
그리고 가장 처음, GEMINI 사용 방법 예제 코드는 pdf 로드였어요.
우선, 인풋 데이터들을 pdf 형식으로 변경하기보다 코드 자체를 txt를 로드하도록 바꾸는 게 나을 것 같아 텍스트를 로드할 수 있는 형태로 변경했습니다.
또 csv를 그대로 학습시키자니, 로우와 컬럼의 관계를 (당연히) 이해하지 못하기에, csv 파일을 전처리 과정으로 txt 파일로 변환했습니다.
from langchain.vectorstores import Chroma
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain.embeddings import HuggingFaceEmbeddings
#파일에서 텍스트 읽기
file_path = "/content/drive/MyDrive/placetest.txt" # 파일 경로를 적절히 수정하세요.
with open(file_path, "r", encoding="utf-8") as file:
text_data = file.read()
#텍스트를 적절한 크기로 분리
text_splitter = RecursiveCharacterTextSplitter(chunk_size=500, chunk_overlap=50)
texts = text_splitter.split_text(text_data)
#HuggingFace의 S-BERT 모델을 사용하여 임베딩 생성
model_name = "jhgan/ko-sbert-nli"
model_kwargs = {'device': 'cpu'}
encode_kwargs = {'normalize_embeddings': True}
hf = HuggingFaceEmbeddings(
model_name=model_name,
model_kwargs=model_kwargs,
encode_kwargs=encode_kwargs
)
#문서 객체 생성 (딕셔너리 형태)
documents = [{"text": text, "metadata": {"page_number": i + 1}} for i, text in enumerate(texts)]
#Chroma 인덱스 생성
docsearch = Chroma.from_texts([doc["text"] for doc in documents], hf)
loader = PyPDFLoader("/content/drive/MyDrive/outputfile.pdf")
pages = loader.load_and_split()
text_splitter = RecursiveCharacterTextSplitter(chunk_size=500, chunk_overlap=50)
texts = text_splitter.split_documents(pages)
from langchain.embeddings import HuggingFaceEmbeddings
model_name = "jhgan/ko-sbert-nli"
model_kwargs = {'device': 'cpu'}
encode_kwargs = {'normalize_embeddings': True}
hf = HuggingFaceEmbeddings(
model_name=model_name,
model_kwargs=model_kwargs,
encode_kwargs=encode_kwargs
)
docsearch = Chroma.from_documents(texts, hf)
from langchain.prompts import ChatPromptTemplate
from langchain.schema.runnable import RunnableMap
template = """Answer the question as based only on the following context:
{context}
Question: {question}
"""
prompt = ChatPromptTemplate.from_template(template)
gemini = ChatGoogleGenerativeAI(model="gemini-pro", temperature = 0)
chain = RunnableMap({
"context": lambda x: retriever.get_relevant_documents(x['question']),
"question": lambda x: x['question']
}) | prompt | gemini
Markdown(chain.invoke({'question': "제주별빛누리공원이 무슨 분류야?"}).content)

와! 대답이 잘 나왔네요. 아까는 폐쇄되었다더니 크크

추가했던 sector 정보도 잘 나옵니다.
지금 기입한 정보는 관광지명, 분류, PLACE ID, 링크, 마트 정보, 주소 뿐이지만, 우선 리뷰에서 뽑아낸 인덱스 단어들을 추가하고 나중에 시간이 남고 성능이 괜찮으면 네이버 리뷰 정보 전체를 다 추가해보는 것으로 합시다.
그런데 문제가 있다면...
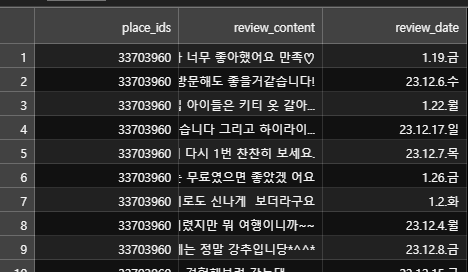
다른 테이블들에는 place_ids만 있고, 가게명은 없어요.
그럼 가게명이 있는 테이블과 조인을 해야 할 것 같은데, 생각보다 조인이 많이 일어나고 있어서 이럴거면 왜 테이블을 분리해놨지 싶기도 합니다.
ERD를 다시 한 번 짜봐야 할 것 같습니다.
- 인덱스!
회원가입을 했을 때 저희는 MBTI처럼 마음에 더 드는 쪽을 선택하는 간단한 테스트로 유저 취향을 파악할 예정인데요.
어떻게 분류를 나눌까 싶어서 자주 들어가는 인덱스 단어들과 섹터들을 확인해보려 했습니다.
워드클라우드를 그려보니!

아니 재밌어가 왜 명사냐고 ㅋㅋ
저는 OKT의 함수인 NOUNS (OKT는 형태소 분류 기능 포함)를 이용해
분명 명사만 추출했거든요?
그런데 저 밌 애들은 무엇인가.
