글자 단위 RNN 언어 모델(Char RNNLM)
- 단어 단위가 아니라 글자 단위를 입, 출력으로 사용하므로 임베딩층(embedding layer)을 사용하지 않음
- 영어가 훈련 데이터일 때 대부분의 경우에서 글자 집합의 크기가 단어 집합을 사용했을 경우보다 집합의 크기가 현저히 작다는 특징 가짐
- 영어 단어를 표현하기 위해서 글자 집합에 포함되는 글자는 26개의 알파벳뿐이기 때문
- 훈련 데이터의 알파벳이 대, 소문자가 구분된 상태라고 하더라도 모든 영어 단어는 총 52개의 알파벳으로 표현 가능
--> 방대한 양의 텍스트라도 집합의 크기를 적게 가져갈 수 있다는 것은 구현과 테스트를 굉장히 쉽게 할 수 있다는 이점
->RNN의 동작 메커니즘 이해를 위한 토이 프로젝트로 굉장히 많이 사용됨
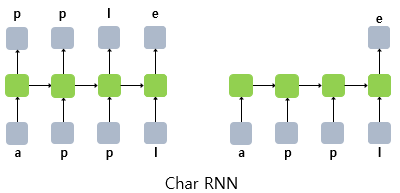
훈련 데이터에 apple이라는 시퀀스가 있고, 입력 시퀀스의 길이. 즉, 샘플의 길이를 4라고 한다면 입력 시퀀스와 예측해야 하는 출력 시퀀스는 다음과 같이 구성
appl은 train_X(입력 시퀀스),pple는 train_y(예측해야하는 시퀀스)에 저장
- 테스트 과정은 예측 글자를 다음 입력 시퀀스에 추가하는 형태.
-참고자료에서는 긴 시퀀스의 입력을 처리하기 위해 LSTM을 사용하였음
딥러닝을 이용한 자연어 처리 입문
https://wikidocs.net/48649
