k-Nearest Neighbors
Classification과 k-NN
분류 문제에서 k-NN 기본 아이디어는 unknown data의 k개의 최근접 이웃들을 찾은 후, 가장 많은 클래스로 분류하는 것이다.
1. k = 1
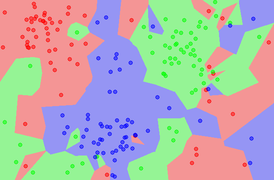 경계가 복잡하다. overfitting 이 발생할 확률이 높다.
경계가 복잡하다. overfitting 이 발생할 확률이 높다.
2. k = 5
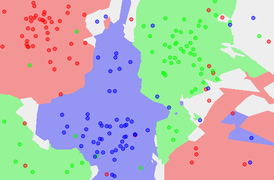 k가 커지면서 경계가 단순화된다. stable 하지만 정확도는 떨어질 수 있다. 따라서 최적의 k를 찾는 것이 중요하다.
k가 커지면서 경계가 단순화된다. stable 하지만 정확도는 떨어질 수 있다. 따라서 최적의 k를 찾는 것이 중요하다.
Regression 과 k-NN
regression은 레이블을 찾아내는 classification과 달리 실제 값 (real number)를 함수를 통해 찾아내야 한다.
X축에서 k개의 근접 이웃을 찾고, y값들의 평균으로 찾는다.
단순한 카운팅/평균의 문제점 극복
단순히 카운팅을 하거나 평균을 이용하게 되면 데이터의 수에 따른 편향이 일어날 수 있다
해결 방법: 거리에 따른 가중치를 추가한다.
Distance Measure
distance(거리)는 선형적으로 스케일되어 있기 때문에 스케일에 민감하다. 따라서 distance에서 k NN 을 사용하기 전에는 variance를 고려해 주어야 한다.
요약하자면. . .
-
Small K : higher variance, less stable -
데이터 값들이 다양하게 분포되어 있으며(예측값들의 편차가 작다) 안정적이지 않다. overfitting의 가능성 -
Large K : higher bias, less precise - 데이터 값들이 정답에서 떨어져 있다. underfitting의 가능성
장점
- 훈련 과정이 필요없다.
- 단순한 추론 과정
- 함수의 복잡도가 상관없다
- 가까운 값들만 찾아내면 되기 때문에
- 정보의 손실이 없다.
단점
- 모든 데이터를 보관해야 하므로, 메모리 사용량이 많다.
- k값이 작은 경우, 노이즈에 민감하다.
- 훈련 데이터 양의 균형이 맞지 않을 경우, major class 쪽으로 편향된다.
- 모든 훈련 데이터들로부터의 거리를 계산해야 하므로 많은 시간 소모
- 높은 차원에서의 거리 계산은 많은 비용을 소모한다.
연산 비용을 줄이는 방법은?
- approximaty 사용
어림으로 가까운 K개의 이웃을 찾는다. - Dimensions 줄이기
- 데이터의 크기 줄이기
- 샘플링, clustering 등 사용

https://github.com/youznn