AI Agent는 어떻게 작동할까? 그리고 어떻게 구현할 수 있을까?
최근에 학교에 다니면서 인공지능과 컴퓨터 동아리에 풀스택 개발자로 합류하게 되었다. 데모데이가 2주 남은 시점 열린 회의에서 PM이 갑자기 우리 앱에 AI Agent 기능을 추가하자는 의견을 전달해주었다. (아무리 에자일리쉬하게 한다지만 이러한 메이저한 기능은 미리 기획하고 알려주면 좋을텐데 말이다) 아무튼 나 역시 개발할 때 Cursor를 사용하는 사람으로써 늘 이 부분에 대한 궁금증을 갖고 있었다.
How AI IDE Works?
Ai Agent를 어떻게 구현할지 전혀 갈피가 안 잡히는 상황에서 매우 좋은 블로그 글(링크)을 찾아서 볼 수 있었다. Cursor의 구현 과정부터 어떻게 하면 더 효과적으로 잘 사용할 수 있을지 적어둔 매우 좋은 글이었다. Cursor에 막 입문한 사람이 아니더라도 한번쯤은 읽어보면 좋은 글이다.
아무튼 간단하게 요약을 하자면 Cursor와 같은 AI IDE는 다음과 같은 과정을 복잡하게 래핑하여 구현되었다.
1. Fork VSCode
2. Add a chat UI and pick a good LLM
3. Implement tools for the coding agent (read_file, write_file, run_command...)
4. Optimize the internal prompts
그리고 가끔 방대한 코드 속에서 특정 기능을 구현했던 코드 파일을 찾아달라고 할 때 파일을 정확하게 찾아주는데, 이것은 역시 내 예상대로 모든 파일을 요청마다 LLM이 읽는 방식이 아니라, IDE가 전체 코드베이스를 벡터로 인덱싱하기 때문에 에이전트가 항상 정확한 파일을 찾을 수 있는 것이었다. 물론 이렇게 임베딩을 할 때 어느 정도 수준까지 쪼개서 하는지는 모르겠다(예를 들면 파일, 함수, 클래스... 등 다양한 단위).
