- 트랜스포머
2017년 구글이 발표한 논문인 "Attention is all you need"에서 나온 모델
seq2seq의 구조인 인코더-디코더를 따르면서도, 논문의 이름처럼 어텐션(Attention)만으로 구현한 모델
RNN을 사용하지 않고 인코더-디코더 구조를 설계하였음에도 성능이 RNN보다 우수
1. 기존 seq2seq 모델의 한계
- 복습: seq2seq
- 인코더-디코더 구조
- 인코더: 입력 시퀀스를 하나의 벡터 표현으로 압축
- 디코더: 벡터 표현을 통해서 출력 시퀀스를 만들어 냄
- but 인코더가 하나 벡터 표현으로 압축하는 과정에서 입력 시퀀스의 입력 손실된다는 단점
-> 보정 위해 어텐션 사용함
--> 어텐션으로 아예 인코더와 디코더를 만들어 보자!
2. 트랜스포머의 주요 하이퍼파라미터
- : 트랜스포머의 인코더와 디코더에서의 정해진 입력과 출력의 크기, 임베딩 벡터의 차원, 각 인코더와 디코더가 다음 층의 인코더와 디코더로 값을 보낼 때에도 이 차원을 유지함. +피드 포워드 신경망의 입력층과 출력층 크기
- _ : 인코더와 디코더가 총 몇 층으로 구성되었는지를 의미(하나의 인코더와 디코더를 층으로 생각)
- _ : 분할되어 병렬로 수행되는 어텐션의 개수
- : 트램스포머 내부 피드 포워드 신경망의 은닉층 크기
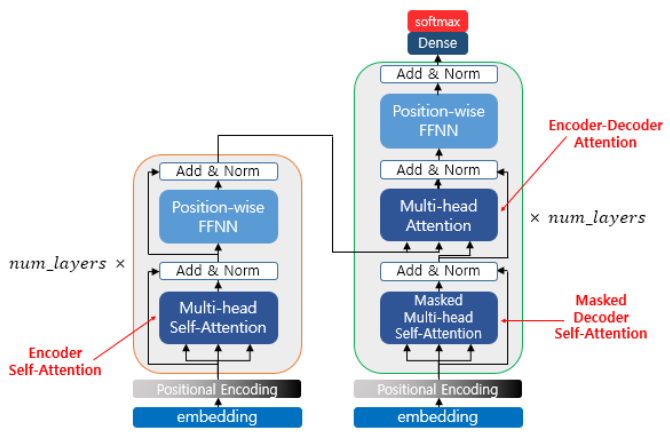
3. 트랜스포머
RNN을 사용하지 않지만 기존의 seq2seq처럼 인코더에서 입력 시퀀스를 입력받고, 디코더에서 출력 시퀀스를 출력하는 인코더-디코더 구조를 유지
다른 점은 인코더와 디코더라는 단위가 N개가 존재할 수 있다는 점
-
인코더와 디코더가 6개 존재하는 트랜스포머의 구조(논문)
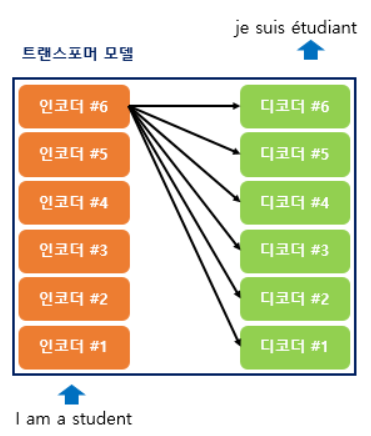
-
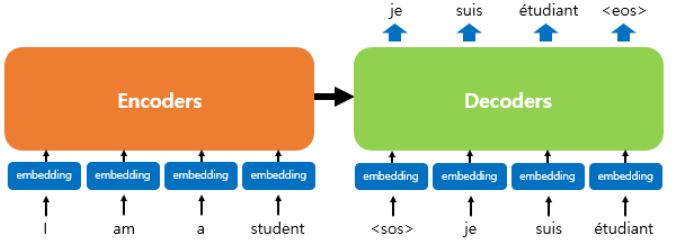
인코더로부터 정보 전달받아 디코더가 출력 결과를 만들어내는 트랜스포머의 구조
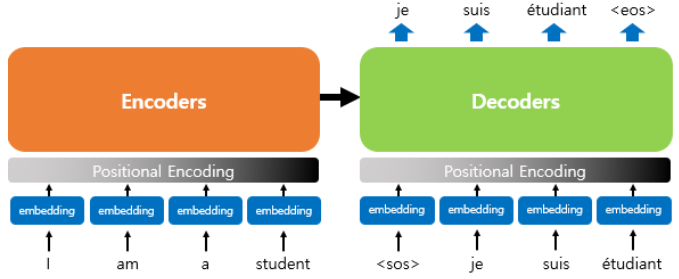
4. 포지셔널 인코딩
트랜스포머의 입력