형태소분석기의 문제인가싶어 MECAB과 HANNANUM을 다 사용해봤는데 결과는 다 비슷했고, 더 심했으면 심했습니다.
그래서 자세히 살펴보니까, 오히려 작은 글자들, 그리고 '밌' 빼고는 다 괜찮더라구요. 아이스크림, 해변, 경험, 금연, 마을, 돌고래, 걷기, 관람, 작품, 자전거, 강아지, 모래, 쇠소깍, 해안, 아기 ... 저희가 딱 원했던 단어들이었습니다.
그래서 자세히 들여다봤죠.

제일 위, 즉 오래되고 리뷰가 많은 데이터들은 아주 명사들이 잘 출력이 된 반면에 최근에 올라오고 리뷰가 적은 관광지들은 아주 형편이 없더군요.
코드를 '꼭 10개!'라고 정해뒀더니, 어쩔 수 없이 나온 것 같습니다.
리뷰가 N개 이하면 탈락-이라고 하기 보다는, 가중치에 제한을 두는 게 나을 것 같습니다.
내일은 이렇게 어떤 제한을 걸어두는 코드를 짜 보겠습니다.
Finance & Statistics 전공으로 ph.D를 가고 싶어서
3학년 2학기부터는 준비를 해 보려고 합니당
마침 진로 관련으로 써 낼 게 있어서 적어봤죵 ...

아직 안 해 봐서 말은 거창함.

2/15 모델팀
우리의 목표 !!
1. 전처리:
1) 한 테이블 내 칼럼명 통일 (place_ids Place ID 등)
2) Sector 분류 nunique해서 묶을 수 있는 거 묶기 (하드코딩)
3) 테이블 조인
2. 버스 노선 학습
- 질문 받을 만한 거 (비짓제주 참고) 생각하기
-> 텍스트 파일로 바꾸기 - 길찾기 API
-
시간 남으면 컬럼 추가
-
추천 모델 구상
나는 오늘 전처리를 위해서 !
우선 과자를 좀 먹었다.
어제 생각했던 건, 지금 불필요하게 나뉜 테이블이 많은 것 같아서
테이블을 나눠 둔 건 빠른 검색을 위해서였는데
조인을 하느라 더 오랜 시간과 불필요한 코드가 생긴다는 거였다.
그리고 일대다 관계가 아니면 정리하고자, 일단 우리가 가진 테이블들과 컬럼들을 쭉 써 보았다.
우리는 place, food, sleep (단순한 이름 ㅈㅅ...)
즉 관광지, 숙소, 식당을 분류해서 띄우는 것을 목표로 한다.
데이터소스는 visitjeju와 네이버 사이트였는데,
네이버사이트에서 긁어온 데이터 테이블, 리뷰와 이미지, 키워드, 평점은 모두 place_ids라는 primary key로 묶일 수 있는 것과 다르게
tour_food, tour_sleep, tour_place는 place_ids 값을 가지고 있지 않았기에 어떻게 통일할지 걱정이 되었다.
visitjeju 것들을 사용하지 않을 수도 있었지만,
관광공사가 더 많은 관광지들을 보유하고 있었고 (네이버에 비해서 약 3천여개 더 많다)
다른 소스에서 가져온 데이터를 조인하는 경험도 필요할 것 같아서,
포기말고 방법을 생각했다.
EDA로 데이터들을 비교해봤다.
우선 tour_place라는, 가게명을 기준으로 본 결과
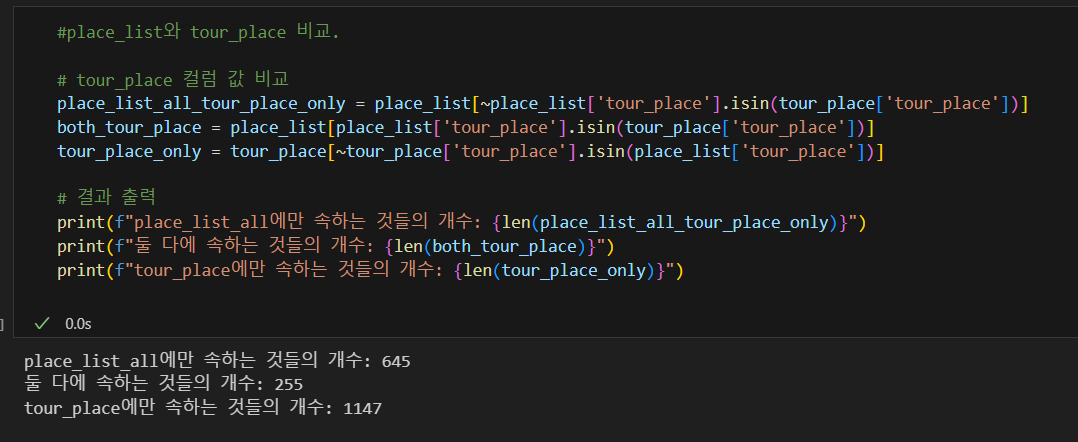
예상 외로 겹치지 않는 것이 많았다.