AI Agent의 UI/UX 뜯어보기
개발자이지만 평소에 무엇이 좋은 UI/UX일까 고민을 많이 한고, 좋은 UI/UX 사례나 닐슨노만그룹의 아티클을 읽어보곤한다. 시중에 배포된 다양한 LLM을 이용한 채팅이나 에이전트 서비스들을 사용해보면 몇 가지 UI/UX 공통점이 존재한다. 나는 크게 2가지 공통점이 있다고 느꼈다. (부족한 학생이고 따로 UI/UX를 전공한 것은 아니라 전부 발견하지 못하거나 깊게 이해하지는 못할 수 있다.) 아래 두가지 예시를 준비했다.
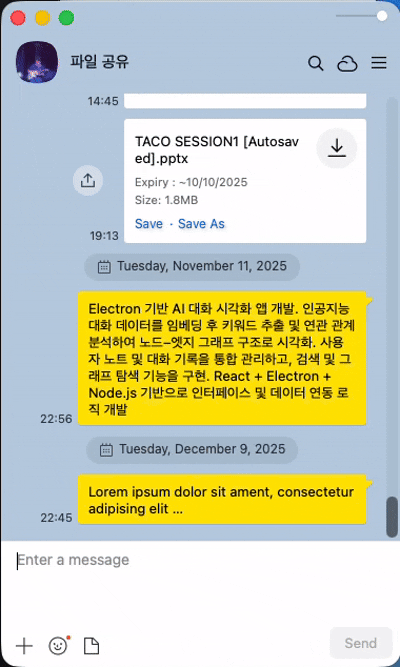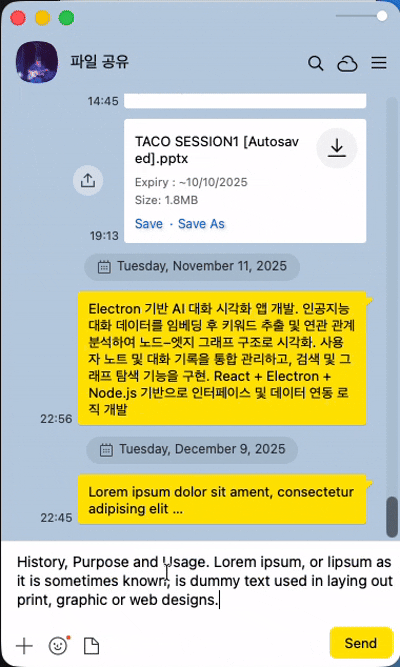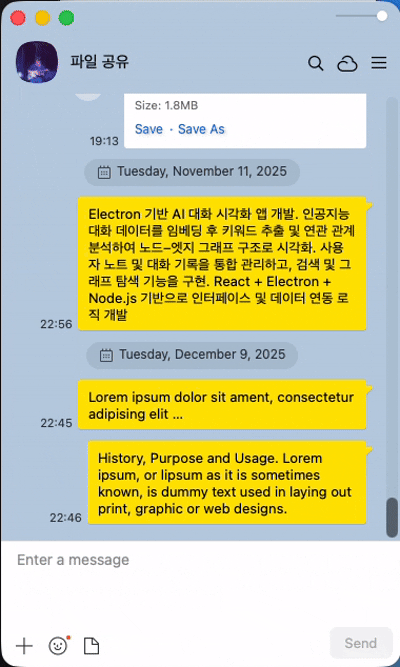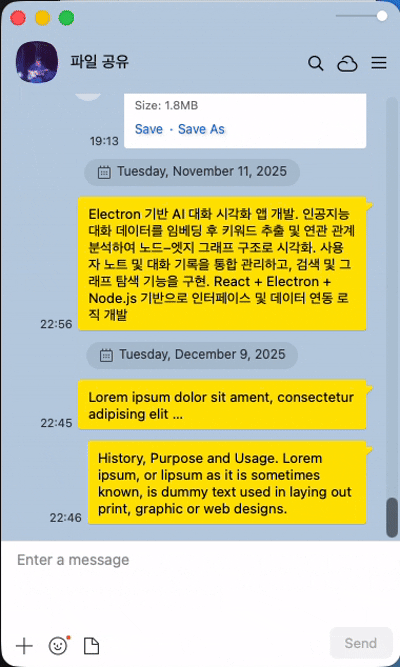
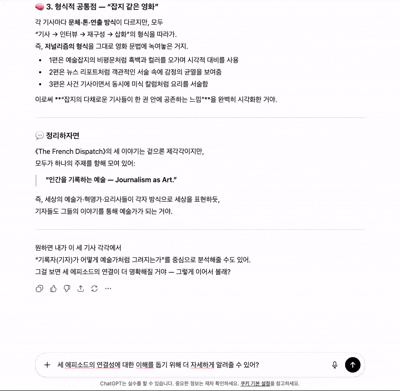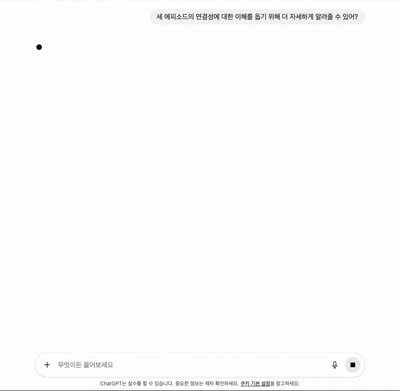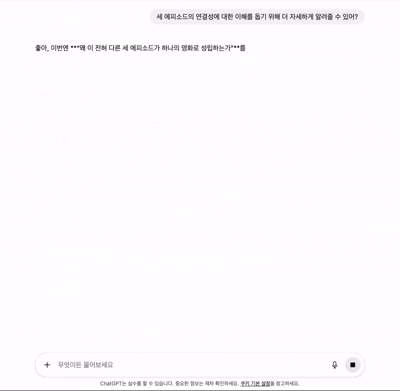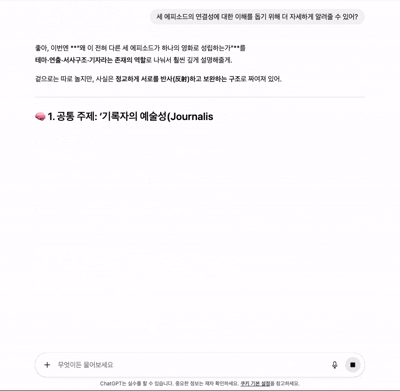
기존 소셜 미디어의 채팅과의 차이점(1) - 새롭게 생성된 메시지의 위치
일반적인 소셜 미디어의 경우 한명 이상의 유저가 응답을 빠르게 주고 받는 경우가 많아서 새로운 채팅은 화면의 아래에 보이고, 기존 채팅은 그만큼 위로 밀리는 형식이다. 그렇지만 LLM과의 채팅에서는 주로 유저의 질문과 LLM의 답변이 한쌍의 흐름을 이루는 요청과 응답의 패턴이며, 일반적인 유저 사이의 채팅과 다르게 LLM의 답변까지 어느 정도의 시간이 소모된다. 질문과 답변 혹은 요청과 응답이라는 패턴을 이룬다는 점에서 유저가 보낸 텍스트는 스크린 최상단에 위치를 하며, 그 아래 LLM의 답변(응답)이 보여지는 형식이다.