- 단어의 위치 정보를 얻기 위해서 각 단어의 임베딩 벡터에 위치 정보들을 더하여 모델의 입력으로 사용
- RNN처럼 단어 입력을 순차적으로 받는 방식이 아니므로 단어의 위치 정보를 다른 방식으로 알려줄 필요가 있기 때문
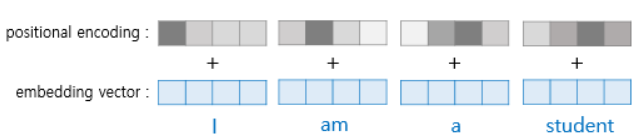
- 위치 정보 가진 값을 만들기 위해 사인, 코사인 함수 사용
는 입력문장에서 임베딩 벡터의 위치, 는 임베딩 벡터 내 차원의 인덱스
- 사실 임베딩 벡터와 포지셔널 인코딩의 덧셈은 임베딩 벡터가 모여 만들어진 문장 벡터 행렬과 포지셔널 인코딩 행렬의 덧셈 연산을 통해 이루어짐
5. 어텐션
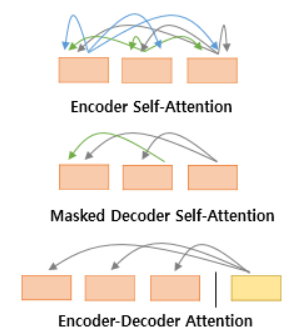
트랜스포머에 사용되는 세 가지 어텐션(=는 벡터의 출처가 같다는 의미)
1. Encoder Self-Attention : 인코더 Query = Key = Value
2. Masked Decoder Self-Attention : 디코더 Query = Key = Value
3. Encoder-Decoder Attention : 디코더 Query : 디코더 벡터 / Key = Value : 인코더 벡터
- 트랜스포머의 아키텍처
6. 인코더
- 트랜스포머는 하이퍼파라미터인 _개수의 인코더 층
- 하나의 인코더 층은 총 2개의 서브층: 셀프 어텐션 + 피드포워드 신경망
- Multi-head는 셀프 어텐션을 병렬적으로 사용하였다는 의미, Position-wise는 일반적인 피드포워드 신경망
7. 인코더의 셀프 어텐션
7.1 셀프 어텐션의 의미와 장점
- 복습: 어텐션 함수
1. 주어진 '쿼리(Query)'에 대해서 모든 '키(Key)'와의 유사도를 각각 구함
2. 가중치로 하여 키와 맵핑되어있는 각각의 '값(Value)'에 반영
3. 유사도가 반영된 '값(Value)'을 모두 가중합하여 리턴
-
셀프 어텐션에서의 Q, K, V
Q : 입력 문장의 모든 단어 벡터들
K : 입력 문장의 모든 단어 벡터들
V : 입력 문장의 모든 단어 벡터들 -
셀프 어텐션의 효과