자세히 뜯어 확인해보니,

동일한 가게가 다른 이름으로 들어있는 경우가 있었다.
여기서 하드코딩을 사용하는 건 좀 아닌 것 같고,
중복되지 않아 primary key로 쓸 수 있으면서
두 개 테이블에 모두 들어있는 칼럼을 확인했다.
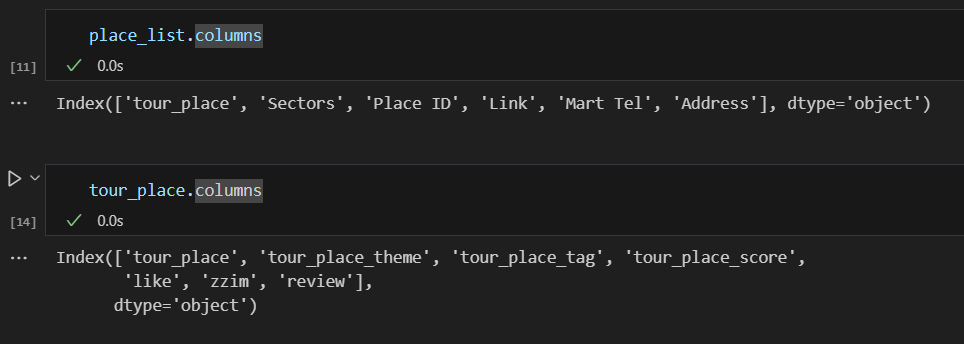
겹치는 게 없었다. 그래서 tour_place를 가져온 소스 페이지를 가 봤는데,
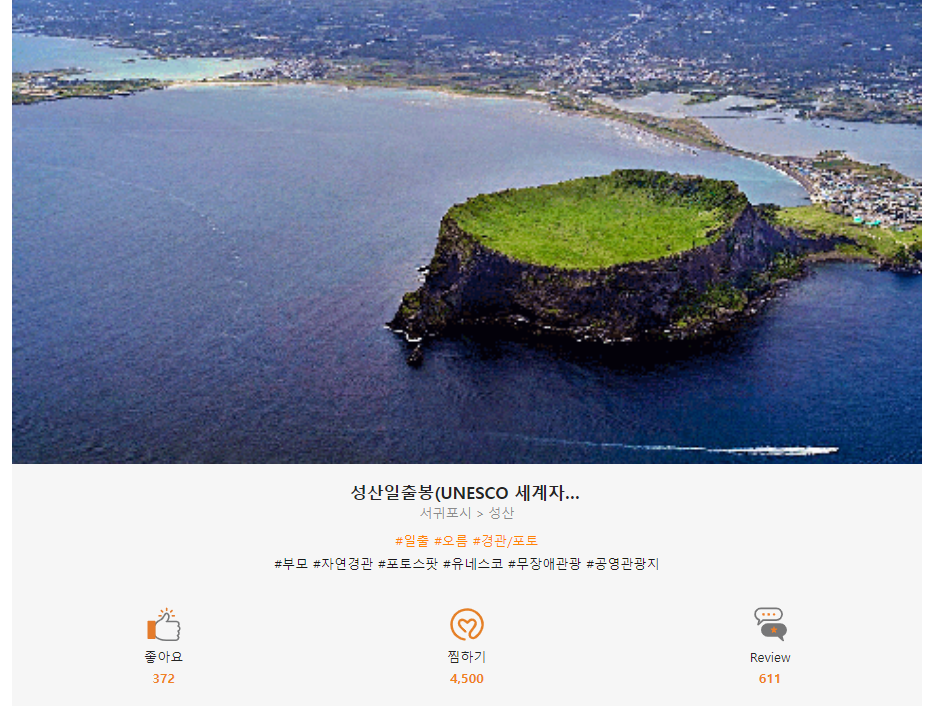
크롤링팀에서 가져온 데이터들은 상세정보 클릭 전이고,
클릭해서 들어가봤을 때
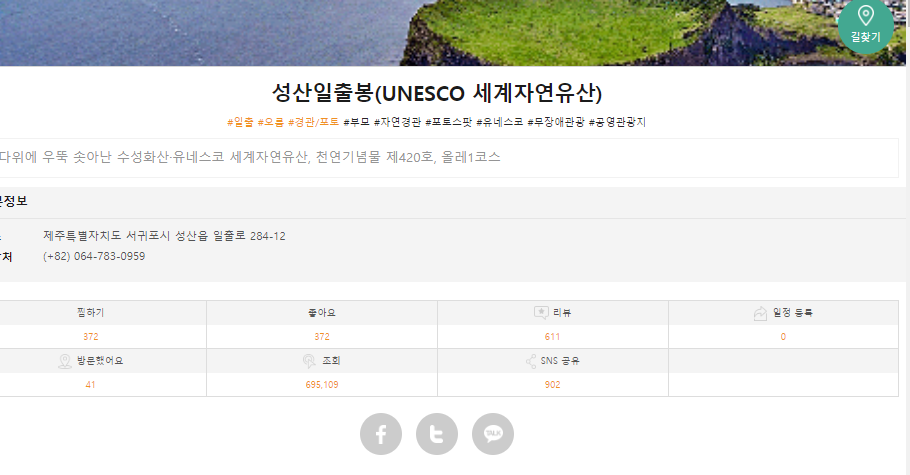
쓸 수 있는 데이터들이 훨씬 더 많았다.