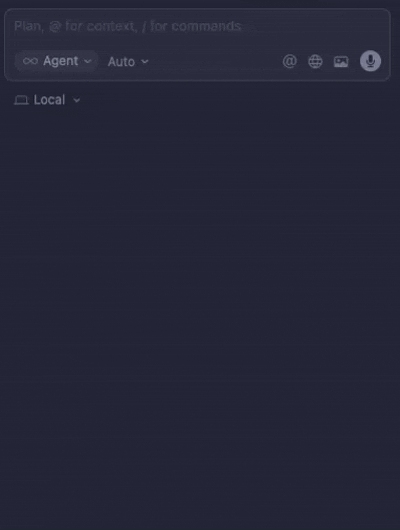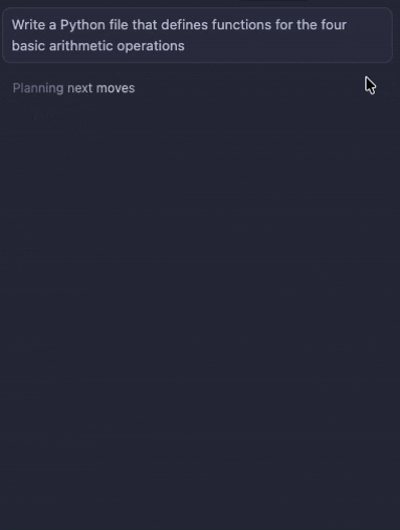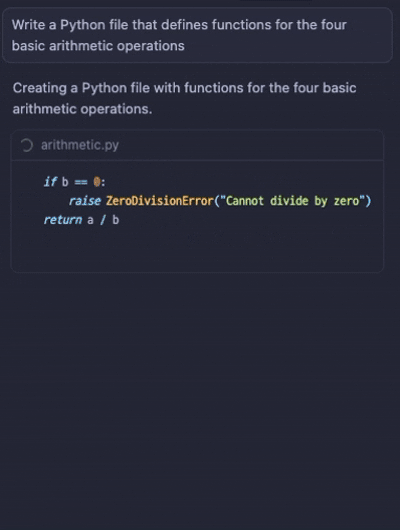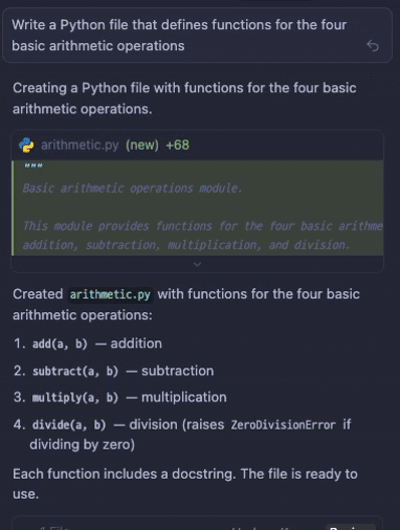
기존 소셜 미디어의 채팅과의 차이점(2) - 데이터 형식과 프로세스 공유
위의 Cursor에서 Agent가 사용자의 명령을 받고, 이해하며, 그 명령에 맞는 결과를 출력하기까지 일반적인 소셜 미디어의 채팅과 달리 응답 완료까지 적지 않은 소요시간이 걸린다. 그리고 사용자는 이 대기 시간에 지루함을 느낀다. 따라서 이러한 대기 시간을 달래기 위해 로딩스피너, 스켈레톤, 프로그레스바 등 다양한 UX 해결책이 제시된 가운데 유명한 LLM 서비스들은 다음과 같은 두가지 방식을 통해 유저의 지루함을 해소하였다. 현재 내가 보낸 응답이 처리되는 과정(상태)를 알려주는 것과 응답 결과를 한번에 보여주는 것이 아닌 스트리밍 데이터를 사용해서 데이터를 빠르게 실시간으로 보내주는 방법이다.