* 입력 문장 내의 단어들끼리의 유사도를 구함
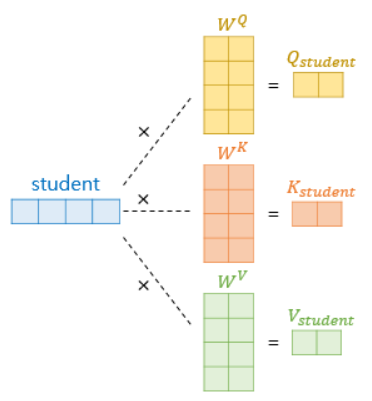
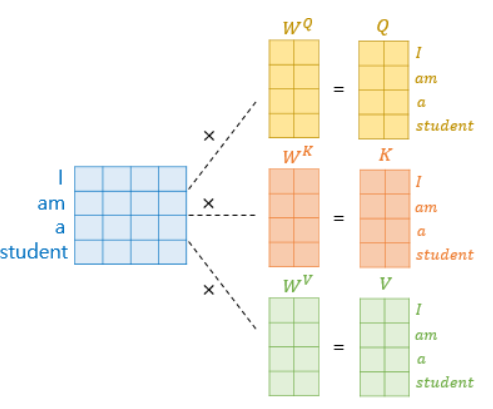
7.2 Q, K, V 벡터 얻기
- 셀프 어텐션은 입력 문장의 단어 벡터들을 가지고 수행한다고 하였는데, 코더의 초기 입력인 의 차원을 가지는 단어 벡터들을 사용하여 셀프 어텐션을 수행하는 것이 아니라 우선 각 단어 벡터들로부터 Q벡터, K벡터, V벡터를 얻는 작업을 함
- 트랜스포머는 을 _로 나눈 값을 각 Q벡터, K벡터, V벡터의 차원으로 결정
- 가중치 행렬 크기 : X(/_)
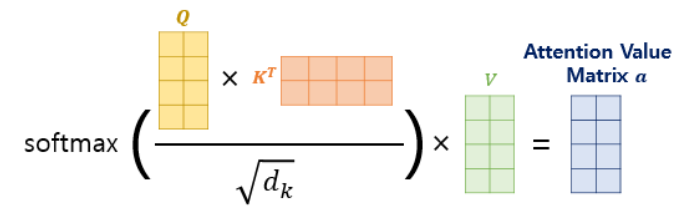
7.3 스케일드 닷-프로덕트 어텐션(Scaled dot-product Attention)
- 특정값으로 나눠준 어텐션 함수 사용 :
- 즉, 어텐션 챕터의 닷-프로덕트 어텐션에서 값을 스케일링하는 것을 추가한 것.
7.4 행렬 연산으로 일괄 처리하기
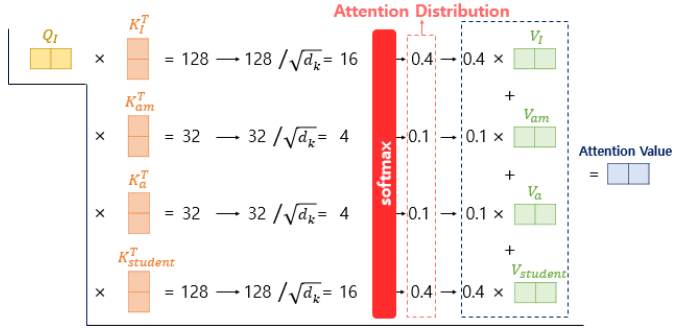
- 각 Q 벡터마다 일일히 연산하지 않고, 행렬 연산 이용(실제로 행렬 연산으로 구현됨)
- 문장 행렬에 가중치 행렬을 곱하여 Q 행렬, K 행렬, V행렬 구함(각 단어 벡터마다 X)
- 어텐션 스코어 : Q 행렬을 K 행렬을 전치한 행렬과 곱하면 Q벡터와 K벡터의 내적이 각 행렬의 원소가 되는 행렬이 나옴.
- 이 값에 전체적으로 로 나눠주면 각 행과 열이 어텐션 스코어 값을 가지는 행렬 됨.
- 어텐션 스코어 행렬에 소프트맥스 함수를 사용하고, V 행렬을 곱해 각 단어의 어텐션 값을 모두 가지는 어텐션 값 행렬 구함
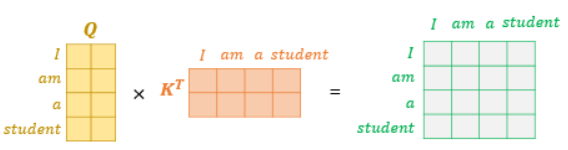
7.5 스케일드 닷-프로덕트 어텐션 구현하기
건너뜀
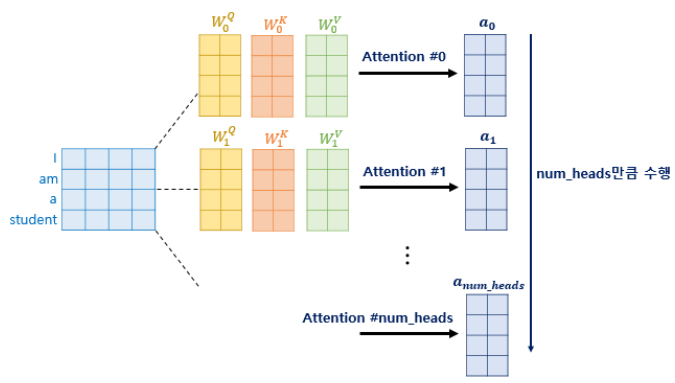
7.6 멀티 헤드 어텐션(Multi-head Attention)
- 한번의 어텐션보다 여러번의 어텐션을 병렬로 사용하는 것이 다른 시각으로 정보들을 수집할 수 있게 함.