그럼 크롤링 코드를 다시 짜서,
연락처(근데 visitjeju에는 (+82)가 붙어있어서 그걸 제거하고 써야겠지)나 주소를 primary key로 써서, 같은 것들을 묶어줘야겠다고 생각했다.
그런데 연락처가 없는 경우(길거리 등)면 어떡하지.
...
그런 생각은 드는 군.
결측치를 생각해봐야지 뭐.
일단 이름에 대해서 join을 한 다음에, 남은 것 중에 전화번호로 join을 하고, 그 다음 주소로 join을 하고 ... 하는 것은 어떨까.
일단 데이터를 가져와보자!
크롤링 코드로 대표사진과 이름, 태그, 설명, 기본정보 중 주소, 연락처, 찜하기, 좋아요, 리뷰, 상세정보, 이용 시간, 요금 정보, 장소 특성, 주요 목적, 주요목적 기타, 평균 소요 시간, 경사도(난이도)에 해당하는 데이터들을 모두 가져와야겠다.
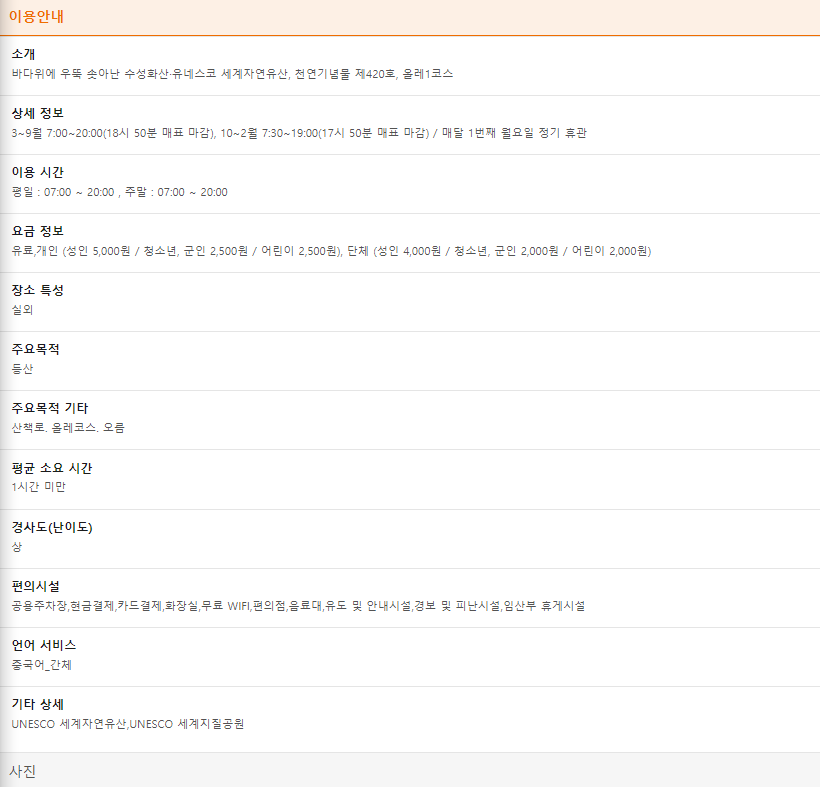
크롤링을 하면서 느낀 점은,
안 쓰면 나중에 드랍하면 되니까 일단 긁어올 수 있는 건 모두 긁어오자는 것이다.
그런데 이 페이지는 정적 페이지가 아니라, '이용안내'를 눌러야 나타나는 동적 페이지이기 때문에 Selenium 라이브러리를 써야 할 것 같다.
크롤링을 해 보자!
[코드리뷰]
from selenium import webdriver
from selenium.webdriver.common.by import By
import pandas as pd
from tqdm import tqdm
#에러 발생 횟수를 체크할 변수
error_count = 0
#시작 페이지 번호
start_page = 1
#종료 페이지 번호
end_page = 9999
#데이터를 저장할 데이터프레임 생성
columns = ['tour_place', 'tour_place_tag', 'tour_place_score', 'tour_place_addr', 'tour_place_tel', 'tour_place_detail', 'tour_place_side', 'tour_place_zzim', 'tour_place_review_count', 'tour_place_view_count', 'tour_place_visit_count', 'tour_place_share_count', 'tour_place_contentsid']
tour_place_df = pd.DataFrame(columns=columns)
#driver_path = '/path/to/chromedriver'
driver = webdriver.Chrome()
for page_number in tqdm(range(start_page, end_page + 1), desc='Pages'):
formatted_page_number = f"{page_number:04d}"
url = f"https://www.visitjeju.net/kr/detail/view?contentsid=CONT_00000000050{formatted_page_number}&menuId=DOM_000001718000000000#"
driver.get(url)
# 에러 페이지인지 확인
if 'visitjeju.net/kr/common/errorPage' in driver.current_url:
error_count += 1
# 연속된 300번의 에러가 발생하면 중단
if error_count == 300:
print("20 consecutive errors. Stopping.")