AI Agent 실제로 구현하기
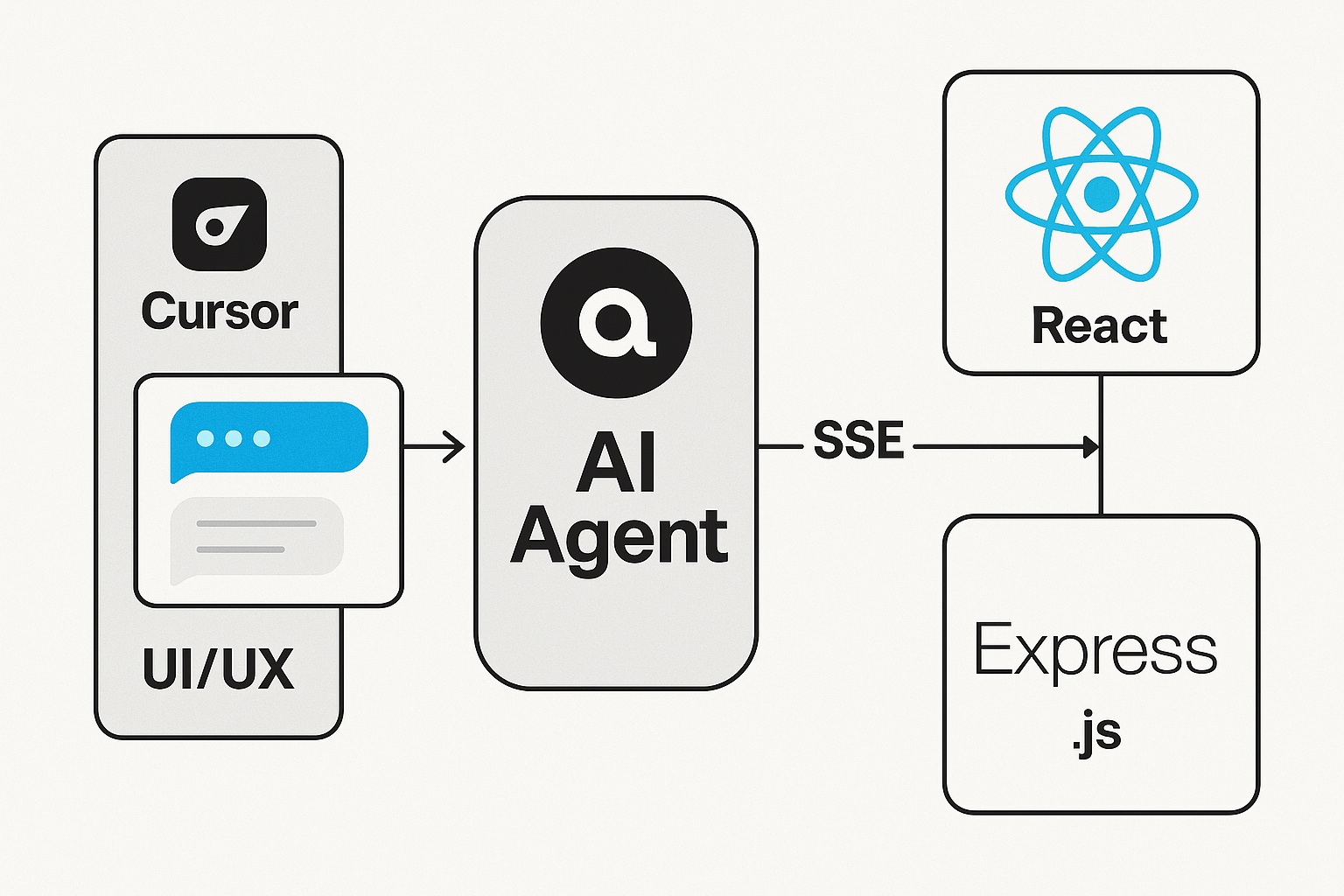
우리 서비스는 Desktop App이고 개발 환경에 대해 간단하게 설명하면 다음과 같다.