- 의 차원을 개로 나눠 $d{model}$ / _ 차원을 가지는 Q, K, V에 대해서 _개의 병렬 어텐션 수행
- 가중치 행렬 는 각 어텐션 헤드마다 전부 다름
- 어텐션 헤드 연결(concatenate) : 행렬 크기 (, $d{model}$)
- 어텐션 헤드를 모두 연결한 행렬은 또 다른 가중치 행렬 을 곱함
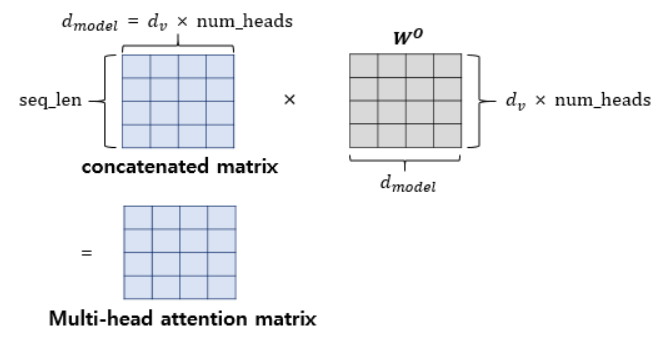
- 의 차원을 개로 나눠 $d{model}$ / _ 차원을 가지는 Q, K, V에 대해서 _개의 병렬 어텐션 수행
*첫번째 서브층인 멀티-헤드 어텐션과 두번째 서브층인 포지션 와이즈 피드 포워드 신경망을 지나면서 인코더의 입력으로 들어올 때의 행렬의 크기는 계속 유지
- 인코더에서의 입력의 크기가 출력에서도 동일 크기로 계속 유지되어야만 다음 인코더에서도 다시 입력이 될 수 있기 때문
7.7 멀티 헤드 어텐션(Multi-head Attention) 구현하기
- 다섯 가지 파트
- WQ, WK, WV에 해당하는 d_model 크기의 밀집층(Dense layer)을 지나게한다.
- 지정된 헤드 수(num_heads)만큼 나눈다(split).
- 스케일드 닷 프로덕트 어텐션.
- 나눠졌던 헤드들을 연결(concatenatetion)한다.
- WO에 해당하는 밀집층을 지나게 한다.
7.8 패딩 마스크(Padding Mask)
-
함수 내부에 아래와 같은 연산 존재
logits += (mask * -1e9) # 어텐션 스코어 행렬인 logits에 mask*-1e9 값을 더해주고 있다. -
입력 문장에 PAD 토큰이 있을 경우 어텐션에서 사실상 제외하기 위한 연산
- PAD 토큰이 있는 경우
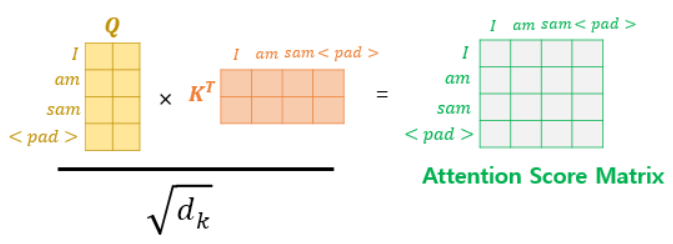
- PAD 토큰이 있는 경우
-
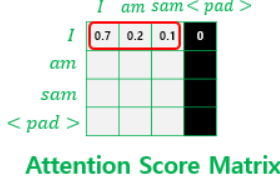
이 토큰은 실질적 의미를 가진 단어가 아니기 때문에 유사도를 구하지 않도록 마스킹(값을 가린다는 의미)하는 것
-
마스킹 위치에 매우 작은 음수 값이 들어가 있으므로 어텐션 스코어 행렬이 소프트맥스 함수를 지난 후에는 해당 위치의 값은 0에 굉장히 가까운 값이 됨
-
따라서 단어 간 유사도를 구하는 일에 PAD 토큰이 반영되지 않게 됨
8. 포지션-와이즈 피드 포워드 신경망