break
continue
else:
# 에러가 아니라면 에러 카운트 초기화
error_count = 0
# 페이지 로드를 기다림
driver.implicitly_wait(5)
# 필요한 요소 추출
sub_info_title_elements = driver.find_elements(By.CLASS_NAME, 'sub_info_title')
tag_area_elements = driver.find_elements(By.CLASS_NAME, 'tag_area')
score_area_l_elements = driver.find_elements(By.CLASS_NAME, 'score_area_l')
addr_elements = driver.find_elements(By.CSS_SELECTOR, "#content > div.cont.detail_page.detail_style > div.sub_visual_wrap > div.inner_wrap > div.sub_info_area > div.basic_information > div:nth-child(2)")
tel_elements = driver.find_elements(By.CSS_SELECTOR, "#content > div.cont.detail_page.detail_style > div.sub_visual_wrap > div.inner_wrap > div.sub_info_area > div.basic_information > div:nth-child(3)")
detail_box_elements = driver.find_elements(By.CLASS_NAME, 'add2020_detail_box_in')
detail_box_side_elements = driver.find_elements(By.CLASS_NAME, 'add2020_detail_side_info')
zzim_elements = driver.find_elements(By.CSS_SELECTOR, '#content > div.cont.detail_page.detail_style > div.cont_wrap.sub_visual > ul > li:nth-child(2) > button > p.appraisal_cnt')
like_elements = driver.find_elements(By.CSS_SELECTOR, '#content > div.cont.detail_page.detail_style > div.cont_wrap.sub_visual > ul > li:nth-child(1) > button > p.appraisal_cnt')
reviewcount_elements = driver.find_elements(By.CSS_SELECTOR, '#content > div.cont.detail_page.detail_style > div.cont_wrap.sub_visual > ul > li:nth-child(3) > p.appraisal_cnt')
viewcount_elements = driver.find_elements(By.CSS_SELECTOR, '#content > div.cont.detail_page.detail_style > div.cont_wrap.sub_visual > ul > li:nth-child(6) > p.appraisal_cnt')
visitcount_elements = driver.find_elements(By.CSS_SELECTOR, '#content > div.cont.detail_page.detail_style > div.cont_wrap.sub_visual > ul > li:nth-child(5) > p.appraisal_cnt')
sharecount_elements = driver.find_elements(By.CSS_SELECTOR, '#content > div.cont.detail_page.detail_style > div.cont_wrap.sub_visual > ul > li:nth-child(7) > p.appraisal_cnt')
# 추출한 요소를 데이터프레임에 추가
data = {
'tour_place': [element.text.strip() for element in sub_info_title_elements],
'tour_place_tag': [element.text.strip() for element in tag_area_elements],
'tour_place_score': [element.text.strip() for element in score_area_l_elements],
'tour_place_addr': [element.text.strip() for element in addr_elements],
'tour_place_tel': [element.text.strip() for element in tel_elements],
'tour_place_detail': [element.text.strip() for element in detail_box_elements],
'tour_place_side': [element.text.strip() for element in detail_box_side_elements],
'tour_place_zzim': [element.text.strip() for element in zzim_elements],
'tour_place_like_count' : [element.text.strip() for element in like_elements],
'tour_place_review_count' : [element.text.strip() for element in reviewcount_elements],
'tour_place_view_count' : [element.text.strip() for element in viewcount_elements],
'tour_place_visit_count' : [element.text.strip() for element in visitcount_elements],
'tour_place_share_count' : [element.text.strip() for element in sharecount_elements],
'tour_place_contentsid': [f"CONT_00000000050{formatted_page_number}" for _ in range(len(sub_info_title_elements))]
}
page_df = pd.DataFrame(data)
tour_place_df = pd.concat([tour_place_df, page_df])#모든 값을 '없음'으로 인코딩
tour_place_df.replace("", "없음", inplace=True)
tour_place_df.replace(" ", "없음", inplace=True)
#CSV 파일로 저장
tour_place_df.to_csv('tour_places_data.csv', index=False)
#데이터프레임 출력
print(tour_place_df)
#WebDriver 종료
driver.quit()
오랜만의 크롤링.
내가 컴퓨터를 부려먹는건지
컴퓨터가 나를 부려먹는건지 ...
잘 되고 있는 거 확인하고 벨로그 정리 중임.
원래보다 훨씬 많은 정보들을 가져오기로 했다!
주소, 전화번호, 디테일 정보, 공유 개수, 조회수 등도 같이 가져오기로 했걸랑.