LLM Provider: OpenAI, DeepSeek
FE: React 19, Electron 38, TypeScript
BE: Express.js 5.1, MongoDB 6.20
BE: SSE 구현 및 LLM 모델 연결
우선 SSE를 사용하기 위해 헬퍼 함수 하나를 만들었다. 백엔드쪽에서 SSE를 Agent만이 아니라 다른 곳에서 확장될 가능성을 고려하였다. 헤더부분의 설정은 클라이언트와 연결을 유지하고, event-stream 데이터를 보내기 위해 꼭 필요한 설정이다.
또한 Named Event설정을 통해 이벤트 종류별로 프론트에서 구분해서 콜백함수로 처리할 수 있다. 여기서 'result'와 같은 이벤트는 SSE에서 정해진 이벤트가 아니고, 백엔드와 프론트가 약속한 커스텀 이벤트 이름을 맞춰서 사용한다.
function setupSSE(res: express.Response) {
res.setHeader('Content-Type', 'text/event-stream; charset=utf-8');
res.setHeader('Cache-Control', 'no-cache, no-transform');
res.setHeader('Connection', 'keep-alive');
res.flushHeaders?.();
const sendEvent = (event: string, data: unknown) => {
res.write(`event: ${event}\n`);
res.write(`data: ${JSON.stringify(data)}\n\n`);
};
// SSE - Named Event
// sendEvent('result', {
// mode: 'summary' as Mode, 이 부분으로 프론트에서 구현한 도구들과 연결
// answer: context,
// noteContent: null,
// });
return { sendEvent };
}OpenAI SDK를 사용할 경우 OpenAI LLM 모델의 응답 결과 또한 Stream 형태로 받을 수 있다. for await...of에 관한 것은 이 문서를 확인하면 된다. SSE라는 것이 실시간으로 데이터를 보내주는 것이기 때문에 잠깐이라도 프론트에서 네트워크에 장애가 생긴다면 문제가 생길 수 있다. 따라서 최종 응답 결과를 보내주는 것을 통해 데이터의 정확성을 보장하고, 프론트에 응답이 완료 상태를 제공한다. 또한 프론트에서 LLM 응답을 통해 수행할 업무(파일을 수정할지, 단순 채팅인지)를 구분한다.
const messages: OpenAI.Chat.Completions.ChatCompletionMessageParam[] = [
{ role: 'system', content: systemPrompt },
{
role: 'user',
content: hasContext ? `[Context]\n${context}\n\n[User]\n${trimmedUser}` : trimmedUser,
},
];
const stream = await openai.chat.completions.create({
model: 'gpt-4.1-mini',
stream: true,
messages,
});
let fullAnswer = '';
// Stream에서 새로운 청크를 수신할 때마다 반복문 호출
for await (const chunk of stream) {
const delta = chunk.choices[0]?.delta?.content ?? '';
if (!delta) continue;
fullAnswer += delta;
sendEvent('chunk', { text: delta });
}
// 최종적으로 전체 응답 전달
sendEvent('result', {
mode: 'chat' as Mode, // 프론트 도구들과 연결
answer: fullAnswer,
noteContent: null,
});
// Stream 종료
return res.end();mode부분에 대해서는 고민이 많았다. LLM이 구현된 도구 중에 어떤 것을 사용할지 판단하는 것 또한 토큰이 소비되기 때문이다. 따라서 이 역시 기존 LLM 서비스에서 참고해서 가져왔다. 아래 사진과 같이 유저에게 가이드 텍스트 버튼을 던져준다.
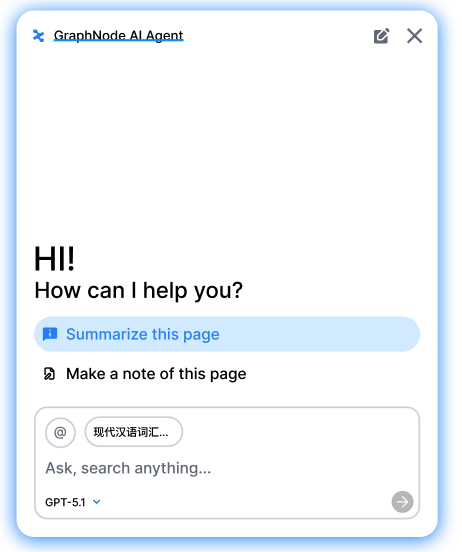
type ModeHint = 'summary' | 'note' | 'auto';
const { userMessage, contextText, modeHint } = req.body as {
userMessage: string;
contextText?: string;
modeHint?: ModeHint;
};해당 버튼을 사용할 경우 modeHind부분에 'auto'가 아닌 값을 부여하는 것을 통해서, 조건으로 이 경우에는 LLM이 굳이 어떤 도구를 사용할지 판단 과정을 생략하고 유저가 보낸 modeHint의 값을 그대로 최종 응답의 mode에 반영하는 식으로 구현하였다. 다만 텍스트 버튼을 클릭하지 않고, 직접 텍스트를 입력했을 때는 여전히 LLM이 어떤 도구를 사용할지 판단을 해야한다.