인코더, 디코더 공통적으로 가지고 있는 서브층
= 완전 연결 FFNN(Fully-connected FFNN)
- 수식:
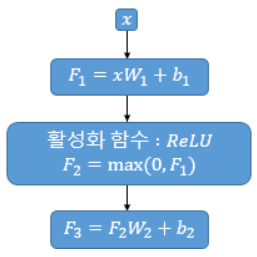
: (, $d{model}$) 크기(멀티헤드 어텐션의 결과)를 가지는 행렬
: ( , ) 크기
: (, ) 크기
- 매개변수 , , , : 하나의 인코더 층 내에서는 다른 문장, 다른 단어들마다 정확하게 동일하게 사용 but 인코더 층마다는 다른 값을 가짐
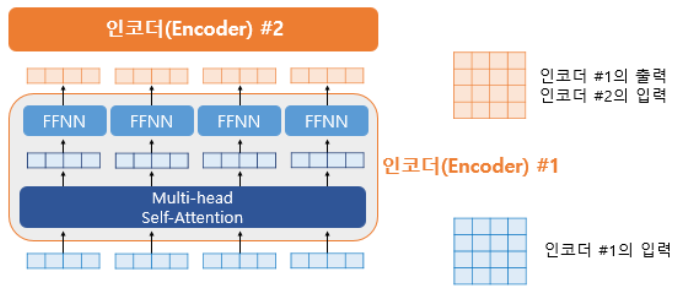
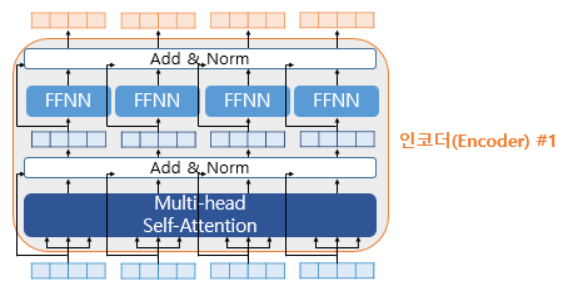
9. 잔차 연결(Residual connection)과 층 정규화(Layer Normalization) (=Add&Norm)
- 피드포워드 설명그림에서 화살표와 Add&Norm 추가한 그림
추가된 화살표들은 서브층 이전의 입력에서 시작되어 서브층의 출력부분을 향하고 있는 것에 주목
9.1 잔차 연결
- =
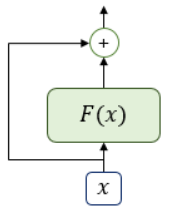
- 가 트랜스포머에서 서브층에 해당
- 잔차 연결 = 서브층의 입력 + 서브층의 출력 (입력과 출력 동일 차원이므로 연산 가능)
- 서브층이 멀티 헤드 어텐션인 경우 연산:
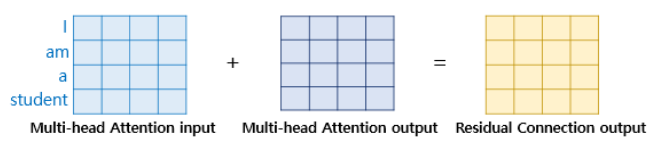
- 잔차 연결은 하위 층의 출력 텐서를 상위 층의 출력 텐서에 더해서 아래층의 표현이 네트워크 위쪽으로 흘러갈 수 있도록 한다. 즉, 하위 층에서 학습된 정보가 데이터 처리 과정에서 손실되는 것을 방지
9.2 층 정규화
잔차 연결 거친 결과가 이어서 층 정규화 과정을 거침
- 텐서의 마지막 차원(=의 차원)에 대해서 평균과 분산을 구하고, 이를 가지고 어떤 수식을 통해 값을 정규화하는 것
- 화살표: 차원의 방향
- 화살표 방향의 벡터
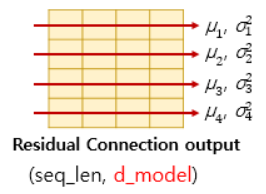
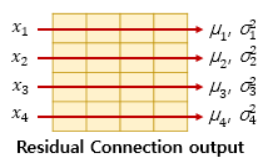
-
층 정규화 과정
1. 평균과 분산을 통한 정규화
2. 감마(초기값 1)와 베타(초기값 0) 도입 -
층 정규화 수행 후 :
-
정규화의 최종 수식 :
-
기울기 소실과 폭주를 완화
딥러닝을 이용한 자연어 처리 입문
https://wikidocs.net/31379