그리고 트레이닝 데이터에 넣기 좋을 것 같은
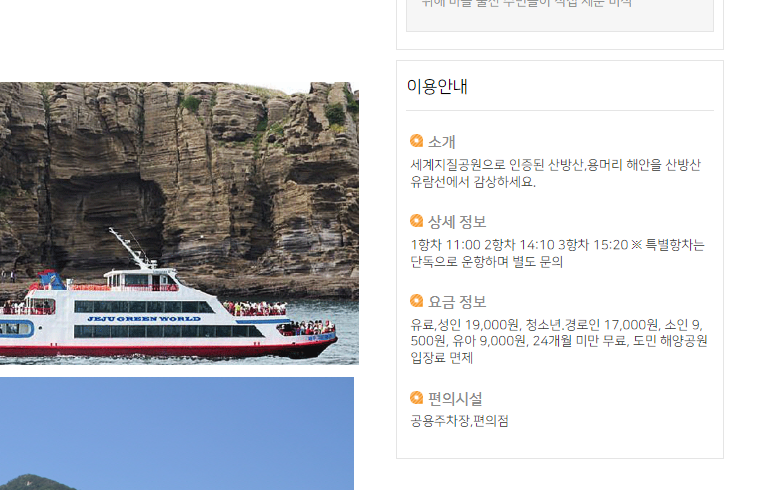
이용안내 부분도 추가해서 가져오기로 했다.
그래서 primary key로 쓰일 수 있는지 파악하기 위해서
주소랑 전화번호 정보가 table 내에 중복되지는 않는지부터 먼저 확인하고
결측치 개수를 센다.
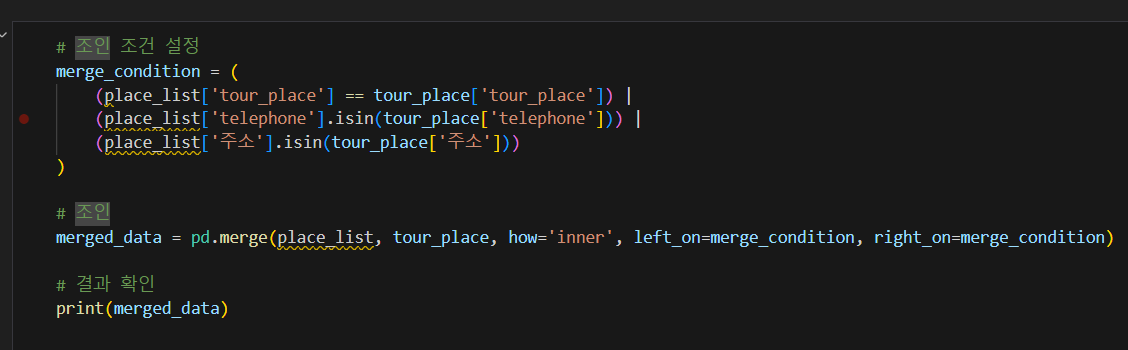
nunique를 세었을 때 전체 컬럼 개수랑 같으면 문제 없이 merge될 것이다.
그 다음 나오는 교집합 외 부분에 대해서는 또 ... 눈으로 보면서 비교해야겠지?
그냥 내일 크롤링이 완전히 잘 되길 바랄 뿐이다.
- 어제 하기로 했던.
리뷰에서 명사가 아니었던 것들이 나온 이유를 분석해봤다.
일단 리뷰 수가 적은 순으로 place_ids를 출력한 다음, 그들의 핵심 단어들을 보았다. 그러니까 문제가 됐었던 힝힝, 밌었던, 밌다, 밌어들이 있었다.
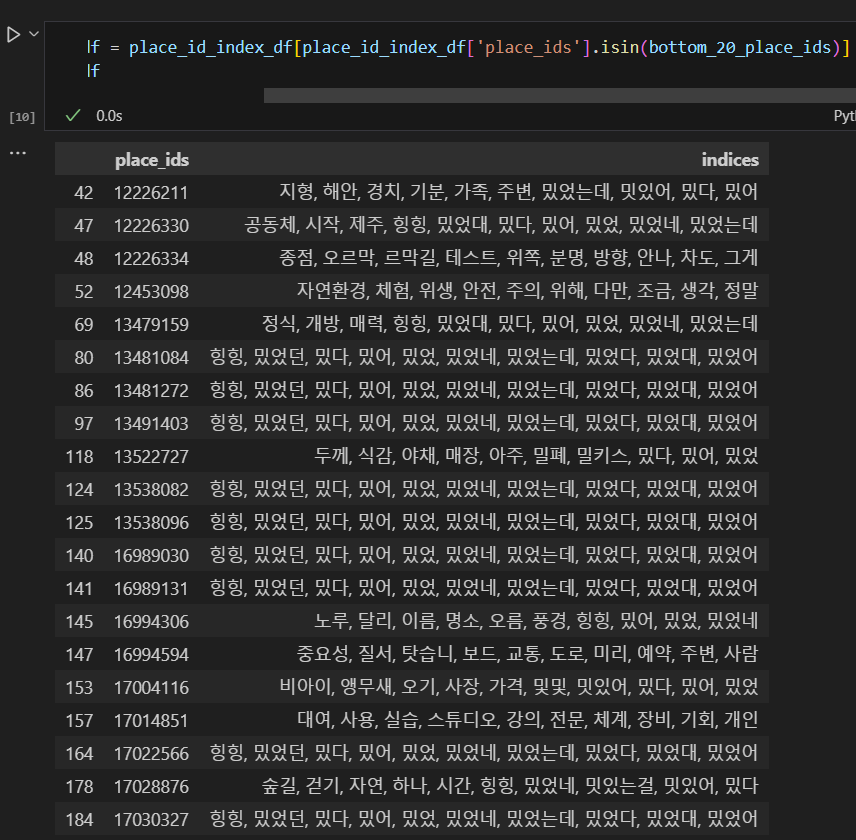
리뷰 수가 n개 이상인 경우 유의미하다고 판단한다 ... 뭐 그런 기준도 좋지만
리뷰가 1개여도 아주 퀄리티가 좋을 수도 있고.