https://itsfuad.medium.com/understanding-server-sent-events-sse-with-node-js-3e881c533081 (Understanding Server-Sent Events (SSE) with Node.js 참고)
FE: Stream 응답 받고, Named Events 대응하기
아래는 백엔드 AI Agent를 담당하는 엔드포인트를 호출하는 프론트쪽 함수이다. buffer와 for문쪽을 보면 하드하게 포맷팅하여 문자열을 추출하는데, SSE 응답자체가 단일 텍스트 스트림이다. 따라서 버퍼에서 라인 단위 파싱을 통해 이벤트와 데이터 추출 과정이 필요하다. 더 자세한 것은 SSE 공식문서를 보면 알 수 있는데 아무튼 SSE 메시지는 표준 포맷이 고정되어있어서 가능하다.
export async function agentChatStream({
userMessage,
contextText,
callbacks,
}: AgentChatStreamParams): Promise<void> {
const res = await fetch(`${API_BASE}/v1/agent/chat/stream`, {
method: "POST",
headers: { "Content-Type": "application/json" },
body: JSON.stringify({
userMessage,
contextText: contextText ?? "",
}),
});
if (!res.ok) {
// 에러처리(1)
}
const reader = res.body?.getReader();
if (!reader) {
// 에러처리(2)
}
const decoder = new TextDecoder();
let buffer = "";
try {
while (true) {
const { done, value } = await reader.read();
if (done) break;
buffer += decoder.decode(value, { stream: true });
const lines = buffer.split("\n");
buffer = lines.pop() || "";
let eventType: StreamEventType | null = null;
let eventData: string | null = null;
for (const line of lines) {
if (line.startsWith("event: ")) {
eventType = line.slice(7).trim() as StreamEventType;
} else if (line.startsWith("data: ")) {
eventData = line.slice(6).trim();
} else if (line === "" && eventType && eventData) {
try {
const data = JSON.parse(eventData);
switch (eventType) {
case "status":
callbacks.onStatus?.(data as StreamStatusEvent);
break;
case "chunk":
callbacks.onChunk?.(data as StreamChunkEvent);
break;
case "result": {
const result = data as StreamResultEvent;
callbacks.onResult?.(result);
break;
}
case "error":
callbacks.onError?.(data as StreamErrorEvent);
throw new Error((data as StreamErrorEvent).message);
}
} catch (e) {
console.error("Failed to parse SSE event:", e, {
eventType,
eventData,
});
}
eventType = null;
eventData = null;
}
}
}
} finally {
reader.releaseLock();
}
}실제 해당 함수를 호출하는 곳에서는 아래와 같이 콜백 함수를 등록하여 사용할 수 있다.
await agentChatStream({
userMessage: instruction,
contextText: combinedContent,
callbacks: {
onStatus: (event) {},
onResult: (event) {
// if (event.mode === "note")의 경우 LLM이 전달해 준 컨텍스트로 내부 DB에 작업
const newNote = await noteRepo.create(cleanedContent);
queryClient.invalidateQueries({ queryKey: ["notes"] });
}
FE: AI Agent의 새로운 채팅을 화면 가장 위로 가져오는 UI 구현하기
사용자가 새 메시지를 전송하면 해당 메시지를 뷰포트 최상단 기준점으로 고정하고, 응답은 그 아래에 누적 렌더링한다. 이때 응답이 아직 짧아 화면 하단에 여백이 남는 경우, 남는 높이만큼 스페이서 영역을 하단에 삽입해 최신 턴이 항상 상단에 위치하도록 유지한다. 응답이 스트리밍되며 높이가 증가하면, 턴 블록의 높이 증가량만큼 스페이서 높이를 실시간으로 감소시켜 화면 하단 여백이 자연스럽게 줄어들도록 한다. 이를 통해 새 메시지가 항상 상단에서 시작되고, 응답 확장 시에도 시선 이동이 발생하지 않는 안정적인 읽기 흐름을 제공한다.