많아도 핵심 단어가 10개 이상이 아닐 수도 있다.
그래서, 가중치가 n 이상인 경우에만 고려-로 하는 게 낫겠다고 생각했다.
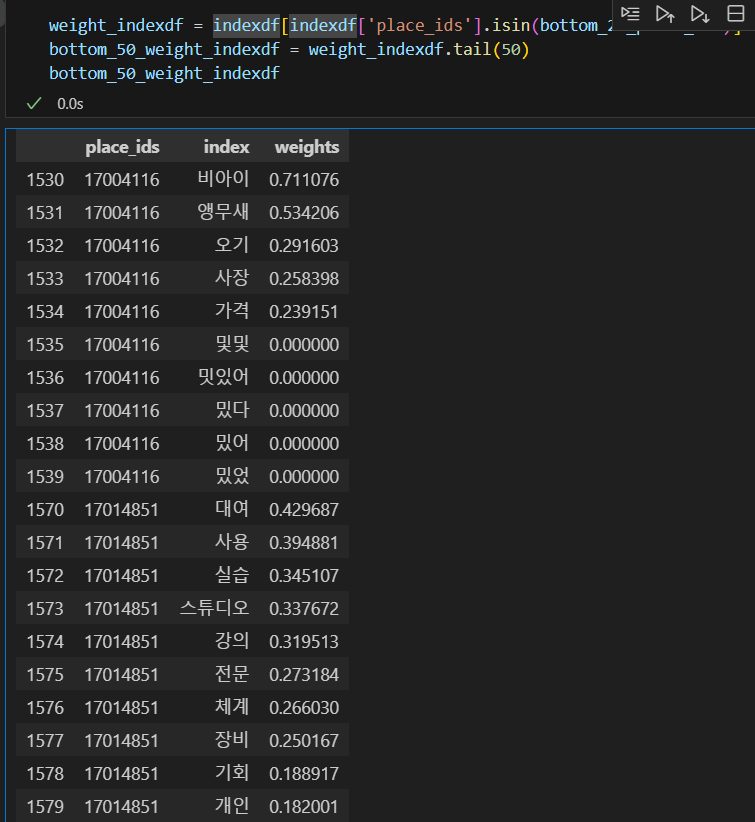
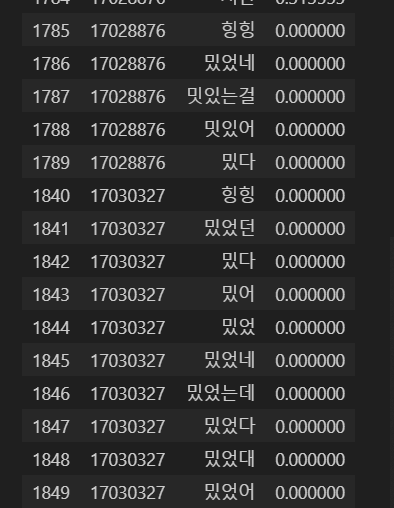
가중치가 0.1 이상인 것만 출력하도록 가중치 코드를 수정했다.
그런 후에 확인하니! 확실히 너무너무 나아진 결과를 보인다.
이건 완전히 끝났으니! 새로운 CSV 파일로 저장하고 마무리.
또, 내일 크롤링 돌리는 동안에는 낮/밤 컬럼을 생각해야겠다.
코드가 이미 있으니까 어렵지 않을 것 같다.
예전에는 컬럼 추가 아이디어 구상이 제일 먼저였는데, 일단 전체 구조를 다 짜 둔 다음에
디테일로 추가하는 게 더 나음이 ... 실감나는 요즘이다.
내일은 크롤링 된 비짓제주와 네이버를 머지시키고,
데이터 전처리 작업을 이어가야겠다.
엔지니어 분 오시면 자동 새 크롤링하기로 한 부분이
컬럼 명 바꿔서 머지된 후에도 괜찮을지도 다음 주에 여쭤봐야겠다.
(리뷰, 이미지 업로드는 영향 없는데 관광지가 업로드되는 경우)
🎈
2/16 금 ~ 2/19 월
ADsP 공부와 동시에 멘토님께 질문사항을 공유드리면서 모델팀끼리 회의도 진행해보았습니다.
사실 2/19에 중간발표를 진행하면서 제가 맡지 않은 부분에 대한 이해가 부족하다고 생각해
소통이 필요하다고 생각했던 참이었기에,
팀원분과 이야기를 나눠보며 서로 겪는 어려움을 공유해 정리해보았습니다.
1) 추천시스템 과 2) 챗봇 모델을 학습 중입니다. 가지고 있는 데이터는 전화번호, 위치, 분류와 같은 사실 데이터와 리뷰 데이터들입니다. 리뷰 데이터에서 파생 변수를 생성해서(성별, 나이, 실내/실외 여부, 계절 등) 모델링에 사용할 예정입니다.
넷플릭스와 같이, 처음 회원가입을 할 때 이미지 여러 개 중 사용자 취향에 맞는 n개(4개로 생각 중)를 선택하면, 해당 관광지의 중심 단어들(태그)을 모아올 것입니다. 취향 단어 리스트와 전체 관광지 태그들에 유사도 검사를 진행하여 추천 예측을 할 예정입니다.
다만, 그렇게 되면 리뷰 텍스트에서 가져온 중심 단어 데이터들만 추천에 고려하게 됩니다. 저희가 고려하고 싶으면서 유의미할 것으로 예측되는 피쳐(나이, 성별, 계절, 실내/실외 여부 등)를 같이 사용하고 싶은데, 데이터의 형태가 달라 같이 사용하는 방법이 궁금합니다. (함께 인코딩하기가 어렵습니다..)
또, 지금 visitjeju 사이트와 네이버 사이트, 그리고 AIHUB의 데이터를 함께 사용하려던 도중, 데이터 merge에 어려움을 겪고 있습니다. 명시적인 primary key가 없을 때 다른 소스 자료들을 사용하는 법을 알고 싶습니다.
넷플릭스 등 대기업 추천 모델에서는 협업필터링과 내용 기반 필터링을 같이 쓰는 하이브리드 모델을 이용하는 것으로 알고 있습니다. 사용자 로그에 대한 정보가 없기 때문에 협업필터링을 사용할 수 없다고 판단하나, 이런 상황에서도 사용이 가능한지와, 상용화 후 어떻게 할 수 있는지에 대한 아이디어를 들어보고 싶습니다.
또, 챗봇 모델에 대해 문의 말씀을 드립니다. LLM과 RAG 모델(LANGCHAIN)을 함께 사용하려고 하는데, RAG에 CSV 형태의 저희 데이터를 학습시키는 과정에서 어려움을 겪고 하드코딩을 통해 TXT 파일로 바꾸어 학습시켰습니다. 그런데 저희는 리뷰데이터와 관광지 데이터를 주기적으로 업데이트할 것이므로, 현재처럼 RAG에 TXT 파일을 학습하는 경우 번거로워 csv로 학습하는 법을 알면 좋을 것 같습니다.
--
정리하고보니 이제 어떤 작업이 필요한지가 보여 좋았습니다.
이에 대한 멘토님의 답변을 듣고 진전이 좀 났으면 좋겠습니다.
회고
🎍 잘했던 점
모델을 뜯어보고 공부하고, 직접 모델 구조를 구성한다는 것에 그래도 익숙해짐을 느꼈습니다.
앞으로도 대충 써보고 안돼서 머리 쥐어 뜯기보다는 리드미를 좀 읽어보는 습관을...
그리고 꽤 생산적인 일주일을 보냈습니다.
🎃
아쉬운 점
저번주부터 크롤링에 개입했는데, 로컬환경에서의 크롤링, out of memory를 중간에 신경쓰면서 하는 게 번거롭고 크롤링하는 동안에는 다른 작업에 완전 집중이 될 수 없어 아쉬웠습니다.
일단 기본 데이터는 다 보유하고 있기 때문에, 이 정도로 돌아갈 수 있도록 코드를 짜 두고
복학 후에 데이터를 추가함과 동시에 피쳐도 추가하며 코드를 수정하는 방향으로,
구동할 수 있는 모델을 서빙하는 걸 목적으로 해야겠습니다.
🎀 개선 방안
막막함에 포기하지 않기
할 수 있는 만큼만 계획하고 실행하기
내일 해야 할 일 적어놓고 귀가하기
내가 지금 어느 수준에 있는지 파악하기
검색을 두려워하지 않기
우선순위를 고려하기
🎡 다음 주(2/21~2/27)
- OCR 모델 서빙 실험
- 챗봇 모델 저장, 실험
- 피쳐 추가 생성 (연령, 나이, 실내/실외, 계절)
- ERD 제대로 그리기
(날짜, 날씨 고려)