// 레이아웃 측정/제어용 refs
const scrollerRef = useRef<HTMLDivElement | null>(null);
const turnRef = useRef<HTMLDivElement | null>(null);
const [spacerH, setSpacerH] = useState(0);
// 최신 유저 메시지를 상단에 보이게 스크롤바 위치 조절
const scrollTurnToTop = () => {
const scroller = scrollerRef.current;
const turn = turnRef.current;
if (!scroller || !turn) return;
scroller.scrollTop = turn.offsetTop;
};
// 최신 유저 메시지가 채팅방 가장 상단에 보일 수 있게 하단 스페이서 높이 계산
const recomputeSpacer = () => {
const scroller = scrollerRef.current;
const turn = turnRef.current;
if (!scroller || !turn) return;
const scrollerH = scroller.clientHeight;
const turnH = turn.offsetHeight;
const next = Math.max(0, scrollerH - turnH);
setSpacerH(next);
};
// 새로운 메시지가 생기면 위 두 함수 호출
useLayoutEffect(() => {
recomputeSpacer();
scrollTurnToTop();
}, [currentUserText, currentAssistantText]);
// 채팅 화면 사이즈를 유저가 조작했을 때 대응
useEffect(() => {
const onResize = () => {
recomputeSpacer();
scrollTurnToTop();
};
window.addEventListener("resize", onResize);
return () => window.removeEventListener("resize", onResize);
}, []);
// // 스트리밍으로 오는 텍스트의 height를 계산해서 실시간으로 spacer 높이 조절
useEffect(() => {
const turn = turnRef.current;
if (!turn) return;
const ro = new ResizeObserver(() => {
recomputeSpacer();
scrollTurnToTop();
});
ro.observe(turn);
return () => ro.disconnect();
}, []);
return (
// ...
// 채팅 부분 UI
<div ref={scrollerRef} className="flex-1 overflow-y-auto">
<div className="min-h-full flex flex-col px-4 py-3">
<div>
{history.map((m) => (
<MessageBubble key={m.id} m={m} />
))}
</div>
<div ref={turnRef} className="pt-2">
<TurnBlock
userText={currentUserText}
assistantText={currentAssistantText}
/>
</div>
<div style={{ height: spacerH }} className="bg-transparent" />
</div>
</div>여기서 중요한 점은 useLayoutEffect를 사용하여서 DOM이 업데이트된 후, 화면에 랜더링하기 전에 실행을 하는 것이다. useEffect와의 차이점을 간단하게 정리하자면 아래와 같다.
- useEffect: 비동기, 렌더링이 끝나고 콜백 함수를 실행
- useLayoutEffect: 동기, 렌더링 전에 콜백 함수를 실행
즉 recomputeSpacer()는 DOM을 측정하는 작업이고, 측정 결과로 spacerH를 설정하며 scrollTop을 변경한다. 따라서 랜더링 전에 측정과 조정 작업이 끝나야 사용자가 잘못된 레이아웃 보지 않거나, 화면이 깜빡이는 것을 방지할 수 있다.
마무리
아직은 MVP 완성 단계이기 때문에 기능적 퀄리티, 퀄리티도 완벽하진 못하다. 당장 Cursor의 경우만 보아도 유저의 질문에 대한 핵심 응답만 Sonnet, GPT, Claude 같은 대형 LLM에 맡기고, 나머지 직접 툴을 골라서 어디에 어떤 툴을 사용할지는 경량화된 Fast Apply LLM을 사용하는 방식을 통해 보다 더 효율적으로 하고 있다. 또한 파일 수정의 경우 Full Write 대신 diff 기반으로 처리하고 있는 등... 나 역시 이런 효율적인 시스템과 토큰 소비의 절감 등 다양한 방면에서 더 깊은 고민을 해봐야할 것 같다. 그래도 AI Agent들이 어떤식으로 내부에서 작동을 하는지 직접 구현하면 어느 정도 알아갈 수 있는 좋은 기회였다.
